《深度学习》ing-8=10.2
9#教材
- 《深度学习》by Ian Goodfellow
#学习周期
6.28 chap1-3
6.29 chap4-5
6.30 chap5-6
7.1 chap6
7.4 chap9 卷积网络
7.5 CNN
7.8 Chap6 反向传播算法和计算图
7.9 Chap6 架构设计和BP
7.11 Chap6 BP和CNN
7.22 Chap7 正则化
8.2 Chap8 深度学习中的优化
Chap9 卷积网络 -知乎
Chap10 循环神经网络 -知乎
#Chap4 数值计算
- 机器学习算法通常需要大量的数值计算,指通过迭代过程更新解的估计值来解决数学问题的算法,而不是通过解析过程推导出公式来提供正确解的方法
##C4.1 上溢和下溢
- underflow:舍入误差
- overfolow
- softmax函数
##C4.2 病态条件
- 条件数指的是函数相对于输入的微小变化而变化的快慢程度,条件数越大,矩阵越病态
- condition number 是一个矩阵(或者它所描述的线性系统)的稳定性或者敏感度的度量,如果一个矩阵的 condition number 在1附近,那么它就是well-conditioned的,如果远大于1,那么它就是 ill-conditioned 的,如果一个系统是 ill-conditioned 的,它的输出结果就不要太相信了。

##C4.3 基于梯度的优化方法
- 1维R -> R:导数
- N维R -> R:梯度
- m维R -> n维R:一阶导(Jacobian矩阵)、二阶导(Hessian矩阵,等价于梯度的Jacobian矩阵)
- 多维情况下,单个点处每个方向上的二阶导数是不同的,Hessian的条件数衡量这些二阶导数的变化范围。当Hessian的条件数很差时,梯度下降法表现的很差,因为一个方向上的导数增加得很快,但另一个方向上增加得很慢。
- 牛顿法
##C4.4 约束优化 - KKT条件
#Chap5 机器学习基础
##C5.1 学习算法
- 对于某类任务T和性能度量P,一个计算机程序被认为可以从经验E中学习是指,通过经验E改进后,它在任务T上由性能度量P衡量的性能有所提升。
##C5.2 容量、过拟合、欠拟合
- 模型容量(capacity),指拟合各种函数的能力,容量低的模型可能很难拟合训练集,容量高的模型可能会过拟合。(模型复杂度?)
- 控制算法容量的方法是选择假设空间,即学习算法可以选择为解决方案的函数集。
- 权重衰减(weight decay)
- 过拟合与欠拟合,参考《machine learning yearning》,正则化项
##C5.3 超参数和验证集
- 超参数用来控制算法香味,不是通过学习算法本身学习出来的,比如容量超参数。如果在训练集上学习超参数,这些超参数总是趋向于最大可能的模型容量。
##C5.4 估计、偏差和方差
##C5.5 最大似然估计
##C5.6 贝叶斯估计
##C5.7 监督学习算法
- 概率监督学习(逻辑回归)
- 支持向量机(SVM)
- 决策树
##C5.8 无监督学习算法
- 主成分分析(PCA)
- k-means
##C5.9 随机梯度下降
- minibatch SGD
##C5.10 构建机器学习算法
##C5.11 促使深度学习发展的挑战
- 维数灾难(curse of dimensionality)
- 局部不变性和平滑正则化
- 平滑先验和局部不变性先验表面我们学习的函数不应在小区域内发生很大的变化。
- 流形学习
- 流形(manifold),指连接在一起的区域。数学上指一组点,每个点都有其领域。
- 流形学习算法通过一个假设来克服障碍,该假设认为 Rn 中大部分区域都是无效的输入,有意义的输入只分布在包含少量数据点的子集构成的一组流形中。而学习函数的输出中,有意义的变化都沿着流形的方向或仅发生在我们切换到另一流形时。
- 知乎:https://www.zhihu.com/question/24015486
- 我们所能观察到的数据实际上是由一个低维流形映射到高维空间上的,m维流行在n维欧式空间的嵌入。由于数据内部特征的限制,一些高维中的数据会产生维度上的冗余,实际上只需要比较低的维度就能唯一地表示。
- 流形学习的一个主要应用就是“非线性降维” (参见Wikipedia: Nonlinear dimensionality reduction) 而非线性降维因为考虑到了流形的问题,所以降维的过程中不但考虑到了距离,更考虑到了生成数据的拓扑结构。本质是一种:“将数据从高维空间降维到低维空间,还能不损失信息”的映射。原空间中的样本分布可能及其扭曲,平铺之后将更有利于样本之间的距离度量,其距离将能更好地反映两个样本之间的相似性。
- CSDN:https://blog.csdn.net/bbbeoy/article/details/78002756


