低精度神经网络:从数值计算角度优化模型效率

作者丨林野
学校丨东北大学自然语言处理实验室2019级博士生
研究方向丨机器翻译、模型压缩、模型加速
背景
近年来,随着人工智能的不断兴起,神经网络已经在语音识别、计算机视觉和自然语言处理领域等多个任务上取得了重大突破,以机器翻译任务为例,基于神经网络的神经机器翻译模型在翻译质量和翻译流畅性等方面都明显优于传统的统计机器翻译。
当前神经网络取得的进展除了模型结构本身的因素外,还主要依赖于三种外部因素:1)海量数据集;2)高性能 GPU 设备;3)大规模分布式训练。
深度学习(Deep Learning, DL)的概念源于人工神经网络的研究,是机器学习的第二次浪潮,也是机器学习领域中最集中和最广泛使用的预测模型之一。许多深度学习问题追求的目标都可以分为两个阶段,第一阶段是性能,第二阶段是效率。
在第一阶段中,效率和响应速度并不那么重要,人们更关心的是提出的研究方法和模型是不是真的 work,对模型性能有多少提升,这种发展趋势也使得当前许多深度神经网络无比繁重。
很快,人们意识到了一个问题:模型效率真的很重要!尽管 DL 带来了诸多好处,但模型的训练和存储却变得越来越困难,很难将神经网络相关的计算工作负载部署在计算资源受限的嵌入式边缘设备上。例如:AlphaGo 的惊人性能需要在 2000 个 CPU 和 250 个 GPU 上进行为期 4 到 6 周的训练,总功耗约为 600kW。
在诸如 AlphaGo 这些深度神经网络中,参数并非都对网络起到正向的效果,而是存在冗余,这种冗余的神经网络不仅会对存储和计算资源造成浪费,还可能导致严重的过参数化和过拟合问题。
当前已经有一些关于模型结构优化的研究工作,可以在提升模型性能的前提下显著降低模型的计算代价,但仍需消耗更多更昂贵的计算资源和内存资源。因此,如何在保证模型性能的前提下提升神经网络模型的计算效率,是我们当前亟待解决的一个问题。
低精度神经网络
为了解决神经网络训练代价过高的问题,将神经网络的发展从计算资源和内存资源等硬件限制中解脱出来,当前研究人员已经研究出一些神经网络模型加速和压缩方法,这些方法主要有网络剪枝、知识蒸馏、张量分解、迁移学习、参数量化、低精度神经网络等等,相较于其他方法,低精度神经网络更倾向于从神经网络的底层数值计算角度来进行神经网络模型的优化。
什么是低精度神经网络?
看到这里大家可能会有一个疑问,到底什么是低精度神经网络?
大家都知道,实数是是不可数的,以枚举的方式不能表示整体的实数。在计算机中只能使用有限数量的 bit 位来表示无穷个实数,因此计算机中对实数的表示本身就是一个近似替代问题,替代的准确度取决于我们用多少 bit 位来对数值进行表示。在神经网络中,最常用的数值表示为 32 位浮点数,在某些科学计算领域会使用 64 位浮点进行严格计算,用更低精度数值表示的神经网络我们称之为低精度神经网络。
神经网络低精度化方法最早可以追溯到 20 世纪 90 年代,但由于当时条件和资源限制,并不能很好的验证神经网络低精度化方法在深层神经网络及大规模数据上的有效性。当前随着计算资源和数据资源的极大丰富,对低精度神经网络的研究逐渐提上日程。
常用数值表示
低精度神经网络将神经网络中权重和隐层单元用低精度的数值进行表示,这种低精度表示明显减少了模型的内存带宽和存储要求并提高了模型的计算效率。为了进一步介绍低精度神经网络的优势,我们首先介绍几种精度的数值表示。
1. 浮点数
