【DIN论文精读】Deep Interest Network for Click-Through Rate Prediction
文章目录
-
- Paper
- 摘要 Abstract
- 1. 简介 Introduction
- 2. 前人的相关工作 Related Work
- 3. 系统概述 System Overview
-
- 3.1 用户行为数据的特性 Characteristic of User Behavior Data
- 3.2 特征表示 Feature Representation
- 3.3 Metrics
- 4. 模型架构 Model Architecture
-
- 4.1 基准模型 Base Model
- 4.2 深度兴趣网络的设计 Deep Interest Network Design
- 4.3 基于数据的激活函数 Data Dependent Activation Function
- 4.4 自适应正则化技术 Adaptive Regularization Technique
- 5. 实现 Implementation
- 6. 实验 Experiments
-
- 6.1 可视化 Visualization of DIN
- 6.2 正则化 Regularization
- 6.3 DIN和基准模型的对比 Comparison of DIN and base model
- 7 总结 Conclusions
Paper
- 本博客仅作为学习交流材料,论文版权归原作者所有:
- ArXiv: https://arxiv.org/abs/1706.06978v2
- APA:
Zhou, G. , Gai, K. , Zhu, X. , Song, C. , Fan, Y. , & Zhu, H. , et al. (2018). Deep Interest Network for Click-Through Rate Prediction. (pp.1059-1068).

摘要 Abstract
To better extract users’ interest by exploiting the rich historical behavior data is crucial for building the click-through rate (CTR) prediction model in the online advertising system in e-commerce industry.
在电子商务的工业应用,如何利用(注:用户的)丰富的历史行为数据,更好地提取用户的兴趣,是构建点击率(CTR)预测模型的关键。
There are two key observations on user behavior data:
关于用户行为数据,有两个关键的观察发现:
i) diversity. Users are interested in different kinds of goods when visiting e-commerce site.
ii) local activation. Whether users click or not click a good depends only on part of their related historical behavior.
- 多样性。用户在访问电子商务网站时,会对不同种类的商品产生兴趣。
- 局部激活。用户是否点击商品,只取决于他们相关的历史行为中的一部分。
However, most traditional CTR models lack of capturing these structures of behavior data.
然而,大多数传统的CTR模型,缺乏捕捉这些行为数据的结构。
In this paper, we introduce a new proposed model, Deep Interest Network (DIN), which is developed and deployed in the display advertising system in Alibaba.
在本文中,我们提出了一种新的模型——深度兴趣网络(DIN),它被开发并部署在阿里巴巴的展示广告系统中。
DIN represents users’ diverse interests with an interest distribution and designs an attention-like network structure to locally activate the related interests according to the candidate ad, which is proven to be effective and significantly outperforms traditional model.
DIN通过兴趣分布来代表用户的不同兴趣,并设计了一个类注意力的神经网络结构,根据候选广告,在局部激活相关兴趣,该模型被证明是有效的,显著优于传统模型。
Over-fitting problem is easy to encounter on training such industrial deep network with large scale sparse inputs. We study this problem carefully and propose a useful adaptive regularization technique.
对于这种具有大规模稀疏输入的工业深度网络,在训练时容易遇到过拟合问题。我们仔细研究了这个问题,并提出了一种有效的自适应正则化技术。
1. 简介 Introduction
Display advertising business brings billions dollars income yearly in Alibaba. In cost-per-click (CPC) advertising system, advertisements are ranked by the eCPM (effective cost per mille) which is the product of the bid price and CTR (click-through rate). Hence, the performance of CTR prediction model has a straight impact on the final revenue and plays a key role in the advertising system.
展示广告业务每年为阿里巴巴带来数十亿美元的收入。在每次点击成本(CPC)广告系统中,广告是按照 eCPM(千次展示有效收益) 进行排名的,eCPM是投标价格和点击率(CTR)的乘积。因此,点击率预测模型的表现直接影响最终的收入,在广告系统中起着关键作用。
Driven by the success of deep learning in image recognition, computer vision and natural language processing, a number of deep learning based methods have been proposed for CTR prediction task [1, 2, 3, 4]. These methods usually first employ embedding layer on the input, mapping original large scale sparse id features to the distributed representations, then add fully connected layers (in other words, multilayer perceptrons, MLPs) to automatically learn the nonlinear relations among features. Compared to traditional commonly used logistic regression model [5, 6], MLPs can reduce a lot of feature engineering jobs, which is time and manpower consuming in industry applications. MLPs now have become a popular model structure on CTR prediction problem. However, in the fields with rich internet-scale user behavior data, such as online advertising and recommendation system in e-commence industry, these MLPs models often lack of deep understanding and exploiting the specific structures of behavior data, thus leave space for further improvement.
深度学习在图像识别、计算机视觉和自然语言处理等领域均取得了成功,在此推动下,许多基于深度学习的方法被提出,用于CTR预测[1,2,3,4]。这些方法通常首先在输入上采用embedding层,将原始的大尺度稀疏id特征映射到(注:低维的)分布式表示上,然后加入全连接层(即多层感知器,MLPs)来自动学习特征之间的非线性关系。与传统常用的逻辑回归模型相比[5,6],MLP可以减少大量特征工程工作,在工业应用中,这部分工作是非常费时费力的。目前,MLPs模型已经成为研究CTR预测问题的一种常用模型结构。然而,在拥有丰富的、互联网规模的(注,即大量的)用户行为数据的领域,如电子商务行业的在线广告、推荐系统等,对于行为数据的具体结构,这些MLPs模型往往缺乏深入的理解和挖掘,这留下了进一步改进的空间。
To summarize the structures of user behavior data collected in the display advertising system in Alibaba, we report two key observations:
- Diversity. Users are interested in different kinds of goods when visiting e-commerce site. For example, a young mother may be interested in T-shits, leather handbag, shoes, earrings, children’s coat, etc at the same time.
- Local activation. Due to the diversity of users’ interests, only a part of users’ historical behavior contribute to each click. For example, a swimmer will click a recommended goggle mostly due to the bought of bathing suit while not the books in her last week’s shopping list.
