操作系统-linux-内存-缓存
目录
Buffer I/O 和 Direct I/O
Buffer I/O
内存映射文件
Direct I/O
文件占用内存详解
free
top
meminfo
vmstat
hcache
fincore
pcatat
slabtop
缓存相关参数
cache过高的原因定位与解决
Buffer I/O 和 Direct I/O

Buffer I/O
缓存 I/O 又被称作标准 I/O,大多数文件系统的默认 I/O 操作都是缓存 I/O。 在 Linux 的缓存 I/O 机制中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。调用read()时,如果 操作系统内核地址空间的页缓存( page cache )有数据就读取出该数据并直接返回给应用程序,如果没有就从磁盘读取数据到页缓存。然后再从页缓存拷贝到应用程序的地址空间。调用write()时,数据会先从应用程序的地址空间拷贝到 操作系统内核地址空间的页缓存,然后再写入磁盘。根据Linux的延迟写机制,当数据写到操作系统内核地址空间的页缓存就意味write()完成了,操作系统会定期地将页缓存的数据刷到磁盘上。所以缓存 I/O 有以下这些优点:
缓存 I/O 使用了操作系统内核的页缓存,保护了磁盘
缓存 I/O 减少读盘的次数,提高了读取速度
总的来说,Buffer I/O为了提高读写效率和保护磁盘,使用了页缓存机制,不过由于页缓存处于内核空间,不能被应用程序(用户进程)直接寻址,所以还需要将页缓存数据再拷贝到内存对应的用户空间中。这样,需要两次数据拷贝才能完成用户进程对数据的读取操作。写操作也是一样,将页缓存的数据写入磁盘的时候,必须先拷贝到内核空间对应的主存,然后在写入磁盘中。
内存映射文件
因此,Buffer I/O 中引入一类特别的操作叫做内存映射文件(mmap),它的不同点在于,中间会减少一层数据从用户地址空间到操作系统地址空间的复制开销 。使用mmap函数的时候,会在当前进程的用户地址空间中开辟一块内存,这块内存与系统的文件进行映射。对其的读取和写入,会转化为对相应文件的操作。 并且,在进程退出的时候,会将变化的内容(脏页)自动回写到对应的文件里面。
Direct I/O
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,中间少了页缓存的支持。操作系统层提供的缓存往往会使应用程序在读写数据的时候获得更好的性能,但是对于某些特殊的应用程序,比如说数据库管理系统这类应用,他们更倾向于选择他们自己的缓存机制,因为数据库管理系统往往比操作系统更了解数据库中存放的数据,数据库管理系统可以提供一种更加有效的缓存机制来提高数据库中数据的存取性能。
在IO敏感、内存不足的服务上做数据copy时,采用Direct I/O方式,避免系统缓存copy的文件(例如:线上索引离线更新)。
文件占用内存详解
free
free命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。在Linux系统监控的工具中,free命令是最经常使用的命令之一。
1.命令格式:
free [参数]
2.命令功能:
free 命令显示系统使用和空闲的内存情况,包括物理内存、交互区内存(swap)和内核缓冲区内存。共享内存将被忽略
3.命令参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。
4.使用实例:
实例1:显示内存使用情况
命令:
free
free -g
free -m
输出:
[root@SF1150 service]# free
total used free shared buffers cached
Mem: 32940112 30841684 2098428 0 4545340 11363424
-/+ buffers/cache: 14932920 18007192
Swap: 32764556 1944984 30819572
[root@SF1150 service]# free -g
total used free shared buffers cached
Mem: 31 29 2 0 4 10
-/+ buffers/cache: 14 17
Swap: 31 1 29
[root@SF1150 service]# free -m
total used free shared buffers cached
Mem: 32168 30119 2048 0 4438 11097
-/+ buffers/cache: 14583 17584
Swap: 31996 1899 30097
说明:
下面是对这些数值的解释:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小。
第三行(-/+ buffers/cached):
used:已使用多大。
free:可用有多少。
第四行是交换分区SWAP的,也就是我们通常所说的虚拟内存。
区别:第二行(mem)的used/free与第三行(-/+ buffers/cache) used/free的区别。 这两个的区别在于使用的角度来看,第一行是从OS的角度来看,因为对于OS,buffers/cached 都是属于被使用,所以他的可用内存是2098428KB,已用内存是30841684KB,其中包括,内核(OS)使用+Application(X, oracle,etc)使用的+buffers+cached.
