知识蒸馏算法原理
知识蒸馏算法原理
“蒸馏”的概念大概就是将本身不够纯净的水通过加热变成水蒸气,冷凝之后就成更纯净的水
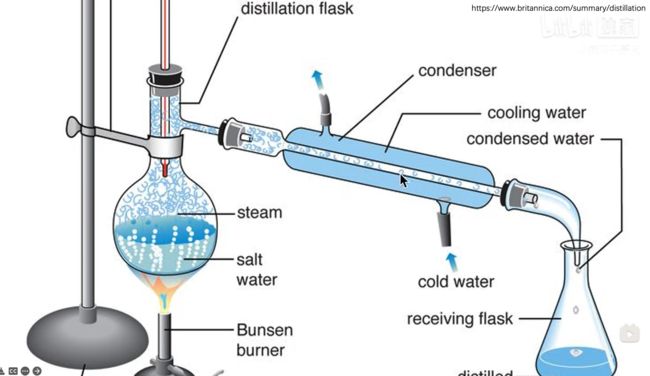
知识蒸馏同样使用这种原理,将不太纯净的“知识”通过“蒸馏”的方式获得更加有用或者纯净的“知识”
体现在神经网络中如下图所示:
一个大而臃肿,但知识丰富且高效的“教师网络”,通过转换精准将特定领域的知识传授给“学生网络”,让“学生网络”在某个方面做得很好,并且不那么臃肿,类似“模型压缩”

为什么不直接使用教师网络?因为将算法应用在现实生活中很多设备的算力会被限制,因此需要尽可能减少算力使用,因此使用大模型训练小模型,将 小模型部署在边缘计算设备

近些年来,预训练大模型的使用越来越广泛,并且参数规模每年增加10倍。大模型预训练都是由大公司耗费大量算力得来,在部署时大多会采用云服务器的方式进行,但是随之而来的问题就是网络延迟和必须要有网络。

因此可以看到轻量化网络是以后的一个主流,压缩网络还可以使用一下方法:

作者介绍
知识蒸馏概念有人工智能教父Hinton,他为人工智能发展做出了巨大贡献,提出反向传播、玻尔兹曼机、dropout、AlexNet、动量优化器、知识蒸馏等,2019年获得图灵奖,与LeCun、Bengio并称深度学习三巨头
google工作了20年的老员工,其中谷歌大部分基础框架是这他完成的,一名传奇的程序员
知识的表示与迁移
将一匹马的图片进行识别,他可能会识别为驴或者是汽车,通过hard targets的标签进行训练,之后将图片出入模型进行识别,可以得到一个soft targets,从soft targets中可以看出马的概率是比较大的,识别为驴的概率和识别为汽车的概率都是比较小的,同样可以看出马和驴的相关性是比较小的,马和汽车的相关性也是比较小的,同样的驴和汽车的相似度也是很小。因此soft targets可以传递出更多的信息,可以使用soft targets去训练学生网络

类似于上面的例子,如果使用手写数据集进行预测,可以看到soft targets给出了输入测试的数字和0-9的数字相似度,它不仅给出了这个数字更像7和9,也给了它有多不像0,同样证明soft targets具有更多信息和知识


总结:Soft Lable 包含了更多“知识”和“信息”像谁,不想睡,有多像,有多不像,特别是非正确类别概率的相对大小(驴和车)
因此我们接下来要做的就是,让教师网络通过Hard Target训练输出的Soft Target,作为学生网络的输入训练学生网络。
蒸馏温度T
Soft Target的输出还不足够“Soft“,因此在对其进行处理,新增一个蒸馏温度T,T使用在softmax函数中,修正输出标签的soft度,如下图,当T为1是,整个式子就是原始的softmax函数,当T等于3时,可以看到softmax的曲线改变了很多,相关分类的相似度降低了,其他不相关分类的相似度有所增加。左下角的图可以看到,当T变大,每个分类所获得的相似度就越平均(越soft),太大的话每个分类的相似度就会相同,越小会发现每个类别的差异会很大。softmax是做归一化,凸显每个分类之间的差别
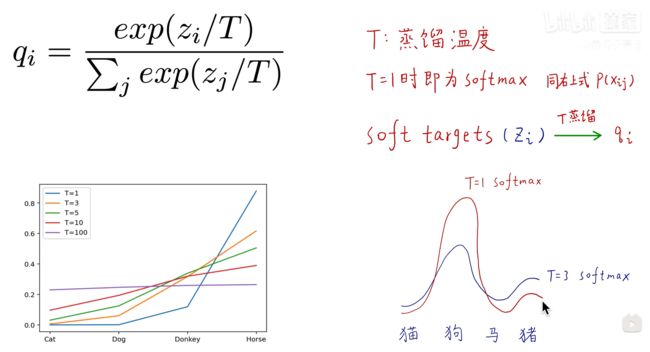
添加蒸馏温度T的学生网络和教师网络softmax计算对比

