「知识蒸馏」最新2022研究综述
每天给你送来NLP技术干货!
来自:专知
华南师范大学等《知识蒸馏》最新综述论文

高性能的深度学习网络通常是计算型和参数密集型的,难以应用于资源受限的边缘设备. 为了能够在低 资源设备上运行深度学习模型,需要研发高效的小规模网络. 知识蒸馏是获取高效小规模网络的一种新兴方法, 其主要思想是将学习能力强的复杂教师模型中的“知识”迁移到简单的学生模型中. 同时,它通过神经网络的互 学习、自学习等优化策略和无标签、跨模态等数据资源对模型的性能增强也具有显著的效果. 基于在模型压缩和 模型增强上的优越特性,知识蒸馏已成为深度学习领域的一个研究热点和重点. 本文从基础知识,理论方法和应用 等方面对近些年知识蒸馏的研究展开全面的调查,具体包含以下内容:(1)回顾了知识蒸馏的背景知识,包括它的 由来和核心思想;(2)解释知识蒸馏的作用机制;(3)归纳知识蒸馏中知识的不同形式,分为输出特征知识、中间特 征知识、关系特征知识和结构特征知识;(4)详细分析和对比了知识蒸馏的各种关键方法,包括知识合并、多教师 学习、教师助理、跨模态蒸馏、相互蒸馏、终身蒸馏以及自蒸馏;(5)介绍知识蒸馏与其它技术融合的相关方法, 包括生成对抗网络、神经架构搜索、强化学习、图卷积、其它压缩技术、自动编码器、集成学习以及联邦学习;(6)对知识蒸馏在多个不同领域下的应用场景进行了详细的阐述;(7)讨论了知识蒸馏存在的挑战和未来的研究方向.
https://cjc.ict.ac.cn/online/onlinepaper/HZH315.pdf
1. 引言
深度学习由于对目标多样性变化具有很好的鲁 棒性,近年来得到广泛的关注并取得快速的发展. 然而性能越好的深度学习模型往往需要越多的资 源,使其在物联网、移动互联网等低资源设备的应 用上受到限制. 因此研究人员开始对高效的(Efficient)深度学习模型展开研究,其目的是使具有高性能 的模型能够满足低资源设备的低功耗和实时性等要 求,同时尽可能地不降低模型的性能. 当前,主要 有 5 种方法可以获得高效的深度学习模型:直接手 工设计轻量级网络模型、剪枝、量化、基于神经架 构搜索(Neural Architecture Search,NAS)[1]的网络自 动化设计以及知识蒸馏(Knowledge Distillation,KD)[2]. 其中,知识蒸馏作为一种新兴的模型压缩方 法,目前已成为深度学习领域的一个研究热点和重 点. 国内外许多大学和研究机构已经对知识蒸馏展 开了深入研究,并且每年在机器学习和数据挖掘的 国际顶级会议和知名期刊中都有关于知识蒸馏的文 章发表.
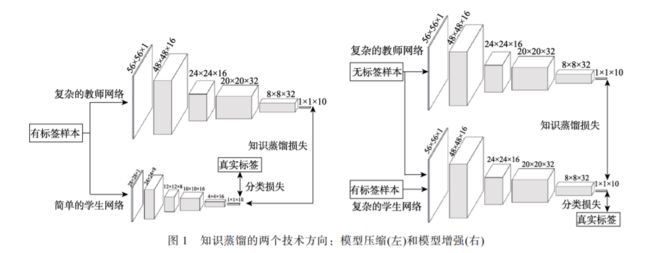
知识蒸馏是一种教师-学生(Teacher-Student)训 练结构,通常是已训练好的教师模型提供知识,学 生模型通过蒸馏训练来获取教师的知识. 它可以以 轻微的性能损失为代价将复杂教师模型的知识迁移 到简单的学生模型中. 在后续的研究中,学术界和 工业界扩展了知识蒸馏的应用范畴,提出了利用知 识蒸馏来实现模型性能的增强. 基于此,本文根据 应用场景划分出基于知识蒸馏的模型压缩和模型增 强这两个技术方向,即获得的网络模型是否为了应 用于资源受限的设备. 图 1 给出了这两种技术对比 的一个例子,其中的教师模型都是提前训练好的复 杂网络. 模型压缩和模型增强都是将教师模型的知 识迁移到学生模型中. 所不同的是,模型压缩是教 师网络在相同的带标签的数据集上指导学生网络的 训练来获得简单而高效的网络模型,如左图的学生 是高效的小规模网络. 模型增强则强调利用其它资 源(如无标签或跨模态的数据)或知识蒸馏的优化策 略(如相互学习和自学习)来提高一个复杂学生模型 的性能. 如右图中,一个无标签的样本同时作为教 师和学生网络的输入,性能强大的教师网络通常能 预测出该样本的标签,然后利用该标签去指导复杂 的学生网络训练.