第三行所指的是从应用程序角度来看,对于应用程序来说,buffers/cached 是等于可用的,因为buffer/cached是为了提高文件读取的性能,当应用程序需在用到内存的时候,buffer/cached会很快地被回收。
所以从应用程序的角度来说,可用内存=系统free memory+buffers+cached。
top
接着通过top命令,shift + M按内存排序后,观察系统中使用内存最大的进程情况
top显示系统当前的进程和其他状况,是一个动态显示过程,即可以通过用户按键来不断刷新当前状态.如果在前台执行该命令,它将独占前台,直到用户终止该程序为止. 比较准确的说,top命令提供了实时的对系统处理器的状态监视.它将显示系统中CPU最“敏感”的任务列表.该命令可以按CPU使用.内存使用和执行时间对任务进行排序;而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定.
下面详细介绍它的使用方法。
参数函数
top - 01:06:48 up 1:22, 1 user, load average: 0.06, 0.60, 0.48 Tasks: 29 total, 1 running, 28 sleeping, 0 stopped, 0 zombie Cpu(s): 0.3% us, 1.0% sy, 0.0% ni, 98.7% id, 0.0% wa, 0.0% hi, 0.0% si Mem: 191272k total, 173656k used, 17616k free, 22052k buffers Swap: 192772k total, 0k used, 192772k free, 123988k cached PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1379 root 16 0 7976 2456 1980 S 0.7 1.3 0:11.03 sshd 14704 root 16 0 2128 980 796 R 0.7 0.5 0:02.72 top 1 root 16 0 1992 632 544 S 0.0 0.3 0:00.90 init 2 root 34 19 0 0 0 S 0.0 0.0 0:00.00 ksoftirqd/0 3 root RT 0 0 0 0 S 0.0 0.0 0:00.00 watchdog/0
统计信息区前五行是系统整体的统计信息。第一行是任务队列信息,同 uptime 命令的执行结果。其内容如下:
01:06:48 当前时间 up 1:22 系统运行时间,格式为时:分 1 user 当前登录用户数 load average: 0.06, 0.60, 0.48 系统负载,即任务队列的平均长度。三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。
第二、三行为进程和CPU的信息。当有多个CPU时,这些内容可能会超过两行。内容如下:
total 进程总数 running 正在运行的进程数 sleeping 睡眠的进程数 stopped 停止的进程数 zombie 僵尸进程数 Cpu(s): 0.3% us 用户空间占用CPU百分比 1.0% sy 内核空间占用CPU百分比 0.0% ni 用户进程空间内改变过优先级的进程占用CPU百分比 98.7% id 空闲CPU百分比 0.0% wa 等待输入输出的CPU时间百分比 0.0%hi:硬件CPU中断占用百分比 0.0%si:软中断占用百分比 0.0%st:虚拟机占用百分比
最后两行为内存信息。内容如下:
Mem: 191272k total 物理内存总量 173656k used 使用的物理内存总量 17616k free 空闲内存总量 22052k buffers 用作内核缓存的内存量 Swap: 192772k total 交换区总量 0k used 使用的交换区总量 192772k free 空闲交换区总量 123988k cached 缓冲的交换区总量,内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
进程信息区统计信息区域的下方显示了各个进程的详细信息。首先来认识一下各列的含义。
