百度App Android启动性能优化-工具篇

一、前言
启动性能是APP的极为重要的一环,启动阶段出现卡顿、黑屏问题,会影响用户体验,导致用户流失。百度APP在一些比较低端的机器上也有类似启动性能问题,为保留存,需要对启动流程做深入优化。现有的性能工具,无法高效的发现、定位性能问题,归因分析和防劣化成本很高,需要对现有工具进行二次开发,提升效率。
丨1.1 工具选型
做好性能优化,不仅需要趁手的工具,而且对工具的要求还很高,具体来说,必需满足要求:
-
高性能,保证自身高性能,以防带偏优化方向
-
多维度,能监控多维度信息,帮助全面发现问题
-
易用性,方便的可视化界面,方便分析
目前业界主流的APP性能探测工具有TraceView、CPU Profiler、Systrace、Perfetto。
| 性能损耗 | 监控维度 | 易用性 | 缺陷 | |
| TraceView | 性能损耗大,支持Trace采集模式,MethodTracing和Sampling,MethodTracing模式需要禁掉JIT,记录所有方法调用,性能损耗大;Sampling模式通过堆栈采样,需要挂起线程,也存在性能能问题,而且耗时计算不够精准,和采样频率相关 | 支持采集所有Java/kotlin方法耗时 | 火焰图分析 | 性能差 |
| CPU Profiler | 性能损耗较大,TraceView的替代工具,同样支持MethodTracing和Sampling模式,存在类似的性能损耗大的问题 | 支持采集所有Java/kotlin方法耗 时; 支持采集C/C++方法的耗时; | 火焰图分析 | 性能差 |
| Systrace | 性能损耗小,Android 4.0默认集成性能工具,基于Android系统层的atrace实现,atrace能力最终是通过Linux内核的性能工具ftrace实现;采样监控,Android系统在Framework层关键点加了Trace收集代码,APP需手动添加Trace收集;内核支持和部分方法采样收集,性能损耗低 | 支持采集Framework关键点耗时; APP耗时需手动添加; 支持采集锁等待、binder调用和IO等信息; 支持ftrace数据源,包括CPU调度信息和系统调用等内核相关信息; | 火焰图分析 | APP耗时监控需要手动添加采样代码,耗时耗力 |
| Perfetto | 性能损耗小,Android 9.0全新的性能工具套件,Systrace的升级版,实现类似,同样性能损耗较低 | 支持Systrace所有监控维度; 支持内存和电量信息监控; | 火焰图分 析 支持写SQL分析 | 同Systrace |
Perfetto提供了强大的Trace分析模块:Trace Processor,可以把多种类型的日志文件(Android systrace、Perfetto、linux ftrace)通过解析、提取其中的数据,结构化为SQLite数据库,并且提供基于SQL查询的Python API,可通过python实现自动化分析;同时有良好的可视化页面,可通过可视化页面查看火焰图和写SQL进行Trace分析。
从性能、监控维度的丰富程度和提供的配套的分析和可视化工具来选择,Perfetto是最好的选择,但前期由于Perfetto是9.0以后默认内置服务但是默认不可用,Android 11服务才默认可用,对低版本系统支持不够,所以我们选择了Systrace+Perfetto工具结合,可覆盖所有Android系统。随着Perfetto持续迭代,增加了对低版本Android系统支持,百度APP也全面切换到了Perfetto为基础采集和分析性能工具。
丨1.2 二次开发
Trace采集
Perfetto收集App的Trace是通过Android系统的atrace收集,需要自己手动添加Trace收集代码,添加Trace采集方式如下:
-
Java/Kotlin:提供了android.os.Trace类,通过在方法开始和结束点成对添加Trace.beginSection和Trace.endSection;
-
NDK:通过引入
,通过ATrace_beginSection() / Atrace_endSection()添加Trace; -
Android系统进程:提供了ATRACE_*宏添加Trace,定义在libcutils/trace.h;
在Android Framework和虚拟机内部会默认添加一些关键Trace,APP层需要手动添加,监控APP启动流程,有海量的方法,手动添加耗时耗力。百度APP大部分逻辑都是Java/Kotlin编写,Java/Kotlin代码会编译成字节码,在编译期间,可通过gradle transform修改字节码,我们需要开发一套自动插桩的gradle插件,在编译时自动添加APP层Trace收集代码,实现监控APP层所有方法。
防劣化
随着优化持续上线,对性能指标会有一定的正向收益,但是随着版本持续迭代,会有各种劣化问题,为保住优化成果,我们在线下每个版本发布之前都需要做真机启动性能测试,测试流程:

打包:需要打出自动插桩的包,需要一个基准包(上次发布版本的release分支的插桩包)和一个测试包(master分支的插桩包),用来做真机测试。
真机测试:用基准包和测试包手动跑启动相关case,启动Perfetto Trace抓取脚本,抓取Trace日志,会输出基准包Trace日志和测试包Trace日志,用作对比分析。
对比分析:Trace日志通过https://ui.perfetto.dev/ 打开可生成的火焰图,通过火焰图进行对比分析,找到存在的劣化问题,这个流程是最耗时的,需要对比分析的调用栈非常繁杂。
分发问题:梳理相关劣化问题,分发跟进对应业务负责同学。
这一整套流程完成,需要2人天,而对比分析工作量最大,需要实现自动化分析Trace日志功能,自动发现新增耗时、耗时劣化、锁等待等问题。
Perfetto提供了强大的Trace分析模块:Trace Processor,把多种类型的日志文件(Android systrace、Perfetto、linux ftrace)通过解析、提取其中的数据,结构化为SQLite数据库,并且提供基于SQL查询的python API,可通过python实现自动化分析。
为提高效率,需基于Trace Processor的python API,开发一套Trace自动分析工具集,实现快速高效分析版本启动劣化问题。
二、Perfetto介绍
百度APP启动性能优化工具是基于Perfetto二次开发,下面对Perfetto的架构和原理做相应的介绍。
丨2.1 整体介绍
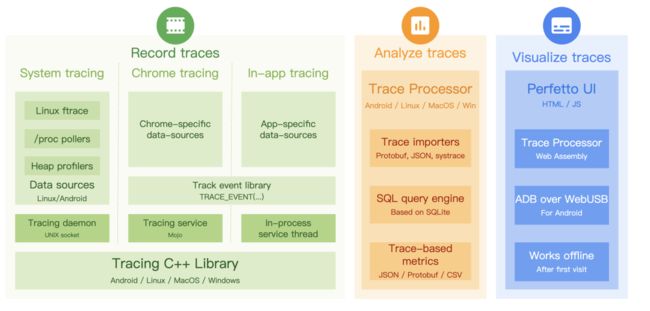
△Perfetto整体介绍
Perfetto是Google开源的一套性能检测和分析框架。按照功能可分成3大块,Record traces(采集)、Analyze traces(分析)、Visualize traces(可视化)。
Record traces
Trace采集能力,支持采集多种类型的数据源,支持内核空间和用户空间数据源。
内核空间数据源是Perfetto内置的,需要系统权限,主要的数据源包括:
-
Linux ftrace:支持收集内核事件,如cpu调度事件和系统调用等;
-
/proc和/sys pollers:支持采样进程或者系统维度cpu和内存状态;
-
heap profilers:支持采集java和native内存信息;
用户空间数据采集,Perfetto 提供了统一的Tracing C++库,支持用户空间数据性能数据收集,也可用atrace在用户层添加Trace收集代码采集用户空间Trace。
Analyze traces
Trace分析能力,提供Trace Processor模块可以把支持的Trace文件解析成一个内存数据库,数据库实现基于SQLite,提供SQL查询功能,同时提供了python API,百度APP也是基于Trace Processor开发了一套Trace自动化分析工具集。
Visualize traces
Perfetto还提供了一个全新的Trace可视化工具,工具是一个网站:https://ui.perfetto.dev/ 。在可视化工具中可导入Trace文件,并且可使用Trace Processor和SQLite的查询和分析能力。
丨2.2 Perfetto采集
采集指令
./record_android_trace -c atrace.cfg -n -o trace.html
**record_android_trace:**Perfetto提供的Trace采集帮助脚本,对低版本Trace采集做了兼容,Android 9以上会通过adb调用默认内置Perfetto执行文件,Android 9以下会根据不同的CPU架构下载外置的Perfetto可执行文件,把可执行文件push到 /data/local/tmp/tracebox,最后通过adb指令启动Perfetto Trace采集,通过这个脚本能够支持所有机型的Trace采集。
-c path:指定trace config配置文件,配置Trace采集时长、buffer_size、buffer policy、data source配置等;
-o path:指定Trace文件输出路径。
Trace config
Trace config配置当次采集的一些核心配置,采集时长、trace buffer size、buffer policy和data source配置等;
示例:
buffers: {
size_kb: 522240
fill_policy: DISCARD
}
data_sources: {
config {
name: "linux.ftrace"
ftrace_config {
ftrace_events: "sched/sched_switch"
atrace_categories: "dalvik"
atrace_categories: "view"
atrace_apps: "com.xx.xx"
}
}
}
duration_ms: 30000
