数据挖掘之K-means聚类算法
实验七、数据挖掘之K-means聚类算法
一、实验目的
1. 理解K-means聚类算法的基本原理
2. 学会用python实现K-means算法
二、实验工具
1. Anaconda
2. sklearn
3. matplotlib
三、实验简介
1 K-means算法简介
k-means算法是一种聚类算法,所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。聚类与分类最大的区别在于,聚类过程为无监督过程,即待处理数据对象没有任何先验知识,而分类过程为有监督过程,即存在有先验知识的训练数据集。
2 K-means算法原理
k-means算法中的k代表类簇个数,means代表类簇内数据对象的均值(这种均值是一种对类簇中心的描述),因此,k-means算法又称为k-均值算法。k-means算法是一种基于划分的聚类算法,以距离作为数据对象间相似性度量的标准,即数据对象间的距离越小,则它们的相似性越高,则它们越有可能在同一个类簇。数据对象间距离的计算有很多种,k-means算法通常采用欧氏距离来计算数据对象间的距离
四、实验内容
1. 随机生成100个数,并对这100个数进行k-mean聚类(k=3,4,5,6)(并用matplot画图)
- 数字聚类不是很明显看出效果
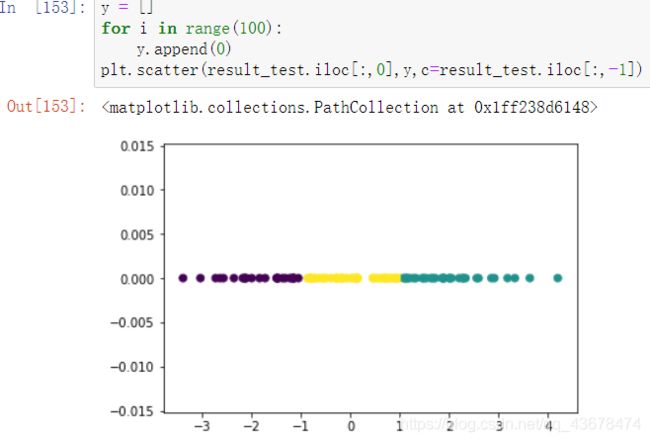
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
#可以内嵌绘图
from sklearn.datasets.samples_generator import make_blobs
def distEclud(arrA,arrB): #欧氏距离
d = arrA - arrB
dist = np.sum(np.power(d,2),axis=1) #差的平方的和
return dist
def randCent(dataSet,k): #寻找质心
n = dataSet.shape[1] #列数
data_min = dataSet.min()
data_max = dataSet.max()
#生成k行n列处于data_min到data_max的质心
data_cent = np.random.uniform(data_min,data_max,(k,n))
return data_cent
def kMeans(dataSet,k,distMeans = distEclud, createCent = randCent):
x,y = make_blobs(centers=100)#生成k质心的数据
x = pd.DataFrame(x)
m,n = dataSet.shape
centroids = createCent(dataSet,k) #初始化质心,k即为初始化质心的总个数
clusterAssment = np.zeros((m,3)) #初始化容器
clusterAssment[:,0] = np.inf #第一列设置为无穷大
clusterAssment[:,1:3] = -1 #第二列放本次迭代点的簇编号,第三列存放上次迭代点的簇编号
result_set = pd.concat([pd.DataFrame(dataSet), pd.DataFrame(clusterAssment)],axis = 1,ignore_index = True)
#将数据进行拼接,横向拼接,即将该容器放在数据集后面
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
dist = distMeans(dataSet.iloc[i,:n].values,centroids) #计算点到质心的距离(即每个值到质心的差的平方和)
result_set.iloc[i,n] = dist.min() #放入距离的最小值
result_set.iloc[i,n+1] = np.where(dist == dist.min())[0] #放入距离最小值的质心标号