知识蒸馏过程
首先教师网络和学生网络都要经过添加了蒸馏温度T的softmax,二者进行一个loss求值,这个loss被称为disiliation loss,这个过程是学生网络在模拟老师网络的预测结果。
学生网络还会使用不添加蒸馏温度T的softmax进行一次计算,然后将结果和hard label进行一次loss计算,这里的loss称为student loss,这部分是学生网络在模拟真正的结果
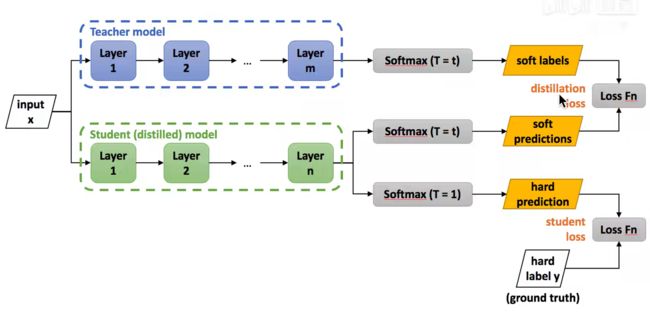
最后的loss函数就是disiliation loss和student loss的加权求和
注:三种loss的计算方式及距离在蒸馏温度T章节的图2有例子


实验结果
图像分类的效果:
知识蒸馏具有覆盖的效果,例如当训练学生网络的时候没有使用狗这个类别,但是教师网络训练时具有这个分类,在完成知识传递后发现学生网络同样可以识别狗这个类别,因为在蒸馏过程中教师网络将自己学习到的特征知识都传递给了学生网络,学生网络也从中学习到了新知识。(类似于老师给学生讲课,虽然学生没有见过真正的飞机,但是老师见过,给学生描述了很多关于飞机的细节,当学生见到飞机时也可以分辨出飞机)(零样本学习)

语音识别:
发现学生网络和教师网络的效果十分相似,学生网络更轻量
使用使用更少的数据集去训练网络,有效的防止过拟合。如果常规网络中使用100%训练出一个模型,如果使用其中3%重新训练模型,会发现训练过程中精度高,测试精度低,出现过拟合,但是如果将3%的数据放在学生网络中就不会出现过拟合情况

应用场景

知识蒸馏背后的机理
绿色是教师网络求解空间,蓝色是学生网络求解空间。红色为教师网络的答案空间,浅绿色为学生网络的答案空间,橙色是在知识蒸馏的情况下得到的答案空间也是最优解。
如果不加引导学生网络会在自己的求解空间中试探着寻找,最后找到浅绿色的答案,在增加了教师网络之后,学生网络查找求解空间时,老师网络会给予指导,让学生网络得到的答案更准确,或者让其往教师网络的答案空间靠。所以知识蒸馏会得到更轻便且效果好的模型

bert给出的解释(这里没有翻译,需要就自己翻译吧)
自己漫无目的翻书,不如师傅手把手教
Soft targets VS lable smoothing
二者对比,相比之下Soft targets保留的信息更多,从直方图上可以看到,lable smoothing突出了正确分类,其他错误类别都拉成相同的,没有Soft targets这样每个类对比明确,这样在学习过程中就不能明确每一种类的类别。

知识蒸馏发展趋势
知识蒸馏是一个人工智能的通用方法,可以应用在各个领域
1)教学相长
常规的知识老师网络单方面的输出,如果添加教师网络接受学生的矫正,也是可以的
2)助教、多个老师、多个同学
新增老师网络或者使用多个学生网络,助教也是一个比较重要的角色,可以增加助教网络
3)知识的表示(中间层)、数据集蒸馏、对比学习
知识蒸馏只是做了最后一层的softmax,可以增加中间层的蒸馏,或者老师将更多知识给学生,不仅仅是最后一层。下图三个角度,Response-Based、Feature-Based、Relation-Based都可以作为研究角度,知识蒸馏只是最后输出的Response-Based

Response-Based
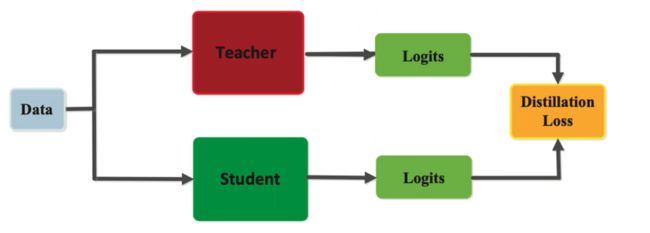
Feature-Based

Relation-Based
指定层数学习:
学生的第一层学习老师的第二层,学生第二层学习老师的第五层(实现中间层蒸馏,脑回路的传授)

对比学习也是一个大的方向
4)多模态、知识图谱、预训练大模型的知识蒸馏
多模态数据(语音、图像、文字结合)
知识蒸馏代码库
OpenMMLab模型压缩工具箱