- 其他:http://blog.pluskid.org/?p=533
- 直观上来讲,一个流形好比是一个 d 维的空间,在一个 m 维的空间中 (m > d) 被扭曲之后的结果。需要注意的是,流形并不是一个“形状”,而是一个“空间”
- 测地距离
##C5.12学习算法
- 对于某类任务T和性能度量P,一个计算机程序被认为可以从经验E中学习是指,通过经验E改进后,它在任务T上由性能度量P衡量的性能有所提升。
#Chap6 深度前馈网络
- 前向(feedforward)表示信息流过x得函数,流经用于定义f的中间计算过程,最终到达输出y。在模型的输出和模型本身之间没有反馈(feedback)连接。当前馈神经网络包含反馈连接时,它们被称为循环神经网络(rnn、recurrent neural network)
##C6.1 学习XOR
- XOR函数(异或运算)是两个二进制x1和x2的运算,当x1或x2中恰好有一个为1时,XOR函数返回1,其余情况返回0。
- 大多数神经网络通过仿射变换之后紧跟着一个被称为激活函数的固定非线性函数来实现这个目标,其中仿射变换由学得的参数控制。(把线性转换为非线性)
##C6.2 基于梯度的学习
- 线性模型和神经网络的最大区别,在于神经网络的非线性导致大多数我们感兴趣的代价函数都变得非凸。这意味着神经网络通常使用迭代的、基于梯度的优化,仅仅使得代价函数达到一个非常小的值,而不是像用于训练回归模型的线性方程求解器,或者用于训练逻辑回归或SVM的凸优化算法那样保证全局收敛。
- 凸优化对初始参数的选取不敏感,总会收敛到最优,而前馈神经网络问题对参数初始值很敏感,对于前馈神经网络,将所有的权重值初始化为小随机数是很重要的。
###C6.2.1代价函数
- 凸优化对初始参数的选取不敏感,总会收敛到最优,而前馈神经网络问题对参数初始值很敏感,对于前馈神经网络,将所有的权重值初始化为小随机数是很重要的。
- 大部分NN最后解决的是分类问题,选择训练数据和模型预测间的交叉熵作为代价函数。
- 代价函数的梯度必须足够得大和具有足够的预测性,来为学习算法提供一个好的指引。
- 交叉熵损失函数:
- https://blog.csdn.net/chaipp0607/article/details/73392175


- https://blog.csdn.net/jasonzzj/article/details/52017438 交叉熵损失函数的推导
###C6.2.2输出单元
- 本节讨论输出层的单元形式,输出层的单元也可以作为隐藏层。
- 线性单元 y=wx+b
- sigmoid单元 y=sigmoid(wx+b)
- softmax单元 softmax(z)=exp(z)/sum(exp(z)),自然地表示具有k个可能值得离散型随机变量的概率分布,由于sum(z)=1,所以不同预测之间会有competitive。
- 如果输出不是概率值,用softmax函数

