GAN论文精读 GGDR:让生成器引导鉴别器来学习 Generator Knows What Discriminator Should Learn in Unconditional GANs
《Generator Knows What Discriminator Should Learn in Unconditional GANs》是NAVER AI Lab 2022年的最新研究,文章被ECCV2022收录。
文章地址:https://link.springer.com/chapter/10.1007/978-3-031-19790-1_25
代码地址:https://github.com/naver-ai/GGDR.
本篇文章是阅读这篇论文的精读笔记。
一、原文摘要
最近的条件图像生成方法受益于密集监督,例如分割标签图,以实现高保真度。然而,很少探索使用密集监督来无条件生成图像。在这里,我们探索了密集监督在无条件生成中的功效,并发现生成器特征图可以替代成本高昂的语义标签图。
根据我们的经验证据,我们提出了一种新的生成器引导鉴别器正则化(GGDR),其中生成器特征映射监督鉴别器在无条件生成中具有丰富的语义表示。
具体地说,我们使用U-Net架构进行鉴别器,该鉴别器被训练以预测给定假图像作为输入的生成器特征图。在多个数据集上的大量实验表明,我们的GGDR在定量和定性方面持续改进了基线方法的性能。
二、为什么提出GGDR?
生成性对抗网络(GAN)在各种计算机视觉任务中取得了很好的结果,而在GAN中,构建有效的鉴别器是生成质量的关键组成部分之一。
改进鉴别器的一种简单而有效的方法是提供可用的附加注释,如类标签、姿势描述符、法线图、语义标签监督等等,其中语义标签监督包含了关于图像的丰富而密集的描述,并且经常用于条件场景生成。语义监督在条件生成中取得了成功,但却很少在无条件环境中进行探索。
本文则是为了证明使用密集和丰富的语义信息指导鉴别器在无条件图像生成中也很有用,提出了一种在利用语义监督的同时避免数据注释成本的方法。

在此设想上,作者提出了生成器引导的鉴别器正则化(GGDR),其利用生成器特征图指导鉴别器,改进鉴别器的性能,主要工作如下:
1.研究了密集语义监督对无条件图像生成的有效性。
2.证明生成器特征图可以用作人类注释语义标签图的有效替代品。
3.提出了生成器引导的鉴别器正则化(GGDR),它鼓励鉴别器通过利用生成器特征图来具有丰富的语义表示。
4.我们证明,GGDR在多个数据集上不断改进最先进的方法,尤其是在世代多样性方面。
三、无条件GAN中的语义监督
3.1、语义监督有助于鉴别器学习更多的语义
更强的语义监督有助于鉴别器学习更多的语义和空间感知表示,并为生成器提供更有意义的反馈。作者设计了实验证明(具体可以看原文),为鉴别器提供额外的语义指导可以提高无条件图像合成中的模型性能。

但密集标签图在用于无条件图像合成的数据集中很少见,手动收集它们很耗时。基于此作者分析生成器中的特征图,作为地面真实标签图的有效替代。
3.2、生成器的特征图可以揭示对象的语义
训练的GAN生成器的特征图包含丰富而密集的语义信息。Collins等人表明将k-means聚类应用于生成器的特征图可以揭示对象的语义,并使用聚类来编辑图像。我们注意到,这些特征图是生成图像的丰富语义描述符,可以替代真实实况标签图。
为了可视化每个特征图中捕获的信息,我们使用生成的一批图像在每个层上运行k-means算法。

可以看出,
- (a)是最终训练好的生成器在不同维度下的特征图,可以看到早期的特征地图显示了粗略的对象位置,后一层的特征地图包含了详细的对象部分。可视化的特征图看起来像伪语义标签图,并且可以被视为包括关于图像的空间和语义信息的丰富描述。
- (b)是在训练期间可视化生成器的特征图,以检查特征图在多早的时候变得有语义意义。令人惊讶的是,可以观察到,即使在早期阶段,特征图和相应生成的图像也能捕捉到物体的粗略形状和位置。也就是说训练过程中可以利用生成器特征图来提高生成性能。
因此,选择生成器的特征图作为语义标签图的替代,以指导使用语义监督的鉴别器是可行的。
且这种特征图是中间图像特征,获取这种特征图不需要额外的资源和人力标注。
3.3、生成器引导鉴别器正则化(GGDR)
基于以上推导,作者提出了生成器引导鉴别器正则化,鉴别器D的设计
采用U-Net编码器-解码器结构,最后一层预测语义标签映射。

