【后端】HTTP 初识
1.HTTP协议是 前后端交互的桥梁~
2.Tomcat 是java世界中,最主流的HTTP服务器之一,写后端代码,很多都是基于Tomcat二次开发
3.Servlet Tomcat后端程序员提供的开发服务器程序的API合集
4.Linux 使用云服务器来部署写好的程序
以上是即将学习的后端知识,下面先来学习HTTP协议~
网络技术中,最核心的概念就是 “协议”
HTTP是应用层典型的协议
应用层,很多时候是需要程序员自定义应用层协议,当然也有一些现成的协议供我们使用
HTTP就是其中最好的一种之一~
HTTP主要涉及以下方面
(1)浏览器和服务器的交互(打开网页)大概率都是使用HTTP协议
(2)手机APP和服务器之间的交互,也大概率是用HTTP协议
(3)(可用HTTP协议,也可不用)服务器之间的相互调用,也可以使用HTTP协议
比如我们在浏览器中输入一个网址,点击搜索就会看到相应的页面
这个过程,就是通过HTTP和服务器进行了通信~
那么HTTP是如何与服务器交互的呢?大致如下图所示~
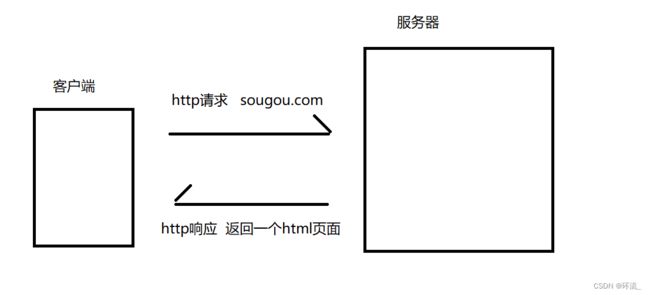
客户端首先会发送一个http请求给服务器,服务器根据请求,找到客户端想要的资源(一般就是一个html)把这个html通过http响应,返回给客户端~
然后客户端接收到服务器返回的html之后,对页面进行渲染,就能看到屏幕上出现了一个网页~
HTTP这个协议属于典型的“一问一答”模型的协议
就是说发送一个请求,返回一个对应的响应,有的协议是多响应模型,就是返回多个响应
我们学习HTTP,主要是学习:HTTP的报文格式
报文格式就描述了HTTP请求是啥样的,响应是啥样的~~
抓包
要想理解HTTP的报文格式,就要通过抓包工具来学习
抓包工具是一个特殊的软件,相当于一个代理工具,浏览器给服务器发的请求就会经过这个代理程序,进一步的就能解析出请求和响应的结果如何~
形象化一点来说,抓包工具就相当于你的舍友~
你到饭点了,会自己去食堂吃饭,到了食堂,你对食堂大叔说,来一份培根蛋炒饭~(此时你作为客户端,对食堂大叔发出了一个“来一份培根蛋炒饭”的请求),过来一会,作为服务器的食堂大叔就给你返回了一份培根蛋炒饭的响应~
但是你使用抓包工具的话,就相当于你的舍友去帮你打饭,你把你的请求(一份培根蛋炒饭)交代给你舍友,你舍友去食堂,把你的请求交代给食堂大叔,接着食堂大叔把培根蛋炒饭给你的舍友,你的舍友再带回来给你

