第R2周:LSTM-火灾温度预测
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:第R2周:LSTM-火灾温度预测(训练营内部可读)
- 作者:K同学啊
任务说明:数据集中提供了火灾温度(Tem1)、一氧化碳浓度(CO 1)、烟雾浓度(Soot 1)随着时间变化数据,我们需要根据这些数据对未来某一时刻的火灾温度做出预测(本次任务仅供学习)
要求:
了解LSTM是什么,并使用其构建一个完整的程序
R2达到0.83
拔高:
使用第18个时刻的数据预测第910个时刻的温度数据
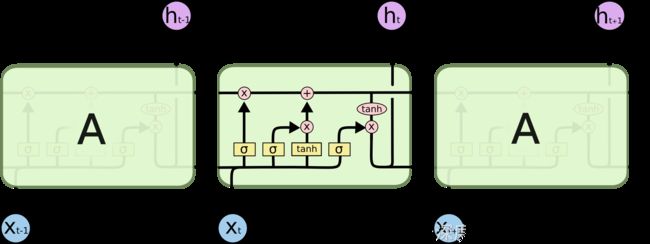
LSTM,全称为长短期记忆网络(Long Short Term Memory networks),是一种特殊的RNN,能够学习到长期依赖关系。LSTM由Hochreiter & Schmidhuber (1997)提出,许多研究者进行了一系列的工作对其改进并使之发扬光大。LSTM在许多问题上效果非常好,现在被广泛使用。
LSTM是为了避免长依赖问题而精心设计的。 记住较长的历史信息实际上是他们的默认行为,而不是他们努力学习的东西。
遗忘门: 控制上一时间步的记忆细胞;
输入门:控制当前时间步的输入;
输出门:控制从记忆细胞到隐藏状态;
记忆细胞:⼀种特殊的隐藏状态的信息的流动,表示的是长期记忆;
h 是隐藏状态,表示的是短期记忆;
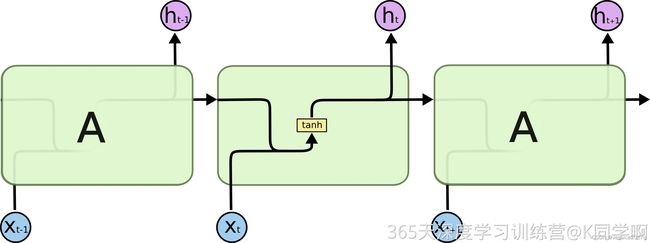
所有的循环神经网络都有着重复的神经网络模块形成链的形式。在普通的RNN中,重复模块结构非常简单,其结构如下:
LSTM避免了长期依赖的问题。可以记住长期信息!LSTM内部有较为复杂的结构。能通过门控状态来选择调整传输的信息,记住需要长时间记忆的信息,忘记不重要的信息,其结构如下:
前期准备工作
导入数据
import numpy as np
import pandas as pd
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader
data = pd.read_csv("/home/liangjie/test/Modelwhale/deep learning/R2/woodpine2.csv")
print(data.head(5))
print(data.columns)
Time Tem1 CO 1 Soot 1
0 0.000 25.0 0.0 0.0
1 0.228 25.0 0.0 0.0
2 0.456 25.0 0.0 0.0
3 0.685 25.0 0.0 0.0
4 0.913 25.0 0.0 0.0
Index(['Time', 'Tem1', 'CO 1', 'Soot 1'], dtype='object')
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['savefig.dpi'] = 500 #图片像素
plt.rcParams['figure.dpi'] = 500 #分辨率
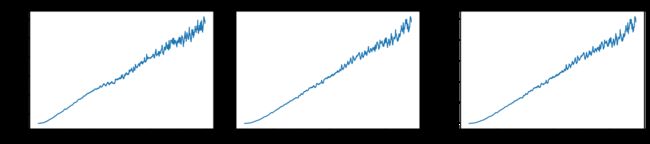
fig, ax =plt.subplots(1,3,constrained_layout=True, figsize=(14, 3))
sns.lineplot(data=data["Tem1"], ax=ax[0])
sns.lineplot(data=data["CO 1"], ax=ax[1])
sns.lineplot(data=data["Soot 1"], ax=ax[2])
plt.show()
构建数据集
dataFrame = data.iloc[:,1:]
dataFrame
| Tem1 | CO 1 | Soot 1 | |
|---|---|---|---|
| 0 | 25.0 | 0.000000 | 0.000000 |
| 1 | 25.0 | 0.000000 | 0.000000 |
| 2 | 25.0 | 0.000000 | 0.000000 |
| 3 | 25.0 | 0.000000 | 0.000000 |
| 4 | 25.0 | 0.000000 | 0.000000 |
| ... | ... | ... | ... |
| 5943 | 295.0 | 0.000077 | 0.000496 |
| 5944 | 294.0 | 0.000077 | 0.000494 |
| 5945 | 292.0 | 0.000077 | 0.000491 |
| 5946 | 291.0 | 0.000076 | 0.000489 |
| 5947 | 290.0 | 0.000076 | 0.000487 |
5948 rows × 3 columns
dataFrame = data.iloc[:,1:].copy()
## 归一化
from sklearn.preprocessing import MinMaxScaler
col=[ 'CO 1', 'Soot 1', 'Tem1']
#将数据归一化,范围是0到1
sc = MinMaxScaler(feature_range=(0, 1))
for i in col:
dataFrame[i] = sc.fit_transform(dataFrame[i].values.reshape(-1, 1))
print(dataFrame.shape)
###设置X、y
width_X = 8
width_y = 2
##取前8个时间段的Tem1、CO 1、Soot 1为X,第9个时间段的Tem1为y。
X = []
y = []
in_start = 0
for _, _ in data.iterrows():
in_end = in_start + width_X
out_end = in_end + width_y
if out_end < len(dataFrame):
X_ = np.array(dataFrame.iloc[in_start:in_end , ])
#X_ = X_.reshape((len(X_)*3))
y_ = np.array(dataFrame.iloc[in_end :out_end, 0])
X.append(X_)