为了总结在阿里巴巴展示广告系统中收集的用户行为数据的结构,我们提出了两个关键的观察结果:
- 多样性。用户在访问电子商务网站时,会对不同种类的商品产生兴趣。例如,一位年轻的母亲可能同时对T恤、皮包、鞋子、耳环、儿童外套等感兴趣。
- 局部激活。由于用户兴趣的多样性,只有一部分用户的历史行为会影响到(注:后面的)每次点击。例如,一个游泳者会点击推荐的泳镜,主要是因为买了泳衣,而不是她上周购物清单上的书。
In this paper, we introduce a new proposed model, named Deep Interest Network (DIN), which is developed and deployed in the display advertising system in Alibaba. Inspired by the attention mechanism used in machine translation model[7], DIN represents users’ diverse interests with an interest distribution and designs an attention-like network structure to locally activate the related interests according to the candidate ad. We demonstrate this phenomenon in the experiment section 6.1. Behaviors with higher relevance to the candidate ad get higher attention scores and dominant the prediction. Experiments on Alibaba’s productive CTR prediction datasets prove that the proposed DIN model significantly outperforms MLPs under the GAUC (group weighted AUC, see section 3.3) metric measurement.
在本文中,我们提出了一种新的模型,名为深度兴趣网络(DIN),它被开发并部署在阿里巴巴的展示广告系统中。DIN受到机器翻译模型[7]中注意力机制的启发,通过兴趣分布来代表用户的多种兴趣,并设计了一个类注意力的网络结构,根据候选广告在局部激活相关兴趣。我们在6.1节的实验中,展示了这一现象。与候选广告(注:商品)相关度越高的行为,其注意力得分越高,在预测中占主导地位。基于阿里巴巴丰富的CTR预测数据集,实验证明,本文提出的DIN模型在GAUC(分组加权AUC,见3.3节)度量方式向下,显著优于MLPs(注:多层感知器系列模型)。
Overfitting problem is easy to encounter on training such industrial deep network with large scale sparse inputs. Experimentally we show with addition of fine-grained user behavior feature (e.g., good id), the deep network models easily fall into the overfitting trap and cause the model performance to drop rapidly. In this paper, we study this problem carefully and propose a useful adaptive regularization technique, which is proven to be effective for improving the network convergence in our application. DIN is implemented at a multi-GPU distributed training platform named X-Deep Learning (XDL), which supports model-parallelism and data-parallelism. To utilize the structural property of internet behavior data, we employ the common feature trick proposed in [8] to reduce the storage and computation cost. Due to the high performance and exibility of XDL platform, we accelerate training process about 10 times and optimize hyparameters automatically with high tuning efficiency.
对于这种具有大规模稀疏输入的工业级深度神经网络,训练时很容易遇到过拟合问题。实验表明,随着细粒度用户行为特征(例如商品id)的加入,深度神经网络模型很容易陷入过拟合陷阱,导致模型性能急剧下降。在本文中,我们仔细地研究了这个问题,并提出了一种有效的自适应正则化技术,在我们的实际应用中,(注:该技术)被证明对提高网络模型的收敛性是有效的。DIN是在多GPU分布式训练平台上实现的,该平台名为X-Deep Learning(XDL),支持模型并行和数据并行。为了利用网络行为(注:用户上网行为)数据的结构特性,我们采用[8]中提出的通用特征技巧来降低存储和计算成本。由于XDL平台的高性能和灵活性,我们可以将训练过程加快10倍左右,并以很高的调优效率自动优化超参数。
The contributions of the paper are summarized as follows:
- We study and summarize two key structures of internet-scale user behavior data in industrial e-commence applications: diversity and local activation.
- We propose a deep interest network (DIN), which can better capture the specific structures of behavior data and bring improvements of model performance.
- We introduce a useful adaptive regularization technique to overcome the overfitting problem in training industrial deep network with large scale sparse inputs, which can generalize to similar industry tasks easily.
- We develop XDL, a multi-GPU distributed training platform for deep networks, which is scalable and flexible to support our diverse experiments with high performance.
本文的贡献总结如下:
- 我们研究和总结了工业电子商务应用中,互联网规模的用户行为数据的两个关键结构:多样性和局部激活。
- 我们提出了一个深度兴趣网络(DIN),它可以更好地捕捉(注:用户)行为数据的具体结构,并带来模型性能的改进。
- 我们引入了一种有效的自适应正则化技术来克服具有大规模稀疏输入的工业深度网络训练中的过拟合问题,它可以很容易地推广到类似的工业任务。
- 我们开发了XDL,一个用于深度网络的多GPU分布式训练平台,它具有可扩展性和灵活性,可以以较高的性能,支持我们的各种实验。
In this paper we focus on the CTR prediction task in the scenario of display advertising in e-commerce industry. Methods discussed here can be applied in similar scenarios with rich internet-scale user behavior data, such as personalized recommendation in e-commerce sites, feeds ranking in social networks etc.
本文主要研究电子商务行业展示广告场景下的点击率预测任务。本文所讨论的方法,也可以应用于具有丰富的互联网规模用户行为数据的其他类似场景,如电子商务网站的个性化推荐、社交网络的订阅排名等。
The rest of the paper is organized as follows. We discuss related work in Section 2. Section 3 gives an overview of our display advertising system, including user behavior data and feature representations. Section 4 describes the design of DIN model as well as the adaptive regularization technique. Section 5 gives a brief introduction of developed XDL platform. Section 6 exhibits experiments and analytics. Finally, we conclude the paper in Section 7.
本文的其余部分组织如下。我们将在第2节讨论(注:前人的)相关工作。第3节为我们的展示广告系统提供了一个总览,包括用户行为数据和特征表示。第4节介绍了DIN模型的设计以及自适应正则化技术。第5节简要介绍了先进的XDL平台。第6节展示了实验和分析。最后,在第7节对本文进行总结。
2. 前人的相关工作 Related Work
The CTR prediction model has evolved from shallow to deep structure, with the scale of feature and sample becoming larger and larger at the same time. Along with the mining of feature representations, the design of model structure involves more insights.
CTR预测模型处于逐渐演化的过程中,由浅层结构到深层结构,特征和样本的量级也越来越大。随着特征表示的挖掘,更多的思想被引入模型结构的设计过程中。
As a pioneer work, NNLM [9] proposes to learn distributed representation for words, aiming to avoid curse of dimensionality in language modeling. This idea, we name it embedding, has inspired many natural language models and CTR prediction models that need to handle large-scale sparse inputs.
作为一项开创性的工作,NNLM[9]提出学习词汇的分布式表示,旨在避免语言建模中的维数灾难。这种思想,我们称之为Embedding,启发了许多自然语言模型和CTR预测模型,它们需要处理大规模的稀疏输入。
LS-PLM [8] and FM [10] models can be viewed as a class of networks with one hidden layer, which first employs embedding layer on sparse inputs and then imposes special designed transformation functions for output, aiming to capture the combination relationships among features.
