文本生成:Transformer
1. 模型原理
Transformer是一种基于全连接神经网络的编码器-解码器(encoder-decoder)架构实现,它由输入模块、编码器模块、解码器模型和输出模型四部分组成。其结构如下图所示:
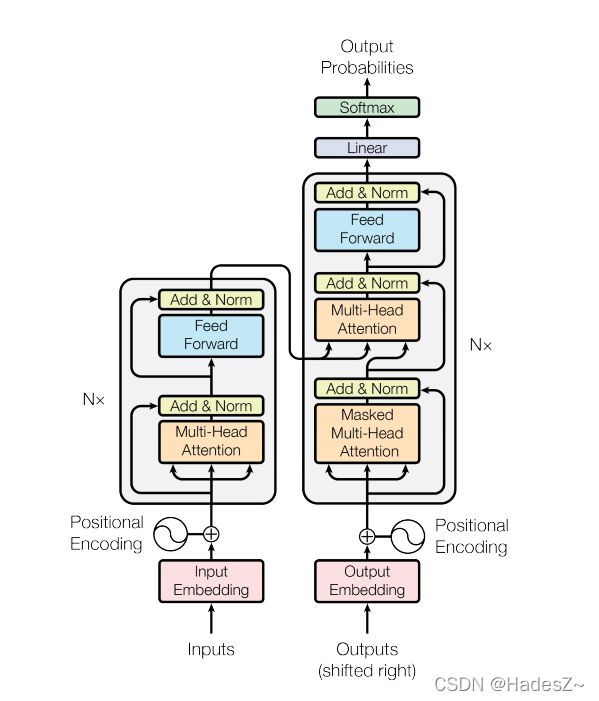
关于Transformer的基础知识介绍,网上已有许多公开的资料。读者可自行查阅学习。本文默认大家已具备Transformer相关的基础知识,文本将讨论其中值得注意的四个问题:
- Transformer中有几种mask机制,它们是如何去除小批量样本padding操作引入的噪声的?
- 自注意力机制为什么不直接使用输入的特征向量,而要使用其线性变换的结果来计算自注意力?
- 什么是layer normal,为使用它而不使用batch normal?
- 绝对位置编码和相对位置编码
1.1 Transformer中的mask机制
Transformer中有三种不同的mask机制:inputs padding mask、look ahead mask和outputs padding mask。
其中,inputs padding mask用于编码器和解码器中的Multi-Head Attention计算,通过与注意力得分矩阵元素对位相乘,使注意力全部集中于输入序列中有效位置的元素,从而消除输入序列padding值引入的噪声干扰。
look ahead mask用于解码器中Mask Multi-Head Attention计算,它在负责消除标签序列padding值引入的噪声干扰的同时,也是将文本生成循环能转为批量进行的保障:它在输入全量的标签序列时,利用mask矩阵实现仅预测时刻之前的部分序列被解码器端可见的效果;outputs padding mask用于动态损失函数计算,负责消除残差结构直连项,绕开Self-Attention层引入的标签序列padding值噪声干扰。所以look ahead mask与outputs padding mask共同作用,彻底消除了标签序列padding值引入的噪声干扰。
1.2 Self-Attention中输入特征向量线性变换的必要性
若不使用线性变换,则每个 token 对应的q,k,v向量都是一样的,那么此 token 对所有 token 所计算出的注意力分布中就只会集中于自己身上,对其他 token 的注意力会非常小。自注意力(Self-Attention)的作用就是筛选出其他 token 中有助于完成任务的特征信息,如果注意力分布不能关注到其他 token 的话,自注意力机制的作用也就丧失了。所以,自注意力机制需要使用输入特征向量的线性变换进行计算。
1.3 Layer Normalizationv.s. Batch Normalization
layer normalization 和 batch normalization 都是样本归一化方法,即:每一条样本都经过(x-mean) / std。
它们的区别在于归一化计算所使用的均值(mean)和方差(std)不同,如下图所示:
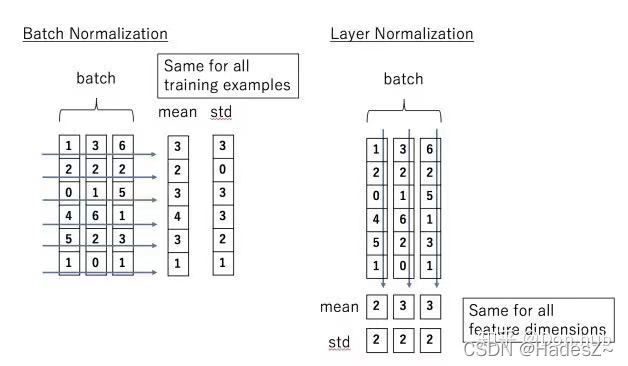
其中batch normalization更适合处理图像数据的归一化问题,而layer normalization更适合处理序列数据的归一化问题。
1.4 位置编码
位置编码有两种方法:functional encoding和parametric encoding。其中,functional encoding:这个是指的是通过特定函数的方式,将输入的位置idx变换为embedding。而,parametric encoding:指的是通过embedding lookup的方式,让模型自己学习位置的embedding。
这两种方式效果相似,functional encoding可减少模型需学习参数,parametric encoding可以减少人工设定的超参数,所以样本量较少时推荐使用functional encoding方法,而样本量充足时优先使用parametric encoding方法成本更低。(Transformer使用的是functional absolute positional encoding,BERT使用的是 parametric absolute positional encoding。)
2. 代码实现
2.1 基于TensorFlow框架的实现
from EncoderDecoder import *
from Attention import Self_Attention
gpus = tf.config.experimental.list_physical_devices(device_type="GPU")
tf.config.experimental.set_visible_devices(devices=gpus[0], device_type="GPU")
# Transformer Encoder
class tfEncoder(layers.Layer):
def __init__(self, hidden_num, head_num):
super(tfEncoder, self).__init__()
self.self_Attention = Self_Attention(hidden_num, head_num, mask_type='self_mask')
self.LayerNorm = layers.LayerNormalization()
self.Hidden = tf.keras.Sequential([
layers.Dense(hidden_num, activation='relu')
])
def call(self, inputs, input_len):
""":param
inputs: inputs is the embedding sequence of input sentences, and its' shape is [batch_size, time_steps, hidden_num]
input_len: input_len is the valid length of input sentences, and its' shape is [batch_size]
"""