y.append(y_)
in_start += 1
X = np.array(X)
y = np.array(y).reshape(-1,1,2)
X.shape, y.shape
(5948, 3)
((5938, 8, 3), (5938, 1, 2))
print(np.any(np.isnan(X)))
print(np.any(np.isnan(y)))
False
False
划分数据集
取5000之前的数据为训练集,5000之后的为验证集
X_train = torch.tensor(np.array(X[:5000]), dtype=torch.float32)
y_train = torch.tensor(np.array(y[:5000]), dtype=torch.float32)
X_test = torch.tensor(np.array(X[5000:]), dtype=torch.float32)
y_test = torch.tensor(np.array(y[5000:]), dtype=torch.float32)
X_train.shape
torch.Size([5000, 8, 3])
train_dl = DataLoader(TensorDataset(X_train, y_train),batch_size=64, shuffle=False)
test_dl = DataLoader(TensorDataset(X_test, y_test),batch_size=64, shuffle=False)
**LSTM **
LSTM接收数据形式为input_size=(batce_size,seq_length,input_size)此处input_size=out_channels,将维度交换有:
input_size=(batch_size,seq_length,out_channels)
LSTM输出结果维度形式为:
output=(batch_size, seq_len, num_directions * hidden_size)
全连接层的输入维度形式为:
fc=(hidden_size,output_size)
LSTM隐层状态h0, c0通常初始化为0,大部分情况下模型也能工作的很好。
LSTM的隐藏层初始状态h0, c0可以看做是模型的一部分参数,并在迭代中更新。
构建模型
class model_lstm(nn.Module):
def __init__(self):
super(model_lstm, self).__init__()
self.lstm0 = nn.LSTM(input_size=3 ,hidden_size=320, num_layers=1, batch_first=True)
self.lstm1 = nn.LSTM(input_size=320 ,hidden_size=320, num_layers=1, batch_first=True)
self.fc0 = nn.Sequential(nn.Linear(320, 300),nn.Dropout(0.3))
self.fc1 = nn.Sequential(nn.Linear(300, 2))
def forward(self, x):
#h_0 = torch.randn(1, x.size(0), 64) #num_layers * num_directions(单向/双向), bs,hidden_size
#c_0 = torch.randn(1, x.size(0), 64) #num_layers * num_directions(单向/双向), bs,hidden_size
#如果不传入h0和c0,pytorch会将其初始化为0
out, hidden1 = self.lstm0(x)
out, _ = self.lstm1(out, hidden1)
out = self.fc0(out)
out = self.fc1(out)
return out[:, -1:, :] #取2个预测值,否则经过lstm会得到8*2个预测
'''
def init_weight(model):
for m in model.modules():
if isinstance(m, nn.Linear):
torch.nn.init.uniform_(m.weight.data, a=0, b=1)
'''
model = model_lstm()
#model.apply(init_weight)
model
model_lstm(
(lstm0): LSTM(3, 320, batch_first=True)
(lstm1): LSTM(320, 320, batch_first=True)
(fc0): Sequential(
(0): Linear(in_features=320, out_features=300, bias=True)
(1): Dropout(p=0.3, inplace=False)
)
(fc1): Sequential(
(0): Linear(in_features=300, out_features=2, bias=True)
)
)
model(torch.rand(30,8,3)).shape
torch.Size([30, 1, 2])
模型训练
#设置GPU训练
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练循环
import copy
def train(train_dl, model, loss_fn, opt, lr_scheduler=None):
size = len(train_dl.dataset)
num_batches = len(train_dl)
train_loss = 0 # 初始化训练损失和正确率
for x, y in train_dl:
x, y = x.to(device), y.to(device)
# 计算预测误差
#pred = model(x)
pred = model(x) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距
# 反向传播
opt.zero_grad() # grad属性归零
loss.backward() # 反向传播
