【机器学习】音乐表示Music Representation
音乐基本术语
- velocity (i.e. bar or body speed)
- A tempo is how fast the beats go by in a particular piece of music.
- quality:音程性质
音乐符号化表示(Symbolic)
- 最基本的音乐信息(Events):在何时起止(Onset、Offset)什么绝对音高(MIDI pitch)。
- 元信息:该音乐数据的名称是什么,包含什么声部、使用什么音色播放。
- 基本音乐学信息:基本的如小节线、速度、拍号、调式等,以及进一步的信息如表情记号(连线、跳音、延长音、重音、强弱)、反复、临时升降号等。
- 高层音乐学信息:乐句、和弦、分段、情绪。
因为最基础的MIDI文件只需要起止(Onset、Offset)、绝对音高(MIDI pitch)就可以播放了(音色之类的都可以设为默认如钢琴),因此才会造成数据如此杂乱。MusicXML格式就好得多,因为其是一个面向乐谱显示或排版的格式,包含基本音乐学信息是其基础。
MIDI(Musical Instrument Digital Interface)
 MIDI Events
MIDI Events
Piano-Roll

MusicXML
MusicXML文件分为两种类型:score-partwise与score-timewise,其中较为常见的是score-partwise。
score-partwise
谱子信息,XML文件信息
各声部信息
声部1全曲:
小节1:
属性
音符1
音符2
……REMI(revamped MIDI-derived events)
基于节拍事件(Beat-based)
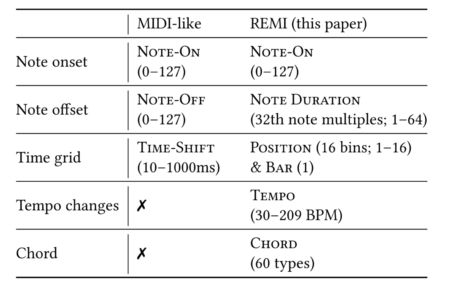
REMI用时值取代MIDI编码里的音符关(Note off),用小节(Bar)和位置(Position)取代MIDI编码里的时移,并且增加了音乐速度与和弦信息。REMI编码将音乐编码成按照小节、位置、和弦、音乐速度、音高、时值、力度依次排列的离散token序列
 The Bar, Position and Tempo-related events entail the use of audio domain downbeat and beat tracking algorithms
The Bar, Position and Tempo-related events entail the use of audio domain downbeat and beat tracking algorithms
相比MIDI-like,REMI的异同:
Note-On和Note Velocity
Note-On事件表示某一特定音高的音的开始事件,Node Velocity则表示响度。这两种事件在Midi-like和REMI表示中都存在。
Note-Off和Note-Duration
在REMI中,使用Note-Duration取代了Note-off,将一个音符用三个连续的token表示:Note Velocity,Note-On,Note-Duration。 这样做主要有两个原因:
- MIDI-like表示中,必须通过开始结束之间的gap推断时值,通过专门的时值事件表示更为清晰直接
- MIDI-like表示中的开始事件与结束事件往往中间间隔若干其他事件,这使得成对出现关系的学习存在困难
Time-Shift和Position & Bar
以固定时值出现的位置&小节(Position & Bar)事件取代原先伴随音符的时间偏移(Time-Shift)事件,能够在音乐数据表示中加入度量结构,避免基于Time-Shift的模型中时间错误累积的问题。Position&Bar更多优点:
- (1)更容易学习不同小节中同一位置的音符的相关关系
- (2)便于添加小节级别的约束关系
- (3)在多音轨/多乐器音乐创作中,以位置&小节表示作为时间参照,便于协调多个不同声部
Tempo
用于考虑速度变化(比如常见的beats per minute; BPM)。这类事件在MIDI乐谱中不一定存在,但是在MIDI演奏数据中可以通过对音频进行乐曲速度估计得到。
Chord
按根音和类型定义的共60种和弦被作为额外的支持符号(supportive token)输入给模型。
节拍(beat)追踪与强拍(downbeat)追踪
为了获取Bar事件位置,本文使用RNN从音频中估计得到强拍(downbeat)位置,并用线性插值的方法得到节拍位置。这样的表示方式可以得到更规则的时间(节奏)序列。
和弦识别
使用基于规则的启发式方法进行符号域和弦识别。遍历片段中的每个音作为可能的和弦根音,并通过与其他音的音程关系计算似然得分,最终得到和弦估计。

Compound Word Representation(CP)
为了进一步缩减REMI编码的序列长度,CP提出将REMI编码的离散token序列转化为以复合词为时间单位的token序列
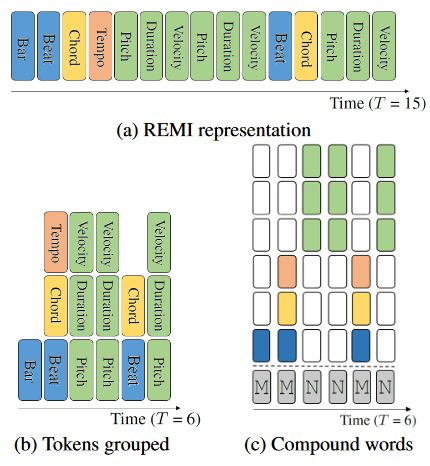
Corpus2Event
# ---- define event ---- #
''' 8 kinds:
tempo: 0: IGN (ignore)
1: no change
int: tempo
chord: 0: IGN
1: no change
str: chord types
bar-beat: 0: IGN
int: beat position (1...16)
int: bar (bar)
type: 0: eos
1: metrical
2: note
duration: 0: IGN
int: length
pitch: 0: IGN
int: pitch
velocity: 0: IGN
int: velocity
'''
# event template
compound_event = {
'tempo': 0,
'chord': 0,
'bar-beat': 0,
'type': 0,
'pitch': 0,
'duration': 0,
'velocity': 0,
}
# event生成的过程 process : 每一个bar,中的每一个tick
final_sequence = []
for bar_step in range(0, global_end, BAR_RESOL):
final_sequence.append(create_bar_event())
# --- piano track --- #
for timing in range(bar_step, bar_step + BAR_RESOL, TICK_RESOL):
pos_on = False
pos_events = []
pos_text = 'Beat_' + str((timing-bar_step)//TICK_RESOL)
...metrical (tempo+chord)
...for note in notes
...