- 其他输出类型:
- 对角精度矩阵:diag(beta)
- 混合密度网络
##C6.3 隐藏单元(激活函数)
- 激活函数的作用是在神经网络中引入非线性
- 整流线性单元(rectified linear unit, ReLU)
- 优点:
- 易于优化,因为它和线性单元非常类似。使得只要整流线性单元处于激活状态时,它的导数都能保持较大。
- 二阶导数处处为0,激活状态下一阶导数处处为1,便于梯度学习
- 缺点:
- 不能通过梯度的方法学习那些使它们激活为0的样本。 ->ReLU的拓展:基于x<0时使用一个非0斜率
- 优点:
- maxout:g(z) = maxz relu的一种拓展
- sigmod:sigma(z)
- 特点:易饱和,仅当z接近0时才对输入强烈敏感
- 双曲正切:tanh(z) = 2*sigma(2z)-1
- 其他隐藏单元:
- 无激活函数:线性输出,纯线性网络
- 径向基函数(radial basis function, RBF)
- softplus函数:g(a)=log(1=e^a),是ReLU的平滑版本
- 硬双曲正切函数
##C6.4 架构设计
- 架构 architecture 指网络的整体结构:单元数量及单元连接方式
- 层:单元组
- 万能近似定理:一个前馈神经网络如果具有线性输出层和至少一层具有任何一种“挤压”性质的激活函数的移仓层,只要给予网络足够数量的隐藏单元,它可以以任意的精度来近似任何一个有限维空间到另一个有限维空间的Borel可测函数。前馈网络的导数也可以任意好地近似函数的导数
- https://zhuanlan.zhihu.com/p/39030338
- 「通用近似定理 (Universal approximation theorem,一译万能逼近定理)」指的是:如果一个前馈神经网络具有线性输出层和至少一层隐藏层,只要给予网络足够数量的神经元,便可以实现以足够高精度来逼近任意一个在 ℝn 的紧子集 (Compact subset) 上的连续函数。
- 模型越深越好,不是越宽越好
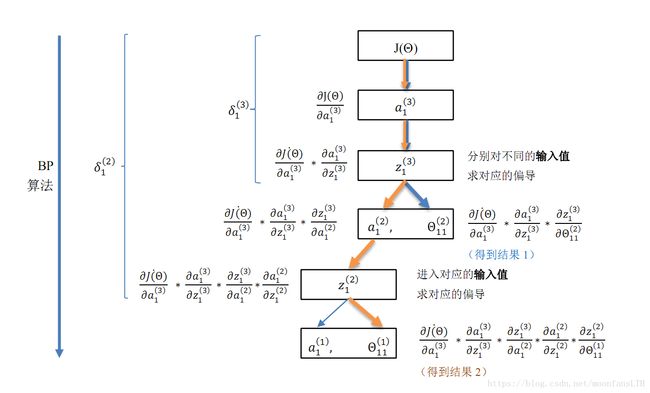
##C6.5 反向传播和其他微分算法
- 前向传播 forward propagation:输入x,传播到每一层的隐藏单元,产生输出y。训练中,FB可以持续向前直到它产生一个标量代价函数。
- 反向传播 back propagation:允许来自代价函数的信息通过网络向后传播,以便计算梯度。是一种计算函数梯度的方法
###C6.5.1 计算图 - 张量(tensor)的定义:
- https://www.zhihu.com/question/20695804/answer/64920043

- what is a tensor: https://www.youtube.com/watch?v=f5liqUk0ZTw
- 向量由component 和 basis vector组成,可以由各个basis vector的线性组合表示
- rank1 - one index, or one basis(indicator) vector per component
- 举例
- rank-two tensor in three-dimensional space

- 9个component / sets of 2 basis vectors
- 2个基向量分别表示某个平面的垂直向量以及该平面上的力的方向,因此3^2=9,有9种组合方式
- 9个component / sets of 2 basis vectors
- rank-three tensor in three-dimensional space

