CTR预估 论文精读(十三)--Behavior Sequence Transformer for E-commerce Recommendation in Alibaba(BST)
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba 论文解读
0. 摘要
In this paper, we propose to use the powerful Transformer model to capture the sequential signals underlying users’ behavior sequences for recommendation in Alibaba.
1. 创新点
其核心创新点是建模用户的行为序列信息,使用 Transformer 中的 self-attention 来学习用户行为序列中每个 item 的更深层的表征(对比 Target Attention 捕获之前点击的 item 和目标 item 之间的相似性);
针对推荐场景中 position embedding,采用了时间戳 embedding 的形式,时间戳的计算方式为: pos ( v i ) = timestamp ( v t ) − timestamp ( v i ) \operatorname{pos}(v i)=\operatorname{timestamp}\left(v_{t}\right)-\operatorname{timestamp}\left(v_{i}\right) pos(vi)=timestamp(vt)−timestamp(vi),其中 v i v_{i} vi 表示用户点击序列中的第i个item, v t v_{t} vt 表示当前候选 item。
BST 模型通过 Transformer 模型来捕捉用户历史行为序列中的各个 item 的关联特征,与此同时,加入待预测的 item 来达到抽取行为序列中的商品与待推荐商品之间的相关性。
2. 行为序列建模
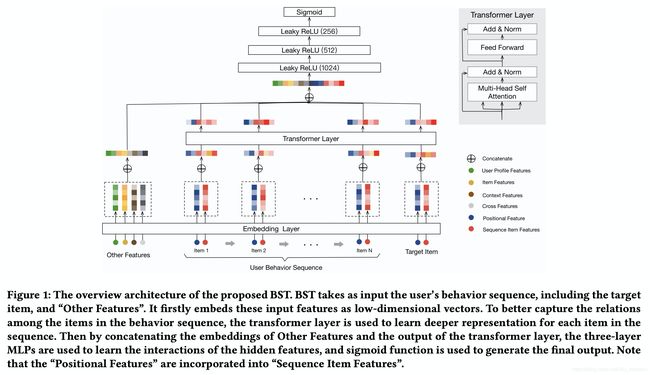
2.1 用户行为序列 (UBS: User Behavior Sequence)
用户行为序列 (UBS: User Behavior Sequence) 蕴含了可以刻画用户兴趣的丰富信息,说它是推荐广告界的一个兵家必争之地也毫不夸张。阿里相关团队(特别是阿里妈妈广告团队)在用户行为序列上就是一个资深玩家,近两年针对UBS发表了很多优质paper。大部分的UBS建模方式可归结为:
- 朴素简单的 sum/mean pooling,工业实践中效果其实还不错。
- weight pooling,关键点是 weight 的计算方式。例如经典模型 DIN 使用注意力机制来捕获候选 item 与用户点击 item 序列之间的相似性作为 weight。
- RNN类,考虑时序信息。例如阿里妈妈随后利用 GRU 捕捉用户行为序列信息,将 DIN 升级为DIEN。
注:用户行为序列建模并未在该论文之前没有,比如阿里的 DIEN 等,都是很有代表性的工作,该论文并未进行对比;
引入 self-attention 的原因:
随着 Transformer 在 很多NLP任务中的表现超过RNN,相比RNN也有可并行等独特优势,利用 Transformer 替代RNN 捕捉 序列信息是一个很自然的idea,这也是本文的动机。用户行为序列 + Transformer (更准确地说,应该是Transformer中的 Multi-head Self-attention ),两者天然地很搭。
Transformer 的主要优点是,通过 self-attention 机制能更好地捕获句子中单词之间的依赖性。直观地说,用户行为序列中 item 之间的“依赖关系”可以通过 Transformer 抽取。(self-attention 学习 item 间的依赖关系,对比 Target Attention attention 捕获目标 item 和先前点击的 item 之间的相似性);
因此,作者提出了在淘宝电商推荐中的用户行为序列 Transformer(BST)。离线实验和在线 A/B 测试表明,BST 与现有方法相比有明显优势。目前 BST 已经部署在淘宝推荐的 rank 阶段,每天为数亿消费者提供推荐服务。
2.2 引入 self-attention
BST 将用户的行为序列作为输入,包括目标 item 和其他特征。它首先将这些输入特征嵌入为低维向量。为了更好地捕获行为序列中 item 之间的关系,Transformer 层用于学习序列中每个 item 的更深层次的表示。然后通过连接其他特征的嵌入和 Transformer 层的输出,三层的 MLP 用于学习隐藏特征的交互作用,Sigmoid 函数用于生成最终的输出。
位置嵌入: 在《Attention is all you need》论文中,作者提出了一种位置嵌入来捕获句子中的顺序信息。同样,顺序也存在于用户的行为序列中。因此,我们添加“位置”作为 bottom layer 中每个 item 的输入特征,然后将其投射为低维向量。注意,item v i v_i vi 计算方式为: pos ( v i ) = timestamp ( v t ) − timestamp ( v i ) \operatorname{pos}(v i)=\operatorname{timestamp}\left(v_{t}\right)-\operatorname{timestamp}\left(v_{i}\right) pos(vi)=timestamp(vt)−timestamp(vi),然后将其投射为低维向量,其中 v i v_{i} vi 表示用户点击序列中的第i个item, v t v_{t} vt 表示当前候选item。
