Python+OpenCV人脸识别(基于LBPH+防照片识别+警报)
目录
废话
1.环境配置(jupyter notebook python 3.6.5)
2.训练集准备
3.代码思路(艹图)
4.人脸识别源码
5.参考文章
6.可能遇到的问题
废话
嗯,开局说点废话,之前用stm32和esp8266改装了下宿舍门,但终究觉得没人脸识别来得舒服,所以就有了这篇文章
1.环境配置(jupyter notebook python 3.6.5)
我这里用的是python3.6,如果你想搭建一个3.6的环境又不想影响原有的,可以用小黑窗(Anaconda Prompt)搭建一个虚拟环境(虚拟环境是一个独立的空间不会影响外界,也不会受外界影响,适合应对不同版本python的需求)
如何搭建虚拟环境可以看看这篇文,简单粗暴
当你搭建好虚拟环境后,第三方库的安装也要安在虚拟环境里,那么如何切换到虚拟环境里呢
打开小黑窗
activate 虚拟环境名字
就可以激活了效果如下:

看到小括号就说明已经切换到虚拟环境里了
然后就可以安装所需的第三方库了,eg.Opencv,scipy,request,dlib,安装方法如下:
1)OpenCV
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python==3.4.2.16pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-python==3.4.2.162)scipy
pip install scipy
3) request
pip install request4) dlib
dlib库的安装比较麻烦,你得先找到对应版本,因为不同python版本对应不同dlib
如果你跟我一样是3.6,那装19.7就行
缺版本或找不到对应版本可以留言
2.训练集准备
这个训练集捏,是借助recognizer.train得到的.yml文件,所以精度没特别高,但是拿来玩玩门锁 还是够用,追求精度可以走深度学习
代码如下:
1)第一步准备照片(即你的人脸像),以“序号.名称”命名,例如“1.xx"这是为了方便切片和保存(即我们可以通过切片将每张照片的脸部特征,序号,名称一一对应)记得你照片的存放路径
2)第二步准备人脸数据集haarcascade_frontalface_alt2.xml,这个是opencv自带的用于检测人脸(注意是检测人脸不是识别人脸)这种做法我觉得有点像RIO ,就是我们在一张图片中匹配人像特征不是从角落开始,而是定位人脸,然后规划一个区域,在区域内进行匹配,这样节省很多时间
3)第三步,跑代码就完事了,然后你会在你指定的文件夹里面找到yml文件,这就是你的训练集
import os
import sys
from PIL import Image
import numpy as np
import cv2
def getImageAndLabels(path):
#建两个空列表后续存储数据
facesSamples=[]
ids=[]
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
#检测人脸
face_detector = cv2.CascadeClassifier('E:\jupyter_notebook\practice\haarcascades\haarcascade_frontalface_alt2.xml')
#打印数组imagePaths
print('路径:',imagePaths)
#遍历列表中的图片
for imagePath in imagePaths:
#打开图片,灰度
PIL_img=Image.open(imagePath).convert('L')
#此时获取的是整张图片的数组
img_numpy=np.array(PIL_img,'uint8')
#获取图片人脸特征,相当于rio
faces = face_detector.detectMultiScale(img_numpy)
#将文件名前的名字转化为ID并记录下来
str_id = os.path.split(imagePath)[1].split('.')[0]
id = int(str_id)
#id = os.path.split(imagePath)[1].split('.')[0]
#预防检测到无面容照片
for x,y,w,h in faces:
#把ID写进ids列表中
ids.append(id)
#把所画的方框写进facesSamples列表中
facesSamples.append(img_numpy[y:y+h,x:x+w])
#打印脸部特征和id
print('id:', id)
print('fs:', facesSamples)
return facesSamples,idsif __name__ == '__main__':
#图片路径
path='E:/face_dormitory/train'
#获取图像数组和id标签数组和姓名
faces,ids=getImageAndLabels(path)
#获取训练对象
recognizer=cv2.face.LBPHFaceRecognizer_create()
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('E:/face_dormitory/opencv/trainer/trainer_xx.yml')3.代码思路(艹图)
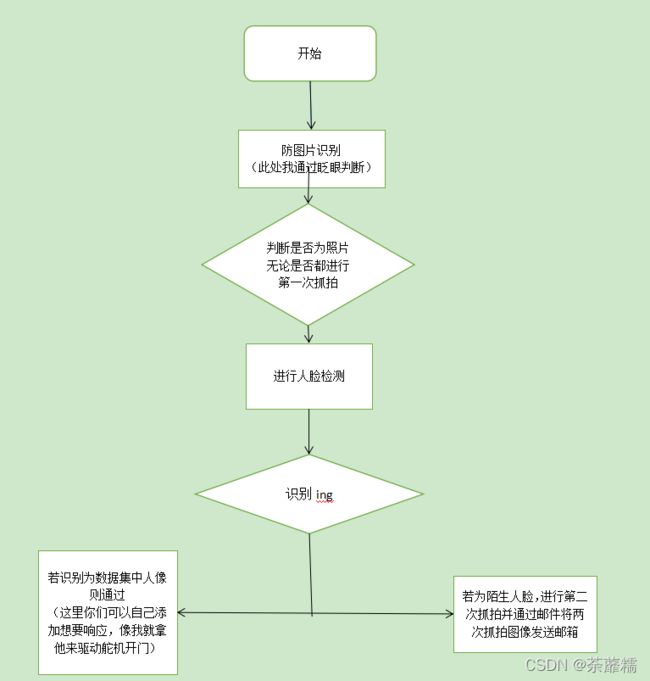
4.人脸识别源码
1)引入库
import cv2
import numpy as np
import os
import urllib
import urllib.request
import hashlib
from scipy.spatial import distance as dist
from collections import OrderedDict
import argparse
import time
import dlib2)加载训练集(这里shape_predictor_68_face_landmarks是用于眨眼检测的)
#加载训练数据集文件