opt.step() # 每一步自动更新
# 记录loss
train_loss += loss.item()
if lr_scheduler is not None:
lr_scheduler.step()
print("learning rate = ", opt.param_groups[0]['lr'])
train_loss /= num_batches
return train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目
test_loss = 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for x, y in dataloader:
x, y = x.to(device), y.to(device)
# 计算loss
y_pred = model(x)
loss = loss_fn(y_pred, y)
test_loss += loss.item()
test_loss /= num_batches
return test_loss
#训练模型
model = model_lstm()
model = model.to(device)
loss_fn = nn.MSELoss() # 创建损失函数
learn_rate = 1e-1 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate,weight_decay=1e-4)
epochs = 150
train_loss = []
test_loss = []
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(opt,epochs, last_epoch=-1)
best_val =[0, 1e5]
for epoch in range(epochs):
model.train()
epoch_train_loss = train(train_dl, model, loss_fn, opt, lr_scheduler)
model.eval()
epoch_test_loss = test(test_dl, model, loss_fn)
if best_val[1] > epoch_test_loss:
best_val =[epoch, epoch_test_loss]
best_model_wst = copy.deepcopy(model.state_dict())
train_loss.append(epoch_train_loss)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_loss:{:.6f}, Test_loss:{:.6f}')
print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))
print("*"*20, 'Done', "*"*20)
print("best_train= ", best_train)
learning rate = 0.09998903417374227
Epoch: 1, Train_loss:0.002651, Test_loss:0.013934
learning rate = 0.09995614150494292
Epoch: 2, Train_loss:0.018316, Test_loss:0.013849
learning rate = 0.09990133642141358
Epoch: 3, Train_loss:0.018440, Test_loss:0.014263
learning rate = 0.09982464296247522
Epoch: 4, Train_loss:0.018521, Test_loss:0.013097
learning rate = 0.09972609476841367
Epoch: 5, Train_loss:0.018815, Test_loss:0.013766
learning rate = 0.0996057350657239
Epoch: 6, Train_loss:0.018648, Test_loss:0.013062
learning rate = 0.09946361664814941
Epoch: 7, Train_loss:0.018662, Test_loss:0.012700
learning rate = 0.09929980185352524
Epoch: 8, Train_loss:0.018499, Test_loss:0.013685
learning rate = 0.09911436253643444
Epoch: 9, Train_loss:0.017969, Test_loss:0.013154
learning rate = 0.09890738003669028
Epoch:10, Train_loss:0.017617, Test_loss:0.012327
learning rate = 0.098678945143658
Epoch:11, Train_loss:0.017123, Test_loss:0.011213
learning rate = 0.09842915805643156
Epoch:12, Train_loss:0.016491, Test_loss:0.010574
learning rate = 0.09815812833988291
Epoch:13, Train_loss:0.015514, Test_loss:0.009402
learning rate = 0.09786597487660335
Epoch:14, Train_loss:0.014383, Test_loss:0.009780
learning rate = 0.09755282581475769
Epoch:15, Train_loss:0.012726, Test_loss:0.008239
learning rate = 0.09721881851187407
Epoch:16, Train_loss:0.011186, Test_loss:0.006732
