Redis安装及使用
Redis的安装及使用
-
- 一、Redis安装
-
- 1、Linux安装
- 2、Windows安装
- 二、Redis常见命令
-
- 1、string
- 2、list
- 3、hash
- 4、set
- 5、zset
- 三、Redis的高级使用
-
- 1、管道连接redis(一次发送多个命令)
- 2、发布订阅(pub/Sub)
- 3、事务(transactions)
- 4、布隆过滤器(RedisBloom)
- 四、Redis的持久化和内存管理
-
- 1、RDB(relation-ship database)持久化
- 2、AOF(append-only file)持久化
- 3、内存管理
- 五、Redis的集群模式
-
- 1、主从复制
- 2、哨兵
- 3、数据分区
Redis的诞生主要是为了解决关系型数据库在高并发场景下磁盘IO瓶颈,磁盘的寻址速度是毫秒(ms)级的,而内存的寻址速度是纳秒(ns)级的,内存的带宽也比磁盘带宽大好几个数量级。总体上来说,内存比磁盘寻址快了接近10万倍。于是便出现了基于内存的k-v数据库Redis。
一、Redis安装
1、Linux安装
在一个新搭建的linux系统上安装步骤,此处用的是CentOS release 6.5 (Final)
1 yum install wget
2 cd
3 mkdir soft
4 cd soft
5 wget http://download.redis.io/releases/redis-5.0.5.tar.gz
6 tar xf redis-5.0.5.tar.gz
7 cd redis-5.0.5
8 yum install gcc
9 make (结束后在src 生成了可执行程序)
10 make install PREFIX=/opt/bigdata/redis5 (此步骤是安装可执行命令到linux中,避免与解压目录混在一起)
11 vi /etc/profile(添加环境变量)
export PATH=$PATH:/opt/bigdata/redis5/bin
12 source /etc/profile(环境变量配置生效)
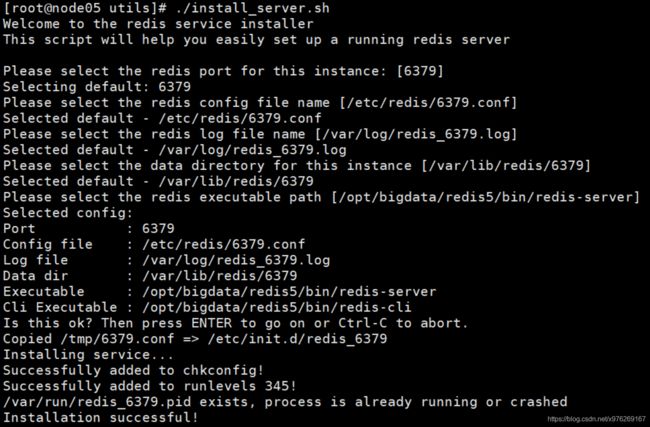
13 cd utils
14 ./install_server.sh(安装Redis服务,可以执行一次或多次)
a) 一个物理机中可以有多个Redis实例(进程),通过端口号区分,默认6379
b) 可执行程序就一份在目录,但是内存中未来的多个实例需要各自的配置文件,持久化目录等资源
c) Redis服务启动/停止/状态 service redis_6379 start/stop/stauts
2、Windows安装
下载服务:
1、https://github.com/microsoftarchive/redis
2、点击Tags,选中Releases
3、选择需要的版本下载
启动服务:
1.Windons启动Redis服务:
redis-server.exe redis.windows.conf
2.Windons客户端连接Redis服务:
redis-cli.exe -h 127.0.0.1 -p 6379
3.Windons安装Redis服务:
安装服务:
redis-server.exe --service-install redis.windows.conf --service-name redisserver1 --loglevel verbose
redis-server.exe --service-install redis.windows.conf --service-name redisserver2 --port 6380 --loglevel verbose
redis-server.exe --service-install redis.windows.conf --service-name redisserver3 --port 6381 --loglevel verbose
启动服务:
redis-server.exe --service-start --service-name redisserver1
redis-server.exe --service-start --service-name redisserver2
redis-server.exe --service-start --service-name redisserver3
停止服务:
redis-server.exe --service-stop --service-name redisserver1
redis-server.exe --service-stop --service-name redisserver2
redis-server.exe --service-stop --service-name redisserver3
卸载服务:
redis-server.exe --service-uninstall--service-name redisserver1
redis-server.exe --service-uninstall--service-name redisserver2
redis-server.exe --service-uninstall--service-name redisserver3
二、Redis常见命令
安装完成后,在linux启动服务端的命令为:redis-server --port 6379;启动客户端的命令为:redis-cli -p 6379。默认端口号是6379,端口号可以不写,但如果有多个Redis实例,就需要指定需要启动的服务端和客户端的端口号。