recogizer=cv2.face.LBPHFaceRecognizer_create()
recogizer.read('E:/face_dormitory/opencv/trainer/trainer_xx.yml')
names=[] #建个空id列表
warningtime = 0
predictor = dlib.shape_predictor('E:/face_dormitory/opencv/shape_predictor_68_face_landmarks.dat')3)邮件函数(即识别出陌生人或可疑人用于发送抓拍照片的)
import smtplib
from PIL import Image
import email # 文件名不可以和引入的库同名
from email.mime.image import MIMEImage # 图片类型邮件
from email.mime.text import MIMEText # MIME 多用于邮件扩充协议
from email.mime.multipart import MIMEMultipart # 创建附件类型
HOST = 'smtp.qq.com' # 调用的邮箱借借口
SUBJECT = 'Warning!!!' # 设置邮件标题
FROM = '[email protected]' # 发件人的邮箱需先设置开启smtp协议
#TO = '[email protected]' # 设置收件人的邮箱(可以一次发给多个人,用逗号分隔)
TO = '[email protected]' # 设置收件人的邮箱(可以一次发给多个人,用逗号分隔)
message = MIMEMultipart('related') # 邮件信息,内容为空 #相当于信封##related表示使用内嵌资源的形式,将邮件发送给对方
def sendmail(HOST, SUBJECT,FROM,TO,message):
# ===========发送信息内容=============
message_html = MIMEText('Warning!!!
 ', 'html', 'utf-8')
message.attach(message_html)
# ===========发送图片-=============
message_image0 = MIMEText(open('E:/face_dormitory/unidentified/0.jpg', 'rb').read(), 'base64', 'utf-8')
message_image0['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 设置图片在附件当中的名字
message_image1 = MIMEText(open('E:/face_dormitory/unidentified/1.jpg', 'rb').read(), 'base64', 'utf-8')
message_image1['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 设置图片在附件当中的名字
message.attach(message_image0)# 添加图片文件到邮件-附件中去
message.attach(message_image1)# 添加图片文件到邮件-附件中去
'''
path='E:/face_dormitory/unidentified'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
PIL_img=Image.open(imagePath,'utf-8')
PIL_img['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'
message.attach(PIL_img)
'''
# ===========删除缓冲图片-=============
#os.remove('E:/face_dormitory/unidentified/0.jpg')
#os.remove('E:/face_dormitory/unidentified/1.jpg')
# ===========发送excel-附件=============
#message_xlsx = MIMEText(open('email_demo.xlsx', 'rb').read(), 'base64', 'utf-8')# 将xlsx文件作为内容发送到对方的邮箱读取excel,rb形式读取,对于MIMEText()来说默认的编码形式是base64 对于二进制文件来说没有设置base64,会出现乱码
#message_xlsx['Content-Disposition'] = 'attachment;filename="email_demo_change.xlsx"'# 设置文件在附件当中的名字
#message.attach(message_xlsx)# 添加excel文件到邮件-附件中去
# ===========配置相关-=============
message['From'] = FROM # 设置邮件发件人
message['TO'] = TO # 设置邮件收件人
message['Subject'] = SUBJECT # 设置邮件标题
email_client = smtplib.SMTP_SSL()# 获取传输协议
email_client.connect(HOST, '465')# 设置发送域名,端口465
result = email_client.login(FROM, 'xxxxxxx') # qq授权码
print('登录结果', result)
# ===========操作=============
email_client.sendmail(from_addr=FROM, to_addrs=TO.split(','), msg=message.as_string()) #发送邮件指令
email_client.close()# 关闭邮件发送客户端
', 'html', 'utf-8')
message.attach(message_html)