learning rate = 0.0968640994745946
Epoch:17, Train_loss:0.009464, Test_loss:0.006170
learning rate = 0.09648882429441258
Epoch:18, Train_loss:0.007577, Test_loss:0.005027
learning rate = 0.09609315757942503
Epoch:19, Train_loss:0.005857, Test_loss:0.005275
learning rate = 0.09567727288213004
Epoch:20, Train_loss:0.004294, Test_loss:0.004527
learning rate = 0.09524135262330098
Epoch:21, Train_loss:0.003098, Test_loss:0.003165
learning rate = 0.09478558801197065
Epoch:22, Train_loss:0.002284, Test_loss:0.002791
learning rate = 0.09431017896156073
Epoch:23, Train_loss:0.001704, Test_loss:0.002221
learning rate = 0.09381533400219318
Epoch:24, Train_loss:0.001219, Test_loss:0.001447
learning rate = 0.09330127018922194
Epoch:25, Train_loss:0.000971, Test_loss:0.001021
learning rate = 0.09276821300802535
Epoch:26, Train_loss:0.000768, Test_loss:0.001615
learning rate = 0.09221639627510077
Epoch:27, Train_loss:0.000617, Test_loss:0.000731
learning rate = 0.09164606203550499
Epoch:28, Train_loss:0.000597, Test_loss:0.000991
learning rate = 0.09105746045668521
Epoch:29, Train_loss:0.000522, Test_loss:0.000714
learning rate = 0.09045084971874738
Epoch:30, Train_loss:0.000494, Test_loss:0.000739
learning rate = 0.08982649590120982
Epoch:31, Train_loss:0.000458, Test_loss:0.001369
learning rate = 0.089184672866292
Epoch:32, Train_loss:0.000435, Test_loss:0.000741
learning rate = 0.08852566213878947
Epoch:33, Train_loss:0.000448, Test_loss:0.000841
learning rate = 0.08784975278258783
Epoch:34, Train_loss:0.000445, Test_loss:0.001881
learning rate = 0.08715724127386973
Epoch:35, Train_loss:0.000409, Test_loss:0.000737
learning rate = 0.08644843137107058
Epoch:36, Train_loss:0.000430, Test_loss:0.001089
learning rate = 0.08572363398164018
Epoch:37, Train_loss:0.000428, Test_loss:0.001132
learning rate = 0.0849831670256683
Epoch:38, Train_loss:0.000397, Test_loss:0.000723
learning rate = 0.08422735529643445
Epoch:39, Train_loss:0.000417, Test_loss:0.000818
learning rate = 0.08345653031794292
Epoch:40, Train_loss:0.000394, Test_loss:0.001651
learning rate = 0.0826710301995053
Epoch:41, Train_loss:0.000423, Test_loss:0.001463
learning rate = 0.0818711994874345
Epoch:42, Train_loss:0.000396, Test_loss:0.001506
learning rate = 0.08105738901391554
Epoch:43, Train_loss:0.000383, Test_loss:0.000920
learning rate = 0.08022995574311877
Epoch:44, Train_loss:0.000400, Test_loss:0.000767
learning rate = 0.07938926261462367
Epoch:45, Train_loss:0.000386, Test_loss:0.000652
learning rate = 0.07853567838422161
Epoch:46, Train_loss:0.000418, Test_loss:0.001014
learning rate = 0.07766957746216722
Epoch:47, Train_loss:0.000358, Test_loss:0.000761
learning rate = 0.07679133974894985
Epoch:48, Train_loss:0.000381, Test_loss:0.000865