浮点格式通常用于表示实值。浮点数的表示由三部分组成:符号位,指数位和尾数位。符号位用来表示正负数值,指数给出了浮点格式的表示范围,尾数保证了浮点精度。常用的三种浮点数值的表示方法如图 1 所示。
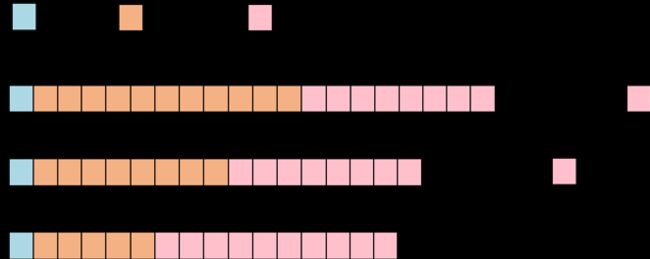
▲ 图1. 三种常用浮点数值表示
2. 定点数
定点数即小数点位置固定的数,主要包括定点整数和定点小数。相比于浮点数来说,定点数的存储方式更加简单,通常的方式就是对每一个十进制数进行 BCD 编码,然后加上一个额外的符号位,16 位整数和 8 位整数的表示方法如图 2 所示。
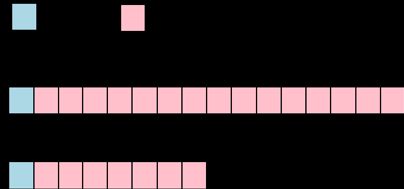
▲ 图2. 两种常用整数表示
低精度神经网络分类
低精度神经网络是用低精度数值表示的一类神经网络,网络参数用一些低精度浮点或是定点数进行表示。这种方法的主要目的是通过发挥低精度数值的运算优势,减少神经网络的空间复杂度和计算复杂度,以提升神经网络模型的计算和存储效率,同时还需保证网络的准确率不受影响。在这里,我们将低精度神经网络分为以下几类:1)单精度浮点网络;2)半精度/更低精度浮点网络;3)定点数网络。
1. 单精度浮点网络
相较于表示范围更广、数值精确度更高的双精度浮点,单精度浮点也是一种较低精度的数值,从这个角度来说,单精度浮点网络可以算是一种特殊的低精度神经网络。由于双精度浮点有着更多的指数位和尾数位,双精度浮点的表示范围更广,数值的刻画也更精细,这就使得双精度浮点网络往往具有更高的准确率。
从历史的经验上来看,在一些需求高性能计算的科学计算任务上(如:模拟人类心脏、计算航天飞机轨迹等),经常使用高精度 64 位浮点进行网络中参数表示,网络计算也比较依赖于 64 位浮点运算。但是,对于当前比较常见的感知和推理任务,例如语音识别,图像分类和机器翻译,单精度即可满足这种程度上的准确度需求。
优点:单精度浮点表示范围较广,可以满足大多神经网络计算需求。
缺点:相比于更低精度数值表示的神经网络,单精度浮点网络对存储资源和计算资源的要求较高,神经网络模型训练周期长、模型存储大,在磁盘间移动困难。
2. 半精度/更低精度浮点网络
随着大数据时代的到来,深度学习技术已经成为当前人工智能领域的一个研究热点,其在语音、图像和自然语言处理等人工智能子领域中单精度已经完全能够胜任模型准确性的需求,但由于浮点运算效率较低,且需要更大的存储空间,内存的访问也比较频繁,在一些深度神经网络中暴露出了致命的缺点:模型效率低下、模型存储要求高。
这就驱使了人们进行更低精度神经网络的研究,半精度/更低精度浮点网络应运而生,主要包括 FP16(16-bit 浮点)、FP8(8-bit 浮点)、FP9(9-bit 浮点)等等。
FP16 在 IEEE 中定义为 1bit 符号位、5bit 指数位、10bit 尾数位,Microsoft 在其 Project Brainwave 中提到了其专有的浮点格式 ms-fp8 和 ms-fp9。从数值表示的角度来看,数值的指数位和尾数位变少,数值精度会变低。
但其优势也很明显,仅从存储层面来看,FP16 相比于 FP32 直接降低了一半的内存需求,而 FP8 直接将内存降为原来的 1/4,部署时占用的存储也随之减小。从直觉来看,数值位数减少,计算也相对比较容易,但这需要特定型号的硬件支持。
优点:相比于单精度浮点网络,半精度/更低精度浮点网络计算效率高,更容易在较小的带宽上共享,也更易于模型的维护和更新。
