(十四)全解MySQL之各方位事无巨细的剖析存储过程与触发器!
引言
本文为掘金社区首发签约文章,14天内禁止转载,14天后未获授权禁止转载,侵权必究!
前面的MySQL系列章节中,一直在反复讲述MySQL一些偏理论、底层的知识,很少有涉及到实用技巧的分享,而在本章中则会阐述MySQL一个特别实用的功能,即MySQL的存储过程和触发器。
在项目的业务开发中,每条
SQL语句不会太过复杂,通常就由几行SQL组成,但往往在一些复杂的业务需求下,SQL操作不会那么简单,有时写着写着,可能会编写出一条由几百行、甚至上千行SQL组成的语句,这种大SQL执行的效率通常会异常的缓慢,因此需要从各方面去尽可能的优化它,而存储过程则是专门为这类SQL而创造的,下面咱们一起来聊一聊它。
MySQL起初并不支持存储过程,而是到了MySQL5.0版本才支持存储过程的编写与执行,在MySQL中存储过程主要分为两类,一类是普通的存储过程,另一类则是触发器类型的存储过程,但如若你海不了解啥是触发器,就随我一点点往下看,好戏,开场啦!
一、初识MySQL的存储过程
Stored Procedure存储过程是数据库系统中一个十分重要的功能,使用存储过程可以大幅度缩短大SQL的响应时间,同时也可以提高数据库编程的灵活性,但一般的开发者很少去主动编写存储过程,通常都会由专门的数据库工程师去负责撰写,但大多数中小型企业并不会将岗位划分的太过细致,因此作为一个合格的后端开发,对于这块内容也需要有一定程度上的掌握。
先来简单的聊一聊啥是存储过程吧,存储过程是一组为了完成特定功能的SQL语句集合,使用存储过程的目的在于:将常用且复杂的SQL语句预先写好,然后用一个指定名称存储起来,这个过程经过MySQL编译解析、执行优化后存储在数据库中,因此称为存储过程。当以后需要使用这个过程时,只需调用根据名称调用即可。
其实存储过程和
Java中的方法、其他语言中的函数十分类似,也就是先将一堆代码抽象成一个函数,当之后需要使用时,不需要再重写一遍代码,而是直接根据名称调用相应的函数/方法即可。
对比常规的SQL语句来说,普通SQL在执行时需要先经过编译、分析、优化等过程,最后再执行,而存储过程则不需要,一般存储过程都是预先已经编译过的,这就好比咱们在讲《JVM-执行引擎》聊到过的JIT即时编译器一样,为了提升一些常用代码的执行效率,JIT会将热点代码编译成本地机器码,以此省略解释器翻译执行的步骤,从而做到提升性能的目的。
但使用存储过程有利有弊,具备的优点如下:
复用性:存储过程被创建后,可以在程序中被反复调用,不必重新编写该存储过程的
SQL语句,同时库表结构发生更改时,只需要修改数据库中的存储过程,无需修改业务代码,也就意味着不会影响到调用它的应用程序源代码。
灵活性:普通的
SQL语句很难像写代码那么自由,而存储过程可以用流程控制语句编写,也支持在其中定义变量,有很强的灵活性,可以完成复杂的条件查询和较繁琐的运算。
省资源:普通的
SQL一般都会存储在客户端,如Java中的dao/mapper层,每次执行SQL需要通过网络将SQL语句发送给数据库执行,而存储过程是保存在MySQL中的,因此当客户端调用存储过程时,只需要通过网络传送存储过程的调用语句和参数,无需将一条大SQL通过网络传输,从而可降低网络负载。
高性能:存储过程执行多次后,会将
SQL语句编译成机器码驻留在线程缓冲区,在以后的调用中,只需要从缓冲区中执行机器码即可,无需再次编译执行,从而提高了系统的效率和性能。
安全性:对于不同的存储过程,可根据权限设置执行的用户,因此对于一些特殊的
SQL,例如清空表这类操作,可以设定root、admin用户才可执行。同时由于存储过程编写好之后,对于客户端而言是黑盒的,因此减小了SQL被暴露的风险。
但还是那句话,凡事有利必有弊,存储过程也会带来一些之前不存在的问题:
CPU开销大:如果一个存储过程中涉及大量逻辑运算工作,会导致
MySQL所在的服务器CPU飙升,因而会影响正常业务的执行,有可能导致MySQL在线上出现抖动,毕竟MySQL在设计时更注重的是数据存储和检索,对于计算性的任务并不擅长。
内存占用高:为了尽可能的提升执行效率,因此当一个数据库连接反复调用某个存储过程后,
MySQL会直接将该存储过程的机器码放入到连接的线程私有区中,当MySQL中的大量连接都在频繁调用存储过程时,这必然会导致内存占用率同样飙升。
维护性差:一方面是过于复杂的存储过程,普通的后端开发人员很难看懂,毕竟存储过程类似于一门新的语言,不同语言之间跨度较大。另一方面是很少有数据库的存储过程支持
Debug调试,MySQL的存储过程就不支持,这也就意味着Bug出现时,无法像应用程序那样正常调试排查,必须得采取“人肉排查”模式,即一步步拆解存储过程并排查。
基于上述原因,咱们在不必要使用存储过程的情况下,就尽量减少存储过程的编写,除非特定的业务需求导致不得不用时,再将注意力转向这块。不过话虽这么说,但少量的存储过程并不会造成太大影响,除非你没事在MySQL中写几十、上百个存储过程,否则基本上不会导致“不良反应”出现。
对存储过程有了基本认知后,接着来聊一聊MySQL中该如何定义、调用及管理存储过程。
二、存储过程的定义、调用与管理
前面简单提过一嘴,存储过程类似于一门新的语言,在其中存在专门的语法规则,因此想要撰写一个高效的存储过程之前,我们得先掌握存储过程中的一些基本语法,例如创建、变量、流程控制、循环等基础语法。
但好在大家都并非刚学编程的小白,因此这些在其他语言中都存在的语法,其实我们只需要搞清楚在
MySQL中的关键字即可,所以上手速度还是非常快的,那么Les't Go~
2.1、存储过程的语法
先来看看存储过程的定义语法,如下:
DELIMITER $
-- 创建的语法:指定名称、入参、出参
CREATE
PROCEDURE 存储过程名称(返回类型 参数名1 参数类型1, ....)
