一篇文章入门循环神经网络RNN
NLP
一、循环神经网络
1、文本的tokenization
tokenization:分词,分出的每一个词语就是token
中英文分词的方法:把句子转化为词语、把句子转化为单个字
2、N-gram表示方法
句子可以用单个字、词语表示,同时我们也可以用2个、3个或者多个词来表示
N-gram一组一组的词语,其中的N表示能够被一起使用的词的数量
import jieba
text = "深度学习是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法"
# lcut(): The main function that segments an entire sentence that contains Chinese characters into separated words.
cuted = jieba.lcut(text)
n_grams = [cuted[i:i + 2] for i in range(len(cuted) - 1)]
print(n_grams)
3、向量化
自然语言文本是非结构化的,从文本中抽象出机器学习算法认识的特征向量的方法:将自然语言文本的每个词作为一个特征。因此对应的特征向量即这些特征的组合(基于这种思想的模型就是词袋模型(Bag of Words),也叫向量空间模型(Vector Space Model))
文本的维度:特征词的数量
文本不能够直接被模型计算,所以要将其转化为向量
把文本转化为向量有两种方法:
- 转化为one-hot编码
- 转化为word-embedding
(1)one-hot编码
在one-hot编码中,每一个token使用一个长度为N的向量表示,N表示词典的数量
one-hot编码/独热编码:设词典的大小为n(词典中有n个词),假如某个词在词典中的位置为k,则设立一个n维向量,第k维置1,其余维全都置0
把待处理的文档进行分词或者是N-gram处理,然后进行去重得到词典
one-hot使用稀疏向量表示文本,占用空间多

一个样本的特征向量即该样本中的每个单词的one-hot向量直接相加
涉及到的单词很多时,词典会变得超大,动辄几千上万维。因此每个样本的特征向量也会变得极其稀疏(大部分维度的值为0),这么高的维数对于很多机器学习模型比如神经网络,那简直是训练的灾难
one-hot编码会忽略单词的语义
(2)word embedding
word-embedding/词向量/词嵌入:将单词编码成低维实数向量(将单词映射到一个低维空间)
word embedding使用了浮点型的稠密矩阵来表示token,根据词典的大小,我们的向量通常使用不同的维度,例如:100/256/300等,其中向量中的每一个值是一个超参数,其初始值是随机生成的,之后会在训练的过程中进行学习而获得
如果我们文本中有20000个词语,如果使用one-hot编码,那么我们会有20000*20000的矩阵,其中大多数的位置都为0,但我们如果使用word embedding来表示的话,只需要2000*维度,比如20000*300

我们会把所有的文本转化为向量,把句子用向量表示
但是在这中间,我们会把token使用数字来表示,再把数字使用向量来表示
即:token---->num---->vector

将单词映射到低维空间可以表示单词之间的语义关系
比如我们的词向量限制为2维。那么词“猫”、“狗”、“开心”、“惊讶”、“手机”映射成词向量后在向量空间中可能是这样子的:

可以看到,“狗”和“猫”都是动物,语义相近,因此具有很小的夹角,而“狗”和“手机”这两个关系不大的词语便会有很大的夹角
合格的词向量除了在语义上相近会被编码到邻近的区域,还应该支持简单的语义运算,将语义运算映射为向量运算。比如:
- “中国”+“首都”=“北京”;
- “王子”-“公主”=“男”-“女“;

4、word bedding的理解
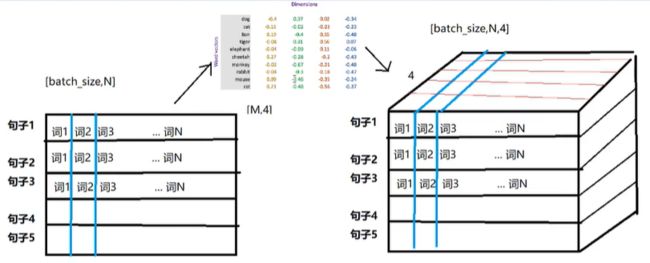
Embedding在数学上表示一个maping, f: X -> Y, 也就是一个function,其中该函数是injective(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)。那么对于word embedding,就是将单词word映射到另外一个空间,其中这个映射具有injective和structure-preserving的特点。
通俗的翻译可以认为是单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。
word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,该表达就是word representation。
word embedding API
torch.nn.Embedding(num_embeddings, embedding_dim):
- num_embeddings:词典的大小
- embedding_dim:embedding的维度
torch.nn.Embedding: 随机初始化词向量,词向量值在正态分布N(0,1)中随机取值
import torch.nn as nn
import torch
# nn.Embedding: This module is often used to store word embeddings and retrieve them using indices.
embedding = nn.Embedding(10, 3)
text = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
word_embedding = embedding(text)
print(word_embedding.shape)
print(word_embedding.size())
print(word_embedding)
'''
padding_idx (int, optional):
If given, pads the output with the embedding vector at :attr:`padding_idx`
(initialized to zeros) whenever it encounters the index.