缺点:相比于单精度浮点网络,半精度/更低精度浮点网络表示范围变小,且需特定的硬件支持,相比于定点计算效率仍较为低下。
3. 定点数网络
定点数类型的使用广泛用于数字信号处理和游戏应用中,其中性能有时比精度更重要。而浮点运算指令复杂,计算困难,因此一些超低功耗嵌入式设备(如无人机、手表等设备)上的微控制器并不支持浮点运算。相比于浮点运算,定点运算指令简单,定点数神经网络主要包括常规的整数网络和一些更为极端的网络(二值网络、三值网络等)。
优点:定点数网络效率高、功耗低且易于部署在嵌入式设备上。
缺点:需要特定的硬件支持,离散数值无法进行反向传播(求导困难),训练定点数网络时往往需要额外的 retraining 操作。
相关硬件支持
由于低精度数值计算常常需要特殊硬件,我们首先要对支持低精度运算的硬件有所了解。
在过去的十年中,计算资源一直是制约计算性能的一项重要因素。当前,低精度计算在机器学习中获得了很大的吸引力。很多公司为了适应低精度计算的需求甚至开始开发新的硬件架构,这些架构本身支持并加速低精度操作,包括微软的 Project Brainwave、Google 的 TPU、NVIDIA 的 Volta、Pascal 架构还有 Intel Xeon 处理器等等。
无论是基于 CPU 还是 GPU 上的张量计算,有关低精度的数值运算都比较依赖于特定型号的硬件支持,这些硬件上有针对低精度数值运算进行优化的特殊指令。然而这些硬件设备价格比较昂贵,如果无法满足上述硬件环境,也可在其他环境下进行低精度数值的模拟计算,通过空间复杂度和时间复杂度的变化来获取理论上的模型优化效果。
问题和挑战
尽管低精度神经网络模型的存储效率和计算效率得到了极大的提升,但当前对低精度神经网络的研究还处于初级阶段,仍存在着一些问题和挑战。
理论层面
首先从理论层面来说,对低精度神经网络的研究主要有以下问题:
1. 模型准确率无法保证:将神经网络中数值进行低精度化后,由于网络中数值表示范围减小,产生的最大问题就是对模型性能的影响。
2. 相关理论支撑:对于如何判断神经网络理论上最低的位宽,以及确定神经网络能接受的误差范围,需要完备的理论支持。
3. 累积误差不确定:神经网络中存在着一些累积操作(如:ReduceSum、ReduceMax、Softmax 等),这些操作的对象一般维度较大,除非已知当前输入张量中的最大值和数据分布,否则无法确定当前网络数值累积的上限。
4. 离散数值的梯度更新:低精度神经网络中数值分布比较离散,当前主流的神经网络梯度更新方法为反向传播算法,但反向传播算法只能进行连续空间上的优化,因此低精度神经网络适用的优化方法也是值得探索的一个问题。
实现层面
从工程实现的层面来说,在低精度神经网络的研究中主要存在以下问题:
1. 硬件资源限制:低精度神经网络中的低精度数值计算比较依赖于硬件支持,若没有针对低精度数值计算指令进行优化,无法得到理论上的加速效果。
2. 训练手段:低精度神经网络中数值精度较低,在训练手段方法有些需要注意的地方,比如是否需要添加一些 Scale 操作、是否需要 retraining 操作都需额外进行考虑。
发展现状
在背景章节中,本文介绍了深度学习经历的两阶段目标,在阶段一中,人们更关心的是模型的性能,而不需要考虑我们的网络到底需要多精确的计算,以及降低当前计算精度是不是会对模型性能产生确实的影响。在阶段二中,我们开始思考这个问题:对于一个神经网络,我们是不是能够以较低的数值精度进行表示?答案是肯定的,当前许多优秀的有关低精度网络的研究工作已经证实了这一点。