LS-PLM[8]和FM[10]模型可以看作是一类具有单个隐藏层的网络,它首先在稀疏输入上使用Embedding,然后对输出施加专门设计的变换函数,旨在捕捉特征之间的组合关系(注:特征交叉)。
Deep Crossing [1], Wide&Deep Learning [4] and the YouTube Recommendation CTR model [2] extend LS-PLM and FM by replacing the transformation function with complex MLP networks, which enhances the model capability greatly. They follow a similar model structure with combination of embedding layer (for learning the distributed representation of sparse id features) and MLPs (for learning the combination relationships of features automatically). This kind of CTR prediction model replaces the manually artificial feature combinations to a great extent. Our base model follows this kind of model structure. However, it’s worth mentioning that for CTR prediction tasks with user behavior data, features are ofter contained with multi-hot sparse ids, e.g., search terms and watched videos in YouTube recommendation system. These models often add a pooling layer after embedding layer, with operations like sum or average, to get a fixed size embedding vector. This will cause loss of information and can’t take full advantage of inner structure of user rich behavior data.
Deep Crossing[1]、Wide&Deep [4]和YouTube推荐CTR模型[2]扩展了LS-PLM和FM,将转换函数替换为复杂MLP网络,大大增强了模型的能力。它们遵循相似的模型结构,结合Embedding(用于学习稀疏id特征的分布式表示)和MLPs(用于自动学习特征的组合关系)(注:特征交叉)。这种CTR预测模型在很大程度上替代了人工的特征组合。我们的基准模型遵循这种模型结构。但值得一提的是,对于具有用户行为数据的CTR预测任务,往往会包含多个multi-hot稀疏id,如YouTube推荐系统中的搜索词、观看视频等。这些模型通常在Embedding层之后添加池化层,通过求和或求平均等操作,得到一个固定大小的Embedding向量。这将导致信息丢失,不能充分利用用户丰富的行为数据的内部结构(注:内部结构特征和信息)。
Attention mechanism, which originates from Neural Machine Translation field [7], gives us inspiration. NMT takes a weighted sum of all the annotations to get an expected annotation and focus only on information relevant to the generation of the next target word in the Bi-directional RNN [11] machine translation task. This inspired us to design attention-like structure to better model user’s historical diverse interests. A recent work, DeepIntent [3] also applies attention technique to better model the rich inner structure of data, which learns to assign attention scores to different words to obtain better sentence representation in sponsored search. However, there is no interaction between query and document, that is, given the model , query or document representations are fixed. This scenario is different from us since in DIN model user representation is adaptive changing with different candidate ads in display advertising system. In other words, DeepIntent captures the diversity structure of data but misses the local activation property, while the proposes DIN model captures both.
注意力机制,源于神经机器翻译(注:后面的NMT)领域[7],给我们带来了启示。NMT对所有注释进行加权求和,以得到一个期望的注释,在双向RNN[11]机器翻译任务中,NMT只关注与生成下一个目标词相关的信息。这启发了我们设计类似注意力的结构,以更好地模拟用户的历史兴趣多样性。最近的一项工作,DeepIntent[3]也应用了注意力技术,来更好地对数据内部的丰富结构进行建模,它通过学习如何给不同的单词分配注意分数,以在付费搜索中获得更好的句子表示。但是,查询和文档之间不存在交互,也就是说,给定了模型,查询或文档的表示(注:表示向量)就固定了。这个场景与我们的不同,因为在DIN模型和展示广告系统中,用户表示向量是随着不同的候选广告而自适应变化的。换句话说,DeepIntent捕获了数据的多样性结构,但忽略了局部激活属性,而本文提出的DIN模型同时捕获了两者。
3. 系统概述 System Overview
The overall scenario of the display advertising system is illustrated in Figure 1. Note that, in the e-commerce sites, advertisements are natural goods. Hence, without special declaration, we refer to ads as goods in the rest of this paper.
展示广告系统的总体方案如图1所示。请注意,在电子商务网站中,广告是天然的商品。因此,无需特别声明,我们在本文其余部分将广告称为商品。
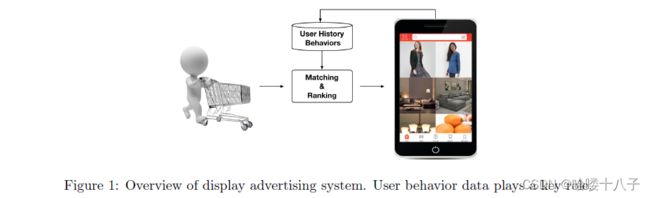
When a user visits the e-commerce site, system
- checks his historical behavior data
- generates candidate ads by matching module
- predicts the click probability of each ad and selects appropriate ads which can attract attention (click) by ranking module
- logs the user reactions given the displayed ads.
This turns to be a closed-loop consumption and generation of user behavior data. At Alibaba, hundreds of millions of users visit the e-commerce site everyday, leaving us with lots of real data.
当用户访问电商网站时,系统
- 检查用户的历史行为数据
- 通过匹配模块生成候选广告
- 预测每个广告的点击概率,通过排名模块,选择合适的、能够吸引用户注意力(即用户大概率会点击)的广告
- 记录向用户显示该广告后,用户的反应
这形成一个闭环过程,涉及的用户行为数据的消费和生成。在阿里巴巴,每天都有数亿用户访问这个电子商务网站,给我们留下了大量的真实数据。
3.1 用户行为数据的特性 Characteristic of User Behavior Data
Table 1 shows examples of user behavior collected from our online product. There are two obvious characteristics of users’ behavior data in our system:
- Diversity. Users are interested in different kind of goods.
- Local activation. Only a part of users’ historical behaviors are relevant to the candidate ad.
表1展示了用户行为示例,从我们的线上生产环境中收集得到。在我们的系统中,用户行为数据有两个明显的特点:
- 多样性。用户对不同种类的商品感兴趣。
- 局部激活。只有一部分用户的历史行为与候选广告(注:对候选商品的选择倾向)有关。

3.2 特征表示 Feature Representation
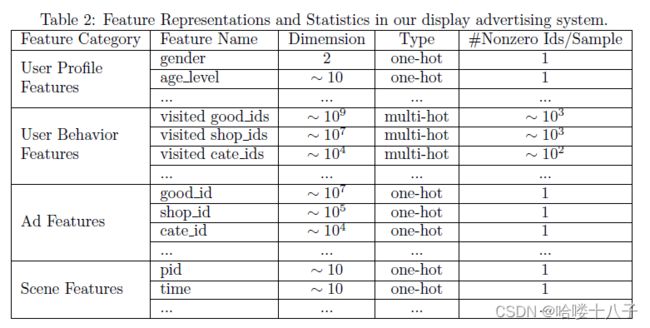
Our feature set is composed of sparse ids, a traditional industry setting like [1, 4, 5]. We group them into four groups, as described in Table 2. Note that in our setting there are no combination features. We capture the interaction of features with deep network.