'''
embedding = nn.Embedding(10, 3, padding_idx=2)
text = torch.LongTensor([[0, 2, 0, 5]])
word_embedding = embedding(text)
print(word_embedding.shape)
print(word_embedding.size())
print(word_embedding)
5、文本情感分类
流程:准备数据集、构建模型、模型训练、模型评估
准备数据集
需要注意:
- 如何完成Dataset和Dataloader的准备
- 每个batch中文本的长度不一致的问题如何解决
- 每个batch中的文本如何转化为数字序列
import torch
from torch.utils.data import DataLoader, Dataset
import os
import re
database_path = './aclImdb'
# 1、定义tokenize的方法
def tokenize(text):
filters = ['!', '"', '#', '$', '&', '\(', '\)', '\*', '\+', ',', '-',
'\.', '/', ':', ';', '<', '=', '>', '\?', '@', '\[', '\\', '\]', '^',
'_', '`', '\{', '\|', '\|', '~', '\t', '\n', '\x97', '\x96']
text = re.sub('<.*?', ' ', text, flags=re.S)
text = re.sub('|'.join(filters), ' ', text, flags=re.S)
return [i.strip() for i in text.split()]
# 2、准备dataset
class ImdbDataset(Dataset):
def __init__(self, mode):
super(ImdbDataset, self).__init__()
if mode == 'train':
text_path = [os.path.join(database_path, i) for i in ['train/neg', 'train/pos']]
else:
text_path = [os.path.join(database_path, i) for i in ['test/neg', 'test/pos']]
self.total_file_path = []
for i in text_path:
# extend(): Extend list by appending elements from the iterable.
self.total_file_path.extend([os.path.join(i, j) for j in os.listdir(i)])
def __getitem__(self, index):
current_path = self.total_file_path[index]
# basename(): Return the base name of pathname path. This is the second element of the pair returned by passing path to the function split().
current_filename = os.path.basename(current_path)
label = int(current_filename.split('_')[-1].split('.')[0])
text = tokenize(open(current_path).read().strip())
return label, text
def __len__(self):
return len(self.total_file_path)
def collate_fn(batch):
# batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果
batch = list(zip(*batch))
label = torch.tensor(batch[0], dtype=torch.int32)
text = batch[1]
return label, text
# 3、实例化,准备dataloader
dataset = ImdbDataset(mode='train')
dataloader = DataLoader(dataset=dataset, batch_size=2, shuffle=True,collate_fn=collate_fn)
for idx, data in enumerate(dataloader):
label, text = data
print(f"idx: {idx}")
print(f"label: {label}")
print(f"data:{text}")
补充:zip()函数
'''
zip(*iterables) --> A zip object yielding tuples until an input is exhausted.
|
| >>> list(zip('abcdefg', range(3), range(4)))
| [('a', 0, 0), ('b', 1, 1), ('c', 2, 2)]
|
| The zip object yields n-length tuples, where n is the number of iterables
| passed as positional arguments to zip(). The i-th element in every tuple
| comes from the i-th iterable argument to zip(). This continues until the
| shortest argument is exhausted.
'''
tuples=((1,2),(3,4))
print(*zip(*tuples))
6、文本序列化
深度学习构建模型前需要将文本转化为向量表示(Word Embedding)。首先需要将文本转化为数字(文本序列化),再把数字转化为向量。可以考虑把文本中的每个词语和其对应的数字,使用字典保存,同时把句子转化为数字的列表。

实现文本序列化之前,应考虑以下几点:
- 如何使用字典把词语和数字进行对应;
- 不同的词语出现的次数不尽相同,是否需要对高频或者低频词语进行过滤
- 得到词典之后,如何把句子转化为数字序列,如何把数字序列转化为句子
- 不同句子长度不相同,每个batch的句子如何构造成相同的长度
- 对于新出现的词语在词典中没有出现怎么办(特殊字符代理)
import numpy as np
class Word2Sequence():
UNK_TAG = 'UNK'
PAD_TAG = "PAD"
UNK = 0
PAD = 1
def __init__(self):
self.dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD
}
self.fited = False
self.count={}
# get index corresponding to the specific word
def word_to_index(self, word):
# word -> index
assert self.fited == True, '必须先进行fit操作'
return self.dict.get(word, self.UNK)
# get word corresponding to the specific index
def index_to_word(self, index):
# index -> word
assert self.fited == True, '必须先进行fit操作'
if index in self.inversed_dictionary:
return self.inversed_dictionary[index]
return self.UNK_TAG
def fit(self,sentence):
'''
把单个句子保存到dict中
:param sentence: [word1, word2, ...]
:return:
'''
for word in sentence:
self.count[word] = self.count.get(word,0)+1
# 过滤低频词语和高频词语,并且生成word—>index的字典
def build_vocabulary(self, min_count=1, max_count=None, max_feature=None):
'''
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
:return:
'''
# 过滤低频词语
if min_count is not None:
self.count = {k: v for k, v in self.count.items() if v >= min_count}
# 过滤高频词语
if max_count is not None:
self.count = {k: v for k, v in self.count.items() if v <= max_count}
# 限制最大的数量
if isinstance(max_feature, int):
# Return a new list containing all items from the iterable in ascending order
self.count = sorted(list(self.count.items()), key=lambda x: x[1])
if max_feature is not None and len(self.count) > max_feature:
self.count = self.count[-int(max_feature):]
for word in self.count:
self.dict[word] = len(self.dict)
else:
for word in self.count:
self.dict[word] = len(self.dict)
self.fited = True
# index -> word
self.inversed_dictionary = dict(zip(self.dict.values(), self.dict.keys()))
# limit the length of sentences and transform word in sentences to corresponding index
def transform(self, sentences, max_len=None):
"""
realize the function transforming the word in sentences to index, finally generate the list of index
:param sentences:
:param max_len:
:return:
"""
assert self.fited, "The 'fited' operation must be performed first"
if max_len is not None:
sentences_index = [self.PAD] * max_len
else:
sentences_index = [self.PAD] * len(sentences)
if max_len is not None and len(sentences) > max_len:
sentences = sentences[:max_len]
for index, word in enumerate(sentences):
sentences_index[index] = self.word_to_index(word)
return np.array(sentences_index, dtype=np.int64)
def inverse_transform(self, indices):
'''
realize the function transforming the index in indices to word, finally generate the list of words
:param indices: [1, 2, 3, ...]