learning rate = 0.07590135046865654
Epoch:49, Train_loss:0.000367, Test_loss:0.001179
learning rate = 0.07500000000000002
Epoch:50, Train_loss:0.000363, Test_loss:0.000680
learning rate = 0.07408768370508578
Epoch:51, Train_loss:0.000375, Test_loss:0.000659
learning rate = 0.07316480175599312
Epoch:52, Train_loss:0.000369, Test_loss:0.000745
learning rate = 0.0722317589592464
Epoch:53, Train_loss:0.000352, Test_loss:0.000549
learning rate = 0.07128896457825366
Epoch:54, Train_loss:0.000345, Test_loss:0.000744
learning rate = 0.07033683215379004
Epoch:55, Train_loss:0.000361, Test_loss:0.000859
learning rate = 0.06937577932260518
Epoch:56, Train_loss:0.000352, Test_loss:0.000698
learning rate = 0.06840622763423394
Epoch:57, Train_loss:0.000339, Test_loss:0.000626
learning rate = 0.0674286023660908
Epoch:58, Train_loss:0.000364, Test_loss:0.000868
learning rate = 0.0664433323369292
Epoch:59, Train_loss:0.000335, Test_loss:0.000752
learning rate = 0.06545084971874741
Epoch:60, Train_loss:0.000333, Test_loss:0.000667
learning rate = 0.06445158984722361
Epoch:61, Train_loss:0.000347, Test_loss:0.000731
learning rate = 0.06344599103076332
Epoch:62, Train_loss:0.000345, Test_loss:0.000656
learning rate = 0.06243449435824276
Epoch:63, Train_loss:0.000355, Test_loss:0.000781
learning rate = 0.06141754350553282
Epoch:64, Train_loss:0.000337, Test_loss:0.000640
learning rate = 0.060395584540888
Epoch:65, Train_loss:0.000332, Test_loss:0.000883
learning rate = 0.05936906572928627
Epoch:66, Train_loss:0.000340, Test_loss:0.000760
learning rate = 0.05833843733580514
Epoch:67, Train_loss:0.000335, Test_loss:0.000650
learning rate = 0.05730415142812061
Epoch:68, Train_loss:0.000347, Test_loss:0.000714
learning rate = 0.056266661678215237
Epoch:69, Train_loss:0.000330, Test_loss:0.000876
learning rate = 0.055226423163382714
Epoch:70, Train_loss:0.000320, Test_loss:0.000640
learning rate = 0.0541838921666158
Epoch:71, Train_loss:0.000339, Test_loss:0.000775
learning rate = 0.0531395259764657
Epoch:72, Train_loss:0.000321, Test_loss:0.000574
learning rate = 0.05209378268646001
Epoch:73, Train_loss:0.000326, Test_loss:0.000653
learning rate = 0.051047120994167874
Epoch:74, Train_loss:0.000336, Test_loss:0.000861
learning rate = 0.050000000000000024
Epoch:75, Train_loss:0.000345, Test_loss:0.000746
learning rate = 0.048952879005832194
Epoch:76, Train_loss:0.000330, Test_loss:0.000679
learning rate = 0.04790621731354004
Epoch:77, Train_loss:0.000330, Test_loss:0.000658
learning rate = 0.04686047402353437
Epoch:78, Train_loss:0.000333, Test_loss:0.000732
learning rate = 0.045816107833384245
Epoch:79, Train_loss:0.000320, Test_loss:0.000756
learning rate = 0.044773576836617354
Epoch:80, Train_loss:0.000331, Test_loss:0.000595
