论文研读:An Event-based Data Model for Granular Information Flow Tracking
An Event-based Data Model for Granular Information Flow Tracking
Abstract
我们提出了一个通用的数据模型(common data model CDM),用于跨各种平台和粒度表示因果事件。该模型是在美国国防高级研究计划局透明计算计划下为攻击起源分析而开发的。统一模型成功地表达了跨一系列粒度(例如,对象或字节级)和平台(例如,Linux和Android、BSD和Windows)的数据起源。本文描述了我们在受控实验室实验中开发通用数据模型的经验、教训和性能结果。
1 Introduction
现代网络威胁,如高级持续威胁(APT),越来越难以检测和应对。这些复杂的程序可以长时间休眠,并使用隐蔽的长期侦察和颠覆来实现它们的目标,例如信息过滤。国防高级研究计划局的透明计算(TC)计划旨在通过使原本不透明的企业系统透明来早期检测APTs和根本原因分析[7]。透明性是通过在企业的通信/计算平面上对程序和数据之间的因果关系进行粒度标记和跟踪,将这些依赖关系组装成端到端的行为,并对行为进行推理来实现的。
核心TC技术被组织成一个三层管道,如图1所示。管道中的第一层是标记和跟踪,其中不同的企业和移动平台集被用于产生粒状的因果事件、标记和元数据流。事件流被传递到数据处理层,使用公共数据模型和API进行规范化和存储。然后,检测和执行层使用流数据进行取证分析和实时APT检测,以及主动执行保护策略。
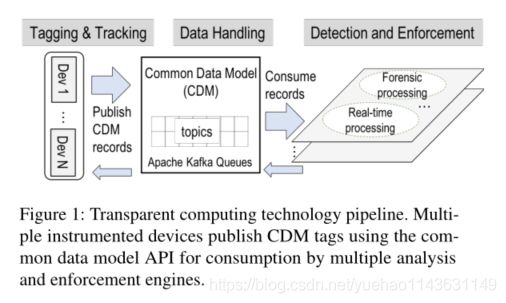
(透明的计算技术流水线。多个设备使用公共数据模型API发布CDM标签,供多个分析和实施引擎使用。)
标记和跟踪技术在活动之间建立因果关系,仔细平衡跟踪粒度与检测速度。存在着大量的技术,其中一些是粗粒度的,比如那些基于审计日志系统的技术(例如,[9,12]),而另一些是细粒度的,比如使用信息流污染跟踪系统(例如,[2,5,6])。这些技术可以在整个系统中以任意粒度跟踪从源到汇聚的数据流。技术也因平台(例如,桌面、服务器、移动、嵌入式)、操作系统和软件栈层而不同。
实时检测和取证分析技术使用标记和跟踪系统产生的起因事件,通常构建某种形式的攻击起因图,并在不同的时间周期对其进行推理,以检测策略违规并执行根本原因分析[10,11]。准确的来源信息是理解数据如何通过设备的关键,这对于检测和理解apt尤其重要。
本文主要关注公共数据模型(CDM)表示(关于标记和跟踪技术的详细信息请参阅[2,5,6,9,12],关于检测技术的详细信息请参阅[10,11],所有这些直接影响了CDM的设计)。我们从这样一个统一的表示中确定了三个主要需求。首先,CDM应该能够以高保真度和跨平台的各种粒度捕获关于数据和控制平面的元数据。第二,表达标签和跟踪技术产生的信息应该是自然的,而不会给它们增加不必要的负担,例如,要求它们捕获它们本不打算捕获的数据或执行不自然的数据转换。第三,它应该包含实现实时检测和取证分析所需的所有语义。CDM对数据做最小的假设,以不限制不断发展的检测和分析算法。在CDM事件流的授权下,不同的检测和分析算法可以各自决定如何在语义上统一或修剪数据以满足其处理需求。
通过与更广泛的TC团队达成共识,我们设计了CDM,首先仔细考虑了标记和跟踪技术产生的数据中检测和分析技术的需求。随着技术团队获得实际操作经验,该设计经过了4年时间的演变。CDM对系统实体(主体、主题和对象)之间的事件和它们之间的颗粒信息流依赖关系进行编码(例如,如果进程读取四个文件并将一个缓冲区写入一个套接字,颗粒标记允许跟踪这四个文件中哪一个对缓冲区有贡献)。实体间的颗粒信息流使得APT检测和分析技术能够以前所未有的保真度[10]重构攻击者行为之间的因果关系。