:return: [word1, word2, ...]
'''
sentences = []
for index in indices:
word = self.index_to_word(index)
sentences.append(word)
return sentences
if __name__ == '__main__':
word_to_sequence = Word2Sequence()
# fit(): build the relations between the word and the index in order from lowest to highest
word_to_sequence.fit(['唐', '舞', '桐'])
word_to_sequence.build_vocabulary()
print(word_to_sequence.dict)
print(word_to_sequence.transform(['舞', '桐']))
7、文本序列化模型的保存
from word_sequence import Word2Sequence
import pickle
import os
from dataset import tokenize
from tqdm import tqdm
if __name__ == '__main__':
if not os.path.exists('./model'):
os.mkdir('./model')
ws = Word2Sequence()
path = r'./aclImdb/train'
temporary_data_path = [os.path.join(path, 'neg'), os.path.join(path, 'pos')]
for data_path in temporary_data_path:
# os.listdir(): Return a list containing the names of the files in the directory.
file_name = os.listdir(data_path)
file_path = [os.path.join(data_path, name) for name in file_name if name.endswith('.txt')]
for file in tqdm(file_path):
sentence = tokenize(open(file, errors='ignore').read())
ws.fit(sentence)
# filter high frequency words and low frequency words and generate the dictionary of words and index that corresponds one to one
ws.build_vocabulary(min_count=5)
print(len(ws))
pickle.dump(ws, open('./model/ws.pkl', 'wb'))
import pickle
# 使用保存的pkl文件
ws = pickle.load(open('./model/ws.pkl', 'rb'))
import torch
from torch.utils.data import DataLoader, Dataset
import os
import re
from pkl import ws
database_path = './aclImdb'
# 1、定义tokenize的方法
def tokenize(text):
filters = ['!', '"', '#', '$', '&', '\(', '\)', '\*', '\+', ',', '-',
'\.', '/', ':', ';', '<', '=', '>', '\?', '@', '\[', '\\', '\]', '^',
'_', '`', '\{', '\|', '\|', '~', '\t', '\n', '\x97', '\x96']
text = re.sub('<.*?', ' ', text, flags=re.S)
text = re.sub('|'.join(filters), ' ', text, flags=re.S)
return [i.strip() for i in text.split()]
# 2、准备dataset
class ImdbDataset(Dataset):
def __init__(self, mode):
super(ImdbDataset, self).__init__()
if mode == 'train':
text_path = [os.path.join(database_path, i) for i in ['train/neg', 'train/pos']]
else:
text_path = [os.path.join(database_path, i) for i in ['test/neg', 'test/pos']]
self.total_file_path = []
for i in text_path:
# extend(): Extend list by appending elements from the iterable.
self.total_file_path.extend([os.path.join(i, j) for j in os.listdir(i)])
def __getitem__(self, index):
current_path = self.total_file_path[index]
# basename(): Return the base name of pathname path. This is the second element of the pair returned by passing path to the function split().
current_filename = os.path.basename(current_path)
label = int(current_filename.split('_')[-1].split('.')[0])
text = tokenize(open(current_path).read().strip())
return label, text
def __len__(self):
return len(self.total_file_path)
def collate_fn(batch):
# batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果
batch = list(zip(*batch))
label = torch.tensor(batch[0], dtype=torch.int32)
text = batch[1]
# ws.transform: realize the function transforming the word in sentences to index, finally generate the list of index
text = [ws.transform(i, max_len=20) for i in text]
return label, text
# 3、实例化,准备dataloader
dataset = ImdbDataset(mode='train')
dataloader = DataLoader(dataset=dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)
for idx, data in enumerate(dataloader):
label, text = data
print(f"idx: {idx}")
print(f"label: {label}")
print(f"data:{text}")
break
8、基础模型的构建
import torch.nn as nn
import torch
# nn.Embedding: This module is often used to store word embeddings and retrieve them using indices.
embedding = nn.Embedding(10, 3)
text = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])
word_embedding = embedding(text)
print(word_embedding.shape)
print(word_embedding.size())
print(word_embedding)
'''
padding_idx (int, optional):
If given, pads the output with the embedding vector at :attr:`padding_idx`
(initialized to zeros) whenever it encounters the index.
'''
embedding = nn.Embedding(10, 3, padding_idx=2)
text = torch.LongTensor([[0, 2, 0, 5]])
word_embedding = embedding(text)
print(word_embedding.shape)
print(word_embedding.size())
print(word_embedding)

使用word embedding,模型只包含一层:
- 数据经过word embedding
- 数据通过全连接层返回结果,计算log_softmax
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from dataset import get_dataloader
from pkl import ws, MAX_LEN
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
class IMDBModel(nn.Module):
def __init__(self):
super(IMDBModel, self).__init__()
'''
padding_idx (int, optional):
If given, pads the output with the embedding vector at :attr:`padding_idx`
(initialized to zeros) whenever it encounters the index.