本文重点收集了近些年在人工智能、机器学习 以及数据挖掘等领域的国际顶级会议(如 ICCV, ICML,EMNLP,KDD)与重要学术期刊(如 PAMI, TOIS,TKDE,TMM)上有关知识蒸馏的论文并加以 整理、归纳和分析. 据我们所知,目前国内没有知 识蒸馏相关的中文综述,而先前两篇英文综述[3,4] 和我们工作相似,但本文进一步完善了知识蒸馏的 综述. 具体地,本文与先前的英文综述[3,4]至少有以 下三点的不同:
(1)先前的研究都忽略了知识蒸馏在模型增强 上的应用前景. 在本文的研究调查中,知识蒸馏不 仅可以用于模型压缩,它还能通过互学习和自学习 等优化策略来提高一个复杂模型的性能. 同时,知 识蒸馏可以利用无标签和跨模态等数据的特征,对 模型增强也具有显著的提升效果.
(2)先前的研究都没有关注到结构化特征知 识,而它在知识架构中又是不可或缺的. 某个结构 上的知识往往不是单一的,它们是有关联的、多个 知识形式组合. 充分利用教师网络中的结构化特征 知识对学生模型的性能提升是有利的,因此它在近 两年的工作中越发重要[5,6].
(3)本文从不同视角给出了基于知识蒸馏的描 述,并提供了更多的知识介绍. 在知识蒸馏的方法 上,本文增加了知识合并和教师助理的介绍;在技 术融合的小节,本文增加了知识蒸馏与自动编码器、 集成学习和联邦学习的技术融合;在知识蒸馏的应 用进展中,本文分别介绍了知识蒸馏在模型压缩和 模型增强的应用,并增加了多模态数据和金融证券 的应用进展;在知识蒸馏的研究趋势展望中,本文 给出了更多的研究趋势,特别是介绍了模型增强的 应用前景.
总的来说,本文在文献[3,4]基础上,以不同的 视角,提供更加全面的综述,以便为后续学者了解 或研究知识蒸馏提供参考指导.
本文组织结构如图 2 所示. 第 2 节回顾了知识 蒸馏的背景知识,包括它的由来;第 3 节解释知识 蒸馏的作用机制,即为什么知识蒸馏是有效的;第 4 节归纳知识蒸馏中知识的不同形式;第 5 节详细 分析了知识蒸馏的各种方法,其强调的是知识迁移 的方式;第 6 节介绍知识蒸馏与其它技术融合的相 关方法;第 7 节归纳知识蒸馏的应用进展;第 8 节 给出了知识蒸馏的研究趋势展望. 最后,第 9 节对 本文工作进行总结.

2. 知识蒸馏的提出
知识蒸馏与较早提出的并被广泛应用的一种机 器学习方法的思想较为相似,即迁移学习[7]. 知识蒸 馏与迁移学习都涉及到知识的迁移,然而它们有以 下四点的不同:
(1) 数据域不同. 知识蒸馏中的知识通常是在同 一个目标数据集上进行迁移,而迁移学习中的知识 往往是在不同目标的数据集上进行转移.
(2) 网络结构不同. 知识蒸馏的两个网络可以是 同构或者异构的,而迁移学习通常是在单个网络上 利用其它领域的数据知识.
(3) 学习方式不同. 迁移学习使用其它领域的丰 富数据的权重来帮助目标数据的学习,而知识蒸馏 不会直接使用学到的权重.
