<论文阅读> M2BEV Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Represen
0. 为什么要读这篇论文
首先,作者本人并不是这个领域的科研工作者,只能说是自动驾驶领域的一个工程师,我更希望我做的每一件事情,读的每一篇文章都在帮我解决一个问题或者一个疑惑。
那么,谈一下为什么要读这篇文章,自动驾驶视觉感知领域算法开发这个领域可谓是日新月异,越来越多的事物可以被感知到,更多的摄像头参与到了感知算法中,从一开始的1V(前视)到5V,再到8V,从1M像素到2M再到现在8M的摄像头,甚至还有双目和RGBD的参与。全方位的视觉感知,直接就加重了自动驾驶硬件的负担,不说AI算力的问题,单单读取这些摄像头的数据,一般的平台直接就挤爆带宽了。如果每个摄像头的对应深度网络都在运行,实时实现检测和分割的任务,虽然没有实际评估过(事实上也要看有多少任务在同时运行),但估计两个Orin,1000TFlops的算力也得吃紧吧。
事实上,现在主流方案基本都是单摄像头多任务网络,多个检测头共用主干网,确实将encoder这部分的计算共享了,省了一大部分计算量。但是多摄像头的任务依然存在,我们不可能将前视的主干网和侧视的主干网共用,采集特征根本不一样。这也是这篇文章的意义所在,将2D转Bird View,直接在鸟瞰视角去做训练,这就有点像倒车影像的演化,从后视加环视,到现在很多车上直接有融合好的车辆360。不知道这篇作者的想法是不是来自于这点。
1. 摘要
和前面提到的类似,作者提出了M2BEV框架,在BEV(Bird Eye View)中执行3D的目标检测和图像分割任务,提高了检出效率。整个框架包括4个主要的设计:(1)高效的BEV Encoder设计减小了特征图的维度; (2)针对3D boxes Anchor的优化,提出了一种动态的策略,可以关注一下和RPN有何区别; (3)A BEV centerness re-weighting that reinforces with larger weights for more distant
predictions。这点目前没有完全理解,可能是权重优化方向的一种设计,增强了一些边缘框的检出率; (4))Large-scale 2D detection pre-training and auxiliary supervision。应该是模型预训练的方法和Loss函数的复合方法上的优化,后面再细致看一下作者做了什么。
2. Introduction
2.1 当前自动驾驶行业的主要任务
(1) 3D Object detection
(2)BEV Segmentation
2.2 本文的目标
目前已经提出的方法不适合360 多任务的感知,作者提出多目摄像头并且不含Lidar的3D目标检测和BEV分割架构。现在看起来主要是Unified BEV Feat可能是区别于一般多任务网络的核心。
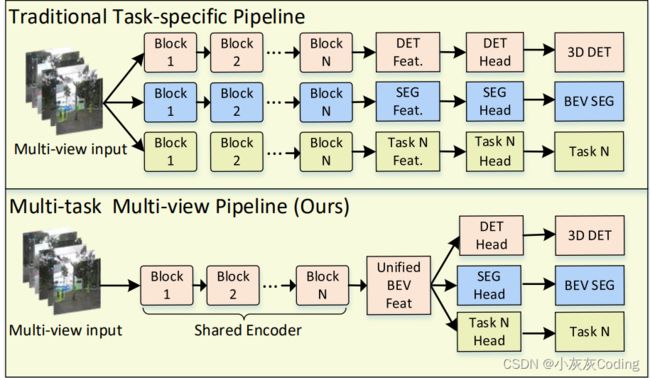
2.3 三种当前主流的方案
(1)Monocular 3D object detection: CenterNet、FCOS3D等,分别在每个 camera view预测 3D BBox, 通过后处理,将每个视角的BBox进行融合 。这些步骤是非鲁棒的,很难给后续规控使用;
(2)Pseudo LIDAR: 通过单目或者双目推测深度信息,来重建3D 体素信息,但是这种方法需要依赖于深度标注信息。依目前读者了解,深度标注在行业内还处于探索阶段,量产还没听说过,即时能标注,高额的标注费用也是需要考虑的;
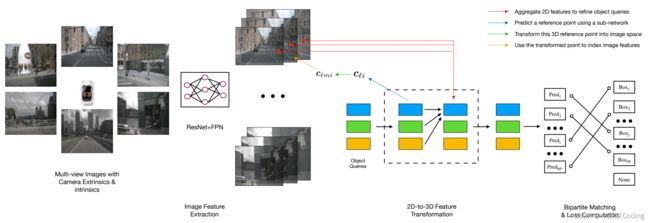