'''
self.embedding = nn.Embedding(len(ws), 100, padding_idx=ws.PAD)
self.linear = nn.Linear(MAX_LEN * 100, 11)
def forward(self, input):
x = self.embedding(input) # [batch_size,max_len,100]
x = x.view(x.size(0), -1) # [batch_size,max_len*100]
out = self.linear(x)
'''
F.log_softmax():
While mathematically equivalent to log(softmax(x)), doing these two
operations separately is slower, and numerically unstable. This function
uses an alternative formulation to compute the output and gradient correctly.
'''
return F.log_softmax(out,dim=-1)
TRAIN_BATCH_SIZE = 128
TEST_BATCH_SIZE = 1024
LR = 0.001
imdb = IMDBModel().to(device)
optimizer = optim.Adam(imdb.parameters(), lr=LR)
criterion = nn.CrossEntropyLoss().to(device)
def train(epoch):
print(f"{'-'*10}epoch: {epoch+1}{'-'*10}")
mode = True
imdb.train(mode)
train_dataloader = get_dataloader(mode='train', batch_size=TRAIN_BATCH_SIZE)
for idx, (label, text) in enumerate(train_dataloader):
label = label.to(device)
text = text.to(device)
optimizer.zero_grad()
output = imdb(text)
loss = criterion(output, label)
loss.backward()
optimizer.step()
if idx % 10 == 0:
print(f'train epoch:{epoch}, loss: {loss.item()}')
print("模型保存成功")
torch.save(imdb.state_dict(), f'./model/ws_{epoch}.pth')
for i in range(20):
train(i)
dataset.py文件:
import torch
from torch.utils.data import DataLoader, Dataset
import os
import re
from pkl import ws
database_path = './aclImdb'
# 1、定义tokenize的方法
def tokenize(text):
filters = ['!', '"', '#', '$', '&', '\(', '\)', '\*', '\+', ',', '-',
'\.', '/', ':', ';', '<', '=', '>', '\?', '@', '\[', '\\', '\]', '^',
'_', '`', '\{', '\|', '\|', '~', '\t', '\n', '\x97', '\x96']
text = re.sub('<.*?', ' ', text, flags=re.S)
text = re.sub('|'.join(filters), ' ', text, flags=re.S)
return [i.strip() for i in text.split()]
# 2、准备dataset
class ImdbDataset(Dataset):
def __init__(self, mode):
super(ImdbDataset, self).__init__()
if mode == 'train':
text_path = [os.path.join(database_path, i) for i in ['train/neg', 'train/pos']]
else:
text_path = [os.path.join(database_path, i) for i in ['test/neg', 'test/pos']]
self.total_file_path = []
for i in text_path:
# extend(): Extend list by appending elements from the iterable.
self.total_file_path.extend([os.path.join(i, j) for j in os.listdir(i)])
def __getitem__(self, index):
current_path = self.total_file_path[index]
# basename(): Return the base name of pathname path. This is the second element of the pair returned by passing path to the function split().
current_filename = os.path.basename(current_path)
label = int(current_filename.split('_')[-1].split('.')[0])
text = tokenize(open(current_path,errors='ignore').read().strip())
return label, text
def __len__(self):
return len(self.total_file_path)
def collate_fn(batch):
# batch是list,其中是一个一个元组,每个元组是dataset中__getitem__的结果
batch = list(zip(*batch))
label = torch.tensor(batch[0], dtype=torch.long)
text = batch[1]
# ws.transform: realize the function transforming the word in sentences to index, finally generate the list of index
text = [ws.transform(i, max_len=20) for i in text]
text=torch.tensor(text)
return label, text
# 3、实例化,准备dataloader
dataset = ImdbDataset(mode='train')
dataloader = DataLoader(dataset=dataset, batch_size=2, shuffle=True, collate_fn=collate_fn)
def get_dataloader(mode, batch_size):
mode_dataset = ImdbDataset(mode)
mode_dataloader = DataLoader(dataset=mode_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_fn)
return mode_dataloader
# loader = get_dataloader('train', 2)
#
# for label, text in loader:
# text = torch.tensor(text)
# print(f"text: {text}")
# print(f'dtype: {text.dtype}')
# print(f'type: {type(text)}')
# break
pkl.py文件:
import pickle
ws = pickle.load(open('./model/ws.pkl', 'rb'))
MAX_LEN = 20
保存./model/ws.pkl文件的py文件:
from word_sequence import Word2Sequence
import pickle
import os
from dataset import tokenize
from tqdm import tqdm
if __name__ == '__main__':
if not os.path.exists('./model'):
os.mkdir('./model')
ws = Word2Sequence()
path = r'./aclImdb/train'
temporary_data_path = [os.path.join(path, 'neg'), os.path.join(path, 'pos')]
for data_path in temporary_data_path:
# os.listdir(): Return a list containing the names of the files in the directory.
file_name = os.listdir(data_path)
file_path = [os.path.join(data_path, name) for name in file_name if name.endswith('.txt')]
for file in tqdm(file_path):
sentence = tokenize(open(file, errors='ignore').read())
ws.fit(sentence)
# filter high frequency words and low frequency words and generate the dictionary of words and index that corresponds one to one
ws.build_vocabulary(min_count=5)
print(len(ws))
pickle.dump(ws, open('./model/ws.pkl', 'wb'))
word_sequence.py文件:
import numpy as np
class Word2Sequence():
UNK_TAG = 'UNK'
PAD_TAG = "PAD"
UNK = 0
PAD = 1
def __init__(self):
self.dict = {
self.UNK_TAG: self.UNK,
self.PAD_TAG: self.PAD
}
self.fited = False
self.count={}
# get index corresponding to the specific word
def word_to_index(self, word):
# word -> index
assert self.fited == True, '必须先进行fit操作'
return self.dict.get(word, self.UNK)
# get word corresponding to the specific index
def index_to_word(self, index):
# index -> word
assert self.fited == True, '必须先进行fit操作'
if index in self.inversed_dictionary:
return self.inversed_dictionary[index]
return self.UNK_TAG
def fit(self,sentence):
'''
把单个句子保存到dict中
:param sentence: [word1, word2, ...]
