常见的深度学习基础知识总结(持续更新中)
一、网络中的传播与优化
(1)反向传播公式推导:
- 参考链接:https://blog.csdn.net/qq_32865355/article/details/80260212
(2)参数初始化:
-
参数初始化的设计一般以激活函数的性质为原则。
-
要保证训练集和测试集用于初始化的 μ μ μ和 σ σ σ相等,即将训练集初始化过程中计算所得的均值 μ μ μ和方差 σ σ σ的值应用于测试集的初始化?
-
全0初始化:深层网络参数不能全0初始化,否则将导致每个隐藏单元(hidden unit)的值相等,使网络中的每一条路径都在拟合同一个函数,即庞大网络计算的函数仅相当于一个神经元所计算的函数。
-
随机初始化:随机取一些很小的值进行初始化,实验表明数值大了容易饱和,小了就激活不动,因此该方法非常不稳定。
-
如果参数初始化的值符合某种分布如 N ( 0 , 1 ) N(0,1) N(0,1)或 U ( − 1 , 1 ) U(-1,1) U(−1,1),此时初始化参数的均值为0,方差为1,训练会更稳定,如以下初始化方法:
-
标准初始化:
1、Standard Normal: W i , j W_{i,j} Wi,j ~ N ( 0 , 1 n i n ) N(0, {1\over n_{in}}) N(0,nin1)
2、Standard Uniform: W i , j W_{i,j} Wi,j ~ U ( − 1 n i n , 1 n i n ) U({-{1\over \sqrt{n_{in}}}}, {1\over \sqrt{n_{in}}}) U(−nin1,nin1) -
Xavier初始化(适用于Tanh):
1、Xavier Normal: W i , j W_{i,j} Wi,j ~ N ( 0 , 2 n i n + n o u t ) N(0, {2\over n_{in}+n_{out}}) N(0,nin+nout2)
2、Xavier Uniform: W i , j W_{i,j} Wi,j ~ U ( − 6 n i n + n o u t , 6 n i n + n o u t ) U({-\sqrt{{6\over {n_{in}+n_{out}}}}},\sqrt{{6\over {n_{in}+n_{out}}}}) U(−nin+nout6,nin+nout6) -
He初始化(适用于ReLU):
1、Xavier Normal: W i , j W_{i,j} Wi,j ~ N ( 0 , 2 n i n ) N(0, {2\over n_{in}}) N(0,nin2)
2、Xavier Uniform: W i , j W_{i,j} Wi,j ~ U ( − 6 n i n , 6 n i n ) U({-\sqrt{{6\over {n_{in}}}}},\sqrt{{6\over {n_{in}}}}) U(−nin6,nin6)
附上He初始化推导过程:https://blog.csdn.net/VictoriaW/article/details/73166752
(3)正则化:
一、逻辑回归的正则化(单层网络):
- L1: J ( w , b ) = J(w,b)= J(w,b)= 1 m 1\over m m1 ∑ i = 1 m L ( y ^ i , y i ) + λ m ∥ w ∥ 1 , ∥ w ∥ 1 = ∑ i = 1 n ∣ w i ∣ \sum_{i=1}^mL(\hat{y}^{i},y^{i})+{λ\over m}{\begin{Vmatrix} w\\ \end{Vmatrix}}_1,{\begin{Vmatrix} w\\ \end{Vmatrix}}_1= \sum_{i=1}^n\mid w_i \mid ∑i=1mL(y^i,yi)+mλ∥∥w∥∥1,∥∥w∥∥1=∑i=1n∣wi∣
- L2: J ( w , b ) = J(w,b)= J(w,b)= 1 m 1\over m m1 ∑ i = 1 m L ( y ^ i , y i ) + λ 2 m ∥ w ∥ 2 2 , ∥ w ∥ 2 2 = ∑ i = 1 n w i 2 = W T W \sum_{i=1}^mL(\hat{y}^{i},y^{i})+{λ\over 2m}{\begin{Vmatrix} w\\ \end{Vmatrix}}_2^2,{\begin{Vmatrix} w\\ \end{Vmatrix}}_2^2 = \sum_{i=1}^n w_i^2=W^TW ∑i=1mL(y^i,yi)+2mλ∥∥w∥∥22,∥∥w∥∥22=∑i=1nwi2=WTW
