【机器学习】李宏毅——生成式对抗网络GAN
1、基本概念介绍
1.1、What is Generator
在之前我们的网络架构中,都是对于输入x得到输出y,只要输入x是一样的,那么得到的输出y就是一样的。
但是Generator不一样,它最大的特点在于多了另外一个具有随机性的输入,如下图:
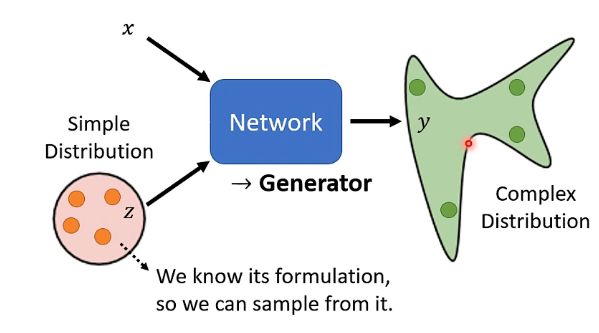
其中输入除了x之外,还有一个z,而z是从一个已知的分布之中进行采样得到的,例如高斯分布等等。那么由于z具有一定的随机性,那么由x与z获得的输出y也就不再只是一个确定的值,而是一个复杂的分布。
1.2、Why distribution
为什么需要将输出y变成一个分布呢?来看下面这个例子:
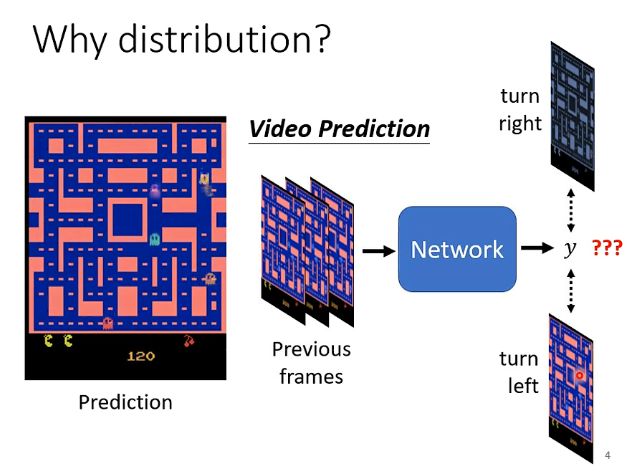
假设我们现在正在做一个画面预测的任务,根据以前的画面数据预测接下来里面的小精灵会往哪里走动。但是以往的数据中可能会存在冲突的数据,即例如同一只小精灵在相同的转角处它选择了不同的选择,某次向左某次向右,这就相当于告诉机器它做出向左向右的预测都是对的,但是它为了拟合这两份数据它就可能在预测的时候直接将一只小精灵进行复制,一只向左一只向右来同时满足最小化误差的学习。但这在我们看来是不合理的。因此我们可以给网络增加一个输入z,由某个分布中取样得到的z来使得y也是一个分布,那么y就根据采样得到的z来决定我这一次是向左转还是向右转。
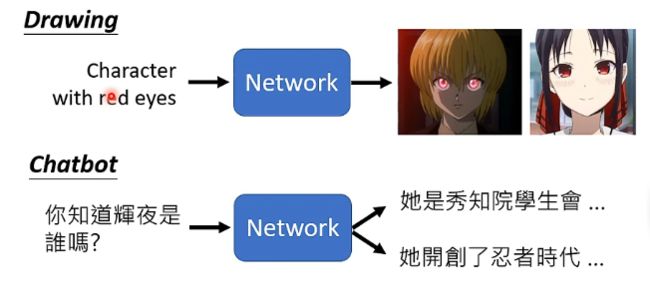
那么实际上在一些需要一定的创造力的任务中就需要输出是一个分布,即某一些任务并不是只有唯一的答案,它面对相同的输入可以有很多个正确的答案,那么这个时候我们就希望y可以是一个分布,如下图:
1.3、Generative Adversarial Network(GAN)
先介绍一下Contional Generation和Uncontional(无条件、无限制) Generation这两者的差别,前者就是之前讲的网络的输入有x和z,而后者就是网络的输入单纯只有z而已。下面我们将以Uncontional Generation用来生成动漫人脸的例子来进行介绍。
需要注意的是一般来说z都是一个较为低纬度的向量,而输出的y如果是一张图片那么将是一个高维的向量,这中间的转换就是由Generator来实现
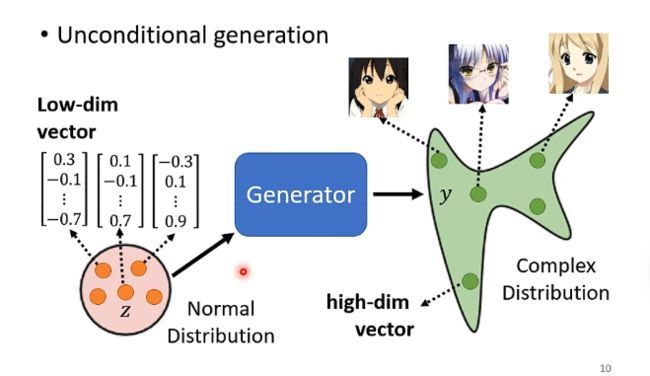
而在训练这个生成器之前呢,我们还需要训练一个discriminator,也是一个网络架构,其功能就是输入一张图片,然后输出结果表示这张图片是动漫人脸的可能性有多大,例如:
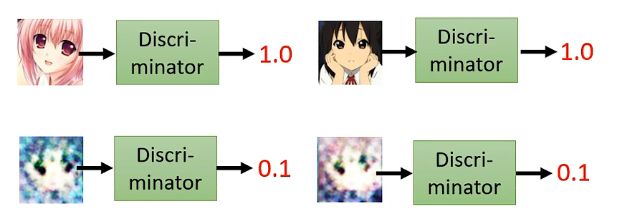
其内部具体的结构取决于你自己的设计,例如是CNN或者Transformer等都可以。
1.4、Basic Idea of GAN
在最开始GAN的训练方式是:
