「硬刚Doris系列」Apache Doris的向量化和Roaring BitMap
点击上方蓝色字体,选择“设为星标”
回复"面试"获取更多惊喜
![]()
轻戳有惊喜:全网最全大数据面试提升手册!
一.向量化
假如有个sql :
select c1 , c2 from t where c1 < 100 and c4 = 10用户通过 SQL 语句向数据库发起计算请求,SQL 中的计算主要包括两类:expression 级别的计算和 operator 级别的计算。该 SQL 包含了 3 个 operator:tablescan,Filter 和 projection,而每个 operator 内部又包含了各自的 expression,例如 Filter 内部的 expression 为c1 < 100 and c4 = 10,projection 内部的 expression 则为c1 和c2。
1. 经典的 SQL 计算引擎
解析原理
在 expression 层面一般采用 expression tree 的模型来解释执行,而在 operator 层面则大多采用火山模型。
上述 SQL 中的 filter 条件对应的 expression tree 就如下图所示:

与 Expression tree 类似,在火山模型中,operator 也被组织为 operator tree 的形式,operator 之间则通过迭代器来串联。Operator 一般有如下定义:
class Operator {
Row next();
void open();
void close();
Operator children[];
}在具体的 operator 中一般包含其需要计算的 expression,例如
class Projection extends Operator {
Expression projectionExprs[];
Row next() {
Row output = new Row(projectionExprs.length);
Row input = children[0].next();
for (int i = 0; i < projectionExprs.length; i++) {
output.set(i, projectionExprs[i].eval(input));
}
return output;
}
}这样上述 SQL 在数据库中实际上会被编译为如下的 operator tree:
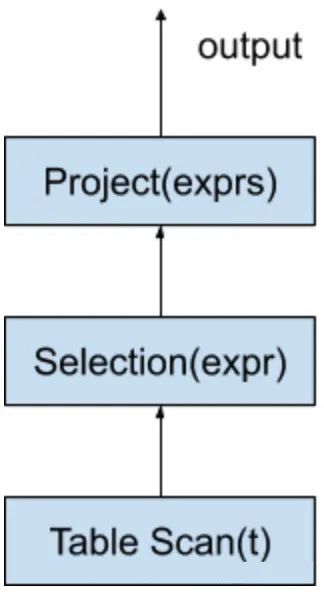
优缺点
优点
火山模型的最大好处是实现简单,每个 operator 都只需要完成其自身特定的功能,operator 之间是完全解耦合的,SQL complier 只需要根据 SQL 的逻辑构造对应的 operator 然后将 operator 串联起来即可。
缺点
Expression层面:基于 expression tree 的解释执行往往使得一些看上去很简单的表达式执行起来很复杂,以上述 SQL 的 filter 条件为例:c1 < 100 and c4 = 10 这个过滤条件在数据库中会被转换为包含 7 个节点的 expression tree,对于表中的每行数据,这 7 个节点的 eval 函数都会被触发一次。
Operator 层面面临的问题与 Expression 类似,火山模型虽然带来了实现简单、干净的好处,但是每次计算一行结果都会有一个很长的 next 虚函数调用链(而且 operator next 函数中一般还会有一个 expression eval 的虚函数调用链)。虽然虚函数调用本身开销并不算特别大,但是仍需要花费一定的时间,而虚函数内部的操作可能就是一个简单的轻量级计算,而且每一行数据都需要若干次的虚函数调用,当数据量非常大的时候,这个开销就会变得十分可观。
除了虚函数带来的计算框架开销外,经典计算引擎还有一些其他缺点,试想上述 SQL 在火山模型中生成相应的 plan 后,其运行时的代码如下:
for(; Row row = plan.next(); row != null) {
// send to client
}其中 plan 即 operator tree 的 root 节点,对上述 SQL 来说就是 projection。
而如果手动写一段代码来实现上述 SQL 的话,其代码大概如下:
for(Row row in scanBuffer) {
int c1 = row.getInt(0);
int c3 = row.getInt(2);
if (c1 < 100 && c3 == 10) {
// construct new row and send to the client
}
}上述两段代码虽然都是一个 for 循环,但是对于第一段代码来说,for 循环里面是很深的虚函数调用,而第二段代码 for 循环里做的事则要简单的多。对 compiler 来说,越简单的代码越容易优化,在这个例子中,compiler 就可以通过将c1和c3放在寄存器中来实现提速。
2. 向量化执行
优化思想
从上面的介绍来看,经典 SQL 的计算引擎一个很大问题就是无论是 expression 还是 operator ,其计算的时候都大量使用到虚函数,由于每行数据都需要经过这一系列的运算,导致计算框架开销比较大,而且由于虚函数的大量使用,也影响了编译器的优化空间。在减小框架开销方面,两个常用的方法就是
均摊开销
消除开销
向量化执行与代码生成正是数据库从业者们在这两个方向上进行的努力。
向量化执行
向量化执行的思想就是均摊开销:假设每次通过 operator tree 生成一行结果的开销是 C 的话,经典模型的计算框架总开销就是 C * N,其中 N 为参与计算的总行数;如果把计算引擎每次生成一行数据的模型改为每次生成一批数据的话,因为每次调用的开销是相对恒定的,所以计算框架的总开销就可以减小到C * N / M,其中 M 是每批数据的行数,这样每一行的开销就减小为原来的 1 / M,当 M 比较大时,计算框架的开销就不会成为系统瓶颈了。除此之外,向量化执行还能给 compiler 带来更多的优化空间,因为引入向量化之后,实际上是将原来数据库运行时的一个大 for 循环拆成了两层 for 循环,内层的 for 循环通常会比较简单,对编译器来说也存在更大的优化可能性。
举例来说,对于一个实现两个 int 相加的 expression,在向量化之前,其实现可能是这样的:
class ExpressionIntAdd extends Expression {
Datum eval(Row input) {
int left = input.getInt(leftIndex);
int right = input.getInt(rightIndex);
return new Datum(left+right);
}
}在向量化之后,其实现可能会变为这样:
class VectorExpressionIntAdd extends VectorExpression {
int[] eval(int[] left, int[] right) {
int[] ret = new int[input.length];
for(int i = 0; i < input.length; i++) {
ret[i] = new Datum(left[i] + right[i]);
}
return ret;
}
}显然对比向量化之前的版本,向量化之后的版本不再是每次只处理一条数据,而是每次能处理一批数据
二.Roaring Bitmap
普通BitMap
Bitmap 会有两个问题,一个是内存和存储占用,一个是 Bitmap 输入只支持 Int 类型。解决内存和存储占用的思路就是压缩,业界普遍采用的 Bitmap 库是 Roaring Bitmap;
Roaring Bitmap
Roaring Bitmap 的核心思路很简单,就是根据数据的不同特征采用不同的存储或压缩方式。为了实现这一点,Roaring Bitmap 首先进行了分桶,将整个 int 域拆成了 2 的 16 次方 65536 个桶,每个桶最多包含 65536 个元素。所以一个 int 的高 16 位决定了,它位于哪个桶,桶里只存储低 16 位。以图中的例子来说,62 的前 1000 个倍数,高 16 位都是 0,所以都在第一个桶里。