二、深度神经网络中的正则化( l l l层网络):
- Fobenius Norm:
L2计算的是一层w的平方范数,而F范数实际上就是 l l l层的w的L2范数的和。
J ( w [ 1 ] , b [ 1 ] . . . w [ l ] , b [ l ] ) = J(w^{[1]},b^{[1]}...w^{[l]},b^{[l]})= J(w[1],b[1]...w[l],b[l])= 1 m 1\over m m1 ∑ i = 1 m L ( y ^ i , y i ) + λ 2 m ∑ l = 1 L ∥ w [ l ] ∥ F 2 , \sum_{i=1}^mL(\hat{y}^{i},y^{i})+{λ\over 2m}\sum_{l=1}^L{\begin{Vmatrix} w^{[l]}\\ \end{Vmatrix}}_F^2, ∑i=1mL(y^i,yi)+2mλ∑l=1L∥∥w[l]∥∥F2,
∥ w [ l ] ∥ F 2 = ∑ i = 1 n [ l − 1 ] ∑ j = 1 n [ l ] w i , j [ l ] 2 {\begin{Vmatrix} w^{[l]}\\ \end{Vmatrix}}_F^2 = \sum_{i=1}^{n^{[l-1]}} \sum_{j=1}^{n{[l]}} {w_{i,j}^{[l]}}^2 ∥∥w[l]∥∥F2=∑i=1n[l−1]∑j=1n[l]wi,j[l]2 - Dropout:
(4)标准化(归一化):
- BN(Batch Normalization) and ICS(Internal Covariate Shift)
- 相关链接:https://zhuanlan.zhihu.com/p/33173246
(5)激活函数的选择:
-
S i g m o i d : Sigmoid: Sigmoid:
g ( z ) = g(z) = g(z)= 1 1 + e − z 1 \over 1+e^{-z} 1+e−z1,仅用于二元分类输出层。
导数:
g ′ ( z ) = g^\prime(z) = g′(z)= g ( z ) ⋅ [ 1 − g ( z ) ] g(z)·[1-g(z)] g(z)⋅[1−g(z)],当 z = z= z= 10 / − 10 10/-10 10/−10时, g ( z ) = g(z)= g(z)= 1 / 0 1/0 1/0, g ′ ( z ) = g^\prime(z)= g′(z)= 0 / 0 0/0 0/0;由此可得,当某层网络输出过大或过小时,在反向传播中计算经过激活函数的导数结果为0,从而导致梯度平缓,影响学习效率。
缺点:
1、激活函数计算量大,反向传播求误差梯度时,求导涉及除法。
2、反向传播时,函数容易饱和,会出现梯度消失的情况,从而无法完成深层网络的训练。 -
T a n h : Tanh: Tanh:
g ( z ) = g(z)= g(z)= e x − e − x e x + e − x e^x-e^{-x}\over e^x+e^{-x} ex+e−xex−e−x
导数:
g ′ ( z ) = g^\prime(z) = g′(z)= 1 − g 2 ( z ) 1-g^2(z) 1−g2(z),当 z = z= z= 10 / − 10 10/-10 10/−10时, g ( z ) = g(z)= g(z)= 1 / 0 1/0 1/0, g ′ ( z ) = g^\prime(z)= g′(z)= 0 / 0 0/0 0/0;由此可得, T a n h Tanh Tanh函数导数性质同上,容易导致梯度平缓甚至梯度消失,影响学习效率。
特点:
缺点和 S i g m o i d Sigmoid Sigmoid 差不多,比 S i g m o i d Sigmoid Sigmoid 好在函数以0为均值,网络收敛速度稍快一些;同时激活值区间(-1~1)比 S i g m o i d Sigmoid Sigmoid 的大,使得特征分离空间大一些,效果明显一些。 -