(4) 目的不同. 知识蒸馏通常是训练一个轻量级 的网络来逼近复杂网络的性能,而迁移学习是将已 经学习到相关任务模型的权重来解决目标数据集的 样本不足问题.
3 知识蒸馏的作用机制
Hinton 等人[2]认为,学生模型在知识蒸馏的过 程中通过模仿教师模型输出类间相似性的“暗知识” 来提高泛化能力. 软目标携带着比硬目标更多的泛 化信息来防止学生模型过拟合. 虽然知识蒸馏已经 获得了广泛的应用,但是学生模型的性能通常是仅接 近于教师模型. 特别地,给定学生和教师模型相同的 大小却能够让学生模型的性能超越教师模型[12],性 能越差的教师模型反倒教出了更好的学生模型[13]. 为了更好地理解知识蒸馏的作用,一些工作从数学 或实验上对知识蒸馏的作用机制进行了证明和解 释. 本文归纳为以下几类:
(1) 软目标为学生模型提供正则化约束. 这一 结论最早可以追溯到通过贝叶斯优化来控制网络超 参数的对比试验[14],其表明了教师模型的软目标为 学生模型提供了显著的正则化. 软目标正则化的作 用是双向的,即还能将知识从较弱的教师模型迁移 到能力更强大的学生模型中[15,16]. 一方面,软目标 通过标签平滑训练提供了正则化[15,16],标签平滑是 通过避免了过分相信训练样本的真实标签来防止训 练的过拟合[15]. 另一方面,软目标通过置信度惩罚 提供了正则化[12],置信度惩罚让学生模型获得更好 的泛化能力,其主要依赖于教师模型对正确预测的 信心. 这两种正则化的形式已经在数学上得到了证 明. 总的来说,软目标通过提供标签平滑和置信度 惩罚来对学生模型施加正则化训练. 因此,即使没 有强大的教师模型,学生模型仍然可以通过自己训 练或手动设计的正则化项得到增强[16].
(2) 软目标为学生模型提供了“特权信息” (Privileged Information). “特权信息”指教师模型 提供的解释、评论和比较等信息[17]. 教师模型在训 练的过程中将软目标的“暗知识”迁移到学生模型 中,而学生模型在测试的过程中并不能使用“暗知 识”. 从这个角度看,知识蒸馏是通过软目标来为 学生模型传递“特权信息”.
(3) 软目标引导了学生模型优化的方向. Phuong 等人[18]从模型训练的角度证明了软目标能引导学生 模型的优化方向. 同时,Cheng 等人[19]从数学上验 证了软目标使学生模型比从原始数据中进行优化学 习具有更高的学习速度和更好的性能.
4 蒸馏的知识形式
原始知识蒸馏(Vanilla Knowledge Distillation)[2] 仅仅是从教师模型输出的软目标中学习出轻量级的 学生模型. 然而,当教师模型变得更深时,仅仅学 习软目标是不够的. 因此,我们不仅需要获取教师 模型输出的知识,还需要学习隐含在教师模型中的 其它知识,比如中间特征知识. 本节总结了可以使 用的知识形式有输出特征知识、中间特征知识、关 系特征知识和结构特征知识. 知识蒸馏的 4 种知识 形式的关系如图 5 所示. 从学生解题的角度,这 4 种知识形式可以形象比喻为:输出特征知识提供了 解题的答案,中间特征知识提供了解题的过程,关 系特征知识提供了解题的方法,结构特征知识则提 供了完整的知识体系.

5 知识蒸馏的方法
本节从知识利用的方式,归纳和分析知识蒸 馏的主要方法,包括知识合并、多教师学习、教 师助理、跨模态蒸馏、相互蒸馏、终身蒸馏以及 自蒸馏.

6 知识蒸馏与其它技术的融合
近几年,研究人员发现知识蒸馏结合其它主流 技术通常能够提高其性能. 目前这些主流技术主要 有:生成对抗网络、神经架构搜索、强化学习、图 卷积、其它压缩技术、自动编码器、集成学习以及 联邦学习.

