Hive:用SQL对数据进行操作,导入数据、清洗脏数据、统计数据订单、优化结果输出等等
文章目录
-
- 1、准备数据
- 2、了解数据
- 3、将数据导入hive
- 4、如何清洗第一行的脏数据?
-
- 4.1 方式一:shell命令
- 4.2 方式二:HQL (hive sql)
- 4.3 方式三:更新表,过滤首行(个人建议用这个SQL命令)
- 5、每个用户有多少个订单? (分组)
- 6、每个用户一个订单平均是多少商品?
-
- 6.1 一个订单有多少个商品?
- 6.2 一个用户有多少商品?
- 6.3 针对步骤6.2,进行用户对应的商品数量 sum求和。
- 6.4 一个用户平均一个订单有多少个商品?
- 6.5 每个用户在一周中的购买订单的分布?
- 6.6 查看 在12点时间段每个用户购买了哪些商品?
- 7、一个用户平均每个购买天中,购买的商品数量
- 8、每个用户最喜爱购买的三个商品product是什么?
-
- 8.1 每个用户购买的商品的次数
- 8.2 对购买的商品次数进行rank
- 8.3 优化输出结果格式
① Hive 数据管理、内外表、安装模式操作
② Hive:用SQL对数据进行操作,导入数据、清洗脏数据、统计数据订单
③ Hive:多种方式建表,需求操作
④ Hive:分区原因、创建分区、静态分区 、动态分区
⑤ Hive:分桶的简介、原理、应用、创建
⑥ Hive:优化 Reduce,查询过程;判断数据倾斜,MAPJOIN
⑦ Hive:数据进行替换切分后的结果保存为新表,新表进行分词
1、准备数据
百度网盘链接:https://pan.baidu.com/s/1QDlf7SoGPWliagV2ettMOQ
提取码:3jcn


2、了解数据
head -10 orders.csv
order_id:订单号
user_id:用户id
eval_set:订单的行为(历史产生的或者训练所需要的)
order_number:用户购买订单的先后顺序
order_dow:order day of week ,订单在星期几进行购买的(0-6)
order_hour_of_day:订单在哪个小时段产生的(0-23)
days_since_prior_order:表示后一个订单距离前一个订单的相隔天数

head -10 order_products__train.csv
order_id:订单号
product_id:商品ID
add_to_cart_order:加入购物车的位置
reordered:这个订单是否重复购买(1 表示是 0 表示否)
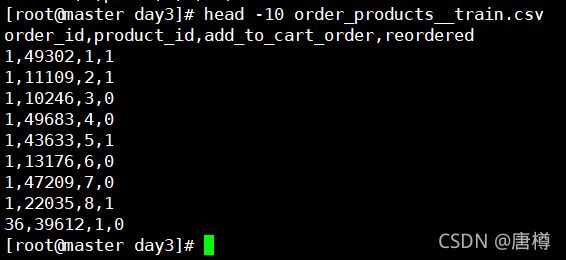
head -10 products.csv (数据仓库定位:商品维度表)
product_id:商品ID
product_name:商品名称
aisle_id:货架id
department_id:该商品数据属于哪个品类,日用品,或者生活用品等

departments.csv(品类维度表)
department_id:部门id, 品类id
department: 品类名称
department_id,department
1,frozen
2,other
3,bakery
order_products__prior.csv(用户历史行为数据)
order_id,product_id,add_to_cart_order,reordered
2,33120,1,1
2,28985,2,1
2,9327,3,0
3、将数据导入hive
对于orders.csv,我们指导他是以‘,’ 作为字段分割符,行与行之间数据是‘\n’是分割。
在hive数据库创建orders表
create table badou.orders(
order_id string
,user_id string
,eval_set string
,order_number string
,order_dow string
,order_hour_of_day string
,days_since_prior_order string
)
row format delimited fields terminated by ','
lines terminated by '\n';