通过舍友,我跟老板的间接交易,舍友的知道得一清二楚的
因此,我们程序员可以通过这个代理程序,就可以知道浏览器和服务器之间的具体内容了~
谈到代理,还分为两种类型
【正向代理】:(给客户端提供服务的,和客户端关系密切)站在服务器的角度,正向代理把真正的客户端给隐藏起来了,服务器不知道真实的客户端是啥;食堂大叔不知道要买培根蛋炒饭的人是你,但这不耽误你获取到食堂大叔的培根蛋炒饭
【反向代理】:(给服务器提供服务的,和服务器关系密切)站在客户端的角度,反向代理把真正的服务器给隐藏起来了,客户端不知道真实的服务器是啥
接下来我们使用抓包工具来分析HTTP协议的工作过程
抓包工具有很多,这里我们使用的是 fiddler抓包工具(去fiddler官网下载即可)
当我们打开浏览器搜索网页的时候,抓包工具就开始抓包了
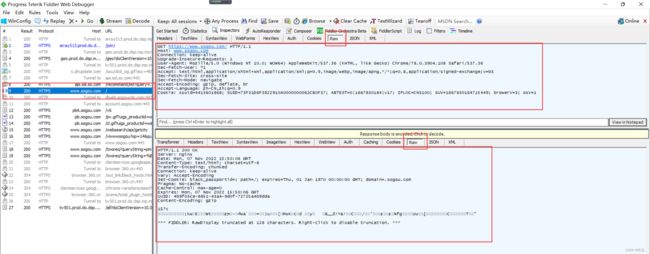
当我们抓包到搜狗官网的页面后
看右半部分,有上下两个部分,上下两个 Raw就是我们的抓包信息,通过这里我们就可以查看HTTP请求和响应的报文格式~
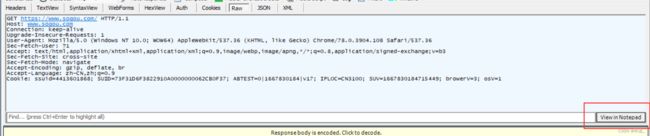
点击左下角的View,就会以文本格式显示出请求和响应的报文格式(上面是请求,下面部分是响应)
先看请求
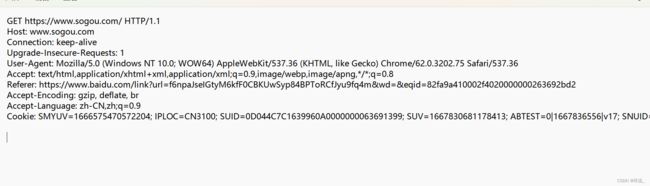
上图是请求的报文格式,里面有4部分信息
(1)首行

上图划分了三部分,第一部分是方法,也就是HTTP方法,表示对服务器做的啥请求;第二部分是网址,也就是URL,描述了网络上的唯一资源;第三部分是版本号
(2)请求头 header

这里的每一行都是一个键值对,键和值之间用 :空格来分割,这里的键都是有固定含义的,之后再说
(3)空行

一个HTTP请求的header可以有若干个,header完后,会预留出一行空白,用来表示header结束~
(4)正文body
正文有的请求没有,有的请求有,就是在空行的下面,搜狗这里是没有正文的
响应
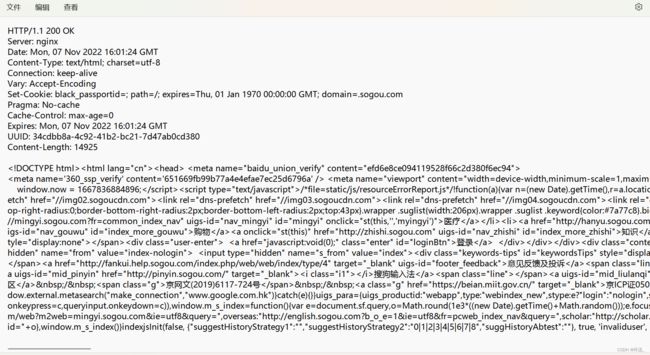
这时搜狗官网完整的响应 格式
同样是4个部分,首行,响应报头,空行,正文
(1)首行
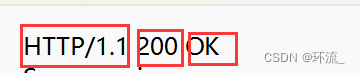
首行有两部分:分别是第一部分 版本号,第二部分的200是状态码,通常表示成功,OK是状态码的描述,有的响应有,有的响应没有,这对状态码进行了解释说明
(2)响应报头header

同样也是键值对结构
(3)空行
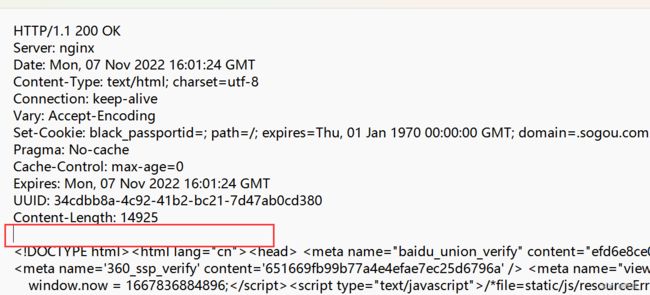
作为header的结束标志
(4)正文
 这不单单是响应才有,请求也是可能会有的
这不单单是响应才有,请求也是可能会有的
综上所述,上面就是HTTP的请求响应的基本报文格式,分别有4部分,内容都大同小异~
ok,结束~~~