[ ...这里在后面讲... ]
-- 表示开始编写存储过程体
BEGIN
-- 具体组成存储过程的SQL语句....
-- 表示到这里为止,存储过程结束
END $
DELIMITER ;
复制代码实际上这个语法和其他语言定义函数/方法的过程类似,例如Java方法的定义:
访问修饰符 返回类型 方法名(参数类型 参数名称, ....){
// 方法体...
}
复制代码存储过程的BEGIN、END就类似于Java方法的{},用来区分起始和结束的边界。OK~,所有语言的函数/方法定义时,一般都会分为四类,如下:
- ①无参无返回。
- ②有参无返回。
- ③无参有返回。
- ④有参有返回。
而SQL的存储过程也不例外,同样也支持这四种定义,主要依赖于IN、OUT、INOUT三个关键字来区分:
- 定义存储过程时,没有入参也没有出参,代表无参无返回类型。
- 定义存储过程时,仅定义了带有
IN类型的参数,表示有参无返回类型。 - 定义存储过程时,仅定义了带有
OUT类型的参数,表示无参有返回类型。 - 定义存储过程时,同时定义了带有
IN、OUT类型的参数,或定义了带有INOUT类型的参数,表示有参有返回类型。
在上述给出的语法体中,最开始有一个DELIMITER $是什么意思呢?
其实这表示指定结束标识,在
MySQL中默认是以;分号作为一条语句的结束标识,因此当存储过程的过程体中,如果包含了SQL语句,SQL语句以;结束时,MySQL会认为存储过程的定义也结束了,过程体就会和;结束符冲突,所以一般咱们要重新定义结束符,例如DELIMITER $,表示以$作为结束标识,只有当MySQL识别到$符时,才会认为结束了。
但记得在结束之后,要再次把结束符改回;,即DELIMITER ;。
还有一条[...这里在后面讲...]是啥意思呢?这是指定存储过程的约束条件,取值范围有很多,如下:
- ①
LANGUAGE SQL - ②
[NOT] DETERMINISTIC - ③
{ CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } - ④
SQL SECURITY { DEFINER | INVOKER } - ⑤
COMMENT '....'
是不是看起来很头大?确实,我写起来也头大,但接着往下看,分别解释一下吧。
- ①说明存储过程中的过程体是否由
SQL语句组成。 - ②说明存储过程的返回值是否为固定的,没有
[NOT]表示为固定的,默认为非固定的。 - ③说明过程体使用
SQL语句的限制:CONTAINS SQL:表示当前存储过程包含SQL,但不包含读写数据的SQL语句。NO SQL:表示当前存储过程中不包含任何SQL语句。READS SQL DATA:表示当前存储过程中包含读数据的SQL语句。MODIFIES SQL DATA:表示当前存储过程中包含写数据的SQL语句。
- ④说明哪些用户可以调用当前创建的存储过程:
DEFINER:表示只有定义当前存储过程的用户才能调用。INVOKER:表示任何具备访问权限的用户都能调用。
- ⑤注释信息,可以用来描述当前创建的存储过程。
上述的五条分别和之前的五种取值范围一一对应,估计大家现在直接来看会有些懵逼,其实这些大概了解即可,无需过多关注,一般在写存储过程的时候不会加上这些条件,通常都是使用默认的。
2.1.1、存储过程的定义
上面刚刚了解了存储过程的基础语法,但多少有点犯迷糊,因此接下来简单的先写几个存储过程简单感受一下:
-- 查询用户表中的所有信息
select * from `zz_users`;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 黑熊 | 男 | 8888 | 2022-09-17 23:48:29 |
| 8 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:29 |
+---------+-----------+----------+----------+---------------------+
-- 查询用户表的字段结构
desc `zz_users`;
+---------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+-------+
| user_id | int(8) | NO | PRI | NULL | |
| user_name | varchar(255) | YES | MUL | NULL | |
| user_sex | varchar(255) | YES | | NULL | |
| password | varchar(255) | YES | | NULL | |
| register_time | varchar(255) | YES | | NULL | |
+---------------+--------------+------+-----+---------+-------+
复制代码下面会基于这张用户表,来设计几个需求,用来加强对存储过程的掌握度,一共四个案例:
- ①定义一个存储过程,查询用户表的所有用户信息。
- ②定义一个存储过程,接收一个用户名,查询用户的注册时间。
- ③定义一个存储过程,查询
ID=1的用户密码并返回。 - ④定义一个存储过程,接收一个用户名,返回该用户名对应的用户
ID。
这四个案例分别对应存储过程的四种类型,也就是分别演示IN、OUT、INOUT的用法,现在依次实践完成!