在一些研究工作中,降低神经网络数值精度的技术已被证明在加速深度学习训练和推理应用方面非常有效。2017 年微软在 Hot Chips 上介绍 Brainwave 时,也讨论了降低精度计算的好处。运行大型的神经网络需要大量的内存带宽和计算来进行权重获取和点积运算,低精度网络的目的就是解决由神经网络过参数化问题而导致的模型占存储空间大且训练和推断速度慢的问题。
当前针对低精度神经网络的研究工作主要有两大方面:低精度神经网络模型训练和模型推断,我们主要由这两方面入手,结合章节 3 中低精度神经网络面临的问题和挑战对低精度神经网络的发展现状进行介绍,在章节 5 中本文会结合当前有关发展给出对未来方向的一些展望。
模型训练
大多数深度学习框架,默认使用 32 位浮点(FP32)算法,是因为 32 位精度高、表示范围大。但是,对于所有操作而言,使用 FP32 对于实现许多最先进的深度神经网络(DNN)的完全准确性并不是必不可少的。
例如:Baidu Research 和 NVIDIA 研究人员介绍了一种混合精度训练方法,讨论了使用 16 位操作数和 32 位累加进行神经网络训练的好处,并且这种方法在一些大型神经网络和复杂任务上都取得了很好的效果,这种算法在 Volta GPU 提供以下的性能优势:FP16 将内存带宽和存储要求降低了 2 倍,还可实现高达 2 倍的加速;FP16 算法使 Volta Tensor Core 能够在广义矩阵乘法(GEMM)和卷积上提供 125 TFlops 的计算吞吐量,比 FP32 增加 8 倍吞吐量。
16 位训练系统当前比较普遍,在此基础上,IBM 研究人员在一系列深度学习数据集和神经网络中实现了 8 位精度的训练和 4 位精度的推理,使用 8 位浮点数成功训练 DNN,同时在一系列深度学习模型和数据集上完全保持了准确率,在 ResNet50,AlexNet 和 BN50_DNN,以及一系列图像,语音和文本数据集上,此技术相比于 16 位系统可达到 2 到 4 倍的加速比。
更极端的例子,比如在图像领域已经取得较好研究成果的 Binarized Neural Networks(BNN)、Ternary Weight Networks(TWN)和 XNOR-Net,在这些网络中仅仅使用 1bit 或者 2bit 数值进行网络训练,大大减少了存储器消耗(存储访问的大小和数量),可用逐位运算取代了大多数算术运算,极大的提升了模型的效率。
虽然当前已经存在一些低精度研究工作证明了低精度神经网络对模型优化的巨大潜力,但现有研究工作中还没有完全的低精度神经网络,这种完全是指在前向推断和反向更新的各个部件中全部使用低精度数值,以图 3 中混合精度方法的训练过程举例。虽然混合精度方法中使用的 16 位浮点有着 5 位指数位、10 位的尾数为,表示范围大概是 5.96×10^-8~6.55×10^4,但仍需部分使用 32 位浮点数进行训练。
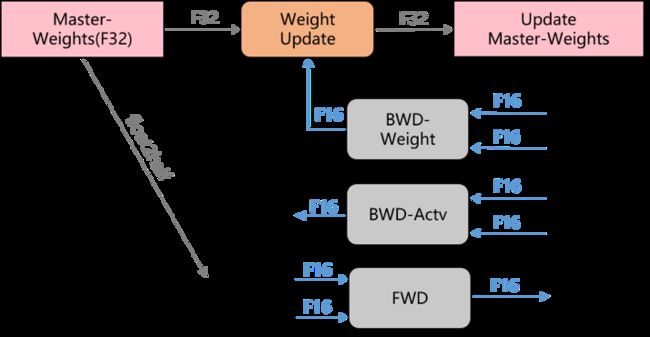
▲ 图3. 混合精度训练过程
低精度数值计算的优点是可以用一系列更快而且计算量更小的操作(如:位操作)来代替昂贵的浮点乘法操作,这不仅减少了内存的占用,还加速了网络的计算。但若数值精度过低,网络训练的准确性显着降低,这是由于低精度数值的表示范围有限,无法很准确的来逼近真实值。低精度神经网络的一个难点在于,低精度神经网络数值是离散的,在反向梯度更新阶段离散值难以求导,为低精度神经网络的训练带来了极大的挑战。
