CAP定理与分布式事务之两阶段提交和三阶段提交的理解
一 数据一致性
在数据越来越多的背景下,数据的可用性与可靠性要得到保障。 可用性指服务能正常响应请求,返回相关数据。而可靠性自然是指数据的准确性。数据想做到可用与可靠,就需要数据有副本,而有副本则会同步数据,就会牵扯到数据的一致性
二 数据的一致性分类
强一致性:
当有操作发生的时候,用户在任一时刻访问或者进程与线程查询,都会获得最新更新过的数据。这种数据上比较友好,但在分布式场景下会牺牲可用性
弱一致性:
当有操作更新过后,任何访问并不保证一定获得最新的更新的数据。 当数据发生更新之后,系统不承诺多久之后可以读到更新的数据。 用户需要一段时间才能读到操作更新后的数据,这一段时间,称为 “不一致性窗口”
最终一致性:
在没有后续操作更新的情况下,系统最终会返回上一次更新后的数据,属于弱一致性的特例。不一致性窗口的时间取决于系统负载和副本的数量。
顺序一致性:
系统所有进程的顺序上是一致的,而且是合理的。不需要与全局时钟下的顺序一致,错的话一起错,对的话一起对。任何一次读都能读到某个数据的最近一次写的数据
三 CAP理论
也叫布鲁尔定理。
C: Consistency 一致性。主要指站在客户端的角度来看,任意时刻所访问的数据总能获得相同的结果
A: Avaliablitiy 可用性。何为可用? 是指 系统在合理的时间范围内,总是能给请求返回结果。 主要强调为 一定的时间、合理的时间
P: Partition Tolerance 分区容错性。 某个节点故障或者网络分区,本是一个网络区域分裂成了多个,互相不能通信的时候。又或者是多个网络区域突然发生故障不能通信的时候。比如分布式下 A B C三个网络区域本是互相通信互相调用,突然发生了故障,不能通信了。
cap表达的就是 在分布式的环境下,在网络分区发生的时候,cap三个特性只能满足2个。
在没有发生网络分区的时候,此时只有AC
在发生网络分区的时候,即在网络区域不通的时候,假设A区域数据发生了变化,却同步不到B区域,那么用户在查询B区域的数据时,要么及时响应旧数据(可用性:AP),要么就是一直等下去 (一致性 CP),等到数据更新了返回。
四 分布式事务之二阶段提交
以 A发起转账100元给B为例:
| id | money | pre_change |
| 1 | 1000 | 0 |
表决阶段:
此阶段主要进行资源的检查和预留。 由协调器通知事务参与者发起表决,同意(该参与者本地执行成功)或者拒绝(该参与者本地执行失败)。同时资源也会在这一步进行锁定 update tablex set money=money-100,pre_change=pre_change+100 where id =1
提交阶段:
协调者在收到参与者的表决后,将依据各个参与者的投票结果来决定进行commit或者cancel操作。然后释放所有的资源。
confirm资源提交操作执行真正的业务,cancel预留资源的取消:update tablex set money=money+100,pre_change=pre_change-100 where id =1
当且仅当所有的参与者都同意提交事务时,协调者才会通知参与者commit操作,否则就会通知参与者cancel操作(包括有的参与者在第一阶段挂掉了,丢包,超时等,协调者都会通知cancel)
两阶段的缺点:
1. 执行过程中,资源会阻塞。当有其他节点访问此资源时会处于阻塞状态
2. 一旦协调者在通知参与者表决后挂掉,则整个资源会处于阻塞状态
3. 若协调者刚通知参与者commit或者cancel操作,只有一个参与者收到了通知,参与者执行后和协调者都挂掉了,此时会造成数据不一致。其他参与者根本不清楚是哪种操作
4. 若第二阶段参与者挂掉了,协调者有重试机制,无大碍,但系统应该具有幂等性。
5. 因为网络会有超时与丢包的现象,所以会产生空回滚和事务悬挂的问题
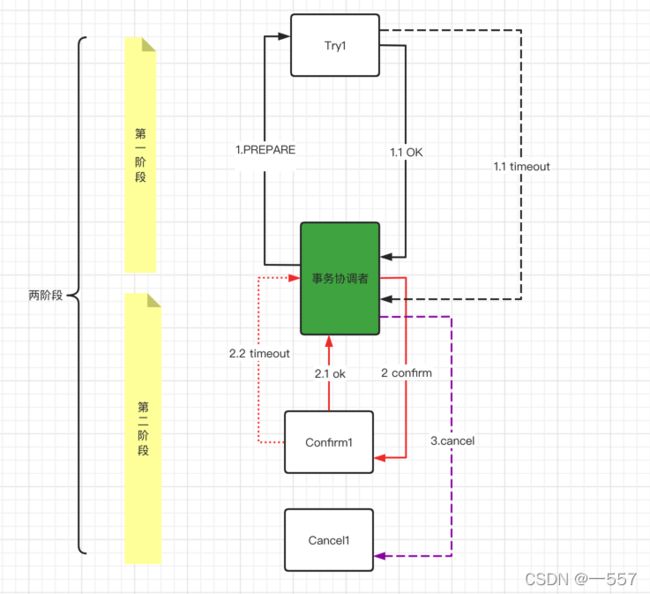
空回滚:就是在一阶段尚未执行时,先执行了rollback. (此图片参考与网络)
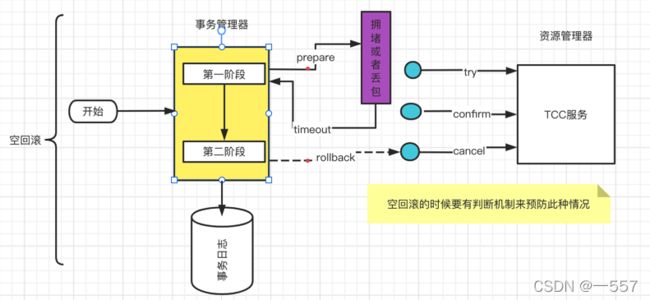
