阿旭机器学习实战【2】KNN算法进行人体动作识别
本系列文章为机器学习实战内容,旨在通过实战的方式学习各种机器学习算法的知识,更易于掌握和学习,更过干货内容持续更新…
目录
- 人类动作识别问题描述
- 导入相关数据并查看数据信息
- 构建KNN算法模型并查看准确率
- 结果分析
-
- 找出其中预测错误的10个动作,并画出其特征图像
案例及数据集获取方式见文末。 需要的小伙伴可自行获取学习,欢迎大家一起共同学习交流。
人类动作识别问题描述
数据获取方式:
数据采集每个人在腰部穿着智能手机信号,采用嵌入式加速度计和陀螺仪,以50Hz的恒定速度捕获3轴线性加速度和3轴角速度,来获取人类动作数据。
主要进行了六个活动(步行,上楼,下楼,坐着,站立和躺着)的数据采集。
目的:
通过分析已经采集的数据集构建算法模型,来识别人类的动作类型。
导入相关数据并查看数据信息
import numpy as np
# 训练数据特征
x_train = np.load("./x_train.npy")
# 测试数据特征
x_test = np.load("./x_test.npy")
# 训练数据标签
y_train = np.load("./y_train.npy")
# 测试数据标签
y_test = np.load("./y_test.npy")
# 打印数据形状
x_train.shape,x_test.shape,y_train.shape,y_test.shape
((7352, 561), (2947, 561), (7352,), (2947,))
通过上面数据形状可以知道,该数据训练集有7352个样本,测试集有2947个样本,数据特征有561个。
# 打印前100个训练样本的标签数据
y_train[:100]
array([5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
5, 5, 5, 5, 5, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6,
6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=int64)
可以发现有1、2、3、4、5、6这6种标签样本,分别代表人类6种动作。
其中 1 代表 步行; 2代表上楼 ;3代表下楼;4代表坐着;5代表站立;6代表躺着
# 给1-6六个标签起名字
labels = {
1:"walking",
2:"up",
3:"down",
4:"sitting",
5:"standing",
6:"lying"
}
构建KNN算法模型并查看准确率
from sklearn.neighbors import KNeighborsClassifier
# 创建模型
knn = KNeighborsClassifier()
# 训练
knn.fit(x_train,y_train)
# 预测
y_ = knn.predict(x_test)
# 查看准确率
knn.score(x_test,y_test)
0.9015948422124194
上述结果表明:该算法的准确率为90%,还是比较不错的。
结果分析
找出其中预测错误的10个动作,并画出其特征图像
import matplotlib.pyplot as plt
%matplotlib inline
# 设置plt面板大小
fig = plt.figure(figsize=(4*4,3*3))
error_num = 0
for i in range(500):
# y_test表示测试数据真实标签,y_表示KNN算法预测出的结果,取出两者不相等的结果,进行特征绘图
if y_test[i] != y_[i]:
# 画出子轴面
axes = fig.add_subplot(2,5,error_num+1)
# 向每一个子轴面中画图
axes.plot(x_test[i])
# 设置标题
axes.set_title("True:%s\n Predict:%s"%(labels[y_test[i]],labels[y_[i]]))
error_num += 1
if error_num == 10:
break
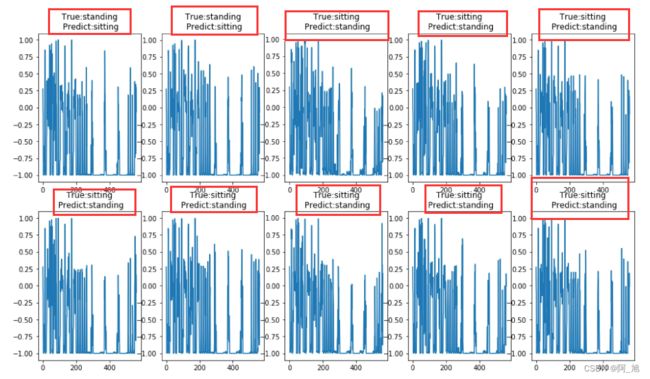
通过上面打印出的预测错误的动作类型,我们可以发现,大部分错误类型基本都是坐着的动作识别成了站着的动作。可能是由于这两种动作信号差别较小的原因造成的。后续可针对性的对采集的信号进行改进。
如果内容对你有帮助,感谢记得点赞+关注哦!
关注下方公众号,发送:
KNN人体动作识别,即可获取本文pdf及实战案例所使用的数据集。
更多干货内容持续更新中…
-------欢迎关注下方我的公众号,共同学习交流,获取更多学习资源------