在当前阶段的低精度神经网络中,大多研究方法在反向阶段仍使用高精度数值来进行梯度更新。但像 Binarized Neural Networks 这种网络中不可避免的会存在一些硬阈值单元(Hard Thresholding),由于这类单元在几乎所有情况下导数都为 0,无法通过梯度下降进行训练,这时可以使用一种直通估计(Straight-Through Estimator,STE)方法,将每个硬阈值单位的导数替换为一个确定值,解决了硬值域函数的求导问题。
来自 Stanford 和 Cornell 的研究学者采用了一种新的随机梯度下降的变体,称为高准确率低精度(High-Accuracy Low-Precision,HALP),这种方法减少了限制低精度 SGD 精度的两个噪声源:梯度方差和舍入误差,可以比以前的算法做得更好。
模型推断
现有的 GPU 和 CPU 集群配备了丰富的内存资源和计算单元,使得强大的 DNN 模型能够在相对合理的时间段内进行训练,但长时间的推理对于一些实时应用来说却不切实际,因此我们需要神经网络模型能使用低精度数值进行推断。
降低模型精度是加速模型推断过程的有效方法,在提升计算效率的同时降低了内存带宽。从经验上来说,相比于模型训练阶段,推断阶段对网络中数值精度的要求更低。当前研究人员已经证明,深度学习训练和推理都可以用较低的数值精度进行。
目前,有两种主流方式可以降低推断过程的数值精度:1)从模型训练阶段进行低精度训练随后进行推断,这种方法中模型训练和推断过程是一致的,在上一小节已进行介绍,这里不再过多赘述;2)训练后进行低精度的量化,这个方法在模型训练之后进行操作,属于训练和推断数值精度不一致的一种方法。
在第二类方法中,可以用聚类的方式(比如:K-means 聚类)来进行混合低精度数值推断,也可以将网络的参数精度固定至 4-12bit,或更极端的用 1-2bit 来表示每个模型参数,即网络权重只能是 1 或者 -1,这种方法比较极端,可以极大减少浮点数的操作并简化专门为深度学习设计的硬件的实现方式。
对于混合低精度数值推断工作,Intel 并行计算实验室的研究人员在 Mixed Low-precision Deep Learning Inference using Dynamic FixedPoint 中用一种基于聚类的量化方法进行混合低精度数值的推断,在此种方法中网络中数值精度并不固定,将预先训练的单精度权重转换为三值权重,对于激活函数统一采取8位整数表示,这里的三值操作会导致模型性能明显的下降,因此最后还需要进行模型参数微调。和单精度神经网络相比,此研究工作可达到 16 倍的模型效率优化。
在当前比较流行的 Transformer 上,也有研究者进行了相关工作。在 Aishwarya Bhandare 等人的研究工作 Efficient 8-BitQuantization of Transformer Neural Machine Language Translation Model 中,首次在 Transformer 模型上进行神经机器翻译推断阶段的模型量化工作,用 8-bit 整数操作代替 32-bit 的浮点操作,一个最简单的 8-bit 整数矩阵乘法量化过程如图 4 所示。
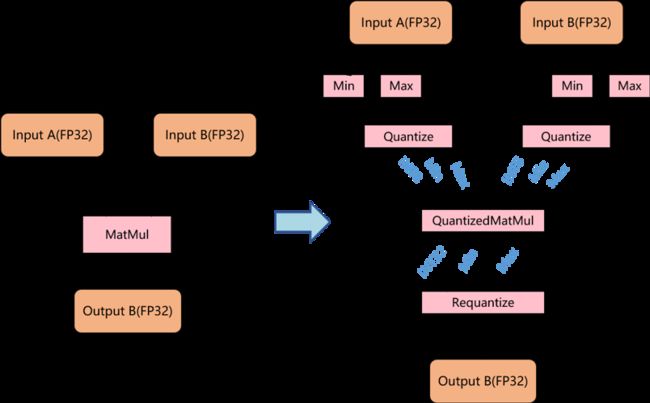
▲ 图4. 8-bit整数乘法量化过程