事务悬挂:就是rollback执行了之后,第一阶段才开始执行。(此图参考与网络)
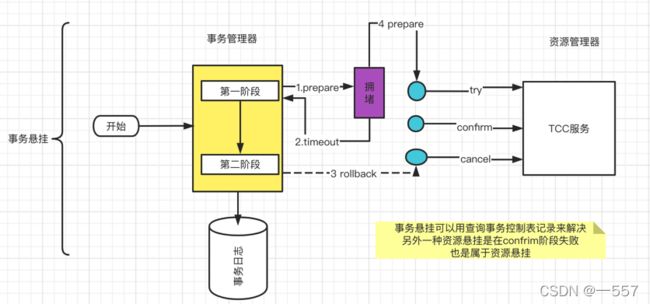
空回滚与事务悬挂可以用插入查询事务控制表等方式来结局。若是confirm失败导致的事务悬挂,可以异步重试来结局,通过扫描事务控制表的方式找到失败的记录。
五 分布式事务之三阶段提交
三阶段就是把二阶段的prepare阶段拆分了 2个阶段。有 CanCommit PreCommit DoCommit阶段
协调者和参与者都引入了超时的机制,在第三阶段若参与者超时未收到响应,则会执行commit操作。两阶段里只有协调者有超时机制,在时间内未收到请求,则会认为失败
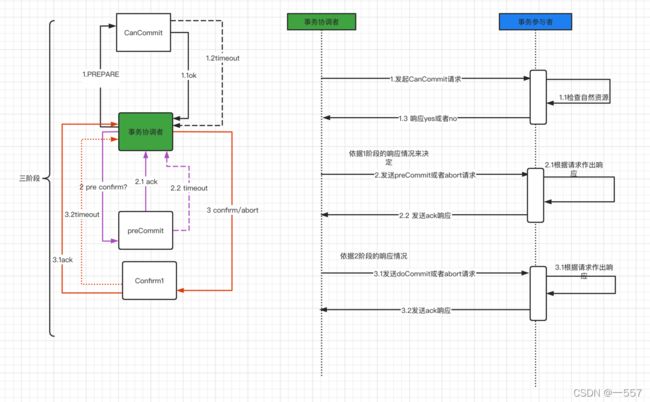
1. CanCommit
协调者向参与者发起询问 commit请求,参与者检查自身资源回复yes 或者no
询问:协调者向所有参与者发起CanCommit请求,询问是否可以执行事务预提交的操作,然后等待参与者的响应
反馈:参与者检查自然资源,若可以预执行则回复yes,否则回复no
2.PreCommit
协调者根据各个参与者CanCommit的回复,作出处理。 有两种情况:
A若各个参与者都回复yes:
协调者发送预提交请求:协调者向参与者发送PreCommit请求,进入Prepare阶段并等待参与者的反馈
参与者执行事务预提交:参与者收到PreCommit后,执行事务的预提交。并且记录undo与redo的信息日志,即update tablex set money=money-100,pre_change=pre_change+100 where id =1.
参与者反馈:若参与者成功执行了预提交之后,则回馈ack信息给协调者,然后开始等待最终的指令,若超时未收到,则会执行Commit操作
B若某个参与者回复no或者超时未响应:
发送中断请求:协调者向参与者发送abort的请求
执行事务中断:参与者收到abort请求,执行事务的中断。注意 参与者超时未收到协调者的请求,也会执行中断事务操作,保障了CanCommit之后协调者挂掉了,资源不会锁住
3. DoCommit
此阶段进行真正的事务提交。协调者根据PreCommit的响应,来决定是否提交事务
提交:
若PreCommit都成功的回了ack,则协调者通知参与者提交事务
发送提交请求:协调者从预提交阶段到提交阶段,向所有参与者发送DoCommit请求
事务提交:参与者收到了DoCommit请求后(或者超时未收到请求),则会执行事务的提交,并且在提交后释放所有的资源
响应反馈:参与者在事务完成后,会向协调者发送ack响应
完成事务:协调者收到了所有的参与者ack之后,则完成整个事务
中断:
发起事务中断请求:若某个参与者超时未响应,则协调者会通知参与者中断事务。发送abort请求
事务回滚:参与者在收到abort请求后,用在二阶段的undo日志,进行事务的回滚。并且回滚完成之后,释放所有的资源
响应反馈:参与者在完成回滚之后,发送ack响应给协调者
中断事务:协调者收到了参与者的ack消息后,标记事务的终端
两阶段与三阶段区别:
协调者与参与者都引入了超时机制
1. 若第一阶段参与者响应请求后协调者突然挂掉,则2阶段的参与者超时会执行abort操作
2. 若协调者再发送PreCommit之后挂断掉,则3阶段参与制会超时执行commit操作
3.若第一阶段或者第二阶段参与者响应之后挂掉,则协调者超时会第三阶段执行abort操作
4.若3阶段参与者挂掉,则需要重试机制,系统应具有幂等性。
三阶段的缺点:
数据不一致:若第2阶段执行PreCommit之后,有一个参与者超时未响应,协调者发送abort请求后,仅有一个参与者收到请求并且执行了的时候,协调者与此参与者都挂掉的情况下,其他参与者会因为超时执行commit操作,造成数据不一致的情况
此种情况两阶段提交也会发生:
若协调者刚通知参与者commit或者cancel操作,只有一个参与者收到了通知,参与者执行后和协调者都挂掉了,其他参与者根本不清楚是哪种操作,执行事务后也可能会造成数据不一致。