序号 列名 含义 a PID 进程id b PPID 父进程id c RUSER Real user name d UID 进程所有者的用户id e USER 进程所有者的用户名 f GROUP 进程所有者的组名 g TTY 启动进程的终端名。不是从终端启动的进程则显示为 ? h PR 优先级 i NI nice值。负值表示高优先级,正值表示低优先级 j P 最后使用的CPU,仅在多CPU环境下有意义 k %CPU 上次更新到现在的CPU时间占用百分比 l TIME 进程使用的CPU时间总计,单位秒 m TIME+ 进程使用的CPU时间总计,单位1/100秒 n %MEM 进程使用的物理内存百分比 o VIRT 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES p SWAP 进程使用的虚拟内存中,被换出的大小,单位kb。 q RES 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA r CODE 可执行代码占用的物理内存大小,单位kb s DATA 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb t SHR 共享内存大小,单位kb u nFLT 页面错误次数 v nDRT 最后一次写入到现在,被修改过的页面数。 w S 进程状态(D=不可中断的睡眠状态,R=运行,S=睡眠,T=跟踪/停止,Z=僵尸进程) x COMMAND 命令名/命令行 y WCHAN 若该进程在睡眠,则显示睡眠中的系统函数名 z Flags 任务标志,参考 sched.h
默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容。
更改显示内容通过 f 键可以选择显示的内容。按 f 键之后会显示列的列表,按 a-z 即可显示或隐藏对应的列,最后按回车键确定。
按 o 键可以改变列的显示顺序。按小写的 a-z 可以将相应的列向右移动,而大写的 A-Z 可以将相应的列向左移动。最后按回车键确定。
按大写的 F 或 O 键,然后按 a-z 可以将进程按照相应的列进行排序。而大写的 R 键可以将当前的排序倒转。
命令使用
top使用格式
top [-] [d] [p] [q] [c] [C] [S] [s] [n]
参数说明
d 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。 p 通过指定监控进程ID来仅仅监控某个进程的状态。 q 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。 S 指定累计模式 s 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。 i 使top不显示任何闲置或者僵死进程。 c 显示整个命令行而不只是显示命令名
其他实用命令
下面介绍在top命令执行过程中可以使用的一些交互命令。从使用角度来看,熟练的掌握这些命令比掌握选项还重要一些。这些命令都是单字母的,如果在命令行选项中使用了s选项,则可能其中一些命令会被屏蔽掉。
Ctrl+L 擦除并且重写屏幕。 h或者? 显示帮助画面,给出一些简短的命令总结说明。 k 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。 i 忽略闲置和僵死进程。这是一个开关式命令。 q 退出程序。 r 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。 S 切换到累计模式。 s 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。 f或者F 从当前显示中添加或者删除项目。 o或者O 改变显示项目的顺序。 l 切换显示平均负载和启动时间信息。 m 切换显示内存信息。 t 切换显示进程和CPU状态信息。 c 切换显示命令名称和完整命令行。 M 根据驻留内存大小进行排序。 P 根据CPU使用百分比大小进行排序。 T 根据时间/累计时间进行排序。 W 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
附常用操作:
top //每隔5秒显式所有进程的资源占用情况 top -d 2 //每隔2秒显式所有进程的资源占用情况 top -c //每隔5秒显式进程的资源占用情况,并显示进程的命令行参数(默认只有进程名) top -p 12345 -p 6789//每隔5秒显示pid是12345和pid是6789的两个进程的资源占用情况 top -d 2 -c -p 123456 //每隔2秒显示pid是12345的进程的资源使用情况,并显式该进程启动的命令行参数
参考: http://www.w3pop.com/learn/view/p/1/o/1/doc/linux_cmd_top/
meminfo
通过读取 /proc/meminfo 文件,能够实时获取系统内存情况:
$ cat /proc/meminfo
...
Buffers: 1224 kB
Cached: 111472 kB
SwapCached: 36364 kB
Active: 6224232 kB
Inactive: 979432 kB
Active(anon): 6173036 kB
Inactive(anon): 927932 kB
Active(file): 51196 kB
Inactive(file): 51500 kB
...
Shmem: 10000 kB
...