# ===========发送图片-=============
message_image0 = MIMEText(open('E:/face_dormitory/unidentified/0.jpg', 'rb').read(), 'base64', 'utf-8')
message_image0['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 设置图片在附件当中的名字
message_image1 = MIMEText(open('E:/face_dormitory/unidentified/1.jpg', 'rb').read(), 'base64', 'utf-8')
message_image1['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'# 设置图片在附件当中的名字
message.attach(message_image0)# 添加图片文件到邮件-附件中去
message.attach(message_image1)# 添加图片文件到邮件-附件中去
'''
path='E:/face_dormitory/unidentified'
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
PIL_img=Image.open(imagePath,'utf-8')
PIL_img['Content-disposition'] = 'attachment;filename="Suspicious people.jpg"'
message.attach(PIL_img)
'''
# ===========删除缓冲图片-=============
#os.remove('E:/face_dormitory/unidentified/0.jpg')
#os.remove('E:/face_dormitory/unidentified/1.jpg')
# ===========发送excel-附件=============
#message_xlsx = MIMEText(open('email_demo.xlsx', 'rb').read(), 'base64', 'utf-8')# 将xlsx文件作为内容发送到对方的邮箱读取excel,rb形式读取,对于MIMEText()来说默认的编码形式是base64 对于二进制文件来说没有设置base64,会出现乱码
#message_xlsx['Content-Disposition'] = 'attachment;filename="email_demo_change.xlsx"'# 设置文件在附件当中的名字
#message.attach(message_xlsx)# 添加excel文件到邮件-附件中去
# ===========配置相关-=============
message['From'] = FROM # 设置邮件发件人
message['TO'] = TO # 设置邮件收件人
message['Subject'] = SUBJECT # 设置邮件标题
email_client = smtplib.SMTP_SSL()# 获取传输协议
email_client.connect(HOST, '465')# 设置发送域名,端口465
result = email_client.login(FROM, 'xxxxxxx') # qq授权码
print('登录结果', result)
# ===========操作=============
email_client.sendmail(from_addr=FROM, to_addrs=TO.split(','), msg=message.as_string()) #发送邮件指令
email_client.close()# 关闭邮件发送客户端写邮件函数我是借鉴这个大佬的,站在巨人肩膀上嘛,总不能什么都靠自己来
4)防照片检测(即眨眼检测)这个也可以用于疲劳检测
详见:i·bug - resources - Facial point annotations
FACIAL_LANDMARKS_68_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 36)),
("jaw", (0, 17))
])def eye_aspect_ratio(eye):
# 计算距离,竖直的
A = dist.euclidean(eye[1], eye[5])
B = dist.euclidean(eye[2], eye[4])
# 计算距离,水平的
C = dist.euclidean(eye[0], eye[3])
# ear值
ear = (A + B) / (2.0 * C)
return eardef shape_to_np(shape, dtype="int"):
# 创建68*2
coords = np.zeros((shape.num_parts, 2), dtype=dtype)
# 遍历每一个关键点
# 得到坐标
for i in range(0, shape.num_parts):
coords[i] = (shape.part(i).x, shape.part(i).y)
return coordsdef pervent_to_photo():
# 设置判断参数
EYE_AR_THRESH = 0.3
EYE_AR_CONSEC_FRAMES = 3
# 初始化计数器
COUNTER = 0
TOTAL = 0
# 检测与定位工具
print("loading facial landmark predictor...")
detector = dlib.get_frontal_face_detector()
#predictor = dlib.shape_predictor('E:/face_dormitory/opencv/shape_predictor_68_face_landmarks.dat')
# 分别取两个眼睛区域
(lStart, lEnd) = FACIAL_LANDMARKS_68_IDXS["left_eye"]
(rStart, rEnd) = FACIAL_LANDMARKS_68_IDXS["right_eye"]
# 读取视频
print("starting video stream thread...")