我们的特征集由稀疏的id组成,典型的工业设置方式如文章[1,4,5]。我们将它们分成四组,如表2所示。注意,在我们的设置中没有组合特征。我们利用深度网络捕获特征的相互作用(注:特征交叉)。
3.3 Metrics
Area under receiver operator curve (AUC)[12] is a commonly used metric in CTR prediction area. In practice, we design a new metric named GAUC, which is the generalization of AUC. GAUC is a weighted average of AUC calculated in the subset of samples group by each user. The weight can be impressions or clicks. An impression based GAUC is calculated as follows:
接受者操作曲线下面积(Area under receiver operator curve, AUC)[12]是CTR预测区域常用的指标。在实际应用中,我们设计了一种新的度量,称为GAUC,它是AUC的推广。GAUC是AUC的加权平均值,在样本组子集中计算,按照每个用户。权重可以是曝光或者点击。基于曝光的GAUC计算公式如下:
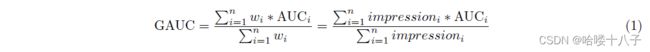
GAUC is practically proven to be more indicative in display advertisement settings, where CTR model is applied to rank candidate ads for each user and model performance is mainly measured by how good the ranking list is, that is, a user specific AUC. Hence, this method can remove the impact of user bias and measure more accurately the performance of the model over all users. With years of application in our production system, GAUC metric is verified to be more stable and reliable than AUC.
实际证明,GAUC在展示广告设置中更具有指标性(注:说明性),CTR模型对每个用户的候选广告进行排名,模型性能主要通过排名列表的好坏来衡量,即用户特定的AUC。因此,该方法可以消除用户偏差的影响,更准确地衡量模型对所有用户的性能。在我们的生产系统中应用多年后,GAUC度量被证明比AUC更加稳定可靠。
4. 模型架构 Model Architecture
Different from the sponsored search, most of users come into display advertising system without clear target. Hence, our system need an effective approach to extract users’ interests from the rich historical behavior while building the click-through rate (CTR) prediction model.
与付费搜索不同的是,大多数用户进入展示广告系统时没有明确的目标。因此,我们的系统在构建点击率(CTR)预测模型的同时,需要一种有效的方法,从丰富的历史行为中提取用户的兴趣。
4.1 基准模型 Base Model
Following the popular model structure introduced in [1, 4, 2], our base model is composed with two steps:
- transfer each sparse id feature into a embedded vector space
- apply MLPs to fit the output.
按照[1,4,2]中介绍的流行的模型结构,我们的基准模型由两个步骤组成:
- 将每个稀疏的id特征,映射到一个Embedding表示向量空间
- 使用MLP,拟合输出
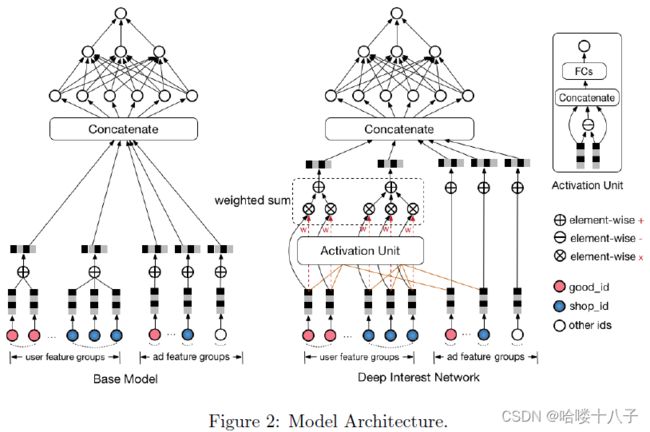
Notice that the input contains user behavior sequence ids, of which the length can be various. Thus we add a pooling layer (e.g. sum operation) to summarize the sequence and get a fixed size vector. As illustrated in the left part of Figure 2, the base model works well practically, which now serves the main trafic of our online display advertising system.
需要提及的是,模型输入包含用户行为序列id,其长度可以是不同的。因此,我们添加了池化层(例如加和操作),对序列进行汇总,得到一个固定大小的向量。如图2左侧所示,基准模型在实际中运行良好,它现在服务于我们的在线展示广告系统的主要流量。
However, going deep into the pooling operation, we will find that much information is lost, that is, it destroys the inner structure of user behavior data. This observation inspires us to design a better model.
但是,深入考虑池化操作,我们会发现很多信息丢失了,即破坏了用户行为数据的内部结构。这个观察结果驱使我们设计一个更好的模型。
4.2 深度兴趣网络的设计 Deep Interest Network Design
In our display advertising scenario, we wish our model to truly reveal the relationship between the candidate ad and users’ interest based on their historical behaviors.
在我们的展示广告场景中,我们希望我们的模型,能够基于用户的历史行为,真实地揭示候选广告和用户兴趣之间的关系。
As discussed above, behavior data contains two structures: diversity and local activation.
如上所述,行为数据包含两个结构:多样性和局部激活。
The diversity of behavior data reflects users’ various interests. User click of ad often originates from just part of user’s interests. We find it is similar to the attention mechanism. In NMT task it is assumed that the importance of each word in each decode process is different in a sentence. Attention network [7] (can be viewed as a special designed pooling layer) learns to assign attention scores to each word in the sentence, which in other words follows the diversity structure of data.
行为数据的多样性反映了用户兴趣的多样性。用户点击广告往往只是由于用户的部分兴趣。我们发现它与注意力机制相似。在NMT(注:Neural Machine Translation)任务中,假设每个词在每一个解码过程中的重要性在句子中是不同的。注意力网络[7] (可以看作是一个特殊设计的池化层)学习给句子中的每个单词分配注意分数,也就是说遵循数据的多样性结构。
However, it is unsuitable to directly apply the attention layer in our applications, where embedding vector of user interest should vary according to different candidate ads, that is, it should follow the local activation structure.
然而,在我们的应用中,不适合直接应用注意力层,用户兴趣的Embedding向量应该根据候选广告的不同而不同,也就是应该遵循局部激活结构。
Let’s check what will happen if the local activation structure is not followed. Now we get the distributed representation of users( V u V_u Vu) and ads( V a V_a Va). For the same user, V u V_u Vu is a fixed point in embedding space. It is the same to ad embedding V a V_a Va. Assume that we use inner product to calculate the relevance between user and ad, F ( U ; A ) = V u ⋅ V a F(U;A) = V_u \cdot V_a F(U;A)=Vu⋅Va. If both F ( U ; A ) F(U;A) F(U;A) and F ( U ; B ) F(U;B) F(U;B) are high, which means user U U U is relevant to both ad A A A and B B B. Under this way of calculation, any point on the line between the vector of V a V_a Va and V b V_b Vb will get high relevance score. It brings a hard constraint to the learning of distributed representation vector for both user and ad. One may increase the embedding dimensionality of the vector space to satisfy the constraint, which can work perhaps, but will cause a huge increase of model parameters.