:return:
'''
for word in sentence:
self.count[word] = self.count.get(word,0)+1
# 过滤低频词语和高频词语,并且生成word—>index的字典
def build_vocabulary(self, min_count=1, max_count=None, max_feature=None):
'''
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
:return:
'''
# 过滤低频词语
if min_count is not None:
self.count = {k: v for k, v in self.count.items() if v >= min_count}
# 过滤高频词语
if max_count is not None:
self.count = {k: v for k, v in self.count.items() if v <= max_count}
# 限制最大的数量
if isinstance(max_feature, int):
# Return a new list containing all items from the iterable in ascending order
self.count = sorted(list(self.count.items()), key=lambda x: x[1])
if max_feature is not None and len(self.count) > max_feature:
self.count = self.count[-int(max_feature):]
for word in self.count:
self.dict[word] = len(self.dict)
else:
for word in self.count:
self.dict[word] = len(self.dict)
self.fited = True
# index -> word
self.inversed_dictionary = dict(zip(self.dict.values(), self.dict.keys()))
# limit the length of sentences and transform word in sentences to corresponding index
def transform(self, sentences, max_len=None):
"""
realize the function transforming the word in sentences to index, finally generate the list of index
:param sentences:
:param max_len:
:return:
"""
assert self.fited, "The 'fited' operation must be performed first"
if max_len is not None:
sentences_index = [self.PAD] * max_len
else:
sentences_index = [self.PAD] * len(sentences)
if max_len is not None and len(sentences) > max_len:
sentences = sentences[:max_len]
for index, word in enumerate(sentences):
sentences_index[index] = self.word_to_index(word)
return np.array(sentences_index, dtype=np.int64)
def inverse_transform(self, indices):
'''
realize the function transforming the index in indices to word, finally generate the list of words
:param indices: [1, 2, 3, ...]
:return: [word1, word2, ...]
'''
sentences = []
for index in indices:
word = self.index_to_word(index)
sentences.append(word)
return sentences
def __len__(self):
return len(self.dict)
if __name__ == '__main__':
word_to_sequence = Word2Sequence()
# fit(): build the relations between the word and the index in order from lowest to highest
word_to_sequence.fit(['唐', '舞', '桐'])
word_to_sequence.build_vocabulary()
print(word_to_sequence.dict)