7 知识蒸馏的应用进展
知识蒸馏的最初目的是压缩深度学习网络模 型,这在资源受限的终端设备上具有广泛的应用. 但随着研究的新进展,知识蒸馏不仅可以用于压缩 模型,还可以通过神经网络的互学习、自学习等优 化策略和无标签、跨模态等数据资源对模型的性能 增强也具有显著的提升效果. 目前知识蒸馏的主要 应用领域有计算机视觉、自然语言处理、语音识别、 推荐系统、信息安全、多模态数据和金融证券. 知 识蒸馏在计算机视觉、自然语言处理、语音识别和 推荐系统上的应用根据其目的的不同,可以分为模 型压缩和模型增强. 模型压缩是为了获得简单而高 效的网络模型,以方便部署于资源受限的设备. 而 模型增强通常是利用其它资源(如无标签或跨模态 的数据)来获取复杂的高性能网络.
8 知识蒸馏的研究趋势展望
知识蒸馏是一个新兴的研究领域,它仍有许多 值得深入探索和亟待解决的问题. 在这一节中,我 们提出一些值得进一步深入探讨的研究点,也是我 们今后需要解决完善的研究方向.
(1) 如何确定何种知识是最佳的. 知识蒸馏中 的知识是一个抽象的概念,网络参数,网络的输出 和网络的中间特征等都可以理解为知识. 但是何种 知识是最佳的,或者哪些知识以互补的方式能成为 最佳的通用知识表示?为了回答这个问题,我们需 要了解每种知识以及不同种类组合知识的作用. 比 如说,基于特征的知识通常用于模仿教师特征产生 的过程,基于关系的知识常用于捕获不同样本之间 或网络层之间特征的关系. 当教师和学生的模型容 量(“代沟”)较小的时候,学生只模仿教师的软目 标就可以获得有竞争力的性能. 而当师生的“代沟” 较大时,需要将多种蒸馏的知识形式和方法结合来 表示教师模型. 虽然能明白多种知识的组合方式通 常能提高学生网络的性能,但是使用哪些知识形式, 方法和技术的组合是最优的,还尚无定论.
(2) 如何确定何处的知识是最佳的. 一些工作 随机选择中间网络的某层特征作为知识,比如 FitNets[27]将教师前几层的网络特征作为特征蒸馏的 位置. 然而他们都没有提供一个理由,即为什么能 够成为代表性知识. 这主要是由于教师和学生模型 结构的不一致导致的,即教师模型通常比学生模型 拥有更多的网络层. 因此,需要筛选教师模型中最 具有代表性的特征. 然而教师模型中哪些特征层是 最具有代表性的?这也是一个未解决的问题. 在基 于关系的知识蒸馏中,也一样无法解释该选择哪些 层的关系知识作为学生模仿的对象. 如 FSP 矩阵[31] 随机选择教师模型的两个网络层作为关系蒸馏的位 置. 关系知识蒸馏是容量无关的,即关系蒸馏仅仅 需要获取的是网络层间或样本间的关系知识. 因此 这不是师生间的“代沟”问题,而是归咎于知识其实是一个“黑盒”问题.
(3) 如何定义最佳的师生结构. 知识蒸馏传递 的并不是参数,而是抽取到的知识. 因此知识蒸馏 是网络架构无关的,即任何学生都可以向任何教师 学习. 通常,容量更大的学生模型可以学习更多的 知识,但复杂度过大会延长推理的时间. 容量更大 的教师模型隐含着较多的知识和更强的能力,但是 并非能力越强的教师就能产生更佳的学生模型[13]. 同时,每一个教师模型都有一个最强学生结构[100]. 因此,我们只能在给定的教师模型的前提下,找到 最佳的学生模型. 然而在未指定教师模型的情况 下,目前还无法确定最佳的学生模型.