SReclaimable: 43532 kB
...vmstat
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
参数:
vmstat [-a] [-n] [-S unit] [delay [ count]]
vmstat [-s] [-n] [-S unit]
vmstat [-m] [-n] [delay [ count]]
vmstat [-d] [-n] [delay [ count]]
vmstat [-p disk partition] [-n] [delay [ count]]
vmstat [-f]
vmstat [-V]
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
root@ubuntu:~# vmstat 2 1 procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 0 3498472 315836 3819540 0 0 0 1 2 0 0 0 100 0
2表示每个两秒采集一次服务器状态,1表示只采集一次。
每列含义
r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
in 每秒CPU的中断次数,包括时间中断
cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
id 空闲 CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
wt 等待IO CPU时间。
如果r经常大于4 ,且id经常少于40,表示cpu的负荷很重。如果bi,bo 长期不等于0,表示内存不足。
通过VMSTAT识别CPU瓶颈:
r(运行队列)展示了正在执行和等待CPU资源的任务个数。当这个值超过了CPU数目,就会出现CPU瓶颈了。
Linux下查看CPU核心数的命令:cat /proc/cpuinfo|grep processor|wc -l
参考:
(总结)Linux监控工具vmstat命令详解
hcache
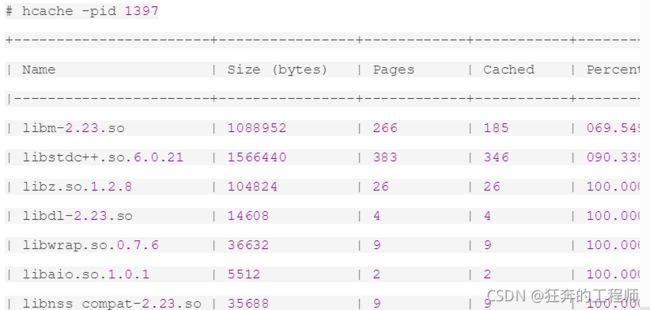
hcache是基于pcstat的,pcstat可以查看某个文件是否被缓存和根据进程pid来查看都缓存了哪些文件。hcache在其基础上增加了查看整个操作系统Cache和根据使用Cache大小排序的特性。
安装
# wget https://silenceshell-1255345740.cos.ap-shanghai.myqcloud.com/hcache
# chmod 755 hcache ;mv hcache /usr/local/bin/
参数:
- name:占用缓存的文件全路径
- size:文件大小
- pages:占了多少个Block
- Cached:缓存使用了多少个Block
- Percent:Cached 与 Pages的比值
查看进程的缓存使用
fincore
fincore的工作原理是将指定的文件的相应inode data与kernel的 page cache table做对比,如果page cache table有这个inode 信息,就找该inode对应的data block的大小。因为kernel的page cache table只存储data block的引用而不是文件名,即文件的inode信息。所以并没有任何一个工具运行一次就可以找出所有的文件使用缓存的情况。
所以使用linux-fincore只能加文件名,来判断该文件是否被缓存,如果缓存,大小是多少。问题是你不能随便猜哪个文件是否被缓存吧。
./fincore --pages=false --summarize --only-cached a.txt

download:
https://github.com/waleedmazhar/linux-ftools
https://code.google.com/p/linux-ftools/
问题
实测发现,直接执行 linux-fincore --pages=false --summarize --only-cached * 有时并不能完全显示所有的缓存。比如:
在测试中构造一个32GB大小的文本文件file1.csv,然后wc -l file1.csv,
执行完毕后通过free可以看到系统cache已经有30多GB了,但执行上述linux-fincore命令却找不到file1.csv的cache记录(没有仔细分析其源码,不太清楚是什么原因)
但是直接指定file1.csv文件名或其目录的话,是可以看到具体的缓存信息的:
参考:
使用linux-fincore查看Linux系统缓存哪些文件_icycode的专栏-CSDN博客_fincore
Linux内存中Cache分析_Linux教程_Linux公社-Linux系统门户网站
pcatat
提供了一个办法,那就查看哪些进程使用的物理内存最多,就找到该进程打开的文件,然后用fincore查看这些文件的缓存使用率。
#!/bin/bash
if [ $(uname -m) == "x86_64" ] ; then
curl -L -o pcstat https://github.com/tobert/pcstat/raw/2014-05-02-01/pcstat.x86_64
else
curl -L -o pcstat https://github.com/tobert/pcstat/raw/2014-05-02-01/pcstat.x86_32
fi
chmod 755 pcstat或者下载源码编译安装,需要$GOPATH/bin is in your PATH
go get golang.org/x/sys/unix
go get github.com/tobert/pcstat/pcstat
或者
git clone https://github.com/tobert/pcstat.git
cd pcstat
go build
sudo cp -a pcstat /usr/local/bin
pcstat /usr/local/bin/pcstat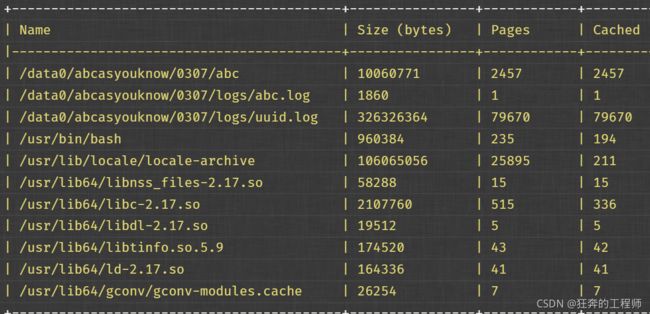
2个查找文件占用内存top n的脚本:
#!/bin/bash
#Author: Shanker
#Time: 2016/06/08
#set -e
#set -u
#you have to install linux-fincore
if [ ! -f /usr/local/bin/linux-fincore ]
then
echo "You haven't installed linux-fincore yet"
exit
fi
#find the top 10 processs' cache file
ps -e -o pid,rss|sort -nk2 -r|head -10 |awk '{print $1}'>/tmp/cache.pids
#find all the processs' cache file
#ps -e -o pid>/tmp/cache.pids
if [ -f /tmp/cache.files ]
then
echo "the cache.files is exist, removing now "
rm -f /tmp/cache.files
fi
while read line
do
lsof -p $line 2>/dev/null|awk '{print $9}' >>/tmp/cache.files
done>/tmp/cache.fincore
fi
done
linux-fincore -s `cat /tmp/cache.fincore`
rm -f /tmp/cache.{pids,files,fincore}
#!/bin/bash
#you have to install pcstat
if [ ! -f /data0/brokerproxy/pcstat ]
then
echo "You haven't installed pcstat yet"
echo "run \"go get github.com/tobert/pcstat\" to install"
exit
fi
#find the top 10 processs' cache file
ps -e -o pid,rss|sort -nk2 -r|head -10 |awk '{print $1}'>/tmp/cache.pids
#find all the processs' cache file
#ps -e -o pid>/tmp/cache.pids
if [ -f /tmp/cache.files ]
then
echo "the cache.files is exist, removing now "
rm -f /tmp/cache.files
fi
while read line
do
lsof -p $line 2>/dev/null|awk '{print $9}' >>/tmp/cache.files
done>/tmp/cache.pcstat
fi
done
/data0/brokerproxy/pcstat `cat /tmp/cache.pcstat`
rm -f /tmp/cache.{pids,files,pcstat}内存求和