①查询用户表的所有用户信息
-- 改变结束标识为 $ 符号
DELIMITER $
CREATE
-- 定义存储过程的名称为:get_all_userInfo()
PROCEDURE get_all_userInfo()
BEGIN
-- 存储过程体:由一条查询全表的SQL组成
select * from `zz_users`;
-- 标识存储过程体结束
END $
-- 重置结束标识为 ; 符号
DELIMITER ;
复制代码上述定义了一个无参无返回的存储过程,接着来执行并调用一下该存储过程,如下:
CALL get_all_userInfo();
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 黑熊 | 男 | 8888 | 2022-09-17 23:48:29 |
| 8 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:29 |
+---------+-----------+----------+----------+---------------------+
复制代码所有存储过程都是通过CALL命令来调用,调用刚刚定义的存储过程后,显然将用户表的所有用户信息查询出来啦!
②接收一个用户名,查询用户的注册时间
上面定义的存储过程,即没有入参,也没有返回值,接着咱们来演示一下带有入参的存储过程:
-- 这里又将结束标识换成了 // 符号
DELIMITER //
CREATE
-- 在定义存储过程时,用 IN 声明了一个入参
PROCEDURE get_user_register_time(IN name varchar(255))
BEGIN
select `register_time` from `zz_users` where `user_name` = name;
END //
DELIMITER ;
复制代码上面这个存储过程中,使用IN声明了一个入参,其类型为varchar,接着来看看如何调用呢?
CALL get_user_register_time("竹子");
+---------------------+
| register_time |
+---------------------+
| 2022-09-14 16:17:44 |
+---------------------+
复制代码结果十分明显,达到了我们想要的效果,但在定义带有参数的存储过程时要注意:参数名必须在参数类型的前面,同时参数类型需要定义长度,也就是varchar(255),而并非varchar,否则低版本的MySQL会出现不兼容的问题。
③查询ID=1的用户密码并返回
上面掌握了IN的用法,接下来咱们瞅瞅OUT关键字的用法,可以用这个关键字指定返回值:
DELIMITER //
CREATE
-- 在定义存储过程时,用 OUT 声明了一个返回值
PROCEDURE get_user_password(OUT userPassword varchar(255))
BEGIN
select `password` into userPassword from `zz_users` where `user_id` = 1;
END //
DELIMITER ;
复制代码在上述这个过程中,当ID=1的用户密码被查询出来之后,会通过into关键字,将查询出的密码赋给userPassword,那这种带有返回值的存储过程又该如何调用呢?如下:
CALL get_user_password(@userPassword);
select @userPassword;
+---------------+
| @userPassword |
+---------------+
| 6666 |
+---------------+
复制代码没错,要调用时直接使用@符号,在调用的地方定义变量即可,调用完成后想要查看返回值,还需要手动查询一次调用时定义的变量。
但定义有返回值的存储过程时,有一点也要额外注意:返回值的数据类型一定要和表字段保持一致,否则有可能出现类型转换错误,毕竟不是所有的类型之间可以隐式转换。
④接收一个用户名,返回该用户名对应的用户ID
这个需求有两种实现方式:
- ①定义两个参数,一个
IN类型的,一个OUT类型的。 - ②使用
INOUT关键字来实现。
咱们这里主要是为了讲解,因此就采取第二种方式来实现,毕竟还没用过INOUT关键字,如下:
DELIMITER $
CREATE
-- 在定义存储过程时,用 OUT 声明了一个返回值
PROCEDURE get_user_id(INOUT parameters varchar(255))
BEGIN
select `user_id` into parameters from `zz_users` where `user_name` = parameters;
END $
DELIMITER ;
复制代码上述存储过程中,利用INOUT定义了一个参数parameters,在下面的存储过程体当中,即使用它作为查询参数,又使用它作为了保存返回值的变量,再来看看这个函数如何调用:
-- 先定义一个变量
set @parameters = "熊猫";
-- 将定义的变量在调用时传入
CALL get_user_id(@parameters);
-- 再次查询定义的变量
select @parameters;
+-------------+
| @parameters |
+-------------+
| 1 |
+-------------+
复制代码如果想要调用这类方法,咱们得先定义一个变量,然后在调用时传入,最后再次查询这个变量即可。
看到这里大家会发现,存储过程中的返回值,并不像正常语言中的
return,而是通过变量传递的方式来实现的,上述这个存储过程,就类似于Java中的这段代码:
public void getUserID(Object obj){
obj = 1;
}
Object obj = new Object("熊猫");
getUserID(obj);
System.out.println(obj);
复制代码本质上并没有return出结果,而是对传入的变量重新赋值,从而做到了值的传递。
OK~,刚刚介绍到了变量的概念,实际上在存储过程也存在这些基础语法,例如变量、判断、循环、游标等,接下来就聊一聊这些存储过程的基础语法。
2.1.2、系统变量和用户变量、局部变量
变量几乎是所有语言都支持的一种语法,存储过程也不例外,在MySQL中大体存在三种级别的变量,即系统变量、用户变量、局部变量,这三个不同级别的有效范围也不同,下面一起聊聊。
系统变量
在MySQL启动后,其内部也会存在许多的系统变量,系统的意思是指由MySQL定义的,而并非用户自己定义的,一般系统变量要么来自于MySQL编译期,要么来自于my.ini配置文件,对于具体拥有那些系统变量,可参考:MySQL官网文档-系统变量,这里就不做过多的赘述。
MySQL的系统变量也会分为两类,一类是全局级变量,一类是会话级变量,还记得在《MySQL事务篇-隔离机制》中,修改数据库隔离级别时的命令嘛?