可以得知,创建orders表成功;接下来我们要把orders.csv数据加载到orders表中。
加载数据到hive,有两种方式:
- 加载本地数据到Hive,overwrite 覆盖, into 追加
load data local inpath 'day3/orders.csv' overwrite into table orders;
- HDFS数据加载到Hive (没有 local,要保证HDFS有数据)
load data inpath 'day3/orders.csv'
overwrite into table orders;
我们这里选择从本地加载数据。
load data local inpath 'day3/orders.csv' overwrite into table orders;
select * from orders limit 10;
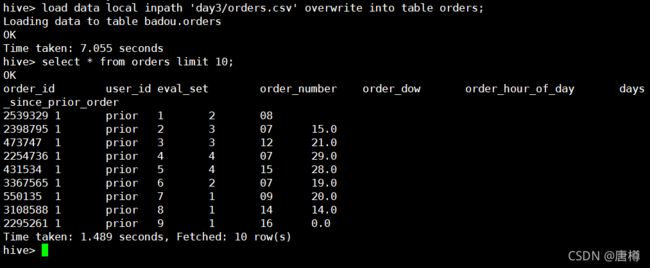
可以发现,第一行数据是脏数据。
我们要自动显示下每个数据的字段名称。
进入 hive-site.xml,在(master)进行配置:
vi hive-site.xml
<!--Hive第一行显示列名称-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>显示列名称</description>
</property>

exit; 退出hive,再重新进入hive。
use badou;
select * from orders limit 10;

创建trains表,加载order_products__train.csv也是如此操作。
4、如何清洗第一行的脏数据?
4.1 方式一:shell命令
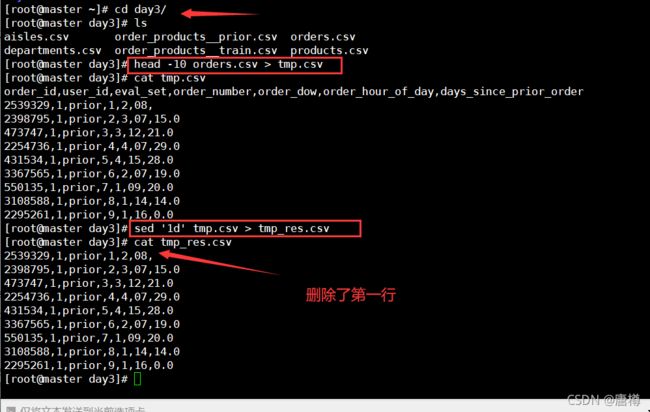
思想:在load加载数据之前,针对异常数据进行处理,用 sed '1d' orders.csv。
测试:
head -10 orders.csv > tmp.csv
cat tmp.csv
sed '1d' tmp.csv > tmp_res.csv
cat tmp_res.csv
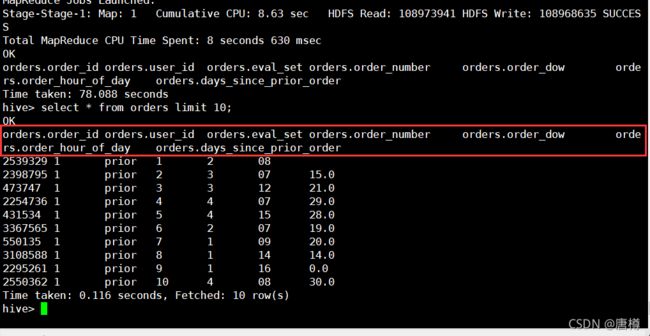
4.2 方式二:HQL (hive sql)
insert overwrite table orders
select * from orders where order_id !='order_id';
4.3 方式三:更新表,过滤首行(个人建议用这个SQL命令)
alter table trains set tblproperties('skip.header.line.count'='1');

5、每个用户有多少个订单? (分组)
我们知道,user_id为用户ID,order_id为订单ID,count(order_id) 统计订单数。
select user_id, count(distinct order_id) as order_cnt
from orders group by user_id
limit 20;
distinct :表示去重
as:把count的结果作为order_cnt

对order_cnt进行从大到小排序的话。
select user_id, count(distinct order_id) as order_cnt from orders
group by user_id
order by order_cnt desc
limit 10;
6、每个用户一个订单平均是多少商品?
先创建priors表,加载order_products__prior.csv数据。
create table priors(
order_id string,
product_id string,
add_to_cart_order string,
reordered string
)
row format delimited fields terminated by ','
lines terminated by '\n';
load data local inpath 'day3/order_products__prior.csv'
overwrite into table priors;
过滤脏数据
alter table priors set tblproperties('skip.header.line.count'='1');

6.1 一个订单有多少个商品?
在priors 表对订单order_id分组,我们选择订单ID和产品数量,产品数量as pro_cnt。
select order_id,count(distinct product_id) as pro_cnt from priors
group by order_id
limit 10;