hcache -pid 117466 | awk '{print $4}' > cache.txt
求和
I=0;$I=0; for N in $(cat cache.txt); do I=$(($I + $N)); done; echo $I参考:
缓存分析工具的安装和使用 · 运维之路
slabtop
内核的模块在分配资源的时候,为了提高效率和资源的利用率,都是透过slab来分配的。slab为结构性缓存占用内存,该项也经常占用很大的内存。不过借助slabtop工具,我们可以很方便的显示内核片缓存信息,该工具可以更直观的显示/proc/slabinfo下的内容。
slabtop -s c显示了一台机器缓存中占用对象的情况:
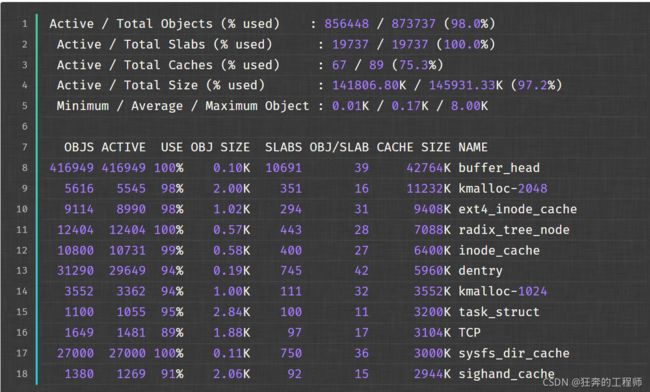
缓存相关参数
在/proc/sys/vm中有以下文件与回刷脏数据密切相关:
配置文件 功能 默认值
dirty_background_ratio 触发回刷的脏数据占可用内存的百分比 0
dirty_background_bytes 触发回刷的脏数据量 10
dirty_bytes 触发同步写的脏数据量 0
dirty_ratio 触发同步写的脏数据占可用内存的百分比 20
dirty_expire_centisecs 脏数据超时回刷时间(单位:1/100s) 3000
dirty_writeback_centisecs 回刷进程定时唤醒时间(单位:1/100s) 500
总结下, cache是linux对读入内存的文件尽量不释放,这样可以减少重复的磁盘读,直到内存不足的
查看配置
sysctl -a | grep dirty
内存中有多少脏数据
cat /proc/vmstat | egrep "dirty|writeback"
vm.dirty_background_ratio
触发异步清理
是内存可以填充“脏数据”的百分比。这些“脏数据”在稍后是会写入磁盘的,pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。举一个例子,我有32G内存,那么有3.2G的内存可以待着内存里,超过3.2G的话就会有后来进程来清理它。
vm.dirty_ratio
触发阻塞io,并将脏数据写进磁盘
是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值。如果脏数据超过这个数量,新的IO请求将会被阻挡,直到脏数据被写进磁盘。这是造成IO卡顿的重要原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.dirty_expire_centisecs
脏数据存活的时间
vm.dirty_writeback_centisecs
多长时间 pdflush/flush/kdmflush 这些进程会起来一次。
100是1秒
修改
/etc/sysctl.conf 并执行 sysctl -p
cache过高的原因定位与解决
- 在crontab定时执行echo 3> /proc/sys/vm/drop_caches清理缓存。治标不治本,过段时间缓存又会增加上来。
- 使用上面介绍的hcache、fincore等工具查看下是哪些文件被缓存了,如果缓存的文件没有用就删除文件即可。删除文件后该文件的缓存将永久清除,但是系统难免会读取新文件什么的缓存可能还是有,可以结合第一个办法定期清理缓存。
- 把没用的日志文件清理删除掉,尤其是大日志文件,一般缓存就下去了。
- 将vm.extra_free_kbytes设置为vm.min_free_kbytes和一样大,提高low阈值,触发操作系统自动回收缓存
服务器cache占了大半的内存导致内存不足,先释放cache保障服务正常运行再说:
手工释放缓存
先用root用户执行sync同步一下然后再执行echo 3> /proc/sys/vm/drop_caches
To free pagecache释放页缓存:
echo 1 > /proc/sys/vm/drop_caches
To free reclaimable slab objects (includes dentries and inodes)释放slab对象:
echo 2 > /proc/sys/vm/drop_caches
To free slab objects and pagecache释放slab和页缓存:
echo 3 > /proc/sys/vm/drop_caches
To disable them, echo 4 (bit 2) into drop_caches.
概念
inode是表示文件的数据结构
dentries是表示目录的数据结构
slab是Linux操作系统的一种内存分配机制,slab分配算法采用cache 存储内核对象。