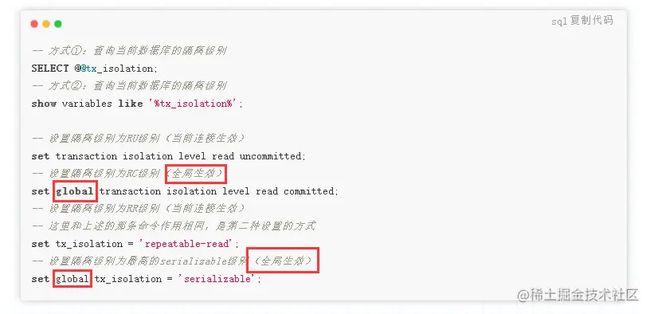
当在修改命令中加上global关键字,则代表修改全局级别的系统变量,如若不加或加上session关键字,则表示只修改当前会话的系统变量,这是啥意思呢?修改全局级别表示对所有连接都生效,而修改会话级别的变量,表示只对当前连接生效,在当前连接中修改系统变量的值之后,是不会影响其他数据库连接的。
对于系统变量,想要查看或修改,使用两个@@符号即可,例如:
-- 查看某个系统变量
select @@xxx;
-- 修改某个系统变量
set @@xxx = "xxx";
复制代码用户变量
系统变量并非咱们的重点,接着来瞧瞧用户变量,也就是自定义的变量,其实非常简单,如下:
set @变量名称 = 变量值;
select @变量名称;
复制代码相较于系统变量而言,用户变量仅仅少了一个@符号而已,不过上述用户变量的赋值,中间的=也可改为:=,其作用也是相同的。除此之外,用户变量的定义还可以和SQL组合,如下:
-- 将用户表的总行数赋值给 row_count 变量
select @row_count := count(*) from `zz_users`;
-- 将 user_id 的平均值赋给 avg_user_id 变量
select avg(user_id) into @avg_user_id from `zz_users`;
复制代码上述这两种方式,都可以创建一个用户变量,也就意味着但凡出现@符号时,MySQL都会将其识别为在定义变量。
局部变量
前面简单讲述了用户变量,但在存储过程中还存在一种名为局部变量的概念,这也就是类似于在Java的方法中定义的变量,有效范围只对当前方法体生效,而局部变量亦是同理,只对当前存储过程体有效,其他存储过程或外部是无法读取或操作局部变量的,定义方式如下:
DECLARE 变量名称 数据类型 default 默认值;
复制代码是不是有点眼熟?这跟通过SQL创建表时,声明表字段的语法相差无几,就前面多了一个DECLARE关键字,举个简单的例子,如下:
DECLARE message varchar(255) default "not message";
复制代码上述定义了一个名为message的局部变量,如果后续使用时未对其赋值,该变量的默认值为"not message"。
后续使用局部变量时,主要有两种赋值方式,如下:
-- 赋值方式一
SET message = 变量值;
SET message := 变量值;
-- 赋值方式二
select 字段名或函数 into message from 表名;
复制代码非常的简单,接着来结合存储过程一起熟悉一下用户变量和局部变量:
DELIMITER //
CREATE
-- 定义了一个 求两数之和 的存储过程
PROCEDURE add_value(IN number1 int(8), OUT result int(8))
BEGIN
-- 这里定义了一个局部变量:number2,默认值为 666
DECLARE number2 int(8) default 666;
-- 将两个数字相加,计算得到的和放入用户变量 result 中
SET result := number1 + number2;
END //
DELIMITER ;
-- 定义一个用户变量,接收调用存储过程后得到的和
SET @result = 0;
-- 调用存储过程,传入一个数字 888 以及接收结果的 result 变量
CALL add_value(888,@result);
-- 查询计算后的和
SELECT @result;
+---------+
| @result |
+---------+
| 1554 |
+---------+
复制代码对于局部变量的定义,必须要写在BEGIN、END之间,否则会提示语法错误,这一点需要在使用时注意,上述定义的存储过程,其工作十分简单,即计算两数之和并返回,具体的过程参考源码中的注释,经过这个例子相信大家对存储过程中的变量能够进一步掌握。
2.1.3、流程控制 - IF判断与CASE分支
上面简单掌握几种变量的语法后,接着再来说说存储过程中的流程控制,也就是条件判断、循环、跳转等语法,先来聊一聊所有语言都有的条件判断。
条件判断:IF
在存储过程中,主要有两类条件判断的语法,即IF、CASE,先来说说常见的IF,语法如下:
IF 条件判断 THEN
-- 分支操作.....
ELSEIF 条件判断 THWN
-- 分支操作.....
ELSE
-- 分支操作.....