在该方法中,先将输入张量量化到 8-bit 整数,然后利用整数计算来加速整数乘法操作,为了保证乘法结果不溢出,计算结果用 32-bit 整数来保存。
总结
本小节主要针对第三部分的问题和挑战,对当前低精度神经网络的发展现状进行总结。
当前,针对低精度神经网络的研究工作确实不少,但理论支持并不完备。现在的神经网络低精度化方法其实大同小异,对于某一神经网络,其低精度化的最大程度往往是由反复实验得出,而不是通过数学上的理论推导。
值得欣慰的是,当前研究人员已经开始从数值分布的角度来思考低精度神经网络,但相关理论部分还有待进一步挖掘。对于容易产生上溢或下溢的一些操作,现在的研究方法都是使用表示范围较大的单精度浮点进行计算,但更理想的解决方案是使用更高效的数值进行计算,以最大程度的提升模型效率。
现有的低精度神经网络的反向传播大多仍使用高精度数值,其过程均基于反向传播方法,如何在神经网络反向部分使用低精度数值,并基于低精度数值进行离散空间的优化是一个值得研究的问题。
未来展望
目前对于低精度神经网络的研究仍属于初级阶段,当前的一些工作大多在小数据集和小规模模型上进行实验,如何在大规模神经网络上验证低精度神经网络的有效性,并利用低精度数值运算进行神经网络模型的加速仍是一个值得研究的问题。个人认为低精度神经网络模型有以下几个研究点非常值得研究:
1. 低精度神经网络的数学原理:当前缺乏针对低精度神经网络的分析类工作,如何针对某一神经网络,在保证其网络准确率的前提下,分析论证其理论上可达到的最低数值精度,是一个值得深思的问题。
2. 低精度神经网络+离散空间优化:受 Hinton 的 Capsule 计划的启发,越来越多的研究人员开始探讨代替反向传播的方法。由于低精度神经网络中参数分布较为离散,反向传播算法显然不适用,当前研究工作大多仍然采用高精度数值来进行反向梯度更新,缺少离散空间优化问题的求解。
3. 低精度神经网络+其他优化目标:将低精度神经网络和一些其他的优化目标相结合,在尽可能高的提升模型计算效率的前提下增加其他的一些优化目标(诸如资源限制),这非常有利于有限资源环境下的神经网络模型部署。
4. 低精度神经网络+结构学习:神经网络模型中的不同模块需要不同的精度,可以将其与结构学习相结合,结构学习的搜索结果为一个低精度网络,不同模块可以有不同的精度表示。
相关资料
1. Dean J, Corrado G S, Monga R, et al. Large scale distributed deep networks[C]//International Conference on Neural Information Processing Systems. CurranAssociates Inc. 2012:1223-1231.
2. Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks withpruning, trained quantization and huffman coding[J]. arXiv preprintarXiv:1510.00149, 2015.
3. Gupta S, Agrawal A, Gopalakrishnan K, et al. Deep learning with limited numericalprecision[C]//International Conference on Machine Learning. 2015: 1737-1746.