self_attention = self.self_Attention(inputs, seq_len=input_len)
layer_norm_1 = self.LayerNorm(self_attention + inputs)
hidden = self.Hidden(layer_norm_1)
layer_norm_2 = self.LayerNorm(hidden + layer_norm_1)
return layer_norm_2
# Transformer Decoder
class tfDecoder(layers.Layer):
def __init__(self, hidden_num, head_num):
super(tfDecoder, self).__init__()
self.Future_Attention = Self_Attention(hidden_num, head_num, mask_type='future_self_mask')
self.LayerNorm = layers.LayerNormalization()
self.Attention = Self_Attention(hidden_num, head_num, mask_type='mask')
self.Hidden = tf.keras.Sequential([
layers.Dense(hidden_num, activation='relu')
])
def call(self, inputs, input_len, enc_hiddens, enc_input_len, training):
"""
**Train**
:inputs: inputs is label sequences, and its' shape is [batch_size*time_steps_label, time_steps_label, hidden_num]
:input_len: input_len is the valid length of label sequences, and its' shape is [batch_size](单向掩码函数中:会自动将其复制 time_steps 份)
:enc_hiddens: [batch_size*time_steps_label, time_steps_input_sentences, hidden_num]
:enc_input_len: enc_input_len is the valid length of input sentences, and its' shape is [batch_size]
:outputs: outputs is predicted label sequences, and its' shape is [batch_size*time_steps_label, time_steps_label, hidden_num]
****
**Predict**
:inputs: inputs is label sequences, and its' shape is [batch_size, time_steps_label, hidden_num]
:enc_hiddens: [batch_size, time_steps_input_sentences, hidden_num]
:outputs: outputs is predicted label sequences, and its' shape is [batch_size, time_steps_label, hidden_num]
"""
if input_len is None and training is not False:
raise ValueError("请检测标签序列长度参数:input_len")
#
future_self_attention = self.Future_Attention(inputs, seq_len=input_len)
layer_norm_1 = self.LayerNorm(future_self_attention + inputs)
# 此处attention中的mask矩阵,也相当于另一种意义上的关于Encoder输出结果的多头注意力机制的mask矩阵,两者任务内容相同
attention = self.Attention(
layer_norm_1, keys=enc_hiddens, values=enc_hiddens, seq_len=enc_input_len
, training=training
)
layer_norm_2 = self.LayerNorm(attention + layer_norm_1)
hidden = self.Hidden(layer_norm_2)
layer_norm_3 = self.LayerNorm(hidden + layer_norm_2)
return layer_norm_3
# Transform Model
class Transformer(EncoderDecoder):
def __init__(self, hidden_num, head_num, encd_layers, decd_layers,
vocab_size, word2index, index2word, **kwargs):
super().__init__(**kwargs)
self.vocab_size = vocab_size
self.word2index = word2index
self.index2word = index2word
#
self.Embed = layers.Embedding(vocab_size, hidden_num)
self.PosEncod = self.Position_Encoder
self.Encoders = [tfEncoder(hidden_num, head_num) for _ in range(encd_layers)]
self.Decoders = [tfDecoder(hidden_num, head_num) for _ in range(decd_layers)]
self.Output = tf.keras.Sequential([