END IF
复制代码上述这段if判断语句基本上和其他语言中相差无几,当一个条件判断成立时,就会进入相应的分支中执行,否则程序会跳过该分支继续往下执行,举个案例快速过一下:
DELIMITER $
CREATE
PROCEDURE if_user_age(IN age int, OUT msg varchar(255))
BEGIN
IF age < 18 THEN
SET msg := '未成年';
ELSEIF age = 18 THEN
SET msg := '刚成年';
ELSE
SET msg := '已成年';
END IF;
END $
DELIMITER ;
复制代码上面定义了一个判断年龄的存储过程,调用时需要传入一个age值,内部会对传入的值进行判断,最后将判断结果写入到msg变量中,调用方式如下:
SET @msg := "Not Data";
CALL if_user_age(16,@msg);
SELECT @msg;
+---------+
| @msg |
+---------+
| 未成年 |
+---------+
CALL if_user_age(18,@msg);
SELECT @msg;
+---------+
| @msg |
+---------+
| 刚成年 |
+---------+
CALL if_user_age(25,@msg);
SELECT @msg;
+---------+
| @msg |
+---------+
| 已成年 |
+---------+
复制代码OK~,存储过程中分支判断的语法,与常规编程语言中的if、else if、else无太大差异,接着来看看CASE的语法。
分支判断:CASE
存储过程中的CASE语法,就类似于Java中的switch语法,但CASE有两种写法,如下:
-- 第一种语法
CASE 变量
WHEN 值1 THEN
-- 分支操作1....
WHEN 值2 THEN
-- 分支操作2....
.....
ELSE
-- 分支操作n....
END CASE;
-- 第二种语法
CASE
WHEN 条件判断1 THEN
-- 分支操作1....
WHEN 条件判断2 THEN
-- 分支操作2....
.....
ELSE
-- 分支操作n....
END CASE;
复制代码举个例子快速过一下,这里就演示第一种语法,毕竟第二种方式就等同于多重IF判断:
DELIMITER $
CREATE
PROCEDURE test_case(IN n int)
BEGIN
CASE n
WHEN 1 THEN
select '竹子真的帅';
WHEN 2 THEN
select '熊猫真好看';
ELSE
select '两个都好看';
END CASE;
END $
DELIMITER ;
复制代码调用结果如下(上面的SELECT 'xxx'就类似于其他语言的print输出):
CALL test_case(1);
+---------------+
| 竹子真的帅 |
+---------------+
| 竹子真的帅 |
+---------------+
CALL test_case(2);
+---------------+
| 熊猫真好看 |
+---------------+
| 熊猫真好看 |
+---------------+
CALL test_case(3);
+---------------+
| 两个都好看 |
+---------------+
| 两个都好看 |
+---------------+
复制代码调用结果很明显,基本上与Java中的switch效果相同!OK~,接着来看看存储过程中的循环语法。
2.1.4、循环:LOOP、WHILE、REPEAT
编程中常见的循环有for、foreach、while、do-while四大类,而存储过程中也支持LOOP、WHILE、REPEAT三类循环,接着挨个简单过一下。
LOOP循环
先简单聊一聊LOOP,语法如下:
循环名称:LOOP
-- 循环体....
END LOOP 循环名称;
复制代码在存储过程的循环,与其他编程语言的循环并不同,在存储过程中可以给每个循环取一个名字,后续可以基于这个名字来跳出循环,但如果想要跳出一个循环,还需要结合LEAVE这个关键字,否则会令循环成为一个死循环,无限执行下去,现在先上个简单的例子:
DELIMITER $
CREATE
PROCEDURE test_loop(IN num int)
BEGIN
-- 定义一个局部变量:num
DECLARE num int(8) default 1;
add_loop:LOOP
-- 一直循环对num + 1
SET num = num + 1;
-- 当num被加到100时
IF num >= 100 THEN
-- 跳出循环
LEAVE add_loop;
END IF;
END LOOP add_loop;
select num;
END $
DELIMITER ;
复制代码这个存储过程很简单,就是利用LOOP循环对局部变量num进行累加,加到100时退出循环,最后查询一下num值,调用结果如下:
CALL test_loop();
+--------+
| num |
+--------+
| 100 |
+--------+
复制代码效果跟想象的差不多,num最终值为100,OK,接着看看其他的循环。
WHILE循环
WHILE循环的语法也和前面的LOOP循环类似,如下:
【循环名称】:WHILE 循环条件 DO
-- 循环体....
END WHILE 【循环名称】;
复制代码其实对于这个循环名称,可以写也可以不写,主要是利用名称来做跳转,这点后续说,先来举个简单的例子感受一下WHILE循环:
DELIMITER $
CREATE
PROCEDURE test_while()
BEGIN
-- 定义一个局部变量:num
DECLARE num int(8) default 1;
-- 循环对num=1,当<=10时退出
WHILE num <= 10 DO
-- 一直循环对num + 1
SET num = num + 1;
END WHILE;
-- 最后查询一下num值
SELECT num;
END $
DELIMITER ;
复制代码这个存储过程也是一个对num变量不断做+1的循环,调用结果如下:
CALL test_while();
+-------+
| num |
+-------+
| 11 |
+-------+
复制代码但此时来看,答案为何是11而并不是10呢?因为循环条件是num<=10,也就是当num=10的时候,依旧会循环一次,num又被+1,所以最终num=11。
REPEAT循环
REPEAT循环和之前两个循环不同,在这种循环中,有专门控制循环结束的语法,如下:
【循环名称】:REPEAT
-- 循环体....