clusterChanged = not (result_set.iloc[:,-1] == result_set.iloc[:,-2]).all()
if clusterChanged:
cent_df = result_set.groupby(n+1).mean() #按照当前迭代的数据集的分类,进行计算每一类中各个属性的平均值
centroids = cent_df.iloc[:,:n].values #当前质心
result_set.iloc[:,-1] = result_set.iloc[:,-2] #本次质心放到最后一列里
return centroids, result_set
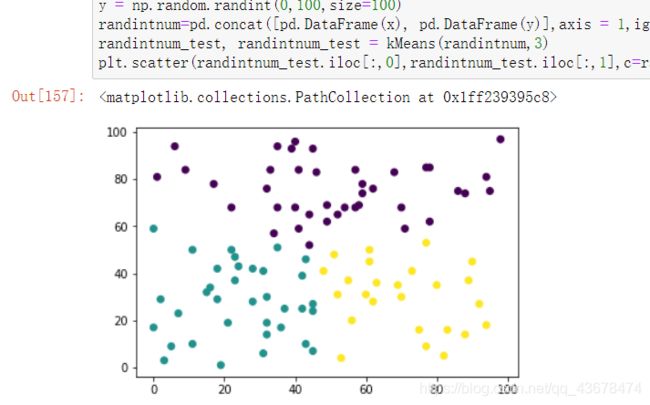
- 于是我用了100个随机点
x = np.random.randint(0,100,size=100)
y = np.random.randint(0,100,size=100)
randintnum=pd.concat([pd.DataFrame(x), pd.DataFrame(y)],axis = 1,ignore_index = True)
randintnum_test, randintnum_test = kMeans(randintnum,3)
plt.scatter(randintnum_test.iloc[:,0],randintnum_test.iloc[:,1],c=randintnum_test.iloc[:,-1])
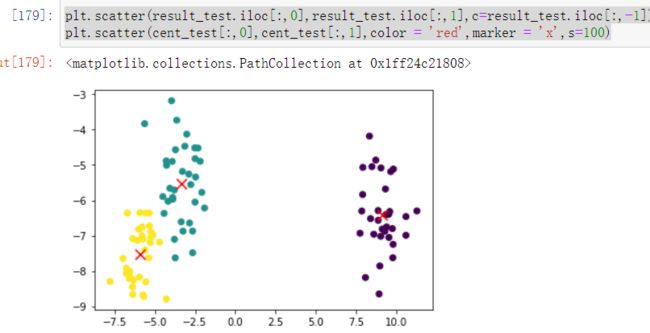
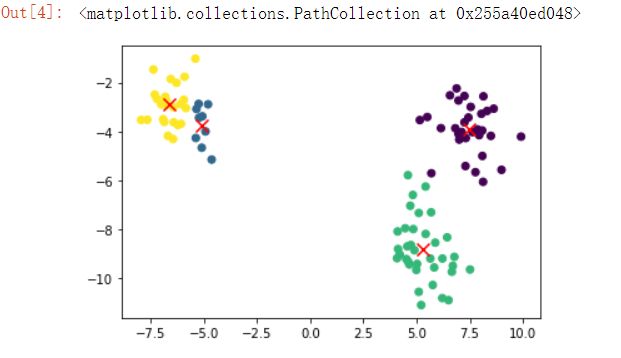
- 最为明显的是通过百度的函数make_blobs最为明显,这也是专门生成聚类数据的函数
plt.scatter(result_test.iloc[:,0],result_test.iloc[:,1],c=result_test.iloc[:,-1])
plt.scatter(cent_test[:,0],cent_test[:,1],color = 'red',marker = 'x',s=100)
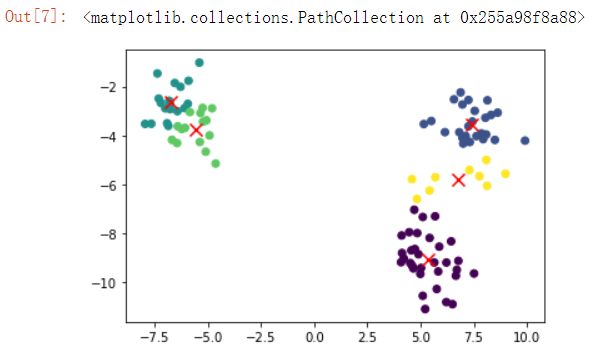
2. 对鸢尾花数据进行K-means算法聚类(并用matplot画图)。
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
%matplotlib inline
#可以内嵌绘图
#导入数据集
from sklearn.datasets import load_iris
iris_dataset=load_iris()
data=iris_dataset['data'] #获取鸢尾花数据集
label=iris_dataset['target'] #获取标签列表
data=pd.DataFrame(data) #从array转换成DataFrame形式
label = pd.DataFrame(label)
def distEclud(arrA,arrB): #欧氏距离
d = arrA - arrB
dist = np.sum(np.power(d,2),axis=1) #差的平方的和
return dist
def randCent(dataSet,k): #寻找质心
n = dataSet.shape[1] #列数
data_min = dataSet.min()
data_max = dataSet.max()
#生成k行n列处于data_min到data_max的质心
data_cent = np.random.uniform(data_min,data_max,(k,n))
return data_cent
def kMeans(dataSet,k,distMeans = distEclud, createCent = randCent):
m,n = dataSet.shape