Redis的value有五种基本类型
1、string
- select db 选择数据库(0-20)
- set k v 设置一个数据
- set k1 v nx nx仅仅可以新建的时候进行插入数据
- set k2 v xx xx仅仅可以更新的时候进行更新数据
- mset k1 v1 k2 v2 可以进行设置多个值
- get k 返回一个v,没有返回nil
- mget k1 k2 k3 获取多个v
- getrange k start end 获取一个索引从start到end,双闭合的区间
- setrange k start value 更新区间范围,我们可以从start的索引开始,更新value数据
- del key 删除一条kv数据
- keys pattern 用正则查询key
- flushdb 清空db
- help @string 查询string相关帮助信息
- append k v 给k的数据进行追加v这个数据
- type k 查看value是什么类型
- object encoding k 查看v的数据类型
- incr k1 将integer的数据类型加一
- incrby k1 v 将integer数据类型加v
- decr k1 将integer的数据类型减一
- decrby k1 v 将integer数据类型减v
- incrbyfloat k1 v 将integer数据类型加一个浮点型
- 数据不够长的时候编码是embstr,之后会变为raw格式
- strlen k1 查看v的长度
- redis-cli --raw 进行进入,会识别编码(比如自动识别GBK)
- getset k1 v 更新新值,返回旧值
- bitpos key bit [start] [end] 查看从start到end的字节,第一次bit出现的位置
- bitcount key [start] [end] 查看start到end的时候,1出现的次数
- bitop and andkey k1 k2 执行k1 k2 按位与操作
- bitop or orkey k1 k2 按位或操作
2、list
- lpush、lpop、rpush、rpop 和栈一样
- lrange 0 -1 所有元素查看
- lindex key index 查看索引位置的值
- lrem key count value 移除count数量的value
- linsert key after afval value 在键后面插入值
- linsert key before befval value 在key前面插入值
- blpop 阻塞式取值(等待有值再取出)
- ltrim key [start] [end] 修剪,进行修剪队列
3、hash
- hset key filed value 设置一个key field的值
- hget key field 获得一个key field的值
- hmset key field value field value 设置多个field的值
- hmget key field fied 获取多个field的值
- hkeys key 查看所有的key
- hvals key 查看所有的field
- hincrby key field num 增加num值
4、set
- sadd key v1 v2 v3… 插入v1,v2,v3…
- smember key 列出所有的value
- srem v1 v2 删除v1,v2…
- sinter k1 k2 求交集并返回
- sinterstore dest k1 k2 交集结果存储dest
- sunion k1 k2 求并集返回
- sunionstore dest k1 k2 并集存储dest
- sdiff k1 k2 求差集并返回
- sdiffstore dest k1 k2 求差集存储dest
- srandmember k1 随机返回一个成员
- srandmember k1 num 随机返回num个元素,num为正数,取出一个去重结果集,如果为负数,那么取出不去重结果集
5、zset
- zadd k score mem score mem 插入数据后增加权重
- zrange k 0 -1 取出所有的值
- zrangebyscore k low high 取出从low到high区间的数据
- zrange k start end 从start到end之间的数据取出
- zscore k v 返回一个数据的分值
- zrange k 0 -1 withscores 携带分数取出
- zincrby k incrscore v 增加一个值的分值
- zunionstore k keynum k1 k2…[aggregate max] 多个key的并集[最大值]
三、Redis的高级使用
1、管道连接redis(一次发送多个命令)
a.安装nc
yum install nc -y
b.通过nc连接redis
nc localhost 6379
c.通过echo向nc发送指令
echo -e "set k2 99\n incr k2\n get k2" |nc localhost 6379
2、发布订阅(pub/Sub)
此功能需要先在一个客户端执行订阅命令,然后再另外一个客户端执行发布命令
subscribe channel
publish channel message


3、事务(transactions)
multi 开启事务
...
exec 执行事务
watch 如果数据被更改,那就不执行事务
unwatch 取消监视
discard 放弃事务

4、布隆过滤器(RedisBloom)
a. 在https://redis.io/modules选择RedisBloom
b. 点击图标小房子进入GitHub,右键点击Download ZIP选择复制链接地址
c. 在linux中使用wget命令获取压缩包
d. yum install unzip
e. unzip master.zip
f. cd RedisBloom-master
g. make
h. 将redisbloom.so 文件拷贝到安装目录下/opt/bigdata/redis5/
i. 重启服务:redis-server --loadmodule /opt/bigdata/redis5/redisbloom.so (注意:–loadmodule可用版本>= 4.0.0)
j. 使用
BF.ADD k1 V 添加数据值
BF.EXISTS k1 V 判断是否存在


四、Redis的持久化和内存管理
Redis中提供了两种方式可以持久化:RDB和AOF,两种方式可以同时开启,在版本4.0.0之前开启AOF只会用AOF来持久化;4.0.0之后AOF包含RDB的全量数据,追加新的写操作。
Redis可以通过命令save和bgsave来触发持久化的操作:


可以看出save是同步操作,执行会导致Redis服务在同步时间不可用,bgsave是异步操作,采用的是写时复制技术(Copy-On-Write, COW)。
AOF因为是追加的方式,当数据量很大时文件就会变大,Redis可以通过重写的方式来优化文件大小,也可以通过BGREWRITEAOF来手动执行重写操作。

redis.conf有重写的配置:
# Redis会记住上一次重写后的AOF文件的大小,和当前的AOF文件大小进行比较,如果当前的大于上一次达到此配置的百分比,则触发重写操作
auto-aof-rewrite-percentage 100
# AOF的文件大于此配置值才会触发重写操作
auto-aof-rewrite-min-size 64mb
1、RDB(relation-ship database)持久化
默认redis会以一个rdb快照的形式,将一段时间内的数据持久化到硬盘,保存成一个dump.rdb二进制文件。
工作原理:当redis需要持久化时,redis会fork一个子进程,子进程将数据写到磁盘上临时一个RDB文件中。当子进程完成写临时文件后,将原来的RDB替换掉,这样的好处就是可以copy-on-write写时复制。
配置redis.conf:
save 900 1
save 300 10
save 60 10000
在900秒内,如果有一个key被修改,则会发起快照保存。300秒之内,如果超过10个key被修改,则会发起快照保存。在60秒内,如果1w个key被修改,则会发起快照保存。
2、AOF(append-only file)持久化
默认会以一个appendonly.aof追加进硬盘。
redis.conf默认配置:
# 每次有数据修改都会写入AOF
appendfdync always
# 每秒同步一次,策略为AOF的缺省策略
appendfsync everysec
# Redis不执行AOF,让操作系统刷新缓存
appendfsync no
3、内存管理
Redis是内存中的数据结构存储系统,内存是有限的,随着访问变化,应该淘汰冷数据,配置如下:
# 设置一个内存的上限,当Redis内存达到上限就会触发淘汰策略,如果淘汰策略设置的是noeviction,那就会对所有写操
# 作返回错误,读操作可以正常访问
maxmemory
# 淘汰策略,有以下值可以设置
# noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个# 例外)
# allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
# volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
# allkeys-random: 回收随机的键使得新添加的数据有空间存放。
# volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
# volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
maxmemory-policy noeviction