UNTIL 结束循环的条件判断
END REPEAT 【循环名称】;
复制代码上述语法种,当UNTIL关键字之后的条件为真时,循环就会终止,OK,来看个用例:
DELIMITER $
CREATE
PROCEDURE test_repeat()
BEGIN
-- 定义一个局部变量:num
DECLARE num int(8) default 1;
REPEAT
SET num = num + 1;
UNTIL num>=10
END REPEAT;
-- 最后查询一下num值
SELECT num;
END $
DELIMITER ;
复制代码存储过程和之前的循环案例相同,也就是对num做累加,调用结果如下:
CALL test_repeat();
+-------+
| num |
+-------+
| 10 |
+-------+
复制代码嗯!?此时num=10是啥原因呢?因为当num>=10时会停止循环,当num被累加到10后就触发了终止条件,因此最终num=10。
OK~,到这里就简单的过了三种循环的基本语法,其中并未涉及太多的案例实操,毕竟这些循环的用法和正常编程语言并无太大差异,所以简单演示语法即可,其他的根据业务来编写循环体即可。
接着来看看存储过程中的跳转语法,其实在之前的LOOP循环中简单的用过,下面一起聊一聊。
2.1.5、跳转:LEAVE、ITERATE
LEAVE、ITERATE两个跳转的关键字,其实本质上就和Java中的break、continue类似,LEAVE主要功能是结束循环体,当执行循环体时遇到了LEAVE关键字,就会结束当前循环。而ITERATE则是跳出本次循环,继续下次循环的意思,作用与continue相同,接着举个案例来简单的实验一下。
-- 测试LEAVE关键字终止循环
DELIMITER $
CREATE
PROCEDURE test_leave()
BEGIN
-- 定义一个局部变量:num
DECLARE num int(8) default 1;
add_while:WHILE TRUE DO
-- 对num持续做+1
SET num = num + 1;
-- 如果num=10,用LEAVE终止循环
IF num = 10 THEN
LEAVE add_while;
END IF;
END WHILE add_while;
-- 最后查询一下num值
SELECT num;
END $
DELIMITER ;
复制代码依旧还是这个令人熟悉的例子,在这里咱们通过WHILE TRUE的方式开启了一个死循环,后续利用LEAVE来终止循环,调用结果如下:
CALL test_leave();
+-------+
| num |
+-------+
| 10 |
+-------+
复制代码最终num=10,这是因为当num=10的时候,就会执行LEAVE add_while;语句,会通过LEAVE关键字终止名为add_while的循环。
存储过程中的这点设计的很不错,在编写循环结构时,由于可以为每个循环命名,因此后续要跳出、终止某个循环时,可以直接通过循环的名称来跳转,在循环嵌套的情况下,这点尤为好用!
-- 测试ITERATE关键字跳出循环
DELIMITER $
CREATE
PROCEDURE test_iterate()
BEGIN
-- 定义一个局部变量:num
DECLARE num int(8) default 0;
-- 定义一个局部变量用来统计偶数和
DECLARE even_sum int(8) default 0;
sum_while:WHILE num <= 100 DO
-- 对num持续做+1
SET num = num + 1;
-- 如果num=10,用LEAVE终止循环
IF num % 2 = 0 THEN
SET even_sum = even_sum + num;
ELSE
-- 如果num不为偶数则跳过本次循环
ITERATE sum_while;
END IF;
END WHILE sum_while;
-- 最后查询一下偶数之和
SELECT even_sum;
END $
DELIMITER ;
复制代码上述这个存储过程作用也很简单,首先开启一个循环遍历1~100,接着对100以内的所有偶数求和,如果num%2=0则表示为偶数,将结果累加到even_sum变量中,不为0则通过ITERATE关键字跳出本次循环,继续下次循环,最终调用结果如下:
+------------+
| even_sum |
+------------+
| 2550 |
+------------+
复制代码结果确实达到了咱们想要的效果!100内的偶数之和确实为2550。OK,最后再了解一下存储过程中的游标即可。
2.1.6、存储过程的游标
游标是所有数据库的存储过程中,很重要的一种特性,它可以对一个结果集中的数据按条处理,也就意味着原本查询出的数据是一个整体性质的集合,而使用游标可以对该集合中的数据逐条处理,在使用游标时一般都会遵循下述四步:
-- ①声明(创建)游标
DECLARE 游标名称 CURSOR FOR select ...;
-- ②打开游标
OPEN 游标名称;
-- ③使用游标
FETCH 游标名称 INTO 变量名称;
-- ④关闭游标
CLOSE 游标名称;
复制代码观察游标的声明语法应该会发现,它和创建局部变量的方式类似,但后面会加上CURSOR FOR关键字来表明创建的是游标,OK~,接着来个简单的案例感受一下游标的使用,需求如下:
计算用户表中
user_id最大的前N个奇数ID之和。
这个需求听起来似乎有些不合常理,确实有些奇葩哈,但主要是为了演示游标的用法,因此就随意编造了一个需求,实现如下:
DELIMITER //
CREATE
PROCEDURE id_odd_number_sum(IN N int(8), OUT sum int(8))
BEGIN
-- 声明局部变量:
-- uid:用于记录每一个user_id
-- odd_id_count:记录奇数ID的个数
-- odd_id_sum:记录奇数ID的和