buffers:设置当次采集的内存trace buffer配置,size_kb,配置当次 trace buffer大小,单位kb;fill_policy,配置trace buffer的策略,RING_BUFFER,trace buffer满了后,新的内容会把最老的内容覆盖,DISCARD,trace buffer满了以后,新的trace会直接丢弃。
duration_ms:trace采集时长,单位ms,到达指定时长后,会停止收集Trace。
data_sources:name,当前data source名称,如linux.ftrace表示ftrace的配置;ftrace_config,ftrace的配置;ftrace_events,配置需要抓取的ftrace事件,内核空间trace;atrace_categories,配置需要收集的atrace category,用户空间Trace;atrace_apps,配置需要采集trace的应用进程包名。
原理简介
启动性能重点关注方法耗时,Perfetto采集方法耗时trace依赖atrace和ftrace实现。相关实现如下:
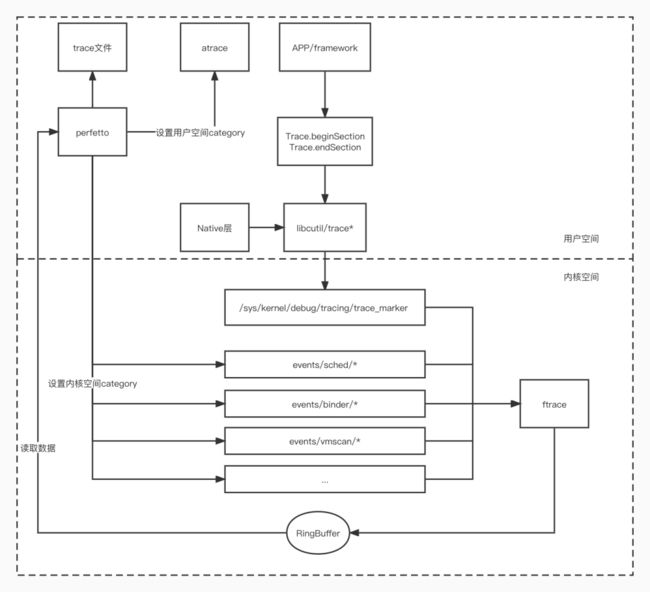
△Perfetto采集Trace原理
Perfetto通过atrace设置用户空间category(数据类型),包括APP自定义 Trace 事件、系统view Trace、系统层 gfx 渲染相关 Trace等,其最终都是通过调用 Android SDK 提供 Trace.beginSection 或者 ATrace宏记录到同一个文件 /sys/kernel/debug/tracing/trace_marker 中,ftrace 会记录该写入操作时间戳。其中Android Framework里面一些重要的模块都加了Trace收集,用户APP代码需要手动加入;
内核空间数据主要一些和系统内核相关数据,如sched(CPU调度信息)、binder(binder驱动)、freq(CPU频率)等信息,Perfetto通过控制一些文件节点实现打开和关闭;
最终两种类型数据会写入ftrace RingBuffer中,Perfetto通过读取ftrace RingBuffer数据,实现Trace收集。
ftrace
ftrace是trace采集的核心实现,ftrace其实也是Perfetto的支持的一个data source,通过ftrace可实现收集用户空间和系统空间trace数据。
ftrace是linux系统内核的trace工具,其中RingBuffer是ftrace的基础,所有的trace原始数据都是通过RingBuffer记录的;
ftrace使用tracefs file system用来控制ftrace的配置和Trace日志输出,ftrace目录:/sys/kernel/debug/tracing(内核4.1之前) 或者 /sys/kernel/tracing(内核4.1之后)。
部分文件说明:
| 文件 | 描述 |
| tracing_on | 设置是否写入trace到ringbuffer,写入0表示disable,写入1表示enable,注意:这个disable仅仅是不写入ringbuffer。 |
| events/* | events目录包含很多ftrace支持采集的内核数据类型,也同通过写入文件节点启停事件收集,如开启cpu调度trace收集,可通过写入events/sched/enable文件节点,写入0表示disable,写入1表示enable |
| buffer_size_kb | 设置每个cpu的ringbuffer的size,单位是KB |
| trace | 这个文件输出可读格式的Trace文件,所有的Ftrace ringbuffer数据,不是一个消费者,读完ringbuffer数据,不会清空ringbuffer |
| trace_pipe | 和trace文件一样,但是是个消费者,读完数据会清空读取的ringbuffer |
| trace_marker | 将用户空间与内核中发生的事件同步,往这个文件写入字符串,会写入ftrace buffer |
| per_cpu | 目录里包含每个cpu的trace信息 |
| per_cpu/cpu0/buffer_size_kb | 设置当前cpu的ringbuffer的size,单位KB |
| per_cpu/cpu0/trace | 和根目录trace类似,但是这个trace只是当前cpu的ringbuffer数据 |
| per_cpu/cpu0/trace_pipe | 和根目录trace_pip类似,但是这个trace只是当前cpu的ringbuffer数据 |
| per_cpu/cpu0/trace_pipe_raw | 和per_cpu/cpu0/trace_pipe类似,只是数据格式是二进制 |
ftrace如何通过在相应的文件节点写入信息和读取,实现ftrace的配置和Trace日志的输出?