learning rate = 0.04373333832178481
Epoch:81, Train_loss:0.000328, Test_loss:0.000588
learning rate = 0.042695848571879455
Epoch:82, Train_loss:0.000335, Test_loss:0.000728
learning rate = 0.0416615626641949
Epoch:83, Train_loss:0.000331, Test_loss:0.000810
learning rate = 0.040630934270713785
Epoch:84, Train_loss:0.000313, Test_loss:0.000684
learning rate = 0.039604415459112044
Epoch:85, Train_loss:0.000329, Test_loss:0.000693
learning rate = 0.03858245649446723
Epoch:86, Train_loss:0.000330, Test_loss:0.000693
learning rate = 0.03756550564175728
Epoch:87, Train_loss:0.000317, Test_loss:0.000625
learning rate = 0.03655400896923674
Epoch:88, Train_loss:0.000331, Test_loss:0.000669
learning rate = 0.03554841015277642
Epoch:89, Train_loss:0.000320, Test_loss:0.000706
learning rate = 0.03454915028125264
Epoch:90, Train_loss:0.000323, Test_loss:0.000584
learning rate = 0.03355666766307085
Epoch:91, Train_loss:0.000332, Test_loss:0.000650
learning rate = 0.03257139763390926
Epoch:92, Train_loss:0.000324, Test_loss:0.000661
learning rate = 0.031593772365766125
Epoch:93, Train_loss:0.000326, Test_loss:0.000694
learning rate = 0.030624220677394863
Epoch:94, Train_loss:0.000320, Test_loss:0.000634
learning rate = 0.02966316784621
Epoch:95, Train_loss:0.000330, Test_loss:0.000740
learning rate = 0.02871103542174638
Epoch:96, Train_loss:0.000335, Test_loss:0.000679
learning rate = 0.02776824104075365
Epoch:97, Train_loss:0.000327, Test_loss:0.000597
learning rate = 0.026835198244006937
Epoch:98, Train_loss:0.000344, Test_loss:0.000589
learning rate = 0.02591231629491424
Epoch:99, Train_loss:0.000333, Test_loss:0.000650
learning rate = 0.024999999999999998
Epoch:100, Train_loss:0.000326, Test_loss:0.000579
learning rate = 0.024098649531343507
Epoch:101, Train_loss:0.000320, Test_loss:0.000605
learning rate = 0.023208660251050187
Epoch:102, Train_loss:0.000321, Test_loss:0.000622
learning rate = 0.02233042253783281
Epoch:103, Train_loss:0.000330, Test_loss:0.000603
learning rate = 0.021464321615778426
Epoch:104, Train_loss:0.000352, Test_loss:0.000745
learning rate = 0.020610737385376356
Epoch:105, Train_loss:0.000332, Test_loss:0.000631
learning rate = 0.019770044256881267
Epoch:106, Train_loss:0.000321, Test_loss:0.000634
learning rate = 0.018942610986084494
Epoch:107, Train_loss:0.000335, Test_loss:0.000641
learning rate = 0.018128800512565522
Epoch:108, Train_loss:0.000318, Test_loss:0.000580
learning rate = 0.01732896980049475
Epoch:109, Train_loss:0.000342, Test_loss:0.000665
learning rate = 0.016543469682057093
Epoch:110, Train_loss:0.000338, Test_loss:0.000632
learning rate = 0.01577264470356557
Epoch:111, Train_loss:0.000346, Test_loss:0.000712
learning rate = 0.015016832974331729