6.2 一个用户有多少商品?
在orders表有用户ID,priors表有商品ID,这两个表同时有 订单ID order_id,可以把表连接起来,把7.1的结果 as t,在t表我们就有 order_id 和 pro_cnt 两个字段。
(select order_id, count(distinct product_id)
as pro_cnt from priors
group by order_id
limit 10000
) as t
select user_id,pro_cnt from orders as od
inner join t
on od.order_id=t.order_id
limit 10;
完整SQL语句:
select od.user_id, t.pro_cnt from orders as od
inner join (
select
order_id, count(distinct product_id) as pro_cnt
from priors
group by order_id
limit 10000
) as t
on od.order_id=t.order_id
limit 10;
as 是可以省略的;
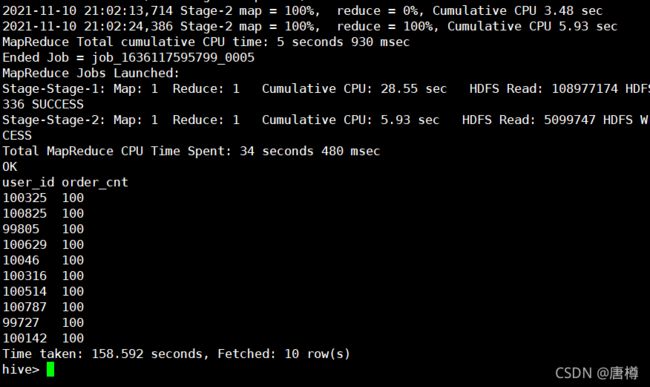
结果应该有用户ID与商品数量 od.user_id, t.pro_cnt。
6.3 针对步骤6.2,进行用户对应的商品数量 sum求和。
对商品数量t.pro_cnt进行求和,即sum(t.pro_cnt)。
【注意】: 使用聚合函数(count、sum、avg、max、min )的时候要结合group by 进行使用。
从 7.2代码进行修改:
select od.user_id, sum(t.pro_cnt) as sum_prods from orders od
inner join (
select order_id, count(distinct product_id) as pro_cnt
from priors
group by order_id
limit 10000
) as t
on od.order_id=t.order_id
group by od.user_id
limit 10;
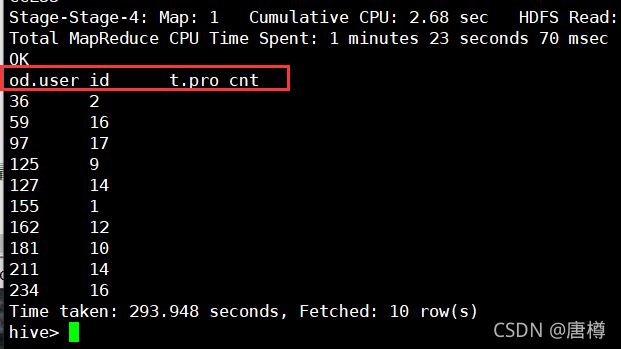
我们,修改 sum(t.pro_cnt) as sum_prods 后,需要进行group by操作,即group by od.user_id。显示结果有 od.user_id sum_prods。
6.4 一个用户平均一个订单有多少个商品?
即 用户的商品数量 / 用户的订单数量 == sum(t.pro_cnt)/count(t.order_id) as sc_prod,
也可以用平均产品数量avg,avg(pro_cnt) as avg_prod
select od.user_id
,sum(t.pro_cnt)/count(t.order_id) as sc_prod
,avg(pro_cnt) as avg_prod
from orders od inner join (
select
order_id, count(distinct product_id) as pro_cnt
from priors
group by order_id
limit 10000
) t
on od.order_id=t.order_id
group by od.user_id
limit 10;

6.5 每个用户在一周中的购买订单的分布?
在 orders表中,的列order_dow,代表购买订单是在一周的星期几,0-6 代表周一到周日。
查询:
head -30 orders.csv
select * from orders limit 30;