让我们看看,如果不遵循局部激活结构,会发生什么。现在我们得到了用户( V u V_u Vu)和广告( V a V_a Va)的分布式表示。对于同一个用户, V u V_u Vu是Embedding空间中的一个固定点, V a V_a Va同样也是。假设我们使用内积来计算用户 U U U和广告 A A A之间的相关性, F ( U ; A ) = V u ⋅ V a F(U;A) = V_u \cdot V_a F(U;A)=Vu⋅Va。如果 F ( U ; A ) F(U;A) F(U;A)和 F ( U ; B ) F(U;B) F(U;B)都很高,说明用户 U U U与广告 A A A和 B B B都相关。在这种计算方式下, V a V_a Va向量与 V b V_b Vb向量直线上的任意一点,都会得到较高的相关性得分。这给用户和广告的分布式表示向量的学习带来了很大的限制。一种方法是增加向量空间的表示维数来满足约束条件,这种方法也许可行,但会导致模型参数的大幅增加。
In this paper we introduce a new design network, named DIN, which follows the two structures of data. DIN is illustrated in the right part of Figure 2. Mathematically, the embedding vector V u V_u Vu of user U U U turns to be a function of the embedding vector V a V_a Va of ad A A A, that is:
本文介绍了一种新设计网络,命名为DIN,它遵循了上述两种数据结构。图2的右侧展示了DIN的结构。在数学上,用户 U U U的表示向量 V u V_u Vu,被表示成广告 A A A的表示向量 V a V_a Va的函数,即:
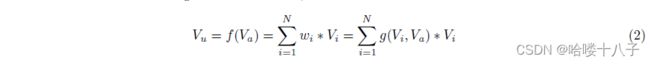
Where, V i V_i Vi is the embedding of behavior id i i i, such as good id, shop id, etc. V u V_u Vu is the weighted sum of all the behavior ids. w i w_i wi is the attention score that the behavior id i i i contributes to the overall user interest embedding vector V u V_u Vu with respect to the candidate ad A A A. In our implementation, w i w_i wi is the output of activation unit (denoted by function g g g) with inputs of V i V_i Vi and V a V_a Va.
其中, V i V_i Vi为行为id i i i 的表示向量,如商品id, 店铺id等。 V u V_u Vu为所有行为id的加权和。 w i w_i wi 是行为id i i i 对表示向量 V u V_u Vu 对候选广告 A A A 的总体用户兴趣贡献的注意得分。在我们的实现中, w i w_i wi 是激活单元的输出(用函数 g g g表示),输入为 V i V_i Vi和 V a V_a Va。
In all, DIN designs the activation unit to follow local activation structure and weighted sum pooling to follow diversity structure. To the best of our knowledge, DIN is the first model which follows both of the two structures of user behavior data in CTR prediction tasks at the same time.
DIN设计的激活单元遵循局部激活结构,加权和池化遵循多样性结构。据我们所知,在CTR预测任务中,DIN是第一个同时遵循两种用户行为数据结构的模型。
4.3 基于数据的激活函数 Data Dependent Activation Function
PReLU [13] is a common used activation function and is chosen in our setting at the beginning, which is defined as
PReLU[13]是一个常用的激活函数,我们在一开始的设置中选择它,它被定义为
![]()
PReLU plays the role as the Leaky ReLU to avoid zero gradients [14] while the a i a_i ai is small. Previous research has shown that PReLU can improve accuracy with a little extra risk of overfftting.
PReLU扮演着 Leaky ReLU 的角色,以避免0梯度[14],其中 a i a_i ai很小。先前的研究表明,PReLU可以提高精度,但有一点额外的过拟合风险。
However, in our application with large scale sparse input ids, training such industrial-scale network still faces a lot of challenge. To further improve the convergence rate and performance of our model, we consider and design a novel data dependent activation function, which we name it Dice:
然而,在我们大规模稀疏输入id的应用中,训练这样的工业规模网络仍然面临着很大的挑战。为了进一步提高模型的收敛速度和性能,我们考虑并设计了一个新颖的、数据依赖的 激活函数,我们将其命名为Dice:
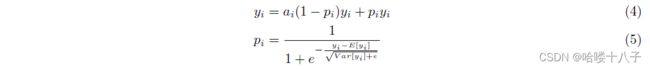
E [ y i ] E[y_i] E[yi] and V a r [ y i ] Var[y_i] Var[yi] in training step are calculate directly from each mini batch data, meanwhile we adopt the momentum method to estimate the running E [ y i ] ′ E[y_i]' E[yi]′ and V a r [ y i ] ′ Var[y_i]' Var[yi]′:
训练步骤中的 E [ y i ] E[y_i] E[yi]和 V a r [ y i ] Var[y_i] Var[yi]由每个小批量数据直接计算,同时我们采用动量法对实时的 E [ y i ] ′ E[y_i]' E[yi]′和 V a r [ y i ] ′ Var[y_i]' Var[yi]′进行估计:
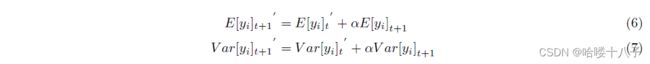
t t t is the mini batch step of the training process, and α \alpha α is a super parameter like 0.99. In the test step we used the running E [ y i ] ′ E[y_i]' E[yi]′ and V a r [ y i ] ′ Var[y_i]' Var[yi]′.
t t t是训练过程的小批处理步骤, α \alpha α是一个超参数,比如0.99。在测试步骤中,我们使用实时的 E [ y i ] ′ E[y_i]' E[yi]′ 和 V a r [ y i ] ′ Var[y_i]' Var[yi]′。
The key idea of Dice is to adaptively adjust the rectifier point according to data, which is different from PReLU using a hard rectifier based on y i > ? 0 y_i \overset{?}{>} 0 yi>?0. In this way, Dice can be viewed as a soft rectifier with two channel: a i y i a_iy_i aiyi and y i y_i yi based on p i p_i pi. p i p_i pi is a weight to keep the original y i y_i yi, it will be lower while y i y_i yi deviate from E [ y i ] E[y_i] E[yi] of each mini batch data. Experiments show Dice provides an obviously improvement on convergence rate and GAUC.