if len(pos_events):
final_sequence.extend(pos_events)
# BAR ending
final_sequence.append(create_bar_event())
# EOS
final_sequence.append(create_eos_event()) event2word
# --- build dictionary --- #
# all files
class_keys = pickle.load(
open(os.path.join(path_indir, eventfiles[0]), 'rb'))[0].keys()
print('class keys:', class_keys)
# define dictionary
event2word = {}
word2event = {}
corpus_kv = collections.defaultdict(list)
for file in eventfiles:
for event in pickle.load(open(
os.path.join(path_indir, file), 'rb')):
for key in class_keys:
corpus_kv[key].append(event[key])
for ckey in class_keys:
class_unique_vals = sorted(
set(corpus_kv[ckey]), key=lambda x: (not isinstance(x, int), x))
event2word[ckey] = {key: i for i, key in enumerate(class_unique_vals)}
word2event[ckey] = {i: key for i, key in enumerate(class_unique_vals)}OctupleMIDI
Multi-track MIDI 编码方式被提出用于对多个音轨同时编码,具有对和声建模的优势。为了进一步缩短编码长度,并提供足够丰富的音乐信息,OctupleMIDI编码将每个音符编码成一个包含拍号、音乐速度、小节、位置、乐器、音高、时值、力度这8个元素的元组。更短的序列长度可以使模型一次性处理更长的音乐片段,从而提升模型的建模能力。用在MusicBERT中。

Python音乐表示库
Music21库
music21可以处理包括MusicXML,MIDI,abc等多种格式的音乐文件,并可以从零开始构建音乐文件或对音乐进行分析。它读取midi文件时,输出是一个个音符object,甚至如果多个音符同时按响,输出就是一个和弦object。而不是一个动作。
import music21
mid = music21.converter.parse("twinkle-twinkle-little-star.mid") # 读取midi文件
for note in mid[0].flat.notes: # 所有的音符
print(note, note.duration.type, note.offset) # 音符, 时长, 位置
#输出
>>> quarter 0.0
>>> half 0.0
>>> quarter 1.0
>>> quarter 2.0
>>> half 2.0
>>> quarter 3.0 音符
f = note.Note("F5#") #创建一个音高为F5#的音符
f.name #音符的音名
f.step #音符的音级(不包含变化音及八度信息的音名,这里成为音级严格来说并不准确)
f.pitch.pitchClassString #音级(以C为0级的音程数)
f.octave #八度
f.pitch #音符的音高,返回一个音高对象
f.duration #音符的时值,返回一个时值对象
f.duration.type #音符的时值的类型 'quarter','half'
f.pitch.midi
#改变属性
f.duration.dots #改变符点数量
f.duration.quarterLength #直接改变时值,以四分音符计
f.pitch.accidental #变化音的类型和弦
cMajor = chord.Chord(["E3","C4","G4"]) #初始化和弦
cMajor.add(note.Note("E3")) #添加和弦
cMajor.duration.quarterLength=2 #和弦也可以修改时值Stream
类似list的基本单位,它可以储存任意music21对象及其组合。
stream1 = stream.Stream() #创建
stream1.append(f)
stream1.insert(0,f)
stream1.repeatAppend(f, 4) #重复添加
stream1.show('text') #显示小节 (Measure)
乐谱Score
MusPy库
MusPy documentation — MusPy documentation (salu133445.github.io) https://salu133445.github.io/muspy/
https://salu133445.github.io/muspy/
- 数据集准备,可以对接PyTorch和TensorFlow。
- 数据的读取和预处理,支持了常见格式,有这和其他库合作的接口。支持数种常见表示。
- 模型的评估算法和工具,包括音频渲染、乐谱可视化、pianoroll可视化,以及指标计算。
允许的四种表示方式

Musicaiz库(2022)
MusicAIz — Musicaiz 0.0.2 documentationhttps://carlosholivan.github.io/musicaiz/index.html
支持提供了音乐生成客观评价指标
Python工具包
Miditoolkit
import miditoolkit
midi_obj = miditoolkit.midi.parser.MidiFile(path_midi)
print(midi_obj)
"""
Output:
ticks per beat: 480
max tick: 72002
tempo changes: 68
time sig: 2
key sig: 0
markers: 71
lyrics: False
instruments: 2
"""Tempo and Beat Resolution
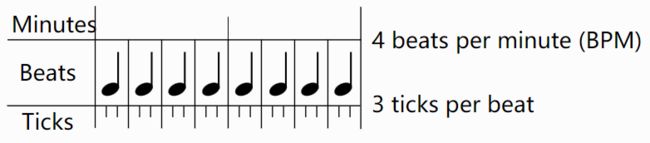
Timing in MIDI files is centered around ticks and beats. A beat is the same as a quarter note. Beats are divided into ticks, the smallest unit of time in MIDI.