R e L U : ReLU: ReLU: g ( z ) = g(z)= g(z)= m a x ( 0 , z ) max(0,z) max(0,z)
导数: g ′ ( z ) = { 0 , z < 0 1 , z > 0 g^\prime(z) = \begin{cases} 0, & \text{$z$ < 0} \\ 1, & \text{$z$ > 0} \end{cases} g′(z)={0,1,z < 0z > 0
由此可得,ReLU具备三个优点:
1、反向传播中,导数的计算量非常小。
2、网络输出为负时会被屏蔽,此操作和 D r o p o u t Dropout Dropout类似,会增加网络的稀疏性,防止过拟合。
3、网络输出为正时,反向传播中计算激活函数的导数结果恒为1,有效解决梯度消失问题。
同时缺点是:
容易使网络中较多的神经元的输出值变为0,导致部分信息丢失,以及网络中神经元的冗余。 -
L e a k y R e L U : Leaky ReLU: LeakyReLU: g ( z ) = g(z)= g(z)= m a x ( 0.01 ⋅ z , z ) max(0.01·z,z) max(0.01⋅z,z)
导数: g ′ ( z ) = { 0.01 , z < 0 1 , z > 0 g^\prime(z) = \begin{cases} 0.01, & \text{$z$ < 0} \\ 1, & \text{$z$ > 0} \end{cases} g′(z)={0.01,1,z < 0z > 0
由此可见,性质与 R e L U ReLU ReLU的差别不大。 -
P R e L U PReLU PReLU:
-
E R e L U EReLU EReLU
(6)损失函数的选择:
(6)不同优化方法的公式推导及优缺点:
-
指数加权平均:https://www.jianshu.com/p/41218cb5e099?utm_source=oschina-app
-
一、为何使用指数加权平均:指数加权平均相较于传统求平均的优势在于,每次计算只需要两个值:当前值 θ θ θ以及积累值 V t V_t Vt,这样的计算既节约内存,又能提高运算效率,而且在代码中实现也仅需一行指令。
-
二、指数加权平均的偏差修正:解决迭代初期所求均值过小的问题。
参考链接:https://mooc.study.163.com/learn/2001281003?tid=2001391036&trace_c_p_k2=049bde7d6d7c4f47a8abcef59fde53f3#/learn/content?type=detail&id=2001702122&cid=2001693071(需先注册网易云课堂用户再进入此链接,参考自吴恩达深度学习视频) -
优化算法:https://zhuanlan.zhihu.com/p/32230623,https://zhuanlan.zhihu.com/p/22252270
-
一、Momentum的形象理解:首先需要理解 d W dW dW是向量,既指导参数更新大小,也指导参数更新的方向(如图所示的蓝色箭头所示)。经过指数加权平均处理的权重更新算法(Momentum)会求出多次迭代所得 d W dW dW的均值,这样的计算会使得 d W dW dW数竖直方向(偏离目标值的方向)的分量互相抵消,水平方向(指向目标值的方向)的分量叠加,从而使得图中的蓝色箭头变成红色箭头,也就是纵向摆动削弱,横向梯度下降速度加快。
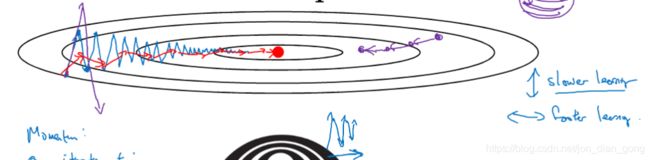
-
二、NAG和SGDM(SGM with Momentum)区别的简单理解:将SGDM的公式化成最简式后观察梯度,实际上就是之前累积梯度和当前梯度分别乘以合适的系数后的简单叠加,而NAG比SGDM多做一步操作,就是让之前累积的梯度先直接影响当前梯度,然后再把之前累积的梯度和被影响过后的当前梯度分别乘以合适的系数后再相加。
-
三、自适应学习率的含义:自适应学习率和学习率衰减都是要让学习率根据训练情况进行调整,但两者有本质的区别。自适应学习率要适应的是迭代过程中不同参数的更新速率,有的参数前期更新较快且学习相对饱满,自适应学习会让其降速,反之则增速;而学习率衰减中的学习率变化是为了避免函数收敛后期学习步长太大而错过收敛点。
(7)梯度消失/爆炸的原因、影响以及解决办法:
- CNN、MLP的梯度消失/爆炸的含义与RNN中的不同,CNN、MLP中的梯度消失/爆炸就是指经过多次迭代计算所得的梯度值太小/太大,导致参数值更新停滞/过大,影响函数收敛效率。
- RNN中的梯度消失/爆炸:
(8)过拟合与欠拟合的含义、原理及解决方法:
维度灾难(curse of dimensionality)会引起过拟合
(9)上采样方法
二、CNN:
(1)CNN各经典网络的演变方向以及优缺点:
1、 L e N e t LeNet LeNet:针对灰度图像,用sigmoid和tanh
2、 A l e x N e t AlexNet AlexNet:用relu,分组卷积,local response normalization(LRN,局部响应归一化层)
3、 V G G N e t VGGNet VGGNet:泛化性能非常好;最大的问题在于参数数量
4、 R e s N e t ResNet ResNet:容易学习恒等式(easy to learn the identity function),保证网络加了resblock以后的performance不会降低
5、 G o o g l e N e t , v 1 − v 4 GoogleNet,v1-v4 GoogleNet,v1−v4:它没有如同 VGG-Net 那样大量使用全连接网络,因此参数量非常小;将网络扩展的方向从深度转变为宽度。
(2)CNN在图像处理中优于全连接层的原因:
1、参数共享(parameter sharing):
在图像处理中,能够用一个固定算子(如 sobel 算子)检测全图不同部位的边缘特征,那么在卷积神经网络(CNN)中,用于特征提取的单个 filter 也能够提取整张图中所有对应的特征,卷积这样的特点使得较大的输入(如 128 × 128 128×128 128×128)只需要单个 filter(如 5 × 5 5×5 5×5) 便可以实现全图(1 28 × 128 28×128 28×128)范围内的特征提取, 实现了参数共享,大大降低了所需的参数数量。
2、稀疏连接(sparsity of connections):
假设某卷积层的 filter 大小为 F × F F×F F×F,那么输出的某一个像素点只和输入的某个 F × F F×F F×F 区域有联系,相对于全连接来说,这种稀疏连接的方法也大大降低了所需的参数数量。
(3)CNN输入输出维度关系:
- 输入图片大小: W × W W×W W×W
- Filter大小: F × F F×F F×F
- Stride: S S S
- Padding: P P P
- 输出图片大小: N × N N×N N×N
N = N = N= ( W − F + 2 ⋅ P ) S (W - F + 2·P) \over S S(W−F+2⋅P) + 1
- 由此可推导,若要保持输入输出维度不变(S = 1时):
P = P = P= ( F − 1 ) 2 (F - 1) \over 2 2(F−1)
(4)CNN感受野
1、感受野的概念:
The receptive field is defined as the region in the input space that a particular CNN’s feature is looking at (i.e. be affected by). —— Dang Ha The Hien
在卷积神经网络中,感受野的定义是 卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。 ——博客园
在机器视觉领域的深度神经网络中有一个概念叫做感受野,用来表示网络内部的不同位置的神经元对原图像的感受范围的大小。 ——蓝荣祎
2、感受野的计算
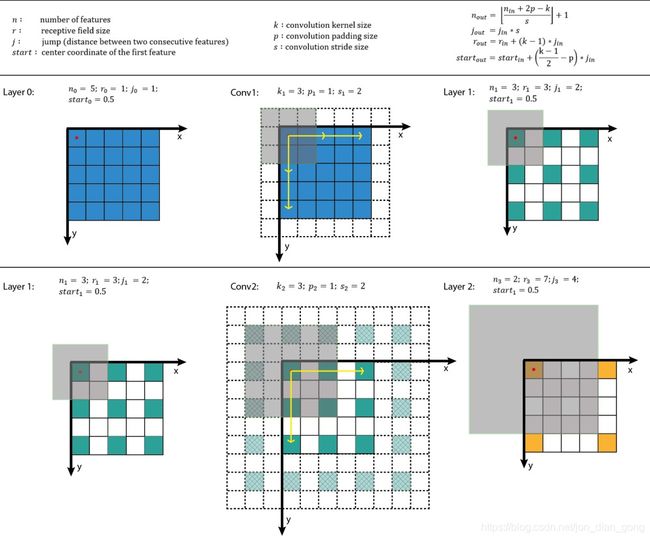
3、对感受野的一些个人理解:
- 某一层feature map(特性图)中某个位置的特征向量,是由前面某一层固定区域(patch)的输入计算出来的,那这个区域就是这个位置的感受野。而根据感受野的公式定义可以看出,感受野代表的只是这个固定区域(patch)的大小,而不限制由 patch 变成某特征向量的过程中的计算。
- 换句话说,如果某层卷积的stride非常大,按照公式计算,该层卷积输出的感受野也非常大,但是实际原输入和卷积核做计算的部分面积很小,那这个很大的感受野会不会失去了衡量输出特征包含输入信息量的意义?