4. 林野, 姜雨帆, 肖桐,等. 面向神经机器翻译的模型存储压缩方法分析[J]. 中文信息学报, 2019, 33(1):98-107.
5. CourbariauxM, Bengio Y, David J, et al. Low precision arithmetic for deep learning[J].international conference on learning representations, 2014.
6. CourbariauxM, Bengio Y, David J P. Training deep neural networks with low precisionmultiplications[J]. arXiv preprint arXiv:1412.7024, 2014.
7. MicikeviciusP, Narang S, Alben J, et al. Mixed precision training[J]. arXiv preprintarXiv:1710.03740, 2017.
8. Wang N, Choi J, Brand D, et al. Training deep neural networks with 8-bit floatingpoint numbers[C]//Advances in neural information processing systems. 2018:7675-7684.
9. CourbariauxM, Bengio Y. Binarynet: Training deep neural networks with weights andactivations constrained to+ 1 or− 1. arXiv 2016[J]. arXiv preprintarXiv:1602.02830.
10. Lahoud F, Achanta R, Márquez-Neila P, et al. Self-Binarizing Networks[J]. arXiv preprintarXiv:1902.00730, 2019.
11. Li F, Zhang B, Liu B. Ternaryweight networks[J]. arXiv preprint arXiv:1605.04711, 2016.
12. Rastegari M, Ordonez V, RedmonJ, et al. Xnor-net: Imagenet classification using binary convolutional neuralnetworks[C]//European Conference on Computer Vision. Springer, Cham, 2016:525-542.
13. De Sa C, Leszczynski M, ZhangJ, et al. High-accuracy low-precision training[J]. arXiv preprintarXiv:1803.03383, 2018.
14. Moons B, Goetschalckx K, VanBerckelaer N, et al. Minimum energy quantized neural networks[C]//2017 51stAsilomar Conference on Signals, Systems, and Computers. IEEE, 2017: 1921-1925.
15. Quinn J, Ballesteros M. Piecesof eight: 8-bit neural machine translation[J]. arXiv preprint arXiv:1804.05038,2018.
16. Banner R, Hubara I, Hoffer E,et al. Scalable methods for 8-bit training of neural networks[C]//Advances inNeural Information Processing Systems. 2018: 5145-5153.
17. Ott M, Edunov S, Grangier D,et al. Scaling neural machine translation[J]. arXiv preprint arXiv:1806.00187,2018.
18. Mellempudi N, Kundu A, Das D,et al. Mixed low-precision deep learning inference using dynamic fixedpoint[J]. arXiv preprint arXiv:1701.08978, 2017.
19. Bhandare A, Sripathi V,Karkada D, et al. Efficient 8-Bit Quantization of Transformer Neural MachineLanguage Translation Model[J]. arXiv preprint arXiv:1906.00532, 2019.
20. Friesen A L, Domingos P M.Deep Learning as a Mixed Convex-Combinatorial Optimization Problem[J].international conference on learning representations, 2018.
本文作者介绍:
林野,东北大学自然语言处理实验室 2019 级博士生,研究方向:机器翻译、模型压缩、模型加速。
东北大学自然语言处理实验室:
东北大学自然语言处理实验室由姚天顺教授创建于 1980 年,现由朱靖波教授领导,长期从事计算语言学的相关研究工作,主要包括机器翻译、语言分析、文本挖掘等。

点击以下标题查看更多往期内容:
图神经网络综述:模型与应用
ACL 2019 | 基于知识增强的语言表示模型
ACL 2019 | 基于上下文感知的向量优化
基于小样本学习的意图识别冷启动
复旦大学邱锡鹏:词法、句法分析研究进展综述
ACL 2019 | 句对匹配的样本选择偏差与去偏方法
深度长文:NLP的巨人肩膀(上)
NLP 的巨人肩膀(下):从 CoVe 到 BERT
 #投 稿 通 道#
#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 获取最新论文推荐