Dice的关键思想是根据数据自适应调整整流点,这与PReLU使用基于 y i > ? 0 y_i \overset{?}{>} 0 yi>?0 的硬整流是不同的。因此,Dice可以被视为具有两个通道的软整流器: a i y i a_iy_i aiyi和基于 p i p_i pi的 y i y_i yi。 p i p_i pi是保留原来 y i y_i yi的权值,当每个小批量数据的 y i y_i yi偏离 E [ y i ] E[y_i] E[yi]时,它会更低。实验表明,在收敛速度和GAUC方面,Dice算法有明显的改进。
4.4 自适应正则化技术 Adaptive Regularization Technique
Not surprisingly, overfitting problem is encountered while training our model with large scale parameters and sparse inputs. We show experimentally, with addition of fine-grained user visited good ids feature, model performance falls rapidly after the first epoch.
不足为奇的是,在大量参数和稀疏输入的场景下,训练我们的模型时,会遇到过拟合问题。实验表明,随着加入细粒度的用户访问商品id这一特征,模型性能在第一个周期后迅速下降。
Many methods have been proposed to reduce overfitting, such as L2 and L1 regularization [15], and Dropout [16]. However, with sparse and high dimensional data, CTR prediction task faces greater challenge. It is known that internet-scale user behavior data follows the long-tail law, that is, lots of feature ids occur a few times in the training samples, while little of them occur many times. This inevitably introduces noise into the training process and intensifies overfitting. An easy way to reduce overfitting is to filter out those low-frequency feature ids, which can be viewed as manual regularization. However, such frequency based filter is quite rough in terms of information loss and threshold setting. Here we introduce an adaptive regularization method, in which we impose different regularization intensity on feature ids according to their occurrence frequency.
许多方法被提出来减少过拟合,如L2和L1正则化[15],Dropout[16]。然而,在稀疏、高维数据的情况下,CTR预测任务面临着更大的挑战。我们知道,互联网规模的用户行为数据遵循长尾规律,即大量特征id在训练样本中多次出现,而很少有特征id多次出现。这不可避免地在训练过程中引入了噪声,并加剧了过拟合。减少过拟合的一个简单方法是过滤掉那些低频特征id,这可以被视为手动正则化。但是这种基于频率的滤波器在信息丢失和阈值设置方面都比较粗糙。本文提出了一种自适应正则化方法,根据特征的出现频率对其施加不同的正则化强度。
Denote that,
(注:本文提出的自适应正则化方法)表示为公式(8)
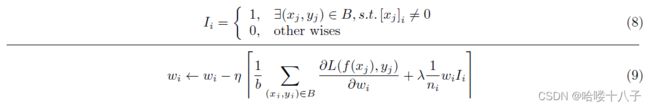
The update formula is shown as Eq.(9). B B B stands for mini-batch samples with size of b b b. n i n_i ni is frequency of feature i i i and λ \lambda λ is regularization parameter.
更新公式如式(9)所示。 B B B为小批量样品,大小为 b b b。 n i n_i ni是特征 i i i的频率, λ \lambda λ是正则化参数。
The idea behind Eq.(9) is to penalize low-frequency features and relax high-frequency features to control the gradient update variance.
Eq.(9)的思想是通过惩罚低频特征,放松高频特征,来控制梯度更新方差。
A similar practice of adaptive regularization can be found in [17] which sets regular coefficient to be proportional to feature frequency, as shown below:
一种类似的自适应正则化做法,见文章[17],该方法将正则系数设置为与特征频率成正比,如下图所示(注:Eq10):
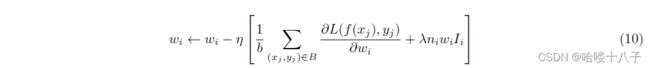
However, in our dataset, training with regularization of Eq.(10) shows no obvious alleviation of overfitting. On the contrary, it slows down the convergence of training process. Eq.(10) applies greater penalty on high-frequency good ids than long-tail goods, while the former contributes more on both the metric and online income in our special e-commerce system. Besides, we also evaluate dropout technique and find slight improvement on overfitting.
然而,在我们的数据集中,Eq.(10)的正则化训练并没有明显减轻过拟合。相反,它会减慢训练过程的收敛速度。与长尾商品相比,Eq.(10)对高频商品id的惩罚更大,而在我们特殊的电子商务系统中,高频商品id对效果度量和在线收入的贡献都更大。此外,我们还评估了dropout技术,发现过拟合有轻微的改善。
5. 实现 Implementation
DIN is implemeted at a multi-GPU distributed training platform named X-Deep Learning (XDL) , which supports model-parallelism and data-parallelism. XDL is designed to solve the challenges of training industrial scale deep learning networks with large scale spare inputs and tens of billions parameters. In our observation, most of these deep networks published now are constructed with two steps: i) employ the embedding technique to cast the original sparse input into low dimensional and dense vectors ii) bridge with networks like MLPs, RNN, CNN etc. Most of the parameters are focused in the first embedding step which needs to be distributed over multi machines. The second network step can be handle within single machine. Under such thinking, we architecture the XDL platform in a bridge manner, as illustrated in figure 3, which is composed of three main kinds of components:
DIN在多GPU分布式训练平台XDL上实现,该平台支持模型并行和数据并行。XDL旨在解决训练工业规模深度学习网络的挑战,即具有大规模稀疏输入和数百亿参数的。在我们的观察中,目前发表的这些深度网络大多是通过两个步骤构建的:i)利用embedding技术,将原始的稀疏输入转换为低维和密集的向量;ii)与MLPs、RNN、CNN等网络桥接。大部分参数集中在Embedding的第一步,需要分布在多台机器上。第二个网络步骤可以在单机中处理。在这样的思路下,我们采用桥接的方式构建了XDL平台,如图3所示,主要由三种组件组成:
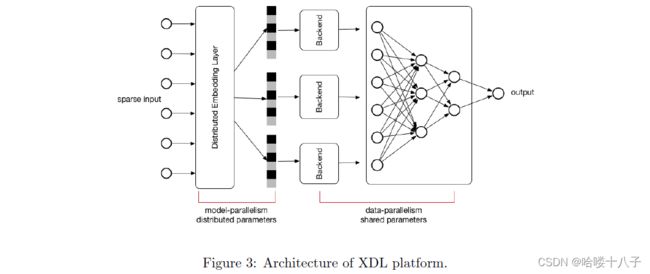
- Distributed Embedding Layer. It is a model-parallelism module, parameters of embedding layer are distributed over multi-GPUs. Embedding Layer works as a predefined network unit, which provides with forward and backward modes.