layers.Dense(vocab_size, activation='softmax')
])
def call(self, X, y, X_len, y_len, training):
"""
:param X: it is the input sentences, and its' shape is [batch_size, time_steps_X]
:param y: it is the label sequence, and its' shape is [batch_size, time_steps_y]
:param X_len: it is the valid length of input sentences, and its' shape is [batch_size, time_steps_X]
:param y_len: it is the valid length of label sequence, and its' shape is [batch_size, time_steps_X]
:param training: its' value is True or False
:return:
"""
# Input
inputs = self.Input(X)
# Encoder
encoder = inputs
for Encoder in self.Encoders:
encoder = Encoder(encoder, input_len=X_len)
# Decoder
if training is True:
""" 强制教学,批量进行 Decoder
The shape of encoder_outputs and decoder_inputs is converted to [batch_size*time_steps, time_steps, hidden_num] from [batch_size, time_steps, hidden_num].
"""
bos = tf.constant([self.word2index['' ]] * y.shape[0], shape=[y.shape[0], 1], dtype=y.dtype)
y = tf.concat([bos, y[:, :-1]], axis=1) # 去除标签
decoder = self.Input(y)
#
encoder = tf.reshape(
tf.tile(tf.expand_dims(encoder, axis=1), [1, decoder.shape[1], 1, 1])
, [encoder.shape[0]*decoder.shape[1], encoder.shape[1], encoder.shape[2]]
)
decoder = tf.reshape(
tf.tile(tf.expand_dims(decoder, axis=1), [1, decoder.shape[1], 1, 1])
, [decoder.shape[0]*decoder.shape[1], decoder.shape[1], decoder.shape[2]]
)
for Decoder in self.Decoders:
decoder = Decoder(decoder, input_len=y_len, enc_hiddens=encoder, enc_input_len=X_len, training=training)
else:
decoder = self.Input(y)
for Decoder in self.Decoders:
decoder = Decoder(decoder, input_len=None, enc_hiddens=encoder, enc_input_len=X_len, training=training)
# Output
outputs = self.Output(decoder)
if training is True:
""" 提取并行计算产生的循环预测标签 """
Diagonal_mask = tf.ones([outputs.shape[1], outputs.shape[1]], dtype=outputs.dtype)
Diagonal_mask = tf.expand_dims(tf.linalg.band_part(Diagonal_mask, 0, 0), axis=-1)
Diagonal_mask = tf.tile(Diagonal_mask, [y.shape[0], 1, 1])
outputs = tf.reduce_sum(
tf.reshape(outputs * Diagonal_mask, [y.shape[0], y.shape[1], y.shape[1], self.vocab_size])
, axis=1)
y_hat = tf.argmax(outputs, axis=-1, output_type=X.dtype)
return y_hat, outputs
# 输入层前向传播过程
def Input(self, X):
embed = self.Embed(X)
pos_encod = self.PosEncod(embed) # 这其实是位置编码与词向量编码共享同一个词向量层
return embed + pos_encod
#
def Position_Encoder(self, inputs, max_len=512):
"""
据文献阐述,Transformer结构的模型最大可处理的文本长度是512个token,更长文本需要用XLNet模型才可很好处理;
所以此处设置max_len=512够用了,再长就超出模型处理能力了。
"""
batch_size, steps, hiddens = list(inputs.shape)
if steps > max_len: raise ValueError('输入序列超出最大编码长度')
#
pos_encoding = np.zeros((1, max_len, hiddens), dtype=np.float32) # The dtype of np.zeros Default is 'numpy.float64', which would raise error because it is expected to be a float32.
