windows10使用cuda11搭建pytorch深度学习框架——运行Dlinknet提取道路(二)——代码运行问题解决
运行程序
去github上下载Dlinknet的代码
https://github.com/zlckanata/DeepGlobe-Road-Extraction-Challenge
把数据集放进dataset/train里面
注意数据命名以及格式

直接使用anaconda的powershell运行程序
python train.py出现错误
RuntimeError: An attempt has been made to start a new process before the…
参考这篇博文
我采用了
去掉num_workers参数解决
下一个问题接踵而至
RuntimeError: CUDA out of memory
貌似都是pytorch经常出现的问题
解决方式没有一个好的方法,最后我参考这篇文章
减小batch_size,修改代码来解决
这个解决方法
貌似挺好的,这里码一下,下次试试
果然不能一帆风顺
UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn(“nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.”)
还能怎么办,F:\anaconda3\lib\site-packages\torch\nn\functional.py:1639: UserWarning: nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.
warnings.warn(“nn.functional.sigmoid is deprecated. Use torch.sigmoid instead.”)
那就改吧
只有networks文件夹里的dlinknet含有nn.functional.sigmoid,全部修改即可
改完,再次运行
编译器
推荐使用vscode,下载pycharm还需要破解,否则只有30天试用
与anaconda结合起来,参考配置环境
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
我发现这两个报错简直是两条死路,貌似都只能改batchsize,这个是太小
最后我把train数据集删去了一半,就能够跑通了,但是出现了下面的错误

这里是说找不到该文件夹和th文件,只要新建一个空的就行,就可以跑起来啦
现在我跑的时间是2022年1月11日17:28
数据集是1480个样本

看看多久能跑完测试数据
现在是真害怕有人半夜拔我网线了hhh
待更新。。。
2022年1月12日11:33:50
目前的进度是跑到了121
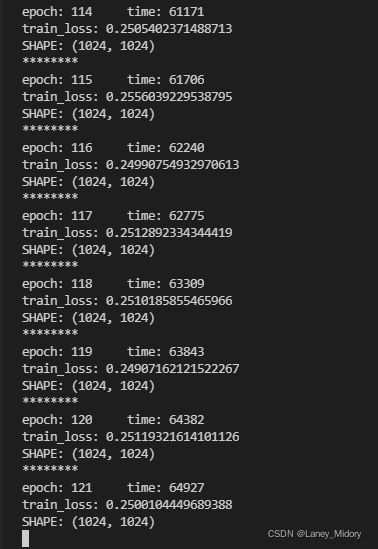
查看代码应该是要跑到epoch=300

目测应该还要跑一整天,这里码一下师姐给我的建议~分享给大家,感谢亲爱的师姐
我:师姐,怎样训练效果最好呢
师姐:
图片越大越多越好
也看你最后要提取哪里的道路
训练的数据和测试的数据要特征要相似
现在用的数据集是东南亚地区的乡村数据,如果你后期提取城市的道路效果就不会很好,如果提取乡村道路应该会效果好一点
先把代码跑通试试效果,之后再进行下一步实验
待更新。。。
现在是2022年1月12日13:18:00
由于出现break语句所以输出了结果

现在来试试predict
运行
python test.py
Error(s) in loading state_dict for DataParallel:
size mismatch for module.finaldeconv1.weight: copying a param with shape torch.Size([64, 32, 3, 3]) from checkpoint, the shape in current model is torch.Size([64, 32, 4, 4]).
size mismatch for module.finalconv3.weight: copying a param with shape torch.Size([1, 32, 2, 2]) from checkpoint, the shape in current model is torch.Size([1, 32, 3, 3]).
尝试了第一种解决方法,失败了
1、model.load_state_dict(torch.load(“model.th”),strict=False)
没效果,还是相同的错
查看了一些博客试了这个方法虽然能成功运行,但结果惨不忍睹
model = torch.load(path)
model.pop('module.finaldeconv1.weight')
model.pop('module.finalconv3.weight')
self.net.load_state_dict(model,strict=False)这是我调试的方法,输出的结果全是黑色图片
最后发现是train的模型和predict模型选择错误才出现了问题
原代码出现了一点问题
需要把下图的dink改成link

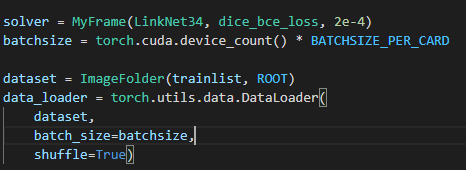

这两个模型需要保持一致
若不一样就会出现网络层数的问题
这样一改结果就出来了

重新进行DinkNet34的训练,这次选取最多的样本,并且还是1024的大小
有了上面的思路,这次重新运行就很快了
总结:
代码部分需要修改的就是
根据需要修改

我决定重启电脑重新训练,重新记录训练时间,大家下一篇博文再见!