论文说明在淘宝首猜场景中,该方法优于《Attention is all you need》论文中使用的 sin 和 cos 函数。
注:请注意,一个 item 往往有数百个特征,但是,在行为序列中选择全部来表征这个 item 代价太大。正如之前的工作《Billion-scale commodity embedding for e-commerce recommendation in alibaba》介绍,item_id 和 category_id 对于性能来说已经足够好了;
3. Transformer layer
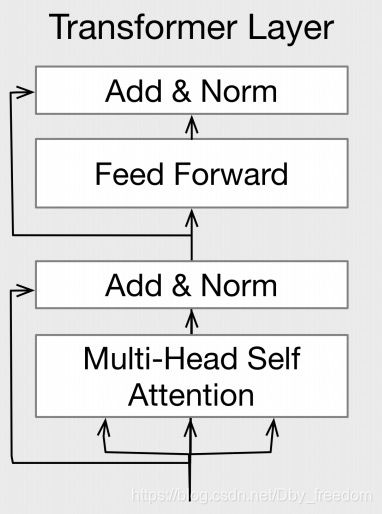
理解了Multi-head Attention,BST 也就懂了,BST 其实就是拿带时序位置信息的 Multi-head Attention, 用在用户历史点击的 item 序列上。那怎么显式引入时序信息呢? 方法也很简单,引入 position embedding。
作者尝试了Transformer原文中 sin/cos 函数的位置嵌入,发现效果不好,最终采取序列 item 与候选 item 时间差 embedding 的计算方式:
pos ( v i ) = timestamp ( v t ) − timestamp ( v i ) \operatorname{pos}(v i)=\operatorname{timestamp}\left(v_{t}\right)-\operatorname{timestamp}\left(v_{i}\right) pos(vi)=timestamp(vt)−timestamp(vi)
其中 v i v_{i} vi 表示用户点击序列中的第 i i i 个item, v t v_{t} vt 表示当前候选 item。如上图所示,BST 通过 item embedding 拼接 position embedding 的形式引入时序信息(Transformer 原文中使用相加,而非拼接),再进行 Multi-head。
Self-Attention
Self-Attention 操作将 item 的嵌入作为输入,并通过线性投影将它们转换为三个矩阵,并将它们输入到 attention 层。跟论文《Attention is all you need》一样,我们使用 multi-head attention :
S = M H ( E ) = Concate ( head i , head 2 , … , head h ) W H , head i = Attention ( E W i Q , E W i K , E W i V ) Attention ( Q , K , V ) = softmax ( Q K T d ) V \begin{array}{c} \boldsymbol{S}=M H(\boldsymbol{E})=\text { Concate }\left(\text {head}_{i}, \text {head}_{2}, \ldots, \text {head}_{h}\right) \boldsymbol{W}^{H}, \\ \text {head}_{i}=\text {Attention}\left(\boldsymbol{E} \boldsymbol{W}_{i}^{Q}, \boldsymbol{E} \boldsymbol{W}_{i}^{K}, \boldsymbol{E} \boldsymbol{W}_{i}^{V}\right) \\ \text {Attention}(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=\operatorname{softmax}\left(\frac{\boldsymbol{Q} \boldsymbol{K}^{T}}{\sqrt{d}}\right) \boldsymbol{V} \end{array} S=MH(E)= Concate (headi,head2,…,headh)WH,headi=Attention(EWiQ,EWiK,EWiV)Attention(Q,K,V)=softmax(dQKT)V
其中, E ∈ R n ∗ d \quad \boldsymbol{E} \in R^{n * d} E∈Rn∗d 表示序列中拼接了位置信息后的 item embedding矩阵, h \quad h h 表示序列长度, d d d 表示嵌入维度。 W i Q , W i K , W i V ∈ R d ∗ d \boldsymbol{W}_{i}^{Q}, \boldsymbol{W}_{i}^{K}, \boldsymbol{W}_{i}^{V} \in \boldsymbol{R}^{d * d} WiQ,WiK,WiV∈Rd∗d 分别表示第 i i i 个 head 的query、key、value 转换矩阵。 W H ∈ R h d ∗ d \boldsymbol{W}^{H} \in \boldsymbol{R}^{h d * d} WH∈Rhd∗d 表示拼接多头输出后的转换矩阵,注意最终输出 S ∈ R n ∗ d \boldsymbol{S} \in \boldsymbol{R}^{n * d} S∈Rn∗d 和 E \boldsymbol{E} E 维度是相同的,回忆下,MH只是为每个embedding学习一个新的表达。