五、Redis的集群模式
Redis在单实例部署时会有单点故障,容量有限,和访问压力的问题,针对单点故障的问题,Redis提供了主从复制模式和哨兵实现自动故障转移;针对容量的问题,Redis通过数据分区来解决。
1、主从复制
启动三个不同端口号的Redis服务端,然后对应这三个服务端再启动三个客户端,比如6379当做主节点,6380和6381作为从节点,可以在这两个节点客户端执行
REPLICAOF 127.0.0.1 6379
然后就可以在这两个从节点上验证数据是否一致。
注意:从节点在追随主节点的时候会先清空从节点的数据然后将主节点的数据同步到从节点
![]()
![]()
![]()
如果其中一台机器挂了,比如6381节点挂了,可以通过启动命令在启动时直接追随主节点同步数据
redis-server --port 6381 --replicaof 127.0.0.1 6379
如果是主节点挂了,可以通过手动将主节点挂机,然后通过如下命令把从节点变为主节点,再将其他从节点追随当前新的主节点
replicaof no one
配置中与主从复制相关配置如下:
# 当从节点失去与主节点的连接,从节点正常运行,是否提供服务,如是,则是从节点上的旧数据
replica-serve-stale-data yes
# 表示从节点是否设置为只读
replica-read-only yes
# 表示数据同步是使用磁盘IO同步还是网络IO同步
repl-diskless-sync no
2、哨兵
在上述主从复制过程中有节点挂掉了,就必须要通过手动重启的方式来恢复,Redis里提供了哨兵模式可以自动选择新的主节点,保证高可用。
在上述主从配置的基础上,新建三个配置文件,例如26379.conf,26380.conf,26381.conf,作为哨兵启动的配置文件,配置文件中分别写对应文件名的端口号和哨兵需要监控的机器端口号等,如下26379.conf所示
port 26379
sentinel monitor mymaster 127.0.0.1 6379 2
上述第二行分别表示:哨兵 监控 监控名 ip 端口 几票通过
然后通过如下命令启动三个哨兵
redis-server ./26379.conf --sentinel
验证:可以通过将主节点挂掉,然后哨兵收到主挂掉的消息后,三个哨兵选出一个哨兵的主节点,然后在由这个哨兵主节点去将一个从节点设置为新的主节点,这样就实现了高可用;在挂掉的主节点启动后,将会作为从节点追随新的主节点。
3、数据分区
分区是将数据分发到不同redis实例上的一个过程,每个redis实例只是你所有key的一个子集。
Redis分区主要有两个目的:
a. 分区可以让Redis管理更大的内存,Redis将可以使用所有机器的内存。如果没有分区,你最多只能使用一台机器的内存。
b. 分区使Redis的计算能力通过简单地增加计算机得到成倍提升,Redis的网络带宽也会随着计算机和网卡的增加而成倍增长。
分区可以在程序的不同层次实现。
客户端分区:在客户端就已经决定数据会被存储到哪个redis节点或者从哪个redis节点读取。
代理分区:意味着客户端将请求发送给代理,然后代理决定去哪个节点写数据或者读数据。代理根据分区规则决定请求哪些Redis实例,然后根据Redis的响应结果返回给客户端。redis和memcached的一种代理实现就是Twemproxy
查询路由:客户端随机地请求任意一个redis实例,然后由Redis将请求转发给正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,但并不是直接将请求从一个redis节点转发到另一个redis节点,而是在客户端的帮助下直接redirected到正确的redis节点。