pos = np.arange(max_len, dtype=np.float32).reshape(-1, 1) / np.power(
10000, np.arange(0, hiddens, 2, dtype=np.float32) / hiddens)
#
pos_encoding[:, :, 0::2] = np.sin(pos) # 奇数位置
pos_encoding[:, :, 1::2] = np.cos(pos) # 偶数位置
return tf.tile(tf.constant(pos_encoding[:, :steps, :]), [batch_size, 1, 1])
2.2 基于Pytorch框架的实现
from .Attention import *
from .EncoderDecoder import *
# Transform Encoder
class Encoder(nn.Module):
def __init__(self, hidden_dim, head_num, hidden_act=nn.ReLU(), device='cpu'):
super(Encoder, self).__init__()
self.device = device
self.self_Attention = Self_Attention(hidden_dim, head_num).to(self.device)
self.LayerNorm = nn.LayerNorm(hidden_dim).to(self.device)
self.Hidden = nn.Linear(hidden_dim, hidden_dim, device=self.device)
self.HiddenAct = hidden_act.to(self.device)
def forward(self, inputs, input_mask):
""":param
inputs: inputs is the embedding sequence of input sentences, and its' shape is [batch_size, time_steps, hidden_dim]
input_len: input_len is the valid length of input sentences, and its' shape is [batch_size]
"""
self_attention = self.self_Attention(inputs, self_mask=input_mask)
layer_norm_1 = self.LayerNorm(self_attention + inputs)
hidden = self.HiddenAct(
self.Hidden(layer_norm_1)
)
layer_norm_2 = self.LayerNorm(hidden + layer_norm_1)
return layer_norm_2
# Transform Decoder
class Decoder(nn.Module):
def __init__(self, hidden_dim, head_num, hidden_act=nn.ReLU(), device='cpu'):
super(Decoder, self).__init__()
#
self.device = device
#
self.Future_Attention = Self_Attention(hidden_dim, head_num).to(self.device)
self.LayerNorm = nn.LayerNorm(hidden_dim).to(self.device)
self.Attention = Self_Attention(hidden_dim, head_num).to(self.device)
self.Hidden = nn.Linear(hidden_dim, hidden_dim, device=self.device)
self.HiddenAct = hidden_act.to(self.device)
def forward(self, inputs, enc_hiddens, future_mask, enc_input_mask):
"""
**Train**
:inputs: inputs is label sequences, and its' shape is [batch_size * y_time_steps, y_time_steps, hidden_dim]
:input_len: input_len is the valid length of label sequences, and its' shape is [batch_size](单向掩码函数中:会自动将其复制 time_steps 份)
:enc_hiddens: [batch_size*y_time_steps, X_time_steps, hidden_dim]
:enc_input_len: enc_input_len is the valid length of input sentences, and its' shape is [batch_size]
:outputs: outputs is predicted label sequences, and its' shape is [batch_size * y_time_steps, y_time_steps, hidden_dim]
****
**Predict**
:inputs: inputs is label sequences, and its' shape is [batch_size, y_time_steps, hidden_dim]
:enc_hiddens: [batch_size, X_time_steps, hidden_dim]
:outputs: outputs is predicted label sequences, and its' shape is [batch_size, y_time_steps, hidden_dim]
"""
batch_size, y_time_steps, _ = inputs.shape
#
future_attention = self.Future_Attention(inputs, self_mask=future_mask)
layer_norm_1 = self.LayerNorm(future_attention + inputs)
# 此处attention中的mask矩阵,也相当于另一种意义上的关于Encoder输出结果的多头注意力机制的mask矩阵,两者任务内容相同
attention = self.Attention(
layer_norm_1, keys=enc_hiddens, values=enc_hiddens, attention_mask=enc_input_mask
)
layer_norm_2 = self.LayerNorm(attention + layer_norm_1)
#
hidden = self.Hidden(layer_norm_2)
layer_norm_3 = self.LayerNorm(hidden + layer_norm_2)
return layer_norm_3
# Transform Model
class Transform(EncoderDecoder):
def __init__(self, hidden_dim, head_num, encd_layers, decd_layers,
vocab_size, word2index, index2word, device='cpu'):
super().__init__()
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.word2index = word2index
self.index2word = index2word
self.device = device
#
self.Embed = nn.Embedding(vocab_size, self.hidden_dim).to(self.device)
self.PosEncod = self.Position_Encoder
self.Encoders = nn.Sequential(
Encoder(self.hidden_dim, head_num, device=self.device)
)
if encd_layers > 1:
for i in range(encd_layers - 1):
self.Encoders.add_module(
str(i + 1), Encoder(self.hidden_dim, head_num, device=self.device)
)
self.Decoders = nn.Sequential(
Decoder(self.hidden_dim, head_num, device=self.device)
)
if decd_layers > 1:
for i in range(decd_layers - 1):
self.Decoders.add_module(
str(i + 1), Decoder(self.hidden_dim, head_num, device=self.device)
)
self.Output = nn.Linear(hidden_dim, vocab_size, device=self.device)
# forward
def forward(self, X, y=None, input_mask=None, future_mask=None, target_time_steps: int = None):
"""
X: it is the input sentences, and its' shape is [batch_size, time_steps_X].