Madmom
Introduction — madmom 0.17.dev0 documentationhttps://madmom.readthedocs.io/en/latest/introduction.html
- madmom 是一个音频信号处理库,主要用于音乐信号提取(MIR)
- 提取特征和使用它的HMM包来提取beat和downbeat(即音乐节拍和强拍)并计算多种评价指标得分
from madmom.audio.signal import SignalProcessor, FramedSignalProcessor
from madmom.audio.stft import ShortTimeFourierTransformProcessor
from madmom.audio.spectrogram import (
FilteredSpectrogramProcessor, LogarithmicSpectrogramProcessor,
SpectrogramDifferenceProcessor)
from madmom.processors import ParallelProcessor, Processor, SequentialProcessor多线程提取频谱特征以及频谱的一阶差分
def madmom_feature(wav):
sig = SignalProcessor(num_channels=1, sample_rate=44100)
multi = ParallelProcessor([])
frame_sizes = [1024, 2048, 4096]
num_bands = [3, 6, 12]
for frame_size, num_bands in zip(frame_sizes, num_bands):
frames = FramedSignalProcessor(frame_size=frame_size, fps=100)
stft = ShortTimeFourierTransformProcessor() # caching FFT window
filt = FilteredSpectrogramProcessor(
num_bands=num_bands, fmin=30, fmax=17000, norm_filters=True)
spec = LogarithmicSpectrogramProcessor(mul=1, add=1)
diff = SpectrogramDifferenceProcessor(
diff_ratio=0.5, positive_diffs=True, stack_diffs=np.hstack)
# process each frame size with spec and diff sequentially
multi.append(SequentialProcessor((frames, stft, filt, spec, diff)))
# stack the features and processes everything sequentially
pre_processor = SequentialProcessor((sig, multi, np.hstack))
feature = pre_processor.process( wav)
return feature用madmom自带的HMM模块处理beat和downbeat联合检测算法生成的激活值
from madmom.features.downbeats import DBNDownBeatTrackingProcessor as DownBproc
hmm_proc = DownBproc(beats_per_bar = [3,4], num_tempi = 80,
transition_lambda = 180,
observation_lambda = 21,
threshold = 0.5, fps = 100)
#act是用神经网络等音频节拍检测算法处理得到的激活值
beat_fuser_est = hmm_proc(act)
beat_pred = beat_fuser_est[:,0]
downbeat_pred = beat_pred[beat_fuser_est[:,1]==1]对节拍检测结果和节拍标注值计算多种评估指标:
from madmom.evaluation.beats import BeatEvaluation
scr = BeatEvaluation(beat_pred,beat_true)
print(scr.fmeasure,scr.pscore,scr.cemgil,scr.cmlc,scr.cmlt,
scr.amlc,scr.amlt)liborsa
- librosa.beat:用于检测速度和节拍
- librosa.core:用于从磁盘加载音频和计算各种频谱图
- librosa.decompose:实现矩阵分解进行谐波和冲击源分离通用频谱图分解
- librosa.display:音频特征的显示
- librosa.effects:时域音频处理,音高变换和时间拉伸,时域包装器。
- librosa.feature:特征提取和操作:色度图,伪常数Q(对数频率)变换,Mel频谱图,MFCC和调谐估计
- librosa.filters:滤波器生成色度。伪CQT、CQT等
- librosa.onset:其实检测和起始强度计算。
- librosa.segment:用于结构分段的函数
- librosa.swquence:顺序建模功能
- librosa.util:辅助工具(规范化。填充、居中)
References
Pop Music Transformer:基于节拍事件表示的流行钢琴作品的建模与生成 - 知乎
AI之歌,旋律动人 - 知乎