Epoch:112, Train_loss:0.000341, Test_loss:0.000644
learning rate = 0.014276366018359849
Epoch:113, Train_loss:0.000352, Test_loss:0.000680
learning rate = 0.01355156862892944
Epoch:114, Train_loss:0.000335, Test_loss:0.000632
learning rate = 0.012842758726130289
Epoch:115, Train_loss:0.000348, Test_loss:0.000663
learning rate = 0.012150247217412192
Epoch:116, Train_loss:0.000353, Test_loss:0.000648
learning rate = 0.011474337861210548
Epoch:117, Train_loss:0.000348, Test_loss:0.000659
learning rate = 0.010815327133708018
Epoch:118, Train_loss:0.000355, Test_loss:0.000656
learning rate = 0.010173504098790191
Epoch:119, Train_loss:0.000341, Test_loss:0.000666
learning rate = 0.009549150281252637
Epoch:120, Train_loss:0.000339, Test_loss:0.000663
learning rate = 0.0089425395433148
Epoch:121, Train_loss:0.000343, Test_loss:0.000694
learning rate = 0.008353937964495031
Epoch:122, Train_loss:0.000341, Test_loss:0.000687
learning rate = 0.007783603724899249
Epoch:123, Train_loss:0.000354, Test_loss:0.000680
learning rate = 0.007231786991974673
Epoch:124, Train_loss:0.000356, Test_loss:0.000709
learning rate = 0.006698729810778078
Epoch:125, Train_loss:0.000346, Test_loss:0.000701
learning rate = 0.006184665997806823
Epoch:126, Train_loss:0.000359, Test_loss:0.000688
learning rate = 0.005689821038439265
Epoch:127, Train_loss:0.000339, Test_loss:0.000691
learning rate = 0.005214411988029368
Epoch:128, Train_loss:0.000349, Test_loss:0.000708
learning rate = 0.0047586473766990335
Epoch:129, Train_loss:0.000356, Test_loss:0.000694
learning rate = 0.004322727117869964
Epoch:130, Train_loss:0.000351, Test_loss:0.000720
learning rate = 0.00390684242057497
Epoch:131, Train_loss:0.000346, Test_loss:0.000707
learning rate = 0.0035111757055874336
Epoch:132, Train_loss:0.000368, Test_loss:0.000705
learning rate = 0.003135900525405428
Epoch:133, Train_loss:0.000369, Test_loss:0.000693
learning rate = 0.002781181488125951
Epoch:134, Train_loss:0.000361, Test_loss:0.000710
learning rate = 0.002447174185242324
Epoch:135, Train_loss:0.000355, Test_loss:0.000701
learning rate = 0.0021340251233966383
Epoch:136, Train_loss:0.000347, Test_loss:0.000712
learning rate = 0.001841871660117095
Epoch:137, Train_loss:0.000351, Test_loss:0.000707
learning rate = 0.0015708419435684464
Epoch:138, Train_loss:0.000373, Test_loss:0.000712
learning rate = 0.0013210548563419857
Epoch:139, Train_loss:0.000361, Test_loss:0.000720
learning rate = 0.0010926199633097212
Epoch:140, Train_loss:0.000351, Test_loss:0.000711
learning rate = 0.0008856374635655696
Epoch:141, Train_loss:0.000360, Test_loss:0.000720
learning rate = 0.0007001981464747509
Epoch:142, Train_loss:0.000358, Test_loss:0.000720
learning rate = 0.0005363833518505835