ftrace使用了tracefs文件系统注册file_operations结构体,对文件进行系统调用会关联对应的函数指针,实现ftrace配置和ftrace Trace日志读取功能,相关代码实现:
// 创建文件,关联file_operations
struct dentry *trace_create_file(const char *name,
umode_t mode,
struct dentry *parent,
void *data,
const struct file_operations *fops)
{
struct dentry *ret;
ret = tracefs_create_file(name, mode, parent, data, fops);
if (!ret)
pr_warn("Could not create tracefs '%s' entry\n", name);
return ret;
}
// 定义操作trace文件系统调用对应的函数指针
static const struct file_operations tracing_fops = {
.open = tracing_open,
.read = seq_read,
.write = tracing_write_stub,
.llseek = tracing_lseek,
.release = tracing_release,
};
trace_create_file("trace", TRACE_MODE_WRITE, d_tracer,
tr, &tracing_fops);
Perfetto采集ftrace数据
下面介绍一下完整采集流程:
-
通过adb的方式启动执行perfetto,指定Trace config,配置buffer_size、buffer policy、data source ftrace配置;
-
Perfetto读取Trace config配置,写入ftrace文件节点,配置收集的数据类型和设置ftrace每个cpu的ringbuffer size,并且定期读取per_cpu/cpu0/trace_pipe_raw内容,即定期读取每个cpu的ringbuffer数据,解析转换成对应的probuf格式,写入Producer和tracing service的共享内存中,tracing service会把共享内存的trace数据拷贝到trace buffer。
-
采集结束,停止trace收集,把tracing service的trace buffer数据读取出来,生成文件,通过Perfetto web ui查看。
相关数据流如下图:
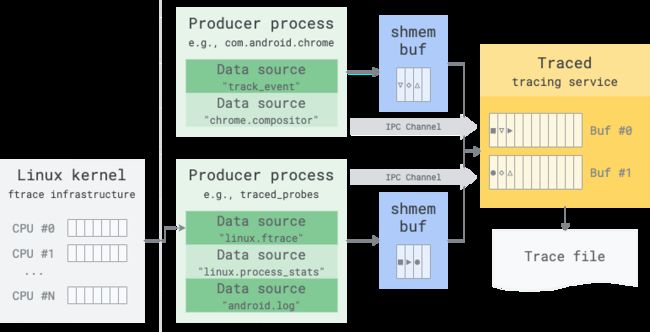
△Perfetto采集ftrace数据流
丨2.3 Perfetto分析
Perfetto分析模块,其核心是Trace Processor,其功能如下:

△Trace Processor
解析Trace文件、提取其中的数据,结构化为SQLite的内存数据库,并且提供基于SQL查询的API,通过写SQL的方式,查询对应的方法耗时,同时提供Python API。
支持的trace数据格式:
-
Perfetto native protobuf format
-
Linux ftrace
-
Android systrace
-
Chrome JSON (including JSON embedding Android systrace text)
-
Fuchsia binary format
-
Ninja logs (the build system)
三、自动插桩工具
自动插桩工具是一个gradle编译插件,全方法Trace插桩,保证Trace闭合,支持监控系统类,同时需要考虑包体积和性能问题。
丨3.1 自动插桩
Android系统会内置一些Trace,在APP代码需要手动添加,耗时耗力,需要实现一个自动插桩工具,自动在APP的方法添加Trace代码。
插桩代码:
class Test {
public void test() {
Trace.benginSection("test");
// 方法体
// ...
Trace.endSection();
}
}
自动插桩工具是利用Gradle Transform(Gradle Transform是Android官方提供给开发者在项目构建阶段中由class到dex转换之前修改class文件的一套api),开发的一个Gradle编译插件。利用ASM字节码操作框架,遍历所有的类的方法,在方法开始和结束点插入收集Trace的代码,实现APP全方法监控。
丨3.2 Did Not Finish问题
自动插桩工具投入使用后,遇到了Did Not Finish的问题,如果出现这种问题,整个Trace都错乱了,如下图所示:

Did Not Finish,表示方法没有结束,经过定位,是因为Trace.benginSection和Trace.endSection没有成对调用。为什么会出现这种问题呢?
示例问题代码:
class Test {
public void test() throws Exception {
Trace.benginSection("test");
// 方法体,代码出现异常,外部调用方法catch住
testThrowException();// 这个方法抛出异常,代码返回,endSection不会调用
// endSection可能存在不调用的情况
Trace.endSection();
}
}
运行期间,方法可能存在主动抛出异常和运行时异常的情况,如存在这种情况,Trace.endSection就得不到调用,就会存在问题。
如何保证Trace.benginSection和Trace.endSection的成对调用?