- 27个component/ sets of 3 basis vectors, 3^3=27
- tensor的好处:无论在何种坐标系下观测值都是相同的,因为不同的坐标系下basis vector进行变化,同时component为了保证Tensor不变而变化。
- 相当于把最基本的单位向量乘积计算出来
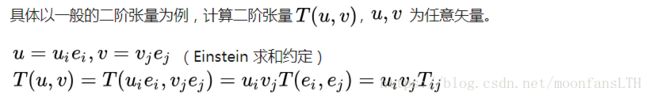
- 后向传播推导
- https://blog.csdn.net/qrlhl/article/details/50885527
- https://www.cnblogs.com/andywenzhi/p/7295262.html
- https://www.cnblogs.com/andywenzhi/p/7295262.html
#Chap7 正则化
- C7.1 参数范数惩罚:传统的对学习参数的正则化约束,比如岭回归
- C7.2 作为约束的范数惩罚:在损失函数中增加约束条件,比如KKT条件
- C7.3 正则化和欠约束问题
- C7.4 数据集增强:通过mock假数据来增加模型泛化能力,对象识别
- C7.5 噪声鲁棒性:向输入添加方差极小的噪声等价于对权重施加范数惩罚
- C7.6 半监督学习
- C7.7 多任务学习
- C7.8 提前终止
- 当训练有足够表示能力甚至会过拟合的模型时,训练误差会随着时间的推移逐渐降低,但验证集的误差再次上升。所以模型训练过程需要提前终止。合适的策略是在完成提前终止的首次训练之后,进行额外的训练。
- i. 第二轮训练使用第一轮提前终止训练确定的最佳步数
- ii. 保持第一轮训练获得的参数,然后使用全部数据继续训练
- 当训练有足够表示能力甚至会过拟合的模型时,训练误差会随着时间的推移逐渐降低,但验证集的误差再次上升。所以模型训练过程需要提前终止。合适的策略是在完成提前终止的首次训练之后,进行额外的训练。
- C7.9 参数绑定和参数共享:正则化一个模型的参数,使其接近另一个无监督模式下训练的模型的参数
- C7.10 稀疏表示
- C7.11 Bagging(bootstrap aggregating)是通过结合几个模型降低泛华误差的技术,分别训练几个不同的模型,然后让所有模型表决测试样例的输出。
- 奏效原因:不同的模型通常不会在测试集上产生完全相同的误差。
- 方法:构造k个不同的数据集,每个数据集从原始数据集中重复采样构成,和原始数据集具有相同数量的样例。(如果成员的误差是独立的,集成将显著地比其他成员表现更好)
- C7.12 Dropout:目标是在指数级数量的神经网络中近似bagging学习(定义k个不同模型,从训练集有放回采样构造k个不同的数据集,然后在训练集i上训练模型i)
- 通过随机行为训练网络并平均多个随机决定进行预测,实现了一种参数共享的bagging形式。(集成模型)
- 引入掩码向量,来定义输入层和隐藏层的单元使用。
- 与bagging的差异:bagging中所有模型是独立的,而dropout模型共享参数,其中每个模型继承父神经网络参数的不同子集。参数共享使得在有限可用的内存下表示指数级数量的模型变得可能。

- 知乎:
- https://zhuanlan.zhihu.com/p/23178423
- 整个dropout过程就相当于 对很多个不同的神经网络取平均。而不同的网络产生不同的过拟合,一些互为“反向”的拟合相互抵消就可以达到整体上减少过拟合。
- https://zhuanlan.zhihu.com/p/28443356
- 让神经元以超参数p的概率失活
- https://zhuanlan.zhihu.com/p/23178423
- C7.13 对抗训练:通过对抗训练减少原因独立同分布的测试集的错误率。
#Chap8 优化
- 参考凸优化中的内容,病态问题,BATCH,SGD
#C9 CNN
-
卷积定义:https://www.zhihu.com/question/22298352/answer/228543288
-
卷积在图像识别中的作用:图像平滑、滤波器、为了更好地区分图像,去掉噪点
-
激励函数作用:
- https://www.zhihu.com/question/22334626
- https://www.zhihu.com/question/22334626
-
神经网络是什么:
- https://www.zhihu.com/question/22553761
- 本质是学习如何利用矩阵的线性变换加激活函数的非线性变换,将原始输入空间投向线性可分/系数的空间去分类/回归。
- 增加节点数:增加维度,即增加线性转换能力。
- 增加层数:增加激活函数的次数,增加非线性转换次数。
-
五种变换:

-
常用的激活函数:max-pooling、sigmod、ReLU
-
反向传播算法:如果输出层发现输出与正确的类号不同,会让最后一层神经元进行参数调整,由此丢提,层层往回退着调整。经过调整的网络会在样本上继续测试,如果输出还是老分类错,继续回退调整,直至网络输出满意为止。
- 是一种求梯度的方法。
-
softmax:
- https://blog.csdn.net/u014380165/article/details/77284921
-
something fansy:
- http://playground.tensorflow.org/#activation=tanh&batchSize=10&dataset=xor®Dataset=reg-plane&learningRate=0.03®ularizationRate=0&noise=0&networkShape=4,2&seed=0.82765&showTestData=false&discretize=false&percTrainData=50&x=true&y=true&xTimesY=false&xSquared=false&ySquared=false&cosX=false&sinX=false&cosY=false&sinY=false&collectStats=false&problem=classification&initZero=false&hideText=false
-
CNN:
-
https://www.zhihu.com/question/39022858/answer/194996805
#Chap10 RNN
https://zhuanlan.zhihu.com/p/24720659
https://www.zhihu.com/question/57828011/answer/155275958