print(word_to_sequence.transform(['舞', '桐']))
word_sequence的准备:
- 定义字典保留所有的词语
- 根据词频对词语进行保留
- 一个batch中对句子的长度进行统一
- 实现方法把句子转化为序列和反向操作
9、循环神经网络的介绍
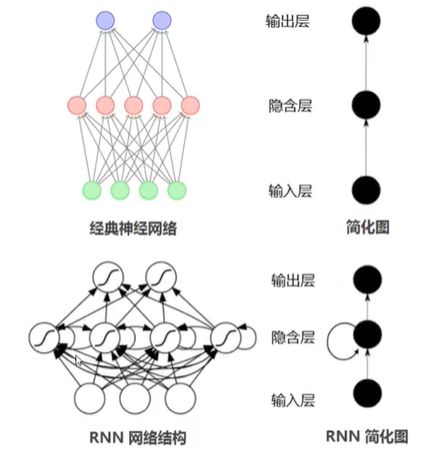
在普通的神经网络中,消息的传递是单向的,这种限制虽然使得神经网络变得容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和过去一段时间的输出相关。此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变
循环神经网络是一种具有短时记忆的神经网络(RNN),在RNN中,神经元不仅可以接收其它神经元的信息,也可以接收自身的信息,形成具有环路的网络结构,即神经元的输出可以在下一个时间步直接作用到自身(作为输入)

循环:当前时间步输入=当前时间步的输入+上一个时间步的输出
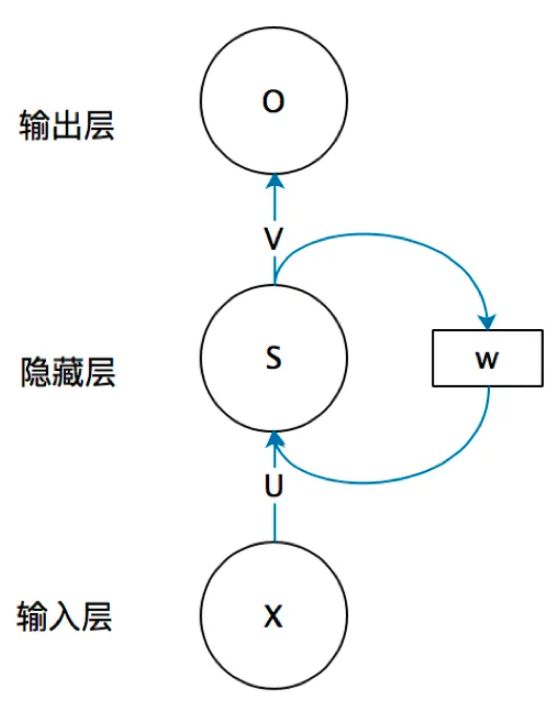
循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重


这个网络在t时刻接收到输入 xt 之后,隐藏层的值是 st ,输出值是 ot
st 的值不仅仅取决于 xt ,还取决于 st−1
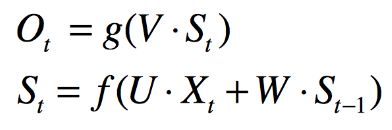
10、RNN
语言模型
我们可以和电脑玩一个游戏,我们写出一个句子前面的一些词,然后,让电脑帮我们写下接下来的一个词。比如下面这句:
我昨天上学迟到了,老师批评了____
我们给电脑展示了这句话前面这些词,然后,让电脑写下接下来的一个词。在这个例子中,接下来的这个词最有可能是『我』,而不太可能是『小明』,甚至是『吃饭』。
语言模型就是这样的东西:给定一句话前面的部分,预测接下来最有可能的一个词是什么。
循环神经网络
循环神经网络的计算方法: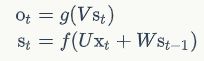
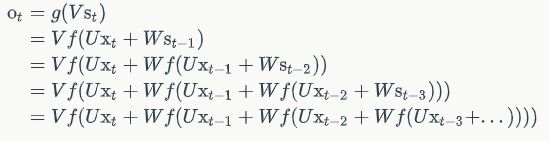
循环神经网络的输出值,是受前面历次输入值xt、xt-1、xt-2、xt-3、…影响的,这就是为什么循环神经网络可以往前看任意多个输入值的原因。

双向循环神经网络
对于语言模型来说,很多时候光看前面的词是不够的,比如下面这句话:
我的手机坏了,我打算____一部新手机。
可以想象,如果我们只看横线前面的词,手机坏了,那么我是打算修一修?换一部新的?还是大哭一场?这些都是无法确定的。但如果我们也看到了横线后面的词是『一部新手机』,那么,横线上的词填『买』的概率就大得多了。
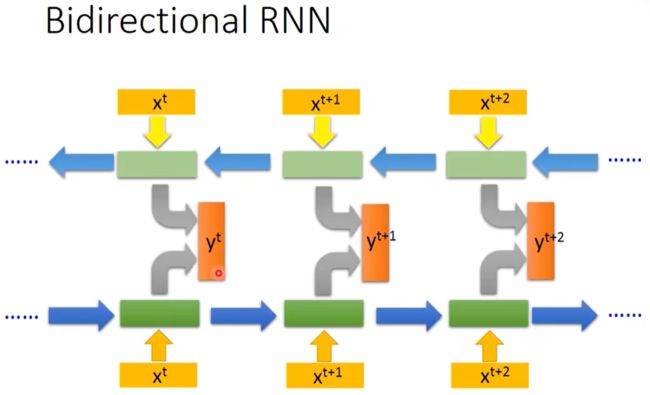
双向卷积神经网络的隐藏层要保存两个值,一个A参与正向计算,另一个值A’参与反向计算。最终的输出值yt取决于At和At'。以y2为例,其计算方法为:![]()
A2和A2'则分别计算: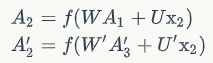
正向计算时,隐藏层的值与有关;反向计算时,隐藏层的值与有关;最终的输出取决于正向和反向计算的加和

从上面三个公式我们可以看到,正向计算和反向计算不共享权重,也就是说U和U’、W和W’、V和V’都是不同的权重矩阵。
循环神经网络的训练
循环神经网络的训练算法:BPTT
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
- 前向计算每个神经元的输出值;
- 反向计算每个神经元的误差项值
- 计算每个权重的梯度
任一时刻的梯度![]()
和![]()
是前面各个时刻的梯度之和,而参数V的梯度则依赖当前时刻的值
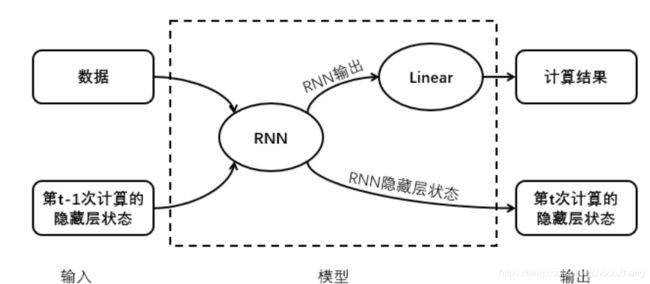
循环神经网络的实现(pytorch)
RNN模型的结构

展开上述循环:
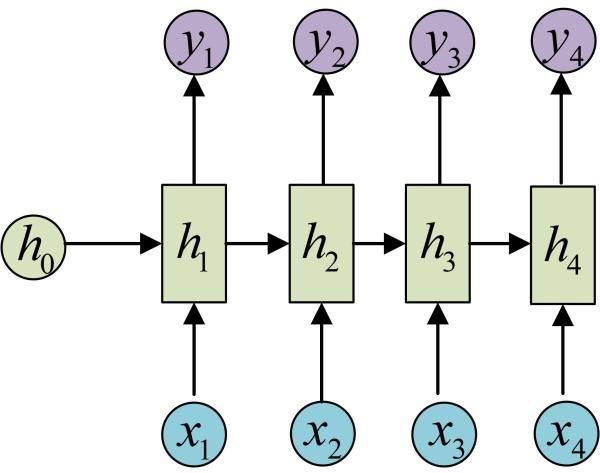
上图是一个二维的RNN模型的结构,RNN是循环神经网络,所指的xt和ht就是t时刻的输入,和t时刻对应的隐藏层,下图是三维的RNN模型图
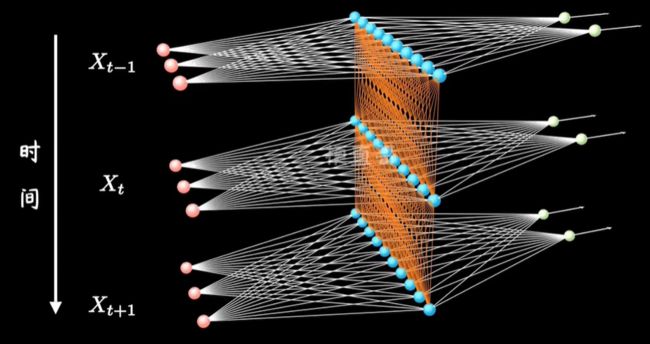
模型输入
RNN模型主要应用于时序型的数据,常见的应用类型为
- 自然语言:你吃饭了嘛,x1为你,x2为吃……以此类推
- 股票价格,每日天气情况等
隐藏层
![]()
- ht为t时刻时输入对应的隐藏单元的值
- U是输入层到隐藏层的权重矩阵
- W就是上一次隐藏层的值ht-1作为本次输入的权值矩阵。;
- b为偏置量
输出层
![]()
- V是隐藏层到输出层的权重矩阵。
- c为偏置量
特别注意:在计算时,每一步使用的参数U、W、V、b、c都是一样的,也就是说每个步骤的参数都是共享的
反向传播
反向传播是对U、W、V、b、c求偏导,调整他们使损失变小。
设t时刻,损失函数(Mean Square Error)为
,则损失函数之和为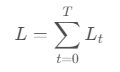
W在每一个时刻都出现了: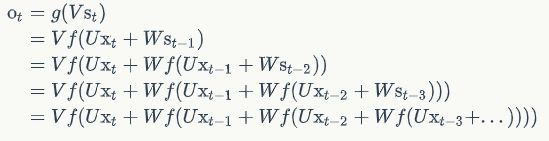