(3)Transformer based method:DETR3D 将3D目标检测投影到多视角2D images下,从而实现了多视角3D 检测。这话稍微有点绕,我理解就是多视角2D信息一起喂到网络里,其实和作者的想法已经非常接近了,但是这个网络没有实现BEV层级的分割任务。下次再读一下 DETR3D这篇文章。
读到这边,其实大概已经有点理解了。现在问题是多视角的标注方法,应该是多图同步进行标注,所以数据对其这点特别重要,其次,目标比较好标注,各个视角图对同一目标进行标注就行,但车道线这种标起来估计就要想一下,感觉会有点问题。
2.4 作者的贡献
(1)新的架构,第一次将3D object detection和BEV Segmentation两个任务放到同一个网络架构里;
(2)对BEV encoder, dynamic box assignment, BEV centerness进行了优化,例如用了S2C operator 实现了4D体素信息转3D BEV tensor;
(3)通过2D annotation 和2D auxiliary supervision 对encoder部分进行pre-trainning,优化了效率和最终执行的性能。
3. 相关工作
3.1 Monocular 3D Detection
(1)早起通过单目2D来预测3D的方法是首先预测一个2Dbox,然后通过啊另一个自网络来回归出3D boxes;
(2)伪3D转换,将RGB图转换成其他的形式,如OFT或者伪LiDAR;
(3) SS3D在训练过程中加入了 3D IOU信息;
(4)FCOS3D 在检测分支加入了3D测距和3D box预测;
(5)PGD使用了对不同目标使用了几何关系来进行深度预测;
关于单目3D检测这部分,目前应该是大部分公司想要的东西,但是在行业里面目前还没有很好的量产产品,我觉得上面说的这些文章也值得去看一下。
说到底,量产会思考做3D检测的成本和其最后的作用,自动驾驶在当前多传感器融合的时代,视觉已经能实现90%以上的目标识别准确率,有没有必要花几百万甚至上千万去优化出一个3D视觉目标Demo,在测距原理没有明显更新的当下,3D目标无非相比2D目标多了一些航向信息或者姿态信息,这个信息从3D视觉输出的准确度有多少?目标是多少?如何去评估?是否需要和测距出来的速度信息进行融合?以及能否通过其他更为简单的方式给出视觉输出的航向信息?这些都是值得研究的。单目3D detection研究还是有一定价值的,毕竟目前很多在跑的车的配置也就是单目的,如果在这个领域有突破,相信行业内部还是很乐意采用的,毕竟我不需要用伪LiDAR或者LiDAR的方式去实现,整车不知道省了多少成本。
3.2 Multi-view 3D Detection
(1) 常规操作:各个摄像头跑自己的网络,靠后处理来做融合,但是后处理程序没有办法和网络集成在一起,没有办法和网络一起优化。还有一个问题,后处理部分不一定有GPU等并行硬件加速,如果有大规模的特征匹配,可能会导致整个结果输出FPS极慢;
(2)ImVoxelNet: 将多视角二维图像信息向三维体素信息进行投影,所有的训练在体素特征上进行。整个听起来应该和作者的思路很像了,用网络将多视角信息进行了融合,后续再细看一下;
- ImVoxelNet读一下相关论文;
这篇论文大概读了一下算法框架,大家有兴趣可以细读一下,论文地址。整体来说,作者先将多视角的信息进行2D CNN处理,处理方法和本文作者的方法几乎一致,下采样到H/32×W/32获得四个特征图,通过FPN网络进行特征融合到到H/4×W/4,然后根据PoseR向3D投影X×Y ×Z×C,多视角再取平均值获得3Dvolume。通过上述操作,完成了2D到3D的特征图投影,再进入neck部分,也就是3D CNN,最后输出head来预测3D BBox,参数为(x, y, z, w, h, l, θ),x,y,z为3D BBox的中心点,w,h,l为宽、高、长, θ为航向角,或者说z轴的转角。
。