我们最初考虑使用和/或扩展W3C PROV[4],它是为表示起源而设计的数据模型。PROV不太适合实现TC的上述目标,主要有三个原因。CDM中的事件是(first class citizens)一类公民,它们具有丰富而复杂的语义,不能使用PROV的简单预定义关系来准确捕获这些语义。其次,CDM设计添加了粒度标签,以空前的保真度和精度表示信息流。这对于APT的检测至关重要,因为APT的活动持续时间很长。使用W3C PROV将只允许对数据依赖关系进行粗粒度跟踪,随着时间的推移,这会导致准确来源的重大损失。最后,CDM中的事件可以有任意数量的主客体关系,而PROV主要支持二元关系,进一步限制了表达性。我们注意到,检测和分析技术可以通过将每个事件映射到一组PROV关系,直接将CDM转换为W3C PROV。这种转换可能会丢失信息。
本文的贡献如下:
1. 通用数据模型及其设计原理(§2)。在四年的时间里,所有的TC表演者都达成了一致意见。
2. 一个使用Apache Avro[13]的模型的开源实现(§3),以及几个用于序列化的测试客户端,以及他们的性能总结。源代码是公开的[3]。
可以在[1,8]处找到使用CDM的能力对不同平台和攻击场景的来源进行编码的开放数据集。数据集包括各种详细的攻击场景示例及其描述、它们的CDM编码以及用于处理和可视化的工具。
https://github.com/darpa-i2o/Transparent-Computing/
2 Common Data Model
我们描述了用于捕获由各种标记和跟踪技术产生的标记事件流的CDM的语义和语法,如[1,8]所示。模型中有6个核心实体:主机、主体、主题、事件、对象和ProvenanceTags。图2显示了这些实体及其关系(参见最新的CDM版本以获得完整的规范和每个实体[3]的详细描述)。

Hosts and Principals Host代表网络中的主机或节点,Principals和对象驻留在该主机或节点上,主体执行和事件发生。Principal代表拥有对象和流程主体的本地用户。
Subjects Subjects代表执行上下文,主要包括线程和进程。如果需要,它们可以更细粒度,并且可以表示其他执行边界,如函数和块。例如,进程内线程内的函数可以表示为三个主题,其中函数的parentSubject属性是线程,线程的parentSubject属性是进程。进程的parentSubject属性将被设置为派生它的父进程。在这里,函数主题是比线程更细粒度的执行边界。
Events Events表示代表主题执行的操作。事件可以用不同的粒度表示。事件包括系统调用,如那些由审计子系统发出的调用(例如,Windows ETW, Linux auditd, BSD dtrace),不同层的函数调用,指令执行,或者甚至更抽象的概念表示“盲”执行,如黑盒没有被检测(更短)。事件是模型中的核心实体,是表示对象和对象之间信息流的主要抽象,概念上表示为主体和对象之间的有向边,反之亦然。事件被假定为原子性的,因此事件之间没有直接的关系。
相反,事件通过受影响的主体和对象与其他事件相关联。我们定义了许多类型的事件,大多对应于系统调用,参见[3]。
事件可以有不同的粒度,但它们仍然是原子。例如,函数边界可能在其中执行许多原子事件,因此函数入口调用将被捕获为事件,函数退出调用也将被捕获。在这种情况下,如果需要,函数边界本身可以作为一个主题被捕获。但是,如果函数边界没有被检测(黑盒),那么函数执行仍然可能被捕获为一个“盲”事件,它与输入和输出主体和对象相关(稍后将详细讨论盲)。
事件序列表示事件相对于同一执行线程中的其他事件的逻辑顺序。这可能是逻辑时间,或者如果时间戳足够准确,可以从时间戳推断出序列,但这是不能保证的,这就是为什么我们保持序列。