vs = cv2.VideoCapture(0)
time.sleep(1.0)
# 遍历每一帧
while True:
# 预处理
frame = vs.read()[1]
if frame is None:
break
(h, w) = frame.shape[:2]
width=1200
r = width / float(w)
dim = (width, int(h * r))
frame = cv2.resize(frame, dim, interpolation=cv2.INTER_AREA)
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 检测人脸
rects = detector(gray, 0)
# 遍历每一个检测到的人脸
for rect in rects:
# 获取坐标
shape = predictor(gray, rect)
shape = shape_to_np(shape)
# 分别计算ear值
leftEye = shape[lStart:lEnd]
rightEye = shape[rStart:rEnd]
leftEAR = eye_aspect_ratio(leftEye)
rightEAR = eye_aspect_ratio(rightEye)
# 算一个平均的
ear = (leftEAR + rightEAR) / 2.0
# 绘制眼睛区域
leftEyeHull = cv2.convexHull(leftEye)
rightEyeHull = cv2.convexHull(rightEye)
cv2.drawContours(frame, [leftEyeHull], -1, (0, 255, 0), 1)
cv2.drawContours(frame, [rightEyeHull], -1, (0, 255, 0), 1)
# 检查是否满足阈值
if ear < EYE_AR_THRESH:
COUNTER += 1
else:
# 如果连续几帧都是闭眼的,总数算一次
if COUNTER >= EYE_AR_CONSEC_FRAMES:
TOTAL += 1
# 重置
COUNTER = 0
# 显示
cv2.putText(frame, "Blinks: {}".format(TOTAL), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.putText(frame, "EAR: {:.2f}".format(ear), (300, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
cv2.imshow("Frame", frame)
#眨眼两次则判断不是照片
if TOTAL >= 2:
cv2.imwrite(r"E:/face_dormitory/unidentified/"+"1.jpg",frame) #抓拍
break
#空格退出
if ord(' ') == cv2.waitKey(10):
break
#vs.release()
cv2.destroyAllWindows()5)人脸检测函数
#准备识别的图片
def face_detect_demo(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)#转换为灰度
face_detector=cv2.CascadeClassifier('E:\jupyter_notebook\practice\haarcascades\haarcascade_frontalface_alt2.xml') #加入数据集
face=face_detector.detectMultiScale(gray,1.1,5,cv2.CASCADE_SCALE_IMAGE,(100,100),(300,300)) #范围在100*100~300*300判断为脸
for x,y,w,h in face:
cv2.rectangle(img,(x,y),(x+w,y+h),color=(0,0,255),thickness=2)
cv2.circle(img,center=(x+w//2,y+h//2),radius=w//2,color=(0,255,0),thickness=1)
# 人脸识别
ids, confidence = recogizer.predict(gray[y:y + h, x:x + w])
#置信评分 confidence 越大越不可信
if confidence > 50:
global warningtime
global num
warningtime += 1
if warningtime > 100:
#cv2.imwrite(r"E:/face_dormitory/unidentified/"+str(num)+".jpg",frame) #抓拍
cv2.imwrite(r"E:/face_dormitory/unidentified/"+"0.jpg",frame) #抓拍
time.sleep(0.1)
sendmail(HOST=HOST, SUBJECT=SUBJECT,FROM=FROM,TO=TO,message=message)
print('ddddddddddd')
#num += 1
warningtime = 0
cv2.putText(img, 'unidentified', (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
else:
cv2.putText(img,str(names[ids-1]), (x + 10, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.75, (0, 255, 0), 1)
cv2.imshow('result',img)#取名函数,切片取名,即照片名为1.cj.jpg,取名后就为cj
def name():
#相册路径
path = 'E:/face_dormitory/train'
#循环读图
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
#切名字
name = str(os.path.split(imagePath)[1].split('.',2)[1])
names.append(name)6)主函数
#防照片识别
pervent_to_photo()
#打开摄像头,0是本地默认,1是外用,我把本地关了把外用开着所以直接0
cap=cv2.VideoCapture(0)
name()
while True:
flag,frame=cap.read()
if not flag:
break
face_detect_demo(frame)
#空格退出
if ord(' ') == cv2.waitKey(10):
break
cv2.destroyAllWindows()
cap.release()
5.参考文章
感谢大佬1
感谢大佬2
感谢大佬3
6.可能遇到的问题
1.如果你搭建了虚拟环境且里面安装了opencv,但是再引用的时候报错没装库,看看有没有将虚拟环境导入kernel

2.如果你发现我的逻辑有问题,相信你自己,错的肯定是我,请务必怼我,毕竟有探讨才有完善,我也是个小菜鸡
3.如果出现”No module named XXX“,说明安装差库了,请跑到虚拟环境里去安装,虚拟环境是独立的,你之前安装了什么都跟虚拟环境无关