,W在t时刻的梯度: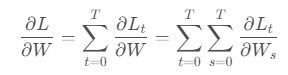
最后更新参数:
接下来举个例子,t=2时刻U、V、W对于损失函数L2的偏导: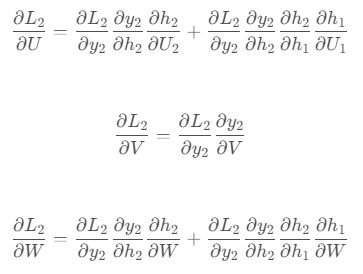
RNN的缺陷:长依赖问题
RNN的优势为可以利用过去的数据来推测当前数据,但是由于RNN的参数是共享的,每一时刻都会由前面所有的时刻共同决定,这是一个相加的过程,这样的话就有个问题,当距离过长了,计算前面的导数时,最前面的导数就会消失或者爆炸
所以当相关的数据离推测的数据越远时,RNN所能学习到的信息则越少。
例如:I live in Beijing. … .I can speak Chinese.
Beijing和Chinese是有着密切的关系的,但是由于中间存在着大量的句子,导致识别到Chinese无法和前面的Beijing产生联系。
RNN代码实现(pytorch)
import torch.nn as nn
import torch
rnn = nn.RNN(10, 20, 2)
# text: [seq_length, batch_size, input_size]
text = torch.randn(5, 3, 10) # seq_length=5, batch_size=3, input_size=10
# h0: [num_layers * num_directions, batch_size, hidden_size]
h0 = torch.randn(2, 3, 20) # num_layers*num_directions=2,batch_size=3,hidden_size=20
# output: [seq_length, batch_size, num_directions * hidden_size]
# hn: [num_layers * num_directions, batch_size, hidden_size]
output, hn = rnn(text, h0)
print(output.size())
print(hn.shape)
import torch.nn as nn
import torch
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
# how many time steps are in one batch of data
sequence_length = 20
# np.linspace(): Return evenly spaced numbers over a specified interval.
time_steps = np.linspace(0, np.pi, sequence_length + 1)
data = np.sin(time_steps)
# np.resize(): Return a new array with the specified shape.
data = np.resize(data, (sequence_length + 1, 1))
# size: Number of elements in the array.
# shape: Tuple of array dimensions
# reshape: Returns an array containing the same data with a new shape.
# resize: Change shape and size of array in-place.
x = data[:-1]
y = data[1:]
print(x.shape)
print(y.shape)
plt.plot(time_steps[1:], x, 'r.', label='input,x')
plt.plot(time_steps[1:], y, 'b.', label='target y')
plt.legend('best')
plt.show()
class SimpleRNN(nn.Module):
def __init__(self, input_size, output_size, hidden_size, layers):
super(SimpleRNN, self).__init__()
self.hidden_size = hidden_size
# defined an RNN with specified parameters
# batch_first means that the first dim of the input and output will be the batch_size
'''
RNN
Applies a multi-layer Elman RNN with tanh or ReLU to an input sequence
Args:
input_size: The number of expected features in the input `x`
hidden_size: The number of features in the hidden state `h`
num_layers: Number of recurrent layers.