Objects 对象通常表示数据源和接收器,这些数据源和接收器可能包括套接字、文件、注册表项、内存和变量,以及通常可以作为事件输入和/或输出的任何数据。此模型扩展了对象的定义,以显式地捕获到事件的数据输入和输出流。我们最初决定将事件参数视为第一类对象(而不是事件实体的属性),其中每个对象可能有自己的来源,再次显式地显示从输入到输出的流。然而,稍后我们就不再讨论这个问题了。
我们确定了一些关键的对象属性。对象时间戳是创建时间。文件url是它的本地或远程路径/位置。文件有版本号。随着文件的更新,一个新的文件对象将创建一个新的版本号。
瞬态数据:其中一个主要讨论点是,我们是否应该将参数建模为对象,还是应该显式地将瞬态数据(如参数)与更持久的数据(如文件)区分开来。我们一致认为区分这两种属性更有意义,主要是因为它们具有非常不同的属性(参数不具有所有权和路径属性,而具有值属性)。最初,我们决定将一个值建模为第一类实体,就像对象一样,可以有标签(在§2中讨论)和影响(并被事件影响)事件。我们后来决定(在0.7版中)将值作为事件的属性,而不是第一类实体,因为值是一次性的结构,只在事件中出现,在执行过程中不会被引用。标记和跟踪系统也不跟踪值的水平。此外,将值作为第一类实体处理需要为每个值分配一个唯一的ID,该ID不能伸缩,因为值可以具有字节粒度。因此,我们决定将值作为事件的属性。
粒度和类型:我们讨论了在不同粒度表示对象。为了显式地区分不同类型的对象,我们还决定将抽象对象子类化到file、NetworkFlow、Memory、PacketSocket、RegistryKey和IPC对象中,而不是使用对象实体的type属性来建模这些对象。这主要是为了保持模型整洁,因为对象类型之间的属性集是不同的。我们包含一个RegistryKey对象来建模windows注册表密钥存储。最后,我们还讨论了是否应该将手机传感器(GPS、相机、陀螺仪等)建模为一个独立于Object的实体,称为Resource。这里的一个观察结果是,例如Android中的传感子系统可能有足够的差异来保证这种区别。相反的观点是,Android底层使用的是linux,人们可以通过对象抽象来摆脱所有这样的数据设备。我们决定只区分少数对象类型(上面提到的那些),其他所有对象都使用通用的srcink对象,它是有类型的(例如,传感器,摄像机等)。
Provenance and Tags 我们使用事件作为连接主体和对象的关系,明确地为对象和主体之间的关系建模。这些边在图中直接表示来源(控制流)。用于捕获数据流的更细粒度的补充方法使用了用ProvenanceTagNode编码的标记。
来源标记定义了对特定数据源(输入)的源依赖。标记标识符通常绑定到一个源,跟踪系统使用它来捕获对该源输入的依赖关系。ProvenanceTagNode为值定义了一个来源步骤(即从源读取或写入到接收器)、对值的前一个来源标记的引用(prevTagId),以及导致该标记的tagId的标记操作(操作码)。标签依赖关系图提供了细粒度的数据流跟踪,将所有贡献事件拼接在一起。标签直接与事件参数相关联,即与值相关联,作为V值实体的属性,用于细粒度的污染跟踪。每个值可以有一个与组成值的字节相关联的标记数组。
例如,考虑程序A,它拍摄一张照片并将其写入文件F1。然后程序B从文件F1中读取图像数据,添加GPS定位数据,并将结果写入文件F2。在编写时,可以发出来源图,显示F2中的数据对两个来源(摄像机和GPS)的粒度依赖性。写入F2的数据的来源标记引用两个源标记的联合,而每个引用的前一个标记引用从源读取数据的读取事件,显示完整的(控制和数据)流。
Control Records TimeMarkeris用于描述数据流中的时间段,以帮助用户了解其在数据流中的当前读取位置。EndMarkerrecord标记数据流的结束。
3 Implementation and Performance Results