DECLARE uid int(8) DEFAULT 0;
DECLARE odd_id_count int(8) DEFAULT 0;
DECLARE odd_id_sum int(8) DEFAULT 0;
-- 声明一个游标:存储倒序的user_id结果集
DECLARE uid_cursor CURSOR FOR select user_id from zz_users order by user_id desc;
-- 打开游标
OPEN uid_cursor;
-- 使用游标
REPEAT
-- 将游标中的每一条user_id值,赋给user_id变量
FETCH uid_cursor INTO uid;
-- 如果当前user_id是奇数,则将ID值累加到sum中
IF uid % 2 != 0 THEN
SET odd_id_count = odd_id_count + 1;
SET odd_id_sum = odd_id_sum + uid;
END IF;
-- 根据传入的N来决定循环的次数
UNTIL odd_id_count >= N END REPEAT;
-- 将前N个奇数ID之和赋给外部变量:sum
SET sum = odd_id_sum;
-- 关闭游标
CLOSE uid_cursor;
END //
DELIMITER ;
复制代码代码的具体逻辑参考上述注释,最终调用结果如下:
select * from zz_users;
+---------+-----------+----------+----------+---------------------+
| user_id | user_name | user_sex | password | register_time |
+---------+-----------+----------+----------+---------------------+
| 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
| 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
| 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
| 4 | 黑熊 | 男 | 8888 | 2022-09-17 23:48:29 |
| 8 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:29 |
+---------+-----------+----------+----------+---------------------+
CALL id_odd_number_sum(2,@sum);
select @sum;
+------+
| num |
+------+
| 4 |
+------+
复制代码表中总共存在1、3这两个奇数ID,然后调用存储过程时传入2,表示获取前两个奇数ID之和,最终结果为4(1+3),显然达到了咱们的需求,在这个过程中我们利用了游标对order by之和的结果集,其中的每个user_id进行了逐条处理、逐条判断,从而完成了前面给出的需求。
2.1.7、存储过程语法小结
到这里,咱们介绍了存储过程中的一些基本语法,但大家想要彻底熟悉每种语法,定然需要多加练习,毕竟“纸上得来终觉浅,绝知此事要躬行”,这类实操性质的知识,自己多练方能真正掌握,但其实存储过程中还有错误处理机制,就类似于Java中的异常机制一样,但略微有些鸡肋,因此不再展开讲解,感兴趣的小伙伴可自行研究~
数据库系统中除开存储过程外,还有一种名为存储函数的概念,它和存储过程类似,但又有些不同,这里也不再展开阐述,有兴趣的小伙伴也可以自己去研究一下,毕竟存储过程也好,存储函数也罢,如若并非专门做数据库开发的岗位,一般接触都比较少。
接着一起来看看,作为客户端,又该如何调用编写好的存储过程呢?下面以Java-MyBatis为例。
2.2、客户端如何调用存储过程
一般在Java项目中,都会选择MyBatis作为操作数据库的ORM框架,那在其中调用存储过程的方式也很简单,如下:
{call 存储过程名(?, ?, ?)}
复制代码当需要调用存储过程中,只需要调用该xml对应的Dao/Mapper层接口即可。
2.3、存储过程的管理
所谓的存储过程管理,也就是指存储过程的查看、修改和删除,在MySQL中也提供了一系列命令,以便于咱们完成这些工作,如下:
SHOW PROCEDURE STATUS;:查看当前数据库中的所有存储过程。SHOW PROCEDURE STATUS WHERE db = '库名' AND NAME = '过程名';:查看指定库中的某个存储过程。SHOW CREATE PROCEDURE 存储过程名;:查看某个存储过程的源码。ALTER PROCEDURE 存储过程名称 ....:修改某个存储过程的特性。DROP PROCEDURE 存储过程名;:删除某个存储过程。
当然,也可以通过下述命令来查看某张表的存储过程:
-- 查看某张表的所有存储过程
select * from 表名.Routines where routine_type = "PROCEDURE";
-- 查看某张表的某个存储过程
select * from 表名.Routines where routine_name = "过程名" AND routine_type = "PROCEDURE";
复制代码还有其他更多的命令就不列举了,后续会出一章《MySQL命令大全》专门来罗列各类命令和函数。
2.4、存储过程的应用场景
存储过程到底该不该用,这点在《阿里开发手册》中是强制禁止使用的:

因为存储过程难以维护,同时拓展性和移植性都很差,因此大多数的开发规范中都会明令禁止使用,但存储过程能够带来的优势也极为明显,因此到底是否该用,这点仁者见仁智者见智,它是一把双刃剑,用的好其实能够给咱们带来不小的收益,那在那些地方适合用呢?