(4) 如何衡量师生间特征的接近程度. 知识蒸 馏是要将教师网络中的知识迁移到学生模型中,迁 移效果的好坏最终可以通过学生网络性能来体现. 然而在网络训练的过程中,只能通过损失函数去判 断教师和学生之间特征的接近程度. 因此需要提前 设计好知识蒸馏的损失函数,如 KL 散度、均方误 差(Mean Squared Error,MSE)和余弦相似性. 而损 失函数的选取受算法和离群点等因素的影响,并且, 不同损失函数的作用范围是不一样的. 例如,通过 KL 散度衡量的两个随机分布上的相似度是非对称 的. 余弦相似性强调两个向量的特征在方向上的差 异,却没有考虑向量大小. MSE 在高维特征中的作 用不明显,且很容易被随机特征混淆[4]. 因此,衡量 师生间特征接近程度的方法是多样化的,我们需要 根据特定的问题和场景选取最合适的损失函数.
(5) 蒸馏的知识形式、方法和融合技术还需要 深入探索. 原始知识蒸馏将类间的关系信息作为知 识,但这在“代沟”较大的师生网络中效果不佳. 为 了解决这一问题,后续的研究者寻找不同形式的“知 识”来充实知识的内涵,如关系知识. 其知识的来 源应该是多样化的,可以来自于单个或多个的样本 和网络本身. 同样,知识蒸馏的方法和融合技术也 能缓解甚至解决师生间的“代沟”问题,它们强调 充分地利用知识来提高模型的表征能力. 新的知 识形式、方法和融合技术的发现可能会伴随着新的 应用场景,这将丰富知识蒸馏的理论框架和实践的 应用.
(6) 模型压缩和模型增强的深度融合. 模型压 缩是将强大的复杂教师模型中的“知识”迁移到简 单的学生模型中以满足低资源设备的应用要求,而 模型增强用于获取高性能的复杂网络. 模型压缩和 模型增强的融合是将教师模型中的“特权信息”迁 移或继续强化轻量级学生模型的性能. 例如,Liu 等人[206]通过从文本翻译模型中迁移“特权信息”来改 进轻量级的语音翻译模型. 在未来的工作中,甚至 能将无标签或其它领域数据的“特权信息”来继续 加强一个轻量级学生模型的性能.
(7) 知识蒸馏在数据样本增强上的应用. 深度 学习是数据驱动型的,往往需要大规模的数据集才 能避免过度拟合. 由于隐私和法律等原因,在一些 领域上,通常无法获取大规模的原始数据集,如医 疗数据. 知识蒸馏需要足够的数据,才能将教师网 络中的知识迁移到学生网络中. 换句话说,数据是 连接教师网络和学生网络的桥梁. 先前的研究已经 证明了知识蒸馏在数据样本增强上的广阔应用前景, 如通过知识蒸馏产生原始数据集的近似样本[207]、 使用其它相关数据的知识来减轻对目标数据集的依 赖[208]以及教师和学生间部分网络的共同训练来提 高具有小样本学生网络的性能[114]. 未来的工作需 要继续探索知识蒸馏在数据样本增强上的应用场景 和高效的蒸馏方法来实现小样本学习(Few-Shot Learning)或零样本学习(zero-shot learning).
(8) 知识蒸馏在数据标签上的应用. 给数据上 标签需要特定领域的专业知识、大量的时间和成本. 可以利用知识蒸馏减少标注训练数据的麻烦,解决 数据标签的问题. 如果该领域存在着强大的教师网 络,能通过知识蒸馏给无标签的数据增加注释. 具 体地,教师网络对未标记数据进行预测,并使用它 们的预测信息充当学生模型数据的自动标注[209]. 以无标签数据作为输入的教师网络会产生软标签, 这恰好能为学生网络提供学习的指导信息. 即使该 领域没有强大的教师网络,也可以通过跨模态知识 蒸馏,将其它领域的知识充当无标签数据的监督信 号[66]. 因此,知识蒸馏能够减少对数据标签的依赖, 需要继续研究它在半监督或无监督学习上的应用.
最近文章
EMNLP 2022 和 COLING 2022,投哪个会议比较好?
一种全新易用的基于Word-Word关系的NER统一模型,刷新了14种数据集并达到新SoTA
阿里+北大 | 在梯度上做简单mask竟有如此的神奇效果
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
下载二:南大模式识别PPT 后台回复【南大模式识别】投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看