'''
self.rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=True)
self.linear = nn.Linear(self.hidden_size, output_size)
def forward(self, x, h_0):
'''
:param x: [seq_length, batch_size, input_size]
:param h_0: [num_layers*num_directions, batch_size, hidden_size]
:return:
'''
batch_size = x.size(1)
# out:[seq_length, batch_size, num_directions * hidden_size]
# h_1: [num_layers * num_directions, batch_size, hidden_size]
out, h_1 = self.rnn(x, h_0)
out = out.view(-1, self.hidden_size)
output = self.linear(out)
return output, h_1
rnn = SimpleRNN(input_size=1, output_size=1, hidden_size=10, layers=1)
x = torch.Tensor(x)
x = x.reshape(20, 1, 1)
print('x: ', x.shape)
# h_1.shape: [num_layers * num_directions, batch_size, hidden_size]
out, h_1 = rnn(x, None)
print('rnn out: ',out.shape)
print(f'cnn h_1: {h_1.shape}')
使用RNN实现文本情感分类
# -*- coding: utf-8 -*-
# @Time : 2022/11/4 19:22
# @Author : 楚楚
# @File : 01RNN文本情感分类.py
# @Software: PyCharm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from dataset import get_dataloader
from pkl import ws, MAX_LEN
from datetime import datetime
from tqdm import tqdm
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class IMDBModel(nn.Module):
def __init__(self, input_size, output_size, hidden_size, layers):
super(IMDBModel, self).__init__()
'''
padding_idx (int, optional):
If given, pads the output with the embedding vector at :attr:`padding_idx`
(initialized to zeros) whenever it encounters the index.
'''
self.embedding = nn.Embedding(len(ws), input_size, padding_idx=ws.PAD)
self.hidden_size = hidden_size
# defined an RNN with specified parameters
# batch_first means that the first dim of the input and output will be the batch_size
'''
RNN
Applies a multi-layer Elman RNN with tanh or ReLU to an input sequence
Args:
input_size: The number of expected features in the input `x`
hidden_size: The number of features in the hidden state `h`
num_layers: Number of recurrent layers.
'''
self.rnn = nn.RNN(input_size=input_size,
hidden_size=hidden_size,
num_layers=layers)
self.linear = nn.Linear(self.hidden_size, output_size)
def forward(self, x, h_0):
'''
:param x: [batch_size, seq_length]
:param h_0: [num_layers*num_directions, batch_size, hidden_size]
:return:
'''
batch_size = x.size(0)
# x: [batch_size, seq_length, input_size]
x = self.embedding(x)
# x: [seq_length, batch_size, input_size]
x = x.permute(1, 0, 2)
# out: [seq_length, batch_size, num_directions*hidden_size]
# h_n: [num_layers*num_directions, batch_size, hidden_size]
out, h_n = self.rnn(x, h_0)
out = out[-1]
out = out.reshape(batch_size, -1)
output = self.linear(out)
return output, h_n
TRAIN_BATCH_SIZE = 128
TEST_BATCH_SIZE = 128
LR = 0.001
imdb = IMDBModel(input_size=100, output_size=11, hidden_size=20, layers=1).to(device)
optimizer = optim.Adam(imdb.parameters(), lr=LR)
criterion = nn.CrossEntropyLoss().to(device)
def train_test(epoch):
print(f"{'-' * 10}epoch: {epoch + 1}{'-' * 10}")
mode = True
imdb.train(mode)
train_dataloader, len_train_data = get_dataloader(mode='train', batch_size=TRAIN_BATCH_SIZE)
for idx, (text, label) in enumerate(train_dataloader):
text = text.to(device)
label = label.to(device)
optimizer.zero_grad()
output, h_n = imdb(text, None)
loss = criterion(output, label)
loss.backward()
optimizer.step()
if idx % 10 == 0:
print(f'train epoch:{epoch}, loss: {loss.item()}')
print(f"{'-' * 10}测试开始{'-' * 10}")
imdb.eval()
test_dataloader, len_test_data = get_dataloader('test', batch_size=TEST_BATCH_SIZE)
sum_loss = 0
total_accuracy = 0
with torch.no_grad():
for text, label in tqdm(test_dataloader):
text = text.to(device)
label = label.to(device)
output, h_n = imdb(text, None)
loss = criterion(output, label)
sum_loss += loss.item()
predicted = output.argmax(1)
accuracy = (predicted == label).sum()
total_accuracy += accuracy
print(f"测试集上的loss:{sum_loss}")
correct_accuracy = total_accuracy / len_test_data
print(f"整体测试集上的正确率:{correct_accuracy}%")
print("模型保存成功")
torch.save(imdb.state_dict(), f'./model/ws_{epoch}.pth')
now = datetime.now()
now = now.strftime("%Y-%m-%d %H:%M:%S")
content = f"time:{now}\t模型在测试集上的准确率:{correct_accuracy}"
with open('./accuracy.txt', 'a+', encoding='utf-8') as file:
file.write(content + '\n')
if __name__ == '__main__':
for i in range(20):
train_test(i)
数据集下载地址:https://ai.stanford.edu/~amaas/data/sentiment/
参考
1、什么是 word embedding?
2、二十一、文本情感分类二
3、python读取中编码错误(illegal multibyte sequence )
4、IndexError: Target 10 is out of bounds
5、一文搞懂RNN(循环神经网络)基础篇
6、Recurrent Neural Network系列3–理解RNN的BPTT算法和梯度消失
7、零基础入门深度学习(5) - 循环神经网络
8、RNN 的基本原理+pytorch代码
9、【Pytorch】21. RNN代码分析
10、【NLP自然语言处理】保姆级入门教程