(5)CNN复杂度分析:
1、时间复杂度
即模型的运算次数,可用 F L O P s FLOPs FLOPs 衡量,也就是浮点运算次数(FLoating-point OPerations)。
1.1、单个卷积层的时间复杂度:
- 输入通道数: C i n C_{in} Cin
- 输出通道数: C o u t C_{out} Cout
- Filter大小: F × F F×F F×F
- 输出图片大小: N × N N×N N×N
T i m e Time Time ~ O ( F 2 ⋅ N 2 ⋅ C i n ⋅ C o u t ) O(F^2 · N^2 · C_{in} · C_{out}) O(F2⋅N2⋅Cin⋅Cout)
- 为简化表达式中的变量个数,假设输入和卷积核都为正方形;
- 每层中的参数应该还包含1个Bias,此处为了简洁而省略。
1.2、卷积神经网络整体的时间复杂度:
- 神经网络所具有的卷积层数,即网络的深度: D D D
- 神经网络的第 l l l个卷积层: l l l
- 第 l l l层输出: C l C_{l} Cl
- 第 l l l层输入,即第 l − 1 l-1 l−1层输出: C l − 1 C_{l-1} Cl−1
- Filter大小: F × F F×F F×F
- 输出图片大小: N × N N×N N×N
T i m e Time Time ~ O ( ∑ l = 1 D F l 2 ⋅ N l 2 ⋅ C l − 1 ⋅ C l ) O(\sum_{l=1}^D F_l^2 · N_l^2 · C_{l-1} · C_{l}) O(∑l=1DFl2⋅Nl2⋅Cl−1⋅Cl)
- 有表达式可以看出,其实是将每一个卷积层的时间复杂度叠加起来;
- 简而言之,层内连乘,层间累加。
2、空间复杂度
空间复杂度(访存量),严格来讲包括两部分:总参数量 + 各层输出特征图。
参数量:模型所有带参数的层的权重参数总量(即模型体积,下式第一个求和表达式)
特征图:模型在实时运行过程中每层所计算出的输出特征图大小(下式第二个求和表达式)
S p a c e Space Space ~ O ( ∑ l = 1 D F l 2 ⋅ C l − 1 ⋅ C l + ∑ l = 1 D N l 2 ⋅ C l ) O(\sum_{l=1}^D F_l^2 · C_{l-1} · C_{l}+\sum_{l=1}^DN_l^2· C_{l}) O(∑l=1DFl2⋅Cl−1⋅Cl+∑l=1DNl2⋅Cl)
- 总参数量只与卷积核的尺寸 F F F、通道数 C C C、层数 l l l 相关,而与输入数据的大小无关。
- 注:实际上有些层(例如 R e L U ReLU ReLU)其实是可以通过原位运算完成的,此时就不用统计输出特征图这一项了。
3、复杂度对模型的影响:
- 时间复杂度决定了模型的训练/预测时间。如果复杂度过高,则会导致模型训练和预测耗费大量时间,既无法快速的验证想法和改善模型,也无法做到快速的预测。
- 空间复杂度决定了模型的参数数量。由于维度灾难(curse of dimensionality)的限制,模型的参数越多,训练模型所需的数据量就越大,而现实生活中的数据集通常不会太大,这会导致模型的训练更容易过拟合。
- 当我们需要裁剪模型时,由于卷积核的空间尺寸通常已经很小( 3 × 3 3×3 3×3),而网络的深度又与模型的表征能力紧密相关,不宜过多削减,因此模型裁剪通常最先下手的地方就是通道数。
三、其他经典网络思想:
(1)SENet:
(2)MobileNet:卷积的拆分
(3)DenseNet:Dense和Res的区别以及优缺点
四、深度学习面经参考(牛客网)
- https://www.nowcoder.com/discuss/65323?type=post&order=time&pos=&page=1
- https://www.nowcoder.com/discuss/87657?type=post&order=jing&pos=&page=1