【Redis缓存】
一、使用Redis缓存的优点
相比于数据库而言,缓存的操作性能更高,缓存性能高的主要原因有以下几点:
1、缓存一般都是key-value查询数据的,因为不像数据库一样还有查询的条件等因素,所以查询的性能一般会比数据库高;
2、缓存的数据是存储在内存当中的,而数据库的数据是存储在磁盘当中的,因为内存的操作性能远远大于磁盘,因此缓存的查询效率会高很多;
3、缓存更容易做分布式部署(当一台服务器变成多台相连的服务器集群),而数据库一般比较难实现分布式部署,因此缓存的负载和性能更容易平行扩展和增加。
二、缓存分类
缓存大致分为两大类:本地缓存、分布式缓存
本地缓存:也叫单机缓存,也就是说可以应用在单机环境下的缓存,所谓的单机环境是指,将服务部署到一台服务器上。本地缓存的特征是只适用于当前系统。
分布式缓存:是指可以应用在分布式系统中的缓存,所谓的分布式系统是指将一套服务器部署到多台服务器,并且通过负载分发将用户的请求按照一定的规则分发到不同服务器。
三、常见缓存使用
1、本地缓存:Spring Cache
在Spring Boot项目当中,我们可以直接使用Spring的内置Cache(本地缓存)。
三个步骤:①开启缓存
在SpringBoot启动类上添加注解,以说明开启缓存:
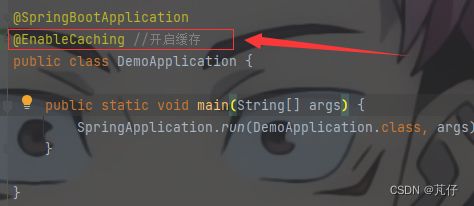
添加@EnableCaching注解即可开启缓存。
②操作缓存
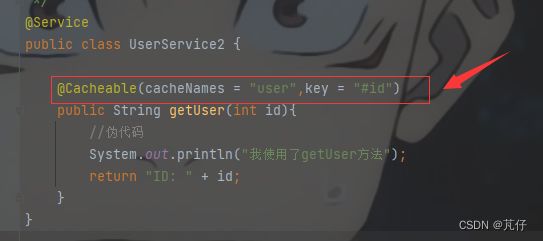
在方法前添加注解@Cacheable,其中的参数分别表示:(1)cacheNames表示缓存的名字,这个名字对应的缓存是一个map的集合(2)以传递的id作为key值,整个方法所返回的信息作为value。
③调用缓存
首先我们设置访问地址接口,通过这个地址来调用UserService2当中使用缓存的方法。
接着我们使用postman来访问这个地址接口,观察打印台输出的信息
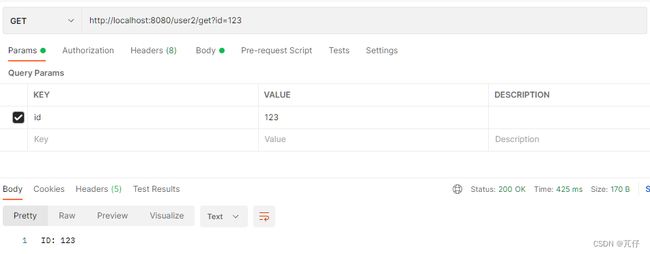
当我们第一次传递参数为123时,IDEA打印台的信息如下:
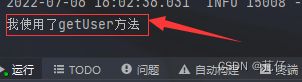
伪代码表示我们查询数据库,将数据库查询到的结果返回给客户端,并且将本次的查询结果存储到缓存当中。
当我们第二次传递参数为123时,IDEA打印台的信息如下:
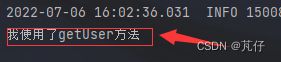
可以看到,并没有打印出“我使用了getUser方法”,这是因为,当第一次传递参数为123时,缓存当中就存储了key值为123的这个键值对,当第二次进行访问时,服务器先会在缓存当中查询是否存在key值为123的键值对,如果存在,则直接将这个key值对应的value返回给客户端,不再进行数据库的查询,如果不存在,则就会对数据库进行查询,查询的结果同样会存储到缓存当中。这样一来,对于频繁需要使用的数据,就可以直接从缓存当中获取,从而大大降低数据库的压力。
扩展:@Cacheable当中的cachNames参数有何意义?
答:用来指定缓存组件的名字,将方法的返回结果放在哪个缓存中,可以是数组的方式,支持指定多个缓存。一台服务器可以有多组缓存,分别存储不同的信息,指定这个参数之后,就表示此次缓存的数据存放在哪一组缓存当中。
2、分布式缓存:Redis
分布式缓存是针对于多项目环境下的服务器,对于一台服务器,可能部署了多个项目,不同的项目操作的是同一个Redis,因此Redis对于整个服务器来说是全局(分布式)的。
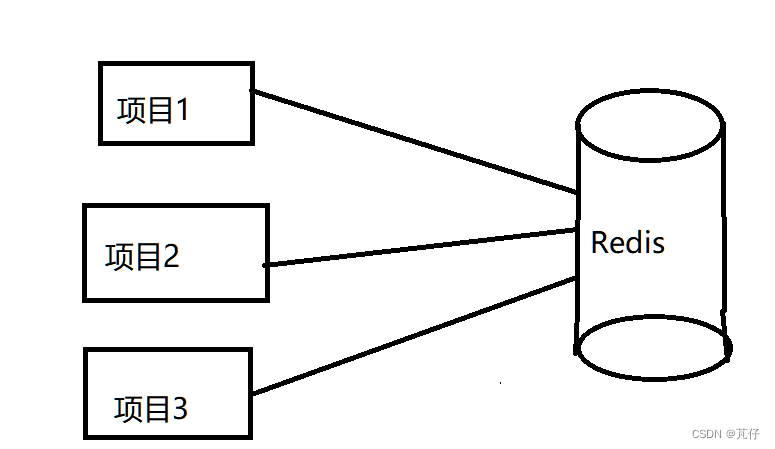
例如:项目1对服务器发起请求,服务器将项目1的响应数据存储到了Redis当中,当项目2发起和项目1同样的请求的时候,Redis就可以将这条缓存数据返回给项目2,这样一来,就实现了项目之间的数据共享性,大大降低数据库的压力。
总结:通常情况下,如果是单机Spring项目,会直接使用SpringCache作为本地缓存,如果是分布式环境一般会使用Redis。
扩展:分布式缓存为什么使用Redis而不使用Memcached?
- 存储方式不同:Memcached把数据全部存贷内存之中,断电之后会挂掉,数据不能超过内存大小;Redis有部分存储在硬盘上,这样就保证数据的持久性
- 数据支持类型:Memcached对数据类型支持相对简单;Redis有复杂的数据类型
- 存储大小不同:Redis最大可以达到512mb,Memcached只有1mb
3、Redis数据类型和使用
Redis有5大基础数据类型:
-
String——字符串类型(简称SDS)
以Key-Value的形式进行存储,根据Key来存储和获取Value的值。
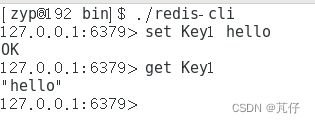
通过set存储键值对,通过get来以key获取value。
设置过期时间:

通过ex + 秒数,设置这个键值对的过期时间。可以看到图中10秒过后再去获取就为nil(表示为null)了。
-
Hash——字典类型
字典类型是将一个键值(key)和一个特殊的“哈希表”关联起来,这个哈希表包含两个字段:字段和值,相当于java当中的Map

注意:此处的第一个String,即key不能出现相同的。一旦出现同名的,就会使用新的value覆盖同字段的旧值。

同样的,也可以为这个key新增字段:

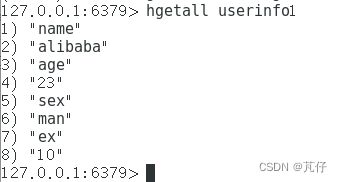
获取这个key的所有字段和value:
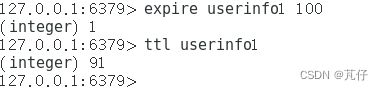
设置过期时间以及查看还有多久过期(单位:秒),这个方式可以针对多种数据类型:
-
List——列表类型

第一行表示创建一个名为namelist的列表,列表中含有这四个名字。
这个列表是一个使用链表结构存储的有序结构,元素的插入会按照先后顺序存储到链表结构中,因此它的元素操作(插入和删除)时间复杂度为O(1),但是它的查询复杂度为O(n)。使用了头插法,并且删除也是删除第一个元素。
使用rpush就可以实现先进先出的功能,同时又可以使用lpop来将第一个元素弹出。

-
Set——集合类型
集合类型是一个无序并唯一的键值集合。

当集合中已经存在的元素,则会插入失败。
-
ZSet——有序集合类型

在有序集合类型当中,它自身会根据你的大小关系进行排序存储。
四、Redis的持久化
所谓的持久化就是将数据从内存保存到磁盘的过程,其目的是为了防止数据丢失,因为内存当中的数据在服务器重启之后就会丢失,而磁盘的数据则不会。
Redis持久化有三种方式:
- 快照方式(RDB)将某一时刻的内存数据,以二进制的方式写入磁盘。
- 文件追加方式(AOF)记录所有的操作命令,并以文本的形式追加到文件当中。
- 混合持久化方式,结合了RDB和AOF的优点,在写入的时候,先把当前的数据以RDB的形式写入文件的开头,再将后续的操作命令以AOF的格式存入文件,这样既能保证Redis重启时的速度,又能降低数据丢失的风险。
开启混合持久化:
开启之后,redis就会以混合持久化方式来作为持久化策略。默认是使用RDB持久化的方式。
开启文件追加方式(AOF)命令为:config set appendonly yes