我们实现了一个版本化和类型化的模式,它整理了CDM概念模型。[3]中提供了CDM实现及其版本历史。该模式使用Apache Avro接口描述语言[13]指定。Avro IDL是一种用于编写Avro模式的高级语言。它为开发人员提供了一种熟悉的感觉,因为它类似于常见的编程语言,如Java、c++和Python。使用Avro的主要优点是它将模式与序列化数据解耦:在反序列化时应该对读者可用的读取器模式可能与写入器模式不同。这意味着在线上的序列化数据的大小更小,因为它不需要输入信息。更重要的是,模式可以随着时间的推移而发展,不依赖于数据,也不需要生成代码。
每个序列化的TCCDMDatum记录可以是以下任意一个:Host, Principal, ProvenanceT agNode, UnknownProvenanceNode, Subject, FileObject, IpcObject, RegistryKeyObject, PacketSocketObject, NetFlowObject, MemoryObject, SrcSinkObject, Event, UnitDependency, TimeMarker, EndMarker。每条记录包含它的类型,主机出版这个记录的唯一标识符,一个序列号,单调增加每次系统启动时,仪表源,生成的记录(例如,Java或原生Android, FreeBSD OpenBSM或dtrace Linux auditd或netfilter, Windows ETW,等等)。
为了避免反序列化歧义,这尤其会导致Python绑定的问题,我们要确保每个记录都有一组唯一的字段名,或者使用CDM的生产者在创建记录实例时至少使用一些唯一的可选字段。这样,不同类型的序列化记录在网络上看起来就不一样了。
Performance Results 我们主要通过标记和跟踪系统产生记录的吞吐量、分析技术消耗记录的吞吐量(图1)以及端到端延迟来评估CDM的性能。我们在此评估中的目标是确保基础设施支持的吞吐量远远超过标记和跟踪技术(分析技术)产生(消费)数据的速率,并确保CDM序列化/反序列化不是瓶颈。在整个分析过程中,我们使用Apache Kafka[14]作为数据处理底层。
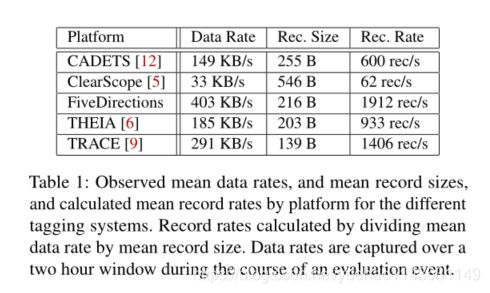
图3显示了使用CDM v20、Apache Avro 1.8.2和Kafka 1.1.0集群的Java生产者和消费者吞吐量,集群由3个代理组成,运行一个Kafka主题(一个分区复制到两个节点)。我们绘制了带有和不带有Avro以及带有和不带有TLS加密的序列化(反序列化)明文的生产者(消费者)吞吐量。生产者吞吐量不包括记录创建时间,其影响可以忽略不计。总之,对于表1所示的从33 KB/秒到400 KB/秒的标记和跟踪技术所期望的记录大小,我们可以维持超过10 MB/秒的吞吐量。这比预期的创纪录增长率高出了一个数量级。对于生产者,TLS加密对吞吐量有显著影响,而对于消费者,Avro反序列化有显著影响。最后,端到端延迟在2毫秒的量级上,这相对于检测算法的时间尺度可以忽略不计。

4 Conclusions
本文提出了一种通用数据模型、设计原理和开源实现。统一的数据模型使几种实时检测和取证分析技术能够使用在不同粒度和不同平台上运行的大量标记和跟踪技术所产生的起源事件。与现有的来源标准表示(如W3C PROV)不同,公共数据模型将事件及其复杂语义视为模型的第一类公民,并合并粒度来源标记以提高精度跟踪数据流。我们展示了单个生产者进程如何在Kafka队列上以超过10mb /秒的速度流化串行CDM记录,这超过了标记和跟踪技术流数据的实时数据速率。由于它是一个需要适应多种标记和跟踪技术的通用模型的本质,该模型被过度指定了。有几个机会可以针对特定的标记和跟踪技术调优和减少这个模型,以实现最佳效率,并减少语义不匹配。