基于SQL语言实现机器学习以及深度学习
目录
前言
一、总体架构
第一步
第二步
第三步
第四步
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
相信很多朋友听到这个标题第一反应:基于SQL能够实现机器学习?当然还有的朋友是有过了解一些类似项目的,例如Byzer和阿里的SQLFlow。都是基于SQL语言去实现一些机器学习算法。但是真正用过的朋友应该还是少数的,一般使用场景也都是使用Python调用sklearn实现一些简单的机器学习。很少有喜欢科研的朋友从底层手撕数学算法写完实现整个算法,我认识的一些同事朋友几乎都是直接调用sklearn实现,确实现在也是一般调库调参也能够快速实现一些功能,但是这使得机器学习的门栏大大降低。
有了机器学习的接口便可集成非常多的功能,如果能够解析传输的SQL语句,能够解析其中的数据和想要实现的一些机器学习算法和参数,那么即可调用sklearn功能。这是我的初步想法,当然之前进行的sqlparse解析也是承担了相当大的功能,可以将如今这个目标做一些初步的攀登了。
一、总体架构
我的初期构建想法可能相对比较简单,简单的来说分为五步。

第一步
如果我们想要实现基于SQL语言的机器学习分析,那么首先我个人感觉应该与平台化系统差不多。以用户角度思考,我传入的是一条SQL语句,其中包含我想要传输的数据库的表包含的字段列名和限制条件,其中想要调用的机器学习算法应该可以作为一个函数去实现。比如:
SELECT KNN_result
FROM (
SELECT
KNN_select(features1,features2,features3),
KNN_parameter(n_neighbors=5,radius='auto',leaf_size=30),
FROM Table1
)t
以上写法只是我现在的想法并不一定最终形式会以这种语法呈现。那么如果我们能够解析SQL语句的话,就不用去限定SQL语句要如何编写了,这样一来使用SQL的数据分析师或者是大数据工程师都可以很好的使用这个功能,不用再花费其他学习成本去学习另一种新的语言。那么这里我们很容易想到这个系统最主要的功能在于这个SQL解析,最后的目标是需要将参数传入sklearn的,因此解析整个SQL将是关键。
第二步
第二步就是关键所在了,如何去解析整个SQL语句,而且最好是能够直接在Python里面就能够解析出来。这样的话可以直接将参数传入读取SQL的python脚本,从而去连接线上的数据库。那么这里最好是以平台、数据中台的形式去集成这样的一个功能。当然直接通过pymysql,pyhive都可以实现连接数据库进行交互。通过解析后的SQL数据做一个简单的提取之后,与数据库取得连接后将要求的特征和数据库以及表传入数据库SQL进行查询,再通过read_sql保存作为一个dataframe输出。
pandas.read_sql(
sql,
con,
index_col=None,
coerce_float=True,
params=None,
parse_dates=None,
columns=None,
chunksize=None)我之前写过一系列关于SQL解析的文章,主要是基于Python语言的SqlParse库进行SQL解析,该项目已经完成初版的大致功能,能够解析比较复杂的SQL语句并且可以获取其相应的字段。

以此作为支持我们可以获取到机器学习算法的关键字段,与sklearn关联起来,即可完成机器学习算法提取。

其实这么处理的话,仅需要读取关键字段之后保存,而原本的SQL语句将传入数据库获取得到的数据作为数据集传出就好了。通过我之前写的一系列文章pyhive或者是pymysql连接数据库很容易实现这个功能。
# Connect to the database
connection = pymysql.connect(host='localhost',
user='user',
pswr='xxx',
database='db',
port = '3306'
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)第三步
第三步就是实现如何将提取出来的关键字段与机器学习的sklearn的算法关联起来了。sklearn的很多方法可以可以通过写函数接口来与提取出来的函数功能字段匹配实现不同的功能。这不算难,应该是比较好实现的功能,关键在于其对于sklearn的调用文档和SQL机器学习函数文档结合是一大难点。该以怎么样的形式传入,又该如何调用这个算法和其对应的参数,这是需要花费精力去写这些文档。
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC通过获取到的DataFrame传入机器学习算法得到结果。
LR=LogisticRegression()
LR.fit(X=X_train,y=Y_train)
predictions=LR.predict(X_test)
print(accuracy_score(Y_test,predictions))
print(confusion_matrix(Y_test,predictions))
print(classification_report(Y_test,predictions))
第四步
输出的结果一般就为DataFrame,此刻一般会产生两种表格,一类为直接输出的结果表,包含计算或者是预测后的结果表;另一类就是基于划分的测试集得到的ROC,AUC,准确率等数据,此类表格需要另外创建张新表保存。也就是说返回结果有两张表格,这两张表格都可以基于to_sql的方法,转换为DataFrame写入数据库就可达到。
DataFrame.to_sql(name, con, schema=None, if_exists='fail',
index=True, index_label=None, chunksize=None, dtype=None)from sqlalchemy import create_engine
import sqlalchemy
import pymysql
import pandas as pd
import datetime
from sqlalchemy.types import INT,FLOAT,DATETIME,BIGINT
date_now=datetime.datetime.now()
data={'id':[888,889],
'code':[1003,1004],
'value':[2000,2001],
'time':[20220609,20220610],
'create_time':[date_now,date_now],
'update_time':[date_now,date_now],
'source':['python','python']}
insert_df=pd.DataFrame(data)
schema_sql={ 'id':INT,
'code': INT,
'value': FLOAT(20),
'time': BIGINT,
'create_time': DATETIME(50),
'update_time': DATETIME(50)
}
insert_df.to_sql('create_two',engine,if_exists='replace',index=False,dtype=schema_sql) 
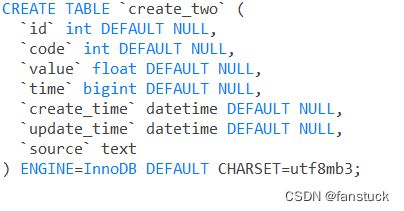
那么以上就完成了基于SQL语言实现机器学习以及深度学习的基本架构和流程方法了,现在要做的就是基于这个架构流程实现一些简单的Demo,跑通整个流程后再封装就好。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。