(3)DETR3D: 是DETR网络的3D扩展版,这个也需要后续细看一下相关论文,这部分我会尝试写个小的综述;
-
读一下相关论文,搞个综述报告;
整体来说和ImVoxelNet方法没有太大区别,都是ResNet50加4层FPN去提取特征,这篇文章里面的维度描述很清楚。
 3.3 BEV Segmentation(1)VPN:一种简单的转化模块,通过两层感知机将特征图从透视图转化为鸟瞰图。这个听起来有点意思,后续关注; - [ ] 了解一下VPN实现的方法; (2)PON: 提出了一种transformer architecture,将图像信息转换成BEV;
3.3 BEV Segmentation(1)VPN:一种简单的转化模块,通过两层感知机将特征图从透视图转化为鸟瞰图。这个听起来有点意思,后续关注; - [ ] 了解一下VPN实现的方法; (2)PON: 提出了一种transformer architecture,将图像信息转换成BEV; -
了解PON实现方法;
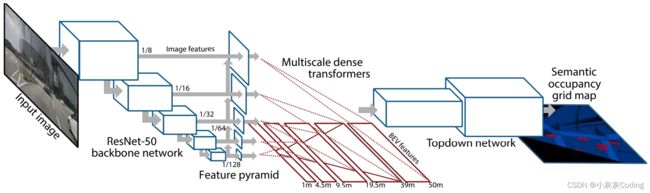
(3)LSS: 通过估计隐式的深度分布来将2D特征转到3D BEV,
- 这个了解一下;
(4)NEAT: 使用Neural Attention fields来预测鸟瞰图坐标系下目标;
4. Method
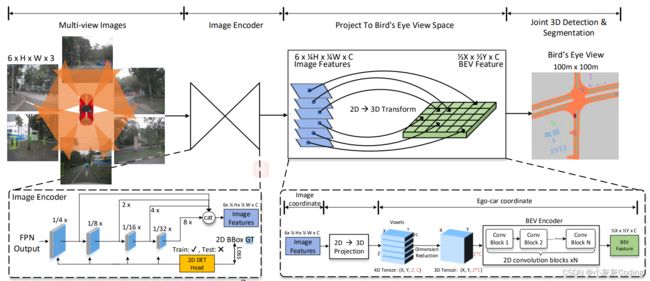
4.1 Architecture
4.2 2D Image Encoder
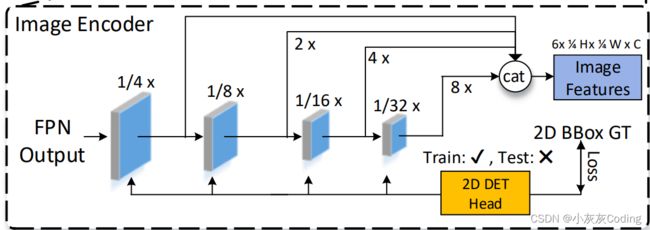
首先,是Encoder部分, Encoder本身是一个提取特征的过程,也称作主干网,作者用的是Resnet。
输入是N张图片,图片维度应该是HW3,每一张图片会走四层Encoder,F1、F2、F3、F4,每一层输出维度为
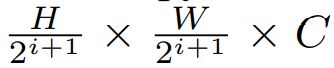
作者定义的融合维度为H/4 * W/4,所以小于该维度F2,F3,F4都要进行上采样。上采样之后,通过11卷积将这四层输出进行concatenate, 此时维度为HWC,如果有6个视角,那输出的特征图就是6HWC。(这部分有点疑问,因为作者在文字描述里面输出是H/4 * W/4,比较奇怪,目前不太清楚是做了特征融合还是特征扩充)
4.3 2D→3D Projection
假设图像中的某个像素P ∈ H×W×3,三维世界中的一个点V ∈ X×Y ×Z×C。根据相机坐标系转换关系,
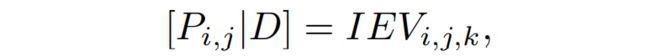
I和E分别是相机的内参和外参,当深度D未知的时候,每个像素点对应三维世界一系列的点。
作者根据这一点,假设深度在这一系列点上的分布是一个均匀分布,也就是说三维空间的这些点都有图像的这个像素的信息。
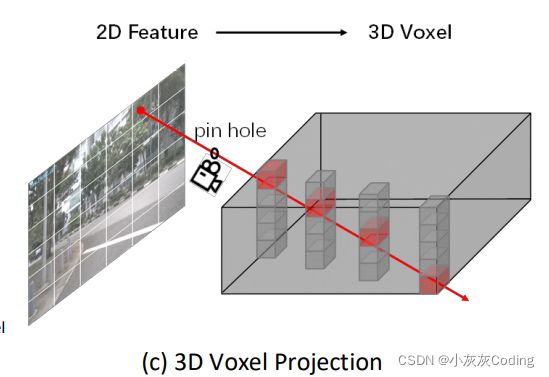
- 待办:看一下这部分的网络架构;
4.4 3D-BEV Encoder
BEV Encoder的作用就是使用3D卷积将Z方向上的维度压缩掉。作者在这里用了Spatial to Channel的方式优化。具体做法就是先用torch.reshape将4D tensor XYZC压缩成XY*ZC,然后使用2D卷积进行Channel方向的压缩,这样的占用内存和计算量会少很多。
4.5 3D DetectionHead
作者直接使用点云的网络PointPillars的3D检测头,优化了anchors的分配方法来解决NMS问题。
- 补充这部分的网络架构
4.6 BEV Segmentation Head
作者用了 4层3×3卷积层+1×1卷积进行上采样,输出H×W×N。 最后像素分类简化为N=2,drivable
area and lane boundary
- 补充这部分网络架构