- 分布式Embedding层。它是一个模型并行模块,Embedding层的参数分布在多个GPU上。Embedding层是一个预定义的网络单元,提供正向和反向两种模式。
- Local Backend. It is a standalone module, which aims to handle the local network training. Here we reuse the open-sourced deep learning frameworks, like tensorflow, mxnet, theano[18, 19, 20] etc. With the unified data exchange interface and abstraction, it is easy for us to integrate and switch in different kinds of frameworks. Another benefit of the backend architecture is the convenience to easily follow up the open source community and utilize the latest published network structures or updating algorithms which are developed with these open-sourced deep learning frameworks.
- 局部后端。它是一个独立的模块,旨在执行局部网络训练。这里我们重用了开源的深度学习框架,如tensorflow、mxnet、theano[18,19,20]等。使用统一的数据交换接口和提取方式,便于我们在不同的框架中集成和切换。后端架构的另一个好处是便于跟踪开源社区,使用最新发布的网络结构或更新的算法,这些算法是用这些开源的深度学习框架开发的。
- Communication Component. It is the base module, which helps to parallel both the embedding layer and backend. In our first version, it is implemented with MPI.
- 通信组件。它是基础模块,有助于embedding层和后端的并行运行。在我们的第一个版本中,它是用MPI实现的。
Besides, we also employ the common feature trick [8], regarding with the structural property of data. Readers can find detailed introduction in [8].
此外,针对数据的结构属性,我们还采用了常用的特征技巧[8]。读者可以在[8]中找到详细的介绍。
Due to the high performance and exibility of XDL platform, we accelerate training process about 10 times and optimize hyparameters automatically with high tuning efficiency.
由于XDL平台的高性能和灵活性,我们可以将训练过程加快10倍左右,并以很高的调优效率优化超参数。
6. 实验 Experiments
6.1 可视化 Visualization of DIN
In DIN model, sparse id features are encoded as embedding vectors. Here we randomly select 9 categories (dress, sport shoes, bags, etc) and 100 goods for each category. Fig. 4 shows the visualization of embedding vectors of goods based on t-SNE[21], in which points with same shape correspond to same category. It shows clearly the clustering property of DIN embeddings.
在DIN模型中,稀疏的id特征被编码为embedding向量。在这里,我们随机选择了9个类别(服装、运动鞋、包等),每个类别100种商品。图4给出了基于t-SNE[21]的商品embedding向量可视化,其中形状相同的点对应同一个类别。它清楚地显示了DIN embedding的聚类特性。

Besides, we color the points in Fig. 4 in a prediction manner: assume all the goods are candidates for the young mother (example in Table 1), they are colored by the prediction value (red ones get higher CTR than blue ones). DIN model identifies goods that meet user’s diverse interests correctly.
此外,我们基于预测结果,对图4中的点进行了染色:假设所有商品都是年轻母亲的候选商品(如表1),根据预测值对其进行染色(红色商品的CTR高于蓝色商品)。DIN模型正确地识别出了满足用户不同兴趣的商品。
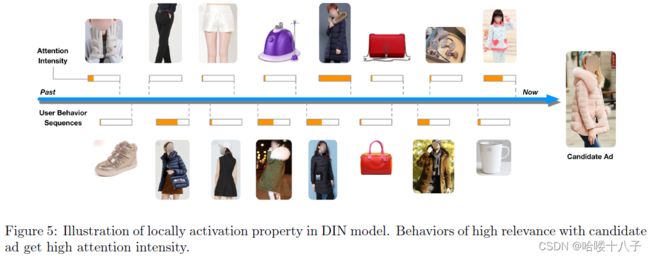
Further, we go deep into DIN model to check the working mechanism. As described in section 4.2, DIN designs the attention unit to locally activate the related behaviors with respect to candidate ads. Fig 5 illustrates the activation intensity (attention score w w w). As expected, behaviors of high relevance with candidate ad get high attention intensity.
在此基础上,我们深入探索DIN模型,了解其工作机制。如第4.2节所述,DIN设计了注意单元,用于局部激活候选广告的相关行为。图5给出了激活强度(注意得分 w w w)。正如所料,与候选广告高度相关的行为,会获得较高的注意强度。
6.2 正则化 Regularization
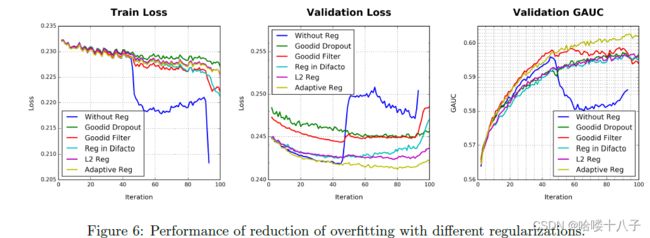
Both the base model and our proposed DIN model encounter overfitting problem during training with addition of fine-grained features, such as good id feature. Fig. 6 illustrates the training process with/without the fine-grained good id feature, which demonstrates the overfftting problem clearly.
在训练过程中,基准模型和我们提出的DIN模型,都遇到了过拟合问题,因为加入了细粒度特征,例如商品id特征。图6给出了有/没有细粒度商品id特征时的训练过程,很好地说明了过拟合的问题。
We now compare different kinds of regularizations experimentally.
我们现在通过实验,比较不同种类的正则化方法。
- Dropout. Randomly discard 50% of good ids in each sample.
- Filter. Filter good ids by occurrence frequency in samples and leave only the most frequent good ids. In our setup, top 20 million good ids are left.
- L2 regularization. Parameter λ \lambda λ is searched and set to be 0.01.
- Regularization in DiFacto. DiFacto proposed this method of Eq.(10). Parameter λ \lambda λ is searched and set to be 0.01.
- Adaptive regularization. Our proposed method of Eq. (9). We use Adam as the optimization method. Parameter λ \lambda λ is searched and set to be 0.01.
- Dropout。在每个样本中,随机丢弃50%商品id。
- 过滤。根据样本中的出现频率,过滤商品id,只留下最频繁的商品id。在我们的设置中,保留了最高频的前2000万个商品id。
- L2正规化。参数 λ \lambda λ 被搜索,设置为0.01。
- DiFacto正则化。DiFacto提出了Eq.(10)的方法。参数 λ \lambda λ 被搜索,并被设置为0.01。
- 自适应正则化。我们提出了公式(9)的方法。我们使用Adam作为优化方法。参数 λ \lambda λ被搜索,并设置为0.01。
Comparison results are shown in Fig. 6. Validation result demonstrates the effectiveness of our proposed adaptive regularization method. Trained using the adaptive regularization technique, model with fine-grained good id feature achieves 0.7% gain in GAUC compared to model without it, which is a significant improvement in the CTR prediction task.