对于每一层,作者连接鉴别器中的解码器和编码器层的输出,并运行一个线性1×1卷积层和上采样堆叠解码器模块,直到解码器输出具有与目标生成器特征图相同的分辨率。然后,计算解码器输出和目标特征图之间的余弦距离损失,帮助改进鉴别器。
可以看到框架简单且易于应用现有的GAN模型,不需要任何额外的注释。
3.4、损失函数
总的损失函数为: L total = L a d v + λ r e g L g g d r \mathcal{L}_{\text {total }}=\mathcal{L}_{a d v}+\lambda_{r e g} \mathcal{L}_{g g d r} Ltotal =Ladv+λregLggdr
损失由两部分组成,第一部分是常用的GAN的对抗性损失,第二部分是GGDR的余弦损失(解码器输出和目标特征图之间的余弦距离损失), λ r e g λ_{reg} λreg是超参数。
-
对抗损失: min G max D L a d v ( G , D ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \begin{array}{r} \min _{G} \max _{D} \mathcal{L}_{a d v}(G, D)=\mathbb{E}_{\boldsymbol{x} \sim p_{\text {data }}(\boldsymbol{x})}[\log D(\boldsymbol{x})]+ \mathbb{E}_{\boldsymbol{z} \sim p(\boldsymbol{z})}[\log (1-D(G(\boldsymbol{z})))] \end{array} minGmaxDLadv(G,D)=Ex∼pdata (x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
-
GGDR余弦距离损失: max D L g g d r ( G , D ) = − E z ∼ p ( z ) [ 1 − F t ( G ( z ) ) ⋅ G ( z ) t ∥ F t ( G ( z ) ) ∥ 2 ⋅ ∥ G ( z ) t ∥ 2 ] \begin{aligned} \max _{D} \mathcal{L}_{g g d r}(G, D) &=\quad-\mathbb{E}_{\boldsymbol{z} \sim p(\boldsymbol{z})} & {\left[1-\frac{F^{t}(G(z)) \cdot G(z)^{t}}{\left\|F^{t}(G(z))\right\|_{2} \cdot\left\|G(z)^{t}\right\|_{2}}\right] } \end{aligned} DmaxLggdr(G,D)=−Ez∼p(z)[1−∥Ft(G(z))∥2⋅∥G(z)t∥2Ft(G(z))⋅G(z)t]
四、实验
4.1、数据集
作者验证了GGDR在各种数据集上的效果,包括CIFAR-10 , FFHQ , LSUN cat, horse,church, AFHQ and Landscapes :
- CIFAR-10由10类50000张微小彩色图像组成;
- FFHQ包含70000张人脸图像;
- AFHQ包含每只猫、狗和野生动物脸大约5000张图像;
- LSUN cat, horse,church分别由猫、马、教堂场景组成,每个数据集使用了20万张图像;
- Landscapes包含从Flickr收集的4320张风景图片。
4.2、实验设置
实验设置:
- 对FFHQ和小数据集应用了水平翻转;
- 所有图像的大小均调整为256×256;
- λ r e g λ_{reg} λreg=10;
- R1正则化;
评估指标:Frechet Inception Distance(FID分数)
4.3、实验结果
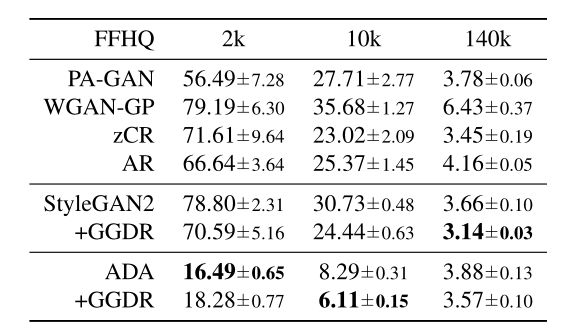
FFHQ数据集上的测量均值和标准差:
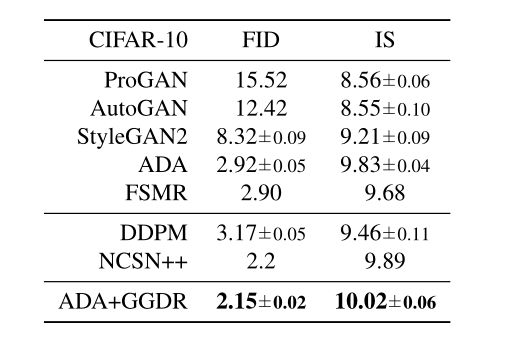
CIFAR-10数据集上的FID和IS分数的均值和标准差:
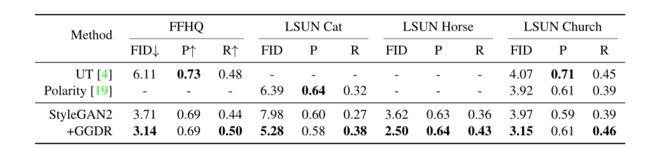
FFHQ、LSUN Cat, LSUN Horse 和 LSUN Church的比较。我们的方法在FID和召回方面改进了大型数据集中的StyleGAN2[29]。P和R表示精度和召回率。更低的FID和更高的精度和召回率意味着更好的性能。
AFHQ Cat, Dog, Wild 和 Landscape的比较。我们的方法在FID和召回方面改进了小数据集中的ADA

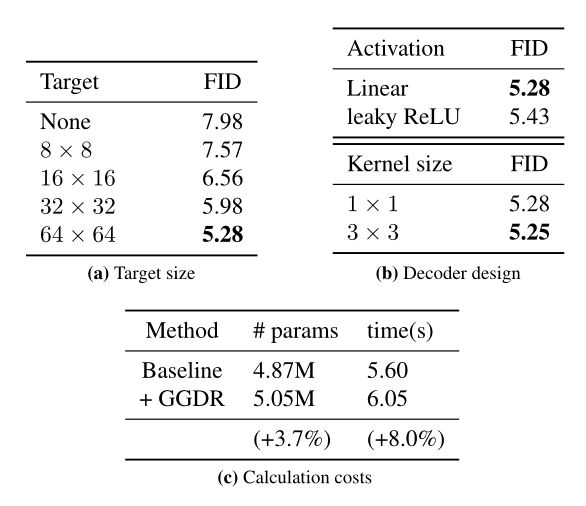
另外,作者还设置了不同size下、不同激活方法、不同卷积核大小的实验结果:
五、总结
文章提出了密集语义标签映射在无条件图像生成中的有效性。受此观察的启发,我们提出了一种新的正则化方法,以利用生成器的特征图,而不是人类注释地面真相语义注释,以允许鉴别器学习更丰富的语义表示。
最后
个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
关注我:中杯可乐多加冰
限时免费订阅:文本生成图像T2I专栏
支持我:点赞+收藏⭐️+留言