理想的解决方案是使用try-finally块整体包裹整个方法体,在方法开始点插入Trace.benginSection在finally块插入Trace.endSection,Java虚拟机会保证finally块的代码在try块代码结束前都会调用,可以保证Trace.benginSection和Trace.endSection的成对调用。
示例代码:
class Test {
public void testMethod(boolean a, boolean b) {
try {
Trace.beginSection("com.sample.systrace.TestNewClass.testMethod.()V");
if (!a) {
throw new RuntimeException("test throw");
}
Log.e("testa", "com.sample.systrace.TestNewClass.testMethod.()V");
if (b) {
return;
}
Log.e("testb", "com.sample.systrace.TestNewClass.testMethod.()V");
} finally {
Trace.endSection();
}
}
}
在字节码层面是没有finally关键字对应的字节码指令,为了搞明白finally的具体实现逻辑,对编译的字节码反编译:
public void testMethod(boolean, boolean);
descriptor: (ZZ)V
flags: ACC_PUBLIC
Code:
stack=3, locals=4, args_size=3
0: ldc #15 // String com.sample.systrace.TestNewClass.testMethod.(ZZ)V
2: invokestatic #21 // Method android/os/Trace.beginSection:(Ljava/lang/String;)V
5: iload_1
6: ifne 19
9: new #23 // class java/lang/RuntimeException
12: dup
13: ldc #25 // String test throw
15: invokespecial #27 // Method java/lang/RuntimeException."":(Ljava/lang/String;)V
18: athrow // 手动抛出异常,没有添加finally块的字节码指令
19: ldc #29 // String testa
21: ldc #31 // String com.sample.systrace.TestNewClass.testMethod.()V
23: invokestatic #37 // Method android/util/Log.e:(Ljava/lang/String;Ljava/lang/String;)I
26: pop
27: iload_2
28: ifeq 35
31: invokestatic #40 // Method android/os/Trace.endSection:()V
34: return // if(b)如果b为true的一个return指令,上一个指令添加了invokestatic,即增加了Trace.endSection调用
35: ldc #42 // String testb
37: ldc #31 // String com.sample.systrace.TestNewClass.testMethod.()V
39: invokestatic #37 // Method android/util/Log.e:(Ljava/lang/String;Ljava/lang/String;)I
42: pop
43: invokestatic #40 // Method android/os/Trace.endSection:()V
46: return // 代码正常结束点,也插入了invokestatic,即增加了Trace.endSection调用
47: astore_3 // 开始异常处理,抛出异常之前也插入了invokestatic,即增加了Trace.endSection调用
48: invokestatic #40 // Method android/os/Trace.endSection:()V
51: aload_3
52: athrow
Exception table: // 异常表,只要行号,from-to之间字节码指令发生异常,则跳转到target行进行处理
from to target type
0 46 47 Class java/lang/Throwable // 处理的异常类型
LocalVariableTable:
Start Length Slot Name Signature
5 42 0 this Lcom/sample/systrace/TestNewClass;
5 42 1 a Z
5 42 2 b
-
其实本质就是一个try-catch块,catch块捕获的异常类型为Throwable;
-
在正常结束点(各类return指令)前,把finally块的指令冗余的添加到各类return指令之前,保证正常退出;
-
异常结束点处理,主动抛出异常或者运行时异常,都统一由catch块处理,会在抛出异常之前插入finally块的指令。
对应的Java代码实现:
classTest {
public void testMethod(boolean a, boolean b) {
try {
Trace.beginSection("com.sample.systrace.TestNewClass.testMethod.()V");
if (!a) {
throw new RuntimeException("test throw");
}
Log.e("testa", "com.sample.systrace.TestNewClass.testMethod.()V");
if (b) {
Trace.endSection();
return;
}
Log.e("testb", "com.sample.systrace.TestNewClass.testMethod.()V");
Trace.endSection();
} catch(throwable e) {
Trace.endSection();
throw e;
}
}
综上,为了保证Trace.beginSection和Trace.endSection成对调用,参考了虚拟机实现try-finally,完美的插桩方案如下:
-
方法开始点只有一个,在方法开始点添加Trace.beginSection即可;
-
方法结束点会有多个,结束点存在两种情况,正常结束和异常结束,针对正常结束点(各类return指令)前添加Trace.endSection;
-
异常结束(主动抛出异常或者运行时异常),则用try-catch住整个方法体,catch异常类型为Throwable,在catch块中添加Trace.endSection,并且抛出捕获的异常。
丨3.3 监控系统类方法
自动插桩方案,只能对APP的代码编译的字节码进行插桩,由于Android系统和Java提供的系统类的字节码不参与打包,不能进行插桩,但还是想监控系统相关的类的一些不合理的调用。比如在主线程调用Object.wait,强制主线程进行等待,放弃CPU的使用权,线程进入sleep状态,等待其他线程notify或者wait的超时,可能会导致严重的性能问题。
为了监控此系统类问题,需要把调用系统Object.wait的代码,前后进行插桩,如下所示:
boolean isMain = Looper.getMainLooper() == Looper.myLooper();
try {
if (isMain) {
Trace.beginSection("Main Thread Wait");
}
lock.wait(timeout, nanos);
} finally {
if (isMain) {
Trace.endSection();
}
}
直接在每个方法里调用了Object.wait的方法调用处进行以上的插桩逻辑,插桩实现异常复杂,容易出错,而且这种实现会在每个Object.wait调用处进行相同逻辑的插桩,会增加指令数量,导致包体积增加。
为了实现Object.wait方法监控,同时减少插桩复杂读,最终决定采用字节码指令替换的方案,即在字节码层面把调用Object.wait方法指令,替换成自定义的wait方法,功能和系统的wait一样,只是添加了自定义的Trace。
Object类定义的wait方法有三个:
public final native void wait(long timeout, int nanos) throws InterruptedException;
public final void wait(long timeout) throws InterruptedException {
wait(timeout, 0);
}
public final void wait() throws InterruptedException {
wait(0);
}
重写后的自定义的增加监控的wait方法,增加Trace监控代码,最终还是调用系统的Object.wait方法:
public static void wait(Object lock, long timeout, int nanos) throws InterruptedException {
// 监控主线程wait
boolean isMain = Looper.getMainLooper() == Looper.myLooper();
try {
if (isMain) {
Trace.beginSection("Main Thread Wait");
}
lock.wait(timeout, nanos);
} finally {
if (isMain) {
Trace.endSection();
}
}
}
public static void wait(Object lock) throws InterruptedException {
wait(lock, 0L, 0);
}
public static void wait(Object lock, long timeout) throws InterruptedException {
wait(lock, timeout, 0);
}
在字节码里调用类方法指令有:INVOKEVIRTUAL(调用类实例方法)、INVOKESTATIC(调用静态方法)、INVOKESPECIAL(调用构造函数),这里我们主要关注下INVOKEVIRTUAL和INVOKESTATIC。
方法调用主要有两步:
-
参数加载,按照参数顺序从左到右加载方法指令的依赖的参数到操作数栈;
-
方法调用,执行INVOKEVIRTUAL或者INVOKESTATIC,指定类名、方法名、方法签名,调用方法。
其中INVOKEVIRTUAL是类实例方法调用,需要依赖对象引用,最先入操作数栈的是类对象引用,然后才是方法参数。