Array Container: 默认会采用 16 位的 Short 数组来存储低 16 位数据;
BitMap Container: 当元素个数超过 4096 时,会采用 Bitmap 来存储数据。为什么是 4096 呢?我们知道, 如果用 Bitmap 来存,65526 个 bit, 除以 8 是 8192 个字节,而 4096 个 Short 就是 4096 * 2 = 8192 个字节。所以当元素个数少于 4096 时,Array 存储效率高,当大于 4096 时,Bitmap 存储效率高。
Run Container: 是优化连续的数据, Run 指的是 Run Length Encoding(RLE),比如我们有 10 到 1000 折连续的 991 个数字,那么其实不需要连续存储 10 到 1000,这 991 个整形,我们只需要存储 1 和 990 这两个整形就够了。
如果这个文章对你有帮助,不要忘记 「在看」 「点赞」 「收藏」 三连啊喂!


2022年全网首发|大数据专家级技能模型与学习指南(胜天半子篇)
互联网最坏的时代可能真的来了
我在B站读大学,大数据专业
我们在学习Flink的时候,到底在学习什么?
193篇文章暴揍Flink,这个合集你需要关注一下
Flink生产环境TOP难题与优化,阿里巴巴藏经阁YYDS
Flink CDC我吃定了耶稣也留不住他!| Flink CDC线上问题小盘点
我们在学习Spark的时候,到底在学习什么?
在所有Spark模块中,我愿称SparkSQL为最强!
硬刚Hive | 4万字基础调优面试小总结
数据治理方法论和实践小百科全书
标签体系下的用户画像建设小指南
4万字长文 | ClickHouse基础&实践&调优全视角解
【面试&个人成长】2021年过半,社招和校招的经验之谈
大数据方向另一个十年开启 |《硬刚系列》第一版完结
我写过的关于成长/面试/职场进阶的文章
当我们在学习Hive的时候在学习什么?「硬刚Hive续集」