Epoch:143, Train_loss:0.000370, Test_loss:0.000719
learning rate = 0.0003942649342761118
Epoch:144, Train_loss:0.000363, Test_loss:0.000715
learning rate = 0.0002739052315863355
Epoch:145, Train_loss:0.000367, Test_loss:0.000712
learning rate = 0.0001753570375247815
Epoch:146, Train_loss:0.000369, Test_loss:0.000713
learning rate = 9.866357858642206e-05
Epoch:147, Train_loss:0.000342, Test_loss:0.000714
learning rate = 4.3858495057080846e-05
Epoch:148, Train_loss:0.000361, Test_loss:0.000713
learning rate = 1.0965826257725021e-05
Epoch:149, Train_loss:0.000350, Test_loss:0.000713
learning rate = 0.0
Epoch:150, Train_loss:0.000368, Test_loss:0.000713
******************** Done ********************
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Input In [18], in | ()
26 print(template.format(epoch+1, epoch_train_loss, epoch_test_loss))
27 print("*"*20, 'Done', "*"*20)
---> 28 print("best_train= ", best_train)
NameError: name 'best_train' is not defined
| 评估
loss图
#LOSS图
# 支持中文
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
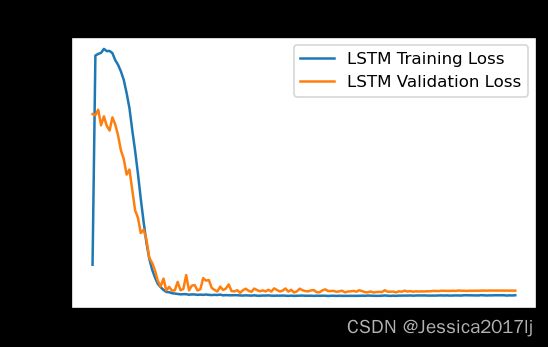
plt.figure(figsize=(5, 3),dpi=120)
plt.plot(train_loss , label='LSTM Training Loss')
plt.plot(test_loss, label='LSTM Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: SimHei
findfont: Font family ['sans-serif'] not found. Falling back to DejaVu Sans.
findfont: Generic family 'sans-serif' not found because none of the following families were found: SimHei
调用模型进行预测
model.load_state_dict(best_model_wst)
model.to("cpu")
predicted_y_lstm = sc.inverse_transform(model(X_test).detach().numpy().reshape(-1,1)) # 测试集输入模型进行预测
y_test_1 = sc.inverse_transform(y_test.reshape(-1,1))
y_test_one = [i[0] for i in y_test_1]
predicted_y_lstm_one = [i[0] for i in predicted_y_lstm]
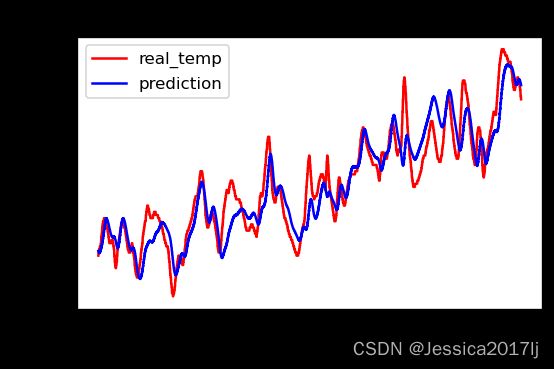
plt.figure(figsize=(5, 3),dpi=120)
# 画出真实数据和预测数据的对比曲线
plt.plot(y_test_one[:2000], color='red', label='real_temp')
plt.plot(predicted_y_lstm_one[:2000], color='blue', label='prediction')
plt.title('Title')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
from sklearn import metrics
"""
RMSE :均方根误差 -----> 对均方误差开方
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
"""
RMSE_lstm = metrics.mean_squared_error(predicted_y_lstm_one, y_test_1)**0.5
R2_lstm = metrics.r2_score(predicted_y_lstm_one, y_test_1)
print('均方根误差: %.5f' % RMSE_lstm)
print('R2: %.5f' % R2_lstm)
均方根误差: 6.65325
R2: 0.83887
test_1 = torch.tensor(dataFrame.iloc[:8 , ].values,dtype = torch.float32).reshape(1,-1,3)
pred_ = model(test_1)
pred_ = np.round(sc.inverse_transform(pred_.detach().numpy().reshape(1,-1)).reshape(-1),2)
real_tem = data.Tem1.iloc[:2].values
print(f"第9~10时刻的温度预测:", pred_)
print("第9~10时刻的真实温度:", real_tem)
第9~10时刻的温度预测: [36.34 36.51]
第9~10时刻的真实温度: [25. 25.]