调用Object.wait(long timeout, int nanos)的字节码指令:
ALOAD 4 # 加载对象引用
LLOAD 1 # 加载long timeout
ILOAD 3 # 加载int nanos
INVOKEVIRTUAL java/lang/Object.wait (JI)V # 调用Object实例方法
重写的wait方法是静态方法,有个细节,第一个入参必须是一个Object对象,不能换位置,对应字节码:
ALOAD 4 # 加载对象引用
LLOAD 1 # 加载long timeout
ILOAD 3 # 加载int nanos
INVOKESTATIC com/baidu/systrace/SystraceInject.wait (Ljava/lang/Object;JI)V # 调用SystraceInject.wait的静态方法
从上面的字节码分析,自定义方法SystraceInject.wait参数和系统方法Object.wait参数顺序保持一致,保证操作数栈入栈顺序一致,参数加载流程一致,所以,我们只需要替换方法调用指令即可实现替换,遍历APP所有方法的字节码指令,替换方法目标wait方法调用的指令,INVOKEVIRTUAL java/lang/Object.wait (JI)V 替换为 INVOKESTATIC com/baidu/systrace/SystraceInject (Ljava/lang/Object;JI)V,即可实现监控主线程wait问题。
同理,其他需要动态替换的系统类也可用相同的方式进行替换,也可实现对系统方法调用的监控。
丨3.4 包尺寸和性能问题
自动插桩工具会对百度APP所有方法进行插桩,会导致包尺寸增加10M左右大小,为了减少包尺寸,需要对插桩的方法进行一些过滤,如一些确定不耗时的方法,比如简单的get、set方法、空方法。
在分析的过程中,还发现一些插桩导致的性能问题,如下图所示:
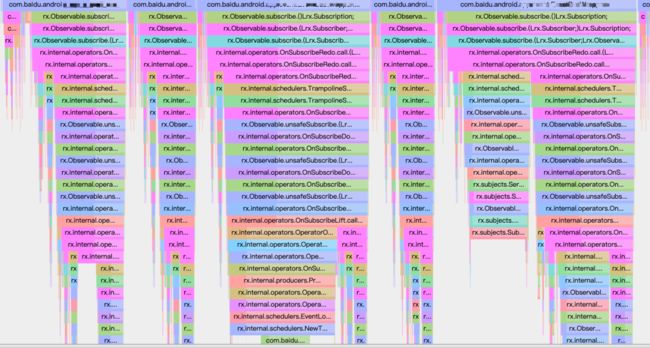
EventBus组件使用rxjava实现,调用层级非常深,在分析的过程中会认为EventBus组件非常耗时,但是经过优化EventBus组件,自定义实现了一套高性能的EventBus组件,通过AB实验查看整个启动流程只快了50ms,收益没有预期的大。
通过源码分析,收集App的trace,java/kotlin使用android.os.Trace,把trace信息最终会写入/sys/kernel/tracing/trace_marker中,写入ftrace RingBuffer。这种方式有一定的性能损耗,这是因为每个事件都涉及到一个字符串化、一个JNI调用,以及一个用户空间<->内核空间的写入trace_marker的系统调用(最耗时的部分)。
为解决此类问题,在自动插桩工具增加黑名单机制,可通过配置文件,配置类名或者包名,指定类或者包下的所有类不进行插桩,达到减少性能损耗和包体积的效果。
四、Trace自动分析工具
Trace自动分析工具主要是为了提升分析效率,基于基准版本自动化分析耗时劣化和锁问题。工具基于Trace Processor提供的Python API,可自己写SQL脚本查询内存数据库表中的Trace数据。
百度APP基于Trace Processor开发了一系列的自动分析工具集:
-
分析大于指定耗时阈值的方法列表;
-
对比分析版本耗时劣化、新增耗时问题;
-
支持统计TOP N异步线程CPU耗时;
-
支持分析主线程锁问题(monitor contention 前缀)。
丨4.1 核心表
自动化分析是基于内存数据库表,其使用的核心表如下:
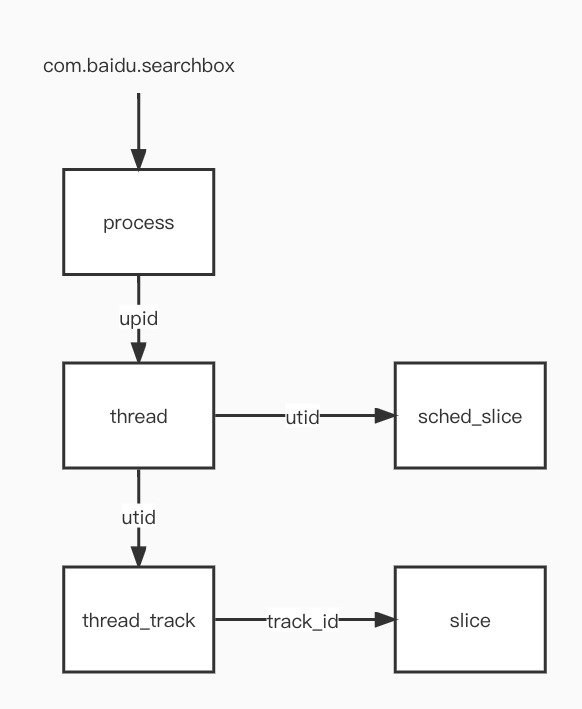
△自动分析使用的表
process:进程信息表,通过进程名,可拿到内存表中进程唯一upid;
thread:线程信息表,通过upid可以查询到进程下的所有线程,同时线程唯一表示使用utid表示;
thread_track:线程上下文,和utid绑定,可以通过track_id关联slice表,表示指定线程下的时间片事件;
sched_slice:cpu调度线程表,一条记录表示cpu调度一个线程的时间片,可用于计算线程被cpu调度时长,表结构:
| 列名 | 类型 | 描述 |
| id | SchedSliceTable::Id | id |
| type | string |
事件类型 |
| ts | int64_t | 开始调度时间戳,单位:nanoseconds |
| dur | int64_t | cpu调度时长,单位:nanoseconds |
| utid | uint32_t | 线程唯一表示utid |
| cpu | uint32_t | 调度的cpu编号 |
| end_state | string | 线程结束状态 |
| priority | int32_t | 调度优先级 |
slice:线程时间片表,和线程关联,关联一个track_id,记录用户空间的线程时间片事件,可用统计方法耗时,表结构:
| 列名 | 类型 | 描述 |
| id | SchedSliceTable::Id | id |
| type | string |
事件类型 |
| ts | int64_t | 开始调度时间戳,单位:nanoseconds |
| dur | int64_t | 时间片时长,单位:nanoseconds |
| arg_set_id | uint32_t | |
| track_id | TrackTable::Id |
thread_track表id,表示关联的线程 |