Point-wise Feed-Forward Network
在论文《Attention is all you need》基础上,作者添加了 point-wise Feed-Forward Network (FFN),注意这里的网络是pointwise的,即操作粒度为 S ∈ R n ∗ d S \in R^{n * d} S∈Rn∗d 中的每一个embedding,以进一步增强模型的非线性能力,定义如下:
F = F F N ( S ) F = FFN(S) F=FFN(S)
为了避免过拟合,并从层次上学习有意义的特征,论文在 self-attention 和 FFN 中都使用了 dropout 和 LeakyReLU;
Self-Attention 和 FFN 层的整体输出如下:
S ′ = LayerNorm ( S + Dropout ( S ) ) F = LayerNorm ( S ′ + Dropout ( LeakyRelu ( S ′ W 1 + b 1 ) W 2 + b 2 ) ) . \begin{array}{c} \boldsymbol{S}^{\prime}=\text {LayerNorm}(\boldsymbol{S}+\text {Dropout}(\boldsymbol{S})) \\ \boldsymbol{F}=\text {LayerNorm}\left(\boldsymbol{S}^{\prime}+\text {Dropout}\left(\text {LeakyRelu}\left(\boldsymbol{S}^{\prime} \boldsymbol{W}^{1}+\boldsymbol{b}^{1}\right) \boldsymbol{W}^{2}+\boldsymbol{b}^{2}\right)\right) . \end{array} S′=LayerNorm(S+Dropout(S))F=LayerNorm(S′+Dropout(LeakyRelu(S′W1+b1)W2+b2)).
其中, W 1 , b 1 , W 2 , b 2 W^1, b^1, W^2, b^2 W1,b1,W2,b2 都是可学习的参数,和 LayerNorm 层是标准的归一化层。
Stacking the self-attention block
在 Self-Attention 之后,它聚合了之前所有 item 的嵌入。为了进一步建模 item 序列基础上的复杂关系,我们将自构建块堆叠起来,第 b 个块的定义如下:
S b = M H ( F b − 1 ) F b = F F N ( S b ) \begin{aligned} \boldsymbol{S}^{b} &=M H\left(\boldsymbol{F}^{b-1}\right) \\ \boldsymbol{F}^{b} &=F F N\left(\boldsymbol{S}^{b}\right) \end{aligned} SbFb=MH(Fb−1)=FFN(Sb)
在实践中,作者指出,在实验中观察到与 b=2,3 相比 b=1 获得了更好的性能(见下文表 4)。
MLP layers and Loss functi
通过连接其他特征的嵌入和应用于目标 item 的 Transformer 层的输出,我们使用三个完全连接的层来进一步学习稠密特征之间的交叉,这是在工业界的标准实践。
为了预测用户是否点击目标 item v t v_t vt,我们将其建模为一个二元分类问题,使用 sigmoid 函数作为输出单元。为了训练这个模型,我们使用了交叉熵(cross-entropy)损失函数:
L = − 1 N ∑ ( x , y ) ∈ D ( y log p ( x ) + ( 1 − y ) log ( 1 − p ( x ) ) ) \mathcal{L}=-\frac{1}{N} \sum_{(x, y) \in \mathcal{D}}(y \log p(x)+(1-y) \log (1-p(x))) L=−N1(x,y)∈D∑(ylogp(x)+(1−y)log(1−p(x)))
其中 D \mathcal{D} D 表示所有的样本, y ∈ { 0 , 1 } y \in\{0,1\} y∈{0,1} 表示用户是否点击了候选 item, p ( x ) p(x) p(x) 是该网络的预测输出;
4. 总结
该论文从理论创新上略显不足,但确实扎扎实实的工业级序列处理做法,其采用 self-attention 建模用户行为序列特征的处理方式在工业界得到了广泛应用;
再次强调:self-attention + target attention 已经是工业级推荐系统标配:利用 self-attention 提取序列中 item 之间的相互关系,利用 multi-head 可以为 item 学习到更多有效的特征表征;利用 target-attention 提取目标 item 和先前点击的 item 之间的相似性)。
5. 参考文献
[1] Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
[2] 阿里将Transformer用于淘宝电商推荐,效果超越深度兴趣网络DIN和谷歌WDL
[3] 简析阿里 BST: 当用户行为序列邂逅Transformer