思路: 要输出的是用户id,与星期几一天的总订单量。即需要sum(星期几订单),判断if order_dow='0'/ '1'/ '2'/ '3'/ '4'/ '5'/ '6' --> true 为1, false 为0,把结果sum,则得出:星期几一天的总订单量。例如:
user_id order_dow
1 0 sum=0+1=1
1 0 sum=1+1=2
1 1 sum=0+1=1
2 1 sum=0+1=1
由上面数据可知,用户id为1,星期一(0),有2个订单;星期二(1),有1个订单;
用户id为2,星期二(1),有1个订单;
【注意】: 实际开发中,一定是最先开始使用小批量数据进行验证,验证代码逻辑的正确性,然后全量跑!!,提高工作效率。
方式一:用case when 语句
select user_id
, sum(case when order_dow='0' then 1 else 0 end) dow0
, sum(case when order_dow='1' then 1 else 0 end) dow1
, sum(case when order_dow='2' then 1 else 0 end) dow2
, sum(case when order_dow='3' then 1 else 0 end) dow3
, sum(case when order_dow='4' then 1 else 0 end) dow4
, sum(case when order_dow='5' then 1 else 0 end) dow5
, sum(case when order_dow='6' then 1 else 0 end) dow6
from orders
where user_id in ('1','2','3')
group by user_id;
方式二:用 if 语句
select user_id
, sum(if(order_dow='0',1,0)) as dow0
, sum(if(order_dow='1',1,0)) dow1
, sum(if(order_dow='2',1,0)) dow2
, sum(if(order_dow='3',1,0)) dow3
, sum(if(order_dow='4',1,0)) dow4
, sum(if(order_dow='5',1,0)) dow5
, sum(if(order_dow='6',1,0)) dow6
from orders
where user_id in ('1','2','3')
group by user_id;

我们验证数据:从上下图可知: 用户id为1: 星期一没有订单,星期二有3个订单。从下图可知验证正确。。小批量验证完成,我们可以取消 where语句,进行全部量操作。

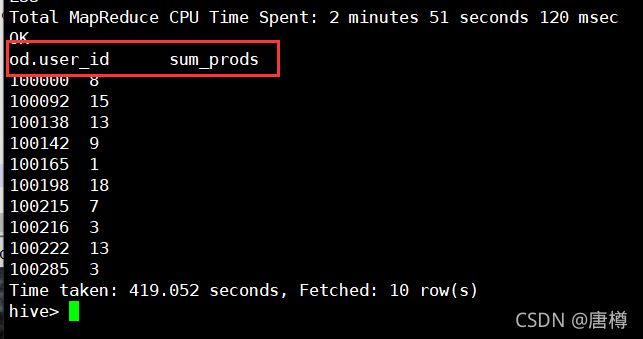
6.6 查看 在12点时间段每个用户购买了哪些商品?
分析:需要 用户ID:user_id, 商品ID:product_id, 时间:order_hour_of_day;
orders表有 : order_id, user_id;
trains表有:order_id, product_id;
把两个表连接起来 inner join。
SQL语句:
select od.user_id, tr.product_id from
orders od inner join trains tr
on od.order_id=tr.order_id
where order_hour_of_day = '12'
limit 10;
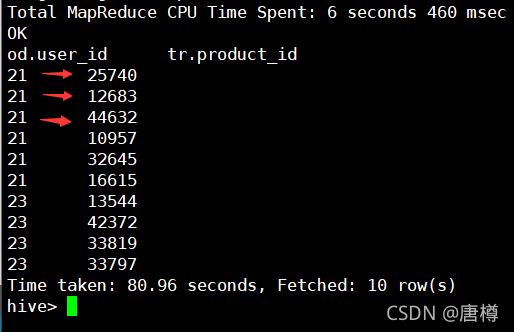
由图可知,在12点,‘21’ 用户 购买了 ‘25740、12683、44632、10957、32645、16615’ 等商品。
7、一个用户平均每个购买天中,购买的商品数量
orders 表中的 days_since_prior_order 等价于购买天数。
我们要用户ID,商品数量,购买天数。
orders 表与priors表 连接可以得到 “用户ID,商品数量,购买天数。”
- 6.1中可以求得一个订单有多少个商品,结果保存为pri 表;
- 从orders表把 order_id, user_id, days_since_prior_order 结果存储为 ord;
- 用 join 连接,查找出
select user_id, sum(商品数量) / count(购买天数) from ord join pri on ord.order_id=pri.order_id group by ord.user_id输出结果
-- ord表,对购买天数的数值需要进行空处理
(select order_id, user_id, if(days_since_prior_order='','-1',days_since_prior_order) as days_since_prior_order
from orders
where eval_set='prior' limit 10000
) ord
-- pro_cnt 为商品数量
select order_id, count(1) as pro_cnt from priors
group by order_id
limit 10000
) pri
完整代码:
select ord.user_id, sum(pri.pro_cnt) / count(distinct days_since_prior_order) avg_prod
from
( select order_id, user_id,
if(days_since_prior_order='','-1',days_since_prior_order) as days_since_prior_order
from orders
where eval_set='prior' limit 10000
) ord
join (
select order_id, count(1) as pro_cnt from priors
group by order_id
limit 10000
) pri
on ord.order_id=pri.order_id
group by ord.user_id
limit 10;