y: it is the label sequence, and its' shape is [batch_size, time_steps_y].
input_mask: it is padding mask matrix of input sentences(X), and its' shape is [batch_size, time_steps_X].
future_mask: 单向掩码矩阵,用于Decoder强制教学, 其形状是 [batch_size * (time_steps_y+1), time_steps_y + 1, time_steps_y + 1].
:return: shape is []
"""
# Input
_, X_time_steps = X.shape
encoder = self.Input(X)
del X; gc.collect()
# Encoder
for Encoder in self.Encoders:
encoder = Encoder(
encoder, input_mask=input_mask
)
del Encoder; gc.collect()
# Train or Predict
if future_mask is not None:
""" 强制教学Train,批量进行 Decoder
The shape of encoder_outputs and decoder_inputs is converted to [batch_size * time_steps_y, time_steps_y, hidden_dim]
from [batch_size, time_steps_y + 1, hidden_dim].
"""
#
batch_size, y_time_steps = future_mask.shape
y = torch.reshape(
torch.tile(
torch.unsqueeze(y, 1), [1, y_time_steps, 1]
)
, [batch_size * y_time_steps, y_time_steps]
)
encoder = torch.reshape(
torch.tile(
torch.unsqueeze(encoder, 1), [1, y_time_steps, 1, 1]
)
, [batch_size * y_time_steps, X_time_steps, self.hidden_dim]
)
input_mask = torch.reshape(
torch.tile(
torch.unsqueeze(input_mask, 1), [1, y_time_steps, 1]
)
, [batch_size * y_time_steps, X_time_steps]
)
# Decoder
decoder = self.Input(y)
for Decoder in self.Decoders:
decoder = Decoder(
decoder, enc_hiddens=encoder, future_mask=future_mask, enc_input_mask=input_mask
)
del Decoder; gc.collect()
# Output
outputs = F.softmax(
self.Output(decoder)
)
outputs = torch.reshape(
outputs, [self.batch_size, self.y_time_steps, self.y_time_steps, -1]
)
else:
""" Predict
y: its' shape is [batch_size, 1],
"""
outputs = []
for i in range(target_time_steps):
# Decoder
decoder = self.Input(y)
for Decoder in self.Decoders:
decoder = Decoder(
decoder, enc_hiddens=encoder, future_mask=None, enc_input_mask=input_mask
)
# Output
output = F.softmax(
self.Output(decoder[:, -1])
)
y_score, y_hat = torch.max(output[:, -1], dim=-1, keepdim=True)
y = torch.concat([y, y_hat], dim=1)
outputs.append(output[:, -1:])
outputs = torch.concat(outputs, dim=1)
return outputs
#
def Input(self, X):
embed = self.Embed(X)
pos_encod = self.PosEncod(embed) # 这其实是位置编码与词向量编码共享同一个词向量层
return embed + pos_encod
#
def Position_Encoder(self, inputs, max_len=512):
"""
据文献阐述,Transform结构的模型最大可处理的文本长度是512个token,更长文本需要用XLNet模型才可很好处理;
所以此处设置max_len=512够用了,再长就超出模型处理能力了。
"""
batch_size, steps, hiddens = inputs.shape
if steps > max_len: raise ValueError('输入序列超出最大编码长度')
#
pos_encoding = np.zeros((1, max_len, hiddens), dtype=np.float32) # The dtype of np.zeros Default is 'numpy.float64', which would raise error because it is expected to be a float32.
pos = np.arange(max_len, dtype=np.float32).reshape(-1, 1) / np.power(
10000, np.arange(0, hiddens, 2, dtype=np.float32) / hiddens)
#
pos_encoding[:, :, 0::2] = np.sin(pos) # 奇数位置
pos_encoding[:, :, 1::2] = np.cos(pos) # 偶数位置
pos_encoding = torch.from_numpy(pos_encoding[:, :steps, :]).to(self.device)
return torch.tile(pos_encoding, [batch_size, 1, 1])