对比结果如图6所示。验证结果证明了我们提出的自适应正则化方法的有效性。使用自适应正则化技术训练后,具有细粒度商品id特征的模型,实现了0.7%的GAUC增长,相比于没有正则化方法,这在CTR预测任务中是一个显著的提高。
Dropout method causes slower convergence in first epoch, while overfitting is somewhat alleviated after the first epoch completes. Frequency filter keep the same speed of convergence with no-operation setup in first epoch. After the first epoch, overfitting is also alleviated, however still worse than dropout setup. In adptive regularization setup, we hardly see overfitting after the first epoch. Loss and GAUC on validation set almost converge when the second epoch completes.
Dropout方法在第一轮训练收敛较慢,而在第一轮训练之后,过拟合得到一定程度的缓解。频率滤波器在第一轮训练中,保持了相同的收敛速度,相比于无操作的方式(注:无正则化)。在第一轮训练之后,过拟合也得到了缓解,但效果仍然比dropout较差。使用自适应正则化时,在第一个训练轮次之后,我们几乎看不到过拟合现象。当第二轮训练完成时,验证集上的Loss和GAUC几乎收敛。
( 注 :结合图6曲线,这里猜测,每一轮训练约有45个iteration。图6中,横坐标iteration=45的位置,第1个epoch完成,第2个epoch开始,对于Without Reg曲线,训练loss骤降,验证loss骤升,过拟合明显;对于其他曲线,使用了不同的正则化方式,过拟合缓解,但缓解程度不尽相同,模型性能也存在差异。这是作者在这一段想要表达的内容。)
Regularization in DiFacto [17] of Eq.(10) set a greater penalty on high-frequency good id. However, in our task, high-frequency good id characterize users’ interest more confidently, and low-frequency good id will bring a lot of noise. The experiment of frequency filter can illustrate this point. Our method softens the low-frequency good id by applying a regular inverse of the frequency of the commodity.
式(10)的DiFacto正则化方法对高频率的商品id的施加了更大的惩罚。但在我们的任务中,高频的商品id在表征用户兴趣方面,有着更高的可信度,而低频的商品id会带来很多噪音。频率滤波器的实验可以说明这一点。我们的方法削弱了低频的商品id(注:对模型权重的更新贡献),通过使用商品频率的正则逆(注:参照公式9,对商品频率 n i n_i ni取倒数)。
6.3 DIN和基准模型的对比 Comparison of DIN and base model
We test the model performance on the productive display advertising system in Alibaba. Both training and testing datasets are generated from system logs, including impression and click logs. We collect two weeks’ samples for training and sample of the following day for testing, which is a productive setting in our system. Both base model and our proposed DIN model are constructed on the same feature representation as described in Table 3.2. Parameters are tuned separately and we report the best results. GAUC is used to evaluate the model performance.
我们测试了模型的性能,在阿里巴巴生产环境的展示广告系统上。训练和测试数据集都是从系统日志生成的,包括曝光和点击日志。我们收集两周的样本用于训练,收集了随后一天的样本用于测试,这在我们的系统中是一个高效的设置。基准模型和我们提出的DIN模型都是基于表3.2(注:猜测是作者笔误,应该是表2)所述的相同的特征表示构建的。参数是单独调优的,我们报告了最佳结果。采用GAUC指标,对模型性能进行了评价。
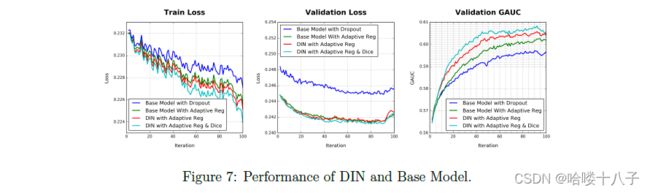
Results are shown in Table 3 and Fig. 7. Obviously, DIN model trained with with adaptive regularization outperforms base model significantly. DIN with adpative_reg used only half iterations of base model to get the highest GAUC of base model. And it achieved total 1.08% GAUC gain than base model in the end, which is a big improvement in our productive system. Dice achieved 0.23% GAUC gain than DIN with adpative reg. With better understanding and exploitation of structures of user behavior data, DIN model shows better ability for capturing the nonlinear relationships of user and candidate ad.
结果如表3和图7所示。显然,使用自适应正则化训练的DIN模型,其效果明显优于基准模型。使用自适应正则化方法的DIN,只使用相比于基准模型一半的迭代次数,就得到了基准模型的最高GAUC。最终达到了高于基准模型1.08%的GAUC提升,这是对我们生产系统的一个很大的改进。与使用自适应正则化的DIN相比,使用Dice后(注:激活函数,公式4,5),获得了0.23%的GAUC增益。随着对用户行为数据结构的更好的理解和利用,DIN模型在捕捉用户和候选广告的非线性关系方面表现出了更好的能力。

7 总结 Conclusions
In this paper, we focus on the CTR prediction task in the scenario of display advertising in e-commerce industry, which involves internet-scale user behavior data. We reveal and summarize the two key structures of data: diversity and local activation and design a novel model named DIN with better exploitation of data structures. Experiments show DIN brings more interpretability and achieves better GAUC performance compared with popular MLPs model. Besides, we study the overfitting problem in training such industrial deep networks and propose an adaptive regularization technique which can help reduce overfitting greatly in our scenario. We suppose these two approaches could be instructive to other industrial deep learning tasks.
本文中,我们聚焦于 电子商务行业中、展示广告场景下 的 点击率预测任务,该场景涉及了互联网规模的用户行为数据。我们揭示和总结了该数据的两个关键结构:多样性和局部激活,并设计了一个新的模型,名为DIN,更好地利用数据结构。实验结果表明,与目前流行的MLP系列模型相比,DIN模型具有更好的可解释性和更高的GAUC性能。此外,我们还研究了此类工业级深度网络训练中的过拟合问题,并提出了一种自适应正则化技术,可以大大减少我们的场景中的过拟合。我们认为,这两种方法对其他工业级深度学习任务,也具有指导意义。
Different from the fields of image recognition and natural language process with mature and state-of-the-art deep network structures, applications with rich internet-scale user behavior data still face a lot of challenges and are worth of making more efforts to study and design more common and useful network structures. We will continue to focus on this direction.
图像识别和自然语言处理等领域,具有成熟和先进的深度网络结构。与此不同,对于 拥有丰富的、互联网规模的 用户行为数据的应用,仍然面临着许多挑战,值得我们花更多的精力,来研究和设计更常见、更有用的网络结构。我们将继续朝着这个方向努力。
End