由图结果可知:由用户ID,平均一天商品购买数量。
8、每个用户最喜爱购买的三个商品product是什么?
最喜欢购买就是 购买的商品最多。
因此要先求 每个用户购买的商品的次数,再对次数排序,前三个。
8.1 每个用户购买的商品的次数
select ord.user_id, pri.product_id, count(1) as top_cnt
from
(select * from orders where eval_set='prior'
) ord
join (
select * from priors limit 1000
) pri
on ord.order_id=pri.order_id
group by ord.user_id,pri.product_id
limit 20;
-- 可以 用 partition by 替换 group by。
select ord.user_id, pri.product_id,
count(1) over(partition by ord.user_id,pri.product_id) as top_cnt
from
(select * from orders where eval_set='prior'
) ord
join (
select * from priors limit 1000
) pri
on ord.order_id=pri.order_id
-- group by ord.user_id,pri.product_id
limit 20;

8.2 对购买的商品次数进行rank
--用with关键字 把每个用户购买的商品的次数结果为rank_tmp
with rank_tmp as (select ord.user_id, pri.product_id,
count(1) over(partition by ord.user_id,pri.product_id) as top_cnt
from
(select * from orders where eval_set='prior'
) ord
join (
select * from priors limit 1000
) pri
on ord.order_id=pri.order_id
)
在操作排名,排序常用函数 row_number() ,用于给数据库表中的记录进行标号,在使用的时候,其后还跟着一个函数 over(),而函数 over() 的作用是将表中的记录进行分组和排序。
row_number() over() --分组排序功能;
--语法格式:
row_number() over(partition by 分组列 order by 排序列 desc)
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
这里我们要:row_number(), 是对用户id分组,对商品次数进行降序排序。
select * from
(
select user_id, product_id,
row_number() over(partition by user_id order by top_cnt desc) as row_num
from rank_tmp
-- 排序结果保存为t表
) t
--得出排序结果,where取前三个
where row_num <= 3
limit 20;


可以发现,每个用户最喜爱购买的三个商品。
8.3 优化输出结果格式
要的显示结果:user1 [100_3,101_2,102_1]
user1 [100_3,101_2,102_1]
100代表商品id,_3 中的3是第三个喜欢的意思
像 101_2,2是第二个喜欢的商品。
把转为列表形式用collect_list()函数;
concat_ws('-',列名1,列名2) = 列名1-列名2
如果列名2是整型要cast为string类型。
--即:
collect_list(concat_ws('_',product_id, cast(row_num as string))) as pro_top3
我们要以上面的列表格式化输出,列表里面的数据为 最喜欢的前三名商品。
同样把上面8.2的结果用 with 进行保存为 rank_result。
with rank_tmp as (select ord.user_id, pri.product_id,
count(1) over(partition by ord.user_id,pri.product_id) as top_cnt
from
(select * from orders where eval_set='prior'
) ord
join (
select * from priors limit 1000
) pri
on ord.order_id=pri.order_id
),
-- 要with嵌套,注意这里用逗号分割
rank_result as ( -- 注意这里没有with
select user_id, product_id,
row_number() over(partition by user_id order by top_cnt desc) as row_num
from rank_tmp
)
-- 正式查询语句,与上面的with as直接没有符号分割
select user_id, collect_list(concat_ws('_',product_id, cast(row_num as string))) as pro_top3,
-- size 返回列表中元素的个数
size(collect_list(product_id)) as top_size
from rank_result
where row_num <= 3
group by user_id
limit 20;

发现上图结果满足,用户的最喜欢商品以列表形式返回,商品id后的‘_1’ 代表 第一个喜欢商品,size返回列表商品个数。