centroids = createCent(dataSet,k) #初始化质心,k即为初始化质心的总个数
clusterAssment = np.zeros((m,3)) #初始化容器
clusterAssment[:,0] = np.inf #第一列设置为无穷大
clusterAssment[:,1:3] = -1 #第二列放本次迭代点的簇编号,第三列存放上次迭代点的簇编号
result_set = pd.concat([pd.DataFrame(data),pd.DataFrame(label), pd.DataFrame(clusterAssment)],axis = 1,ignore_index = True)
#将数据进行拼接,横向拼接,即将该容器放在数据集后面
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
dist = distMeans(dataSet.iloc[i,:n].values,centroids) #计算点到质心的距离(即每个值到质心的差的平方和)
result_set.iloc[i,n+1] = dist.min() #放入距离的最小值
result_set.iloc[i,n+2] = np.where(dist == dist.min())[0] #放入距离最小值的质心标号
clusterChanged = not (result_set.iloc[:,-1] == result_set.iloc[:,-2]).all()
if clusterChanged:
cent_df = result_set.groupby(n+2).mean() #按照当前迭代的数据集的分类,进行计算每一类中各个属性的平均值
centroids = cent_df.iloc[:,:n].values #当前质心
result_set.iloc[:,-1] = result_set.iloc[:,-2] #本次质心放到最后一列里
return centroids, result_set
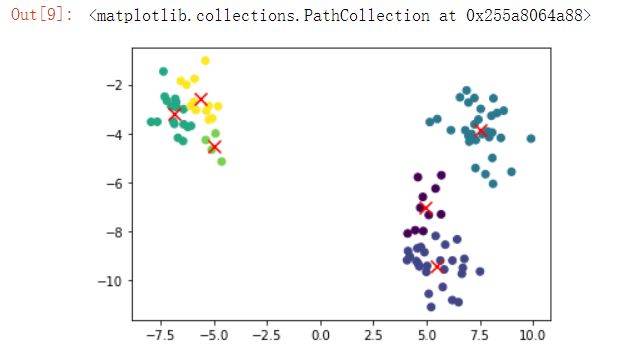
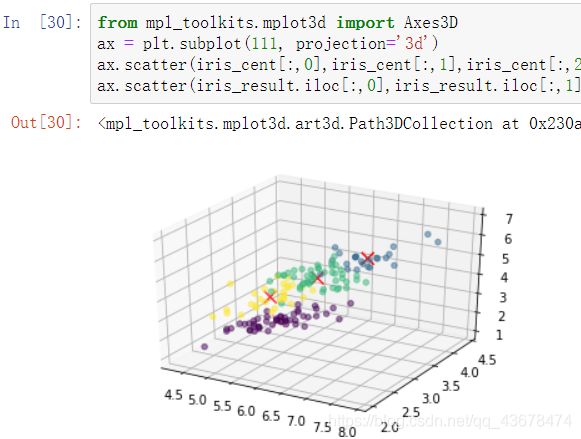
iris_cent,iris_result = kMeans(data, 4)
from mpl_toolkits.mplot3d import Axes3D
ax = plt.subplot(111, projection='3d')
ax.scatter(iris_cent[:,0],iris_cent[:,1],iris_cent[:,2],color = 'red',marker = 'x',s=100)
ax.scatter(iris_result.iloc[:,0],iris_result.iloc[:,1],iris_result.iloc[:,2],c=iris_result.iloc[:,-1],alpha=0.5)
聚成四类之后
- 最终质心
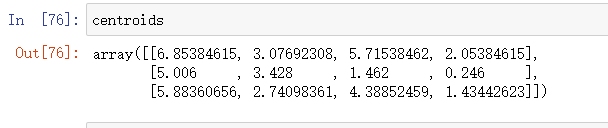
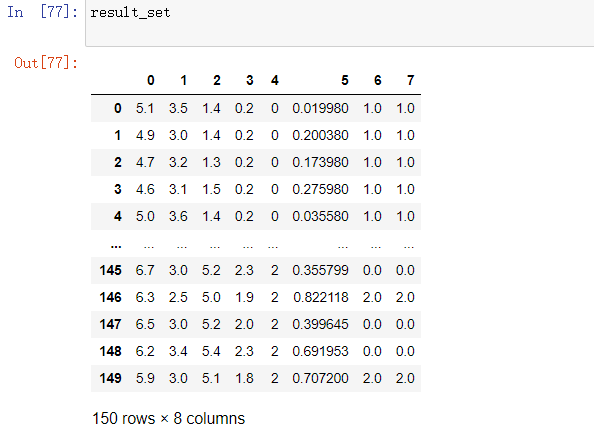
- 形成的数据表,0-4列为鸢尾花数据,第五列为每个值到质心的差的平方和,六七列为本次和上次的分类属性
- 类别统计
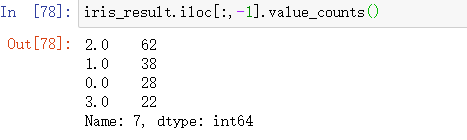
- SSE

- 划分为四类的3D图
五、实验总结(写出本次实验的收获,遇到的问题等)
对于groupby函数一开始怎么也不明白,搜索之后看到一个图便十分明了
聚类步骤即先随机定义k个点(质心),然后遍历每个点,对每个质心计算质心与数据点之间的距离,将数据点分配到据其最近的簇对每个簇。一轮下来后计算簇中所有点的均值并将均值作为新的质心,循环进行直到簇不再发生变化或者达到最大迭代次数或者很少变化。
另外在数据类型的问题上困扰了好久,比如iloc的使用,以及array与dataFrame的转化方法
在3D画图中质心会被较密的点掩盖