①插入测试数据时,一般为了测试项目,都会填充测试数据,往常是写
Java-for跑数据,但现在可以用存储过程来批量插入,它的效率会比用for循环快上无数倍,毕竟从Java传递SQL需要时间,拿到SQL后还要经过解析、优化....一系列工作,而用存储过程则不会有这些问题。
②对数据做批处理时,也可以用存储过程来跑,比如将一个表中的数据洗到另外一张表时,就可以利用存储过程来处理。
③一条
SQL无法完成的、需要应用程序介入处理的业务,尤其是组成起来SQL比较长时,也可以编写一个存储过程,然后客户端调用即可。
三、MySQL的触发器
触发器本质上是一种特殊的存储过程,但存储过程需要人为手动调用,而触发器则不需要,它可以在执行某项数据操作后自动触发,就类似于Spring-AOP中的切面一样,当执行了某个操作时就会触发相应的切面逻辑。
但触发器是在
MySQL5.0.2版本以后才开始被支持的,在此之前的MySQL并不能创建触发器,而触发器的触发条件是以事件为单位的,对于事件相信诸位一定不陌生,比如前端的按钮标签,就会经常用到它的点击事件,当用户点击某个按钮后,就会触发对应的点击函数,从而执行相应逻辑,而MySQL触发器亦是同理。
创建一个触发器的语法如下:
CREATE TRIGGER 触发器名称
{BEFORE | AFTER} {INSERT | UPDATE | DELETE} ON 表名
FOR EACH ROW
-- 触发器的逻辑(代码块);
复制代码从上述语法结构可以看出,对于每一个触发器而言,总共有插入、修改以及删除三种触发事件可选,同时也可以选择将触发器放在事件开始前,亦或事件结束后执行,这点几乎和AOP切面的切入点一模一样,同时也要记住:每个触发器创建后,必然是附着在一张表上的,因为在创建触发器的时候必须要指定表名,它会监控这张表上发生的事件,比如举个例子:
当我对
zz_users表创建了一个插入事件的后置处理器时,那么当每次表中插入数据后,都会自动触发一次相应的逻辑。
接下来依旧上个小案例,简单的感受一下触发器的用法,当然,依旧不要在乎需求是否合理,主要是感受触发器的用法:
-- 创建一张注册日志表
CREATE TABLE `register_log` (
-- 注册时间
`register_time` varchar(255),
-- 注册地
`register_address` varchar(255),
-- 注册设备
`register_facility` varchar(255)
)
ENGINE = InnoDB
CHARACTER SET = utf8
COLLATE = utf8_general_ci
ROW_FORMAT = Compact;
-- 在用户表上创建一个触发器
DELIMITER //
CREATE TRIGGER zz_users_insert_before
BEFORE INSERT ON zz_users
FOR EACH ROW
BEGIN
insert into `register_log` values(NOW(),"北京市海淀区","IOS");
END //
DELIMITER ;
复制代码上述案例中,对zz_users用户表建立了一个插入后置触发器,也就是当用户表中插入一条数据时,会向注册日志表中自动添加一条注册日志,测试效果如下:
-- 向用户表插入一条用户记录
INSERT INTO `zz_users` VALUES(9,"棕熊","男","0369","2022-10-17 23:48:29");
-- 查询注册日志表
select * from `register_log`;
+---------------------+--------------------+-------------------+
| register_time | register_address | register_facility |
+---------------------+--------------------+-------------------+
| 2022-10-18 18:52:50 | 北京市海淀区 | IOS |
+---------------------+--------------------+-------------------+
复制代码刚刚并未手动插入注册日志表的数据,但会发现:当用户表中插入一条数据时,会自动触发创建的插入后置触发器,这个效果相信了解过切面编程的小伙伴都不陌生。
但此时有个小问题,我们可以为一张表的某个事件创建触发器,但在触发器中有没有办法拿到当前操作的数据呢?比如在
insert事件中能否拿到插入的数据?update事件中能否拿到修改前后的数据?答案是可以的,在触发器中有NEW、OLD这两个关键字。
3.1、触发器的NEW、OLD关键字
在触发器中,NEW表示新数据,OLD表示老数据,各类型的事件如下:
insert插入事件:NEW表示当前插入的这条行数据。update修改事件:NEW表示修改后的新数据,OLD表示修改前的老数据。delete删除事件:OLD表示删除前的老数据。
这样似乎有些令人犯迷糊呀,举个简单的例子,以用户表的修改事件为例:
-- 执行的修改语句
update `zz_users` set user_name = "粉熊" and user_sex = "女" where user_id = 9;
-- 用户表修改事件的触发器
DELIMITER //
CREATE TRIGGER zz_users_update_before
BEFORE UPDATE ON zz_users
FOR EACH ROW
BEGIN
DECLARE new_name varchar(255);
DECLARE old_name varchar(255);
-- 可以通过 NEW 关键字拿到修改后的新数据(粉熊)
SET new_name := NEW.user_name;
-- 可以通过 OLD 关键字拿到修改前的老数据(棕熊)
SET old_name := OLD.user_name;
END //
DELIMITER ;
复制代码经过上述这个例子之后,大家应该更能理解NEW、OLD两个关键字,由于这两个关键字存储,它能够使触发器更为灵活~
为啥说触发器是一种特殊的存储过程呢?因为本质上触发器中所用的语法,和存储过程完全是一模一样的,只是存储过程需要手动调用,而触发器则是根据事件自动触发。
触发器的可以用于一些特殊的业务场景,比如需要在写数据前做数据安全性检测、又或者是洗数据时需要效验数据完整性、正确性、又或者是数据的备份和同步等这类需求。
3.2、触发器的管理
SHOW TRIGGERS;:查看当前数据库中定义的所有触发器。SHOW CREATE TRIGGER 触发器名称;:查看当前库中指定名称的触发器。SELECT * FROM information_schema.TRIGGERS;:查看MySQL所有已定义的触发器。DROP TRIGGER IF EXISTS 触发器名称;:删除某个指定的触发器。
四、总结
OK~,本篇到这里就接近尾声了,其实原本是不打算写存储过程与触发器这一章的,毕竟更多的偏向数据库基础,因此放在《全解MySQL数据库》这个定位于数据库进阶的专栏中,略微会有些不合适,但存储过程和触发器很多小伙伴也未了解过这块知识,因此还是写了本章,补齐大家对这块的空缺。
但存储过程一般在线上要少用,或者要用在合适的位置,毕竟曾说过它是一把双刃剑,有利有弊,因此线上的存储过程尽量不要太多,主要可将其用在一些复杂、特殊的业务场景下~