RDB优缺点分析:
优点:
- RDB的内容为二进制的数据,占用内存更小,更紧凑,更适合作为备份文件。
- RDB对灾难恢复非常有用,它是一个紧凑的文件,可以更快的传输到远程服务器进行Redis服务恢复。
- RDB可以更大程度的提高Redis的运行速度,因为每次持久化时Redis主进程都会fork()一个子进程进行数据持久化到磁盘,Redis主进程并不会执行磁盘I/O等操作。
- 与AOF格式的文件相比,RDB文件可以更快的重启。
缺点:
- 因为RDB只能保存某个时刻的数据,如果途中Redis服务被意外终止了,则会丢失一段时间内的Redis数据。
- RDB需要经常fork()才能使用子进程将其持久化在磁盘当中,如果数据集很大,fork()可能很耗时,并且如果数据集很大且CPU性能不佳,则可能导致Redis停止为客户端服务几毫秒甚至一秒钟。
AOF优缺点分析:
优点:
- AOF持久化保存的数据更加完整,AOF提供了三种保存策略:每次操作保存、每秒钟保存一次、跟随系统的持久化策略保存,其中每秒保存一次从数据的安全性和性能两方面考虑是一个十分不错的选择,也是AOF默认的策略,即使发生了意外,最多值丢失1s的数据。
- AOF采用的是命令追加的写入方式,所以不会出现文件损坏的问题,即使由于某些意外原因,导致了最后操作的持久化数据写入一半,也是可以通过redis-check-aof工具轻松的修复。
- AOF持久化文件,非常容易理解和解析,它是把所有Redis键值操作命令,以文件的方式存入到磁盘,即使不小心使用flushall命令删除了所有键值信息,只要使用AOF文件,删除最后的flushall命令,重启Redis即可恢复之前误删的数据。
缺点:
- 对于相同的数据集来说,AOF文件要大于RDB文件
- 在Redis负载比较高的情况下,RDB要比AOF性能突出
- RDB使用快照的形式来持久化整个Redis数据,而AOF只是将每次执行的命令追加到AOF文件中,因此从理论上说,RDB比AOF更加健壮。
混合持久化优点:混合持久化结合了RDB和AOF持久化的优点,开头为RDB的格式,使得Redis可以更快的启动,同时结合了AOF的优点,又降低了大量数据丢失的风险。
混合持久化缺点:
- AOF文件中添加了RDB格式的内容,使得AOF文件的可读性变得很差。
- 兼容性差,如果开启混合持久化,那么此混合持久化AOF文件,就不能用在Redis4.0之前的版本。
五、关于缓存的常见问题
1、缓存雪崩
缓存雪崩是指在较短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而导致数据库造成巨大压力,严重时可能会导致数据库宕机的情况叫做缓存雪崩。
解决方案:
- 加锁排队,加锁排队可以起到缓冲的作用,防止大量的请求同时操作数据库,但他的缺点也很明显,增加了系统的响应时间,降低了系统的吞吐量,牺牲掉一部分用户的体验。
- 随机化过期时间,为了避免缓存同时过期,可在设置缓存时添加随机时间,这样就可以极大的避免大量的缓存同时失效。
- 设置二级缓存,二级缓存是指除了Redis自身外,再设置一层缓存,当Redis失效之后,先去查询二级缓存,再去查询数据库。
2、缓存穿透
缓存穿透是指查询数据库和缓存都无数据,因为数据库查询没有数据,出于容错的考虑,不会将结果保存到缓存当中,因此每次请求都会查询数据库,这种情况叫做缓存穿透。
解决方案:
每次查询数据库时,无论数据库是否返回数据,都将这个结果存储到缓存当中,这样的话,当第二次查询的时候,即便查询结果为空,也不会直接访问数据库查询,Redis就会将这个空数据进行返回。
3、缓存击穿
缓存击穿是指某个热点请求,在某一高峰使用时刻恰好失效了,然后此时刚好有大量的并发请求,此时这些请求将会给数据库造成巨大压力,这种情况就叫做缓存击穿。
解决方案:
- 加锁排队
- 设置永不过期,对于某些高频使用的数据,我们设置永不过期,但是需要注意此条数据一旦发生更改,要及时更新此热点缓存,不然就会造成查询结果的误差。
4、缓存预热
缓存预热并非一个问题,而是使用缓存手段时的一种优化方案。
缓存预热是指在系统启动的时候,先把查询结果预存到缓存当中,以便用户后面查询时可以直接从缓存中读取,以节约用户的等待时间。
实现思路:
- 把需要缓存的方法写在系统初始化的方法中,这样系统启动时就会自动加载数据并缓存数据。
- 把需要缓存的方法挂载到某个页面或后端接口上,手动触发缓存预热。
- 设置定时任务,定时自动进行缓存预热。