| category | string | slice的类别 |
| name | string | Trace#beginSection(name),写入的字符串,可以是方法签名 |
| depth | uint32_t | 表示当前调用的深度 |
| stack_id | int64_t |
|
| parent_stack_id | int64_t | |
| parent_id | SchedSliceTable::Id | 上层的slice的id |
丨4.2 方法耗时统计
分析性能问题,最重要的是统计方法耗时,自动化分析工具统计方法耗时有两种口径:
Wall Duration:方法整体耗时,包含等待CPU调度(sleep、等待IO、时间片耗尽)和CPU执行方法指令耗时,统计方法实际运行时长;
CPU Duration:CPU执行方法指令耗时,不包含等待调度的时间,统计方法自身指令执行的真实耗时;
**Wall Duration = CPU Duration + 等待调度时长,**通过分析方法的Wall Duration和CPU Duration可以分析出方法耗时是因为方法自身逻辑耗时,还是因为执行过程中存在锁、IO或者线程抢占的问题。
Wall Duration统计
Wall Duration是根据slice表中的dur字段统计方法整体耗时。
CPU Duration统计
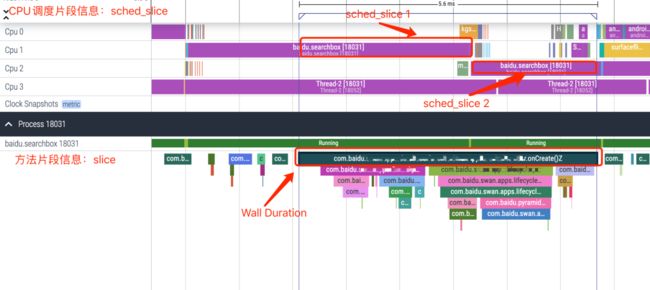
CPU Duration统计需要结合slice表和sched_slice表动态计算,CPU调度的最小单位是线程,方法运行在线程,所以计算方法CPU耗时的思路就是统计在方法运行这段时间,所有CPU调度方法所在线程的累积时长,即为方法的CPU执行耗时。slice表,统计了方法开始时间戳、时长和track_id(可通过thread_track表找到对应的线程Id),可确定线程Id、开始和结束时间戳;sched_slice表包含了CPU调度线程信息,包括调度的CPU编号、线程id、时长和开始时间戳,通过线程Id、开始和结束时间戳,可以把这段时间内调度指定线程Id的记录,累加即可,需要注意处理一些边际条件。如下图所示,CPU duration需要把sched_slice1和sched_slice2累加。
丨4.3 问题分析
百度APP目前自动化trace分析主要分析主线程耗时劣化,分析方法是基于一个基准版本(如线上版本release分支包)做为参照,与测试版本的每个主线程调用进行对比分析。自动分析支持分析以下几类问题:
主线程锁
主要分析synchronize关键字导致的锁问题,虚拟机会通过atrace添加Trace信息,Trace信息有固定前缀monitor contention,并且会说明占用锁的线程ID,直接分析slice表name字段前缀为monitor contention。
方法耗时劣化
此类问题关注的是主线程的方法耗时劣化,通过对比基准版本和测试版本,耗时劣化是指测试的版本对比基准版本耗时有增加,到了一定阈值(当前阈值10ms),会认为是耗时劣化问题。
方法CPU耗时劣化
此类问题劣化问题和方法耗时劣化类似,统计的是方法的CPU耗时。
新增方法耗时
此类问题关注的是主线程的新增方法耗时,测试版本新增方法的耗时到达一定阈值(目前是5ms),会认为是新增耗时问题。
五、最佳实践
百度APP基于自动插桩工具和Trace自动化分析工具,构建了一套线下防劣化监控流水线,流程如下:

其中的打包流程使用的是自动插桩工具,Trace自动分析用的是Trace自动分析工具。流水线自动打包,自动启动测试抓取trace,自动化分析和根据堆栈自动分发问题,无需人工介入,只需投入很少人力处理一些需要豁免的问题(方法改名、系统锁、线程调度问题等),对比之前单次性能人工测试和人工分析需要2人天,极大提升了效率。
性能测试报告:

报告中的指标计算和问题分析都是有Trace自动化分析工具产出,同时问题详情会有详细的劣化数据和堆栈,能快速定位劣化问题。
六、小结
百度APP启动性能工具基于perfetto结合自动插桩和自动化分析能力,支持采集APP全Java/kotlin方法Trace日志,同步支持自动化分析劣化问题,能极大提升效率。由于是全Java/kotlin方法插桩还存在影响包体积问题,同时采集trace也存在一定性能损耗,后续还需要持续优化(继续减少不必要插桩、控制采集层级、接入Perfetto SDK采集等)。
——END——
参考资料:
[1] Perfetto官方文档:
https://perfetto.dev/docs/
[2] Perfetto源码:
https://github.com/google/perfetto
[3] Ftrace原理解析:
https://blog.csdn.net/u012489236/article/details/119494200
[4] Ftrace官方文档:
https://www.kernel.org/doc/html/latest/trace/ftrace.html
[5] Linux内核源码:
https://elixir.bootlin.com/linux/latest/source/kernel/trace/trace.c#L8783
推荐阅读:
数字人技术在直播场景下的应用
百度工程师教你玩转设计模式(工厂模式)
超大模型工程化实践打磨,百度智能云发布云原生 AI 2.0 方案
前后端数据接口协作提效实践
前端的状态管理与时间旅行:San实践篇
百度App 低端机优化-启动性能优化(概述篇)
面向大规模数据的云端管理,百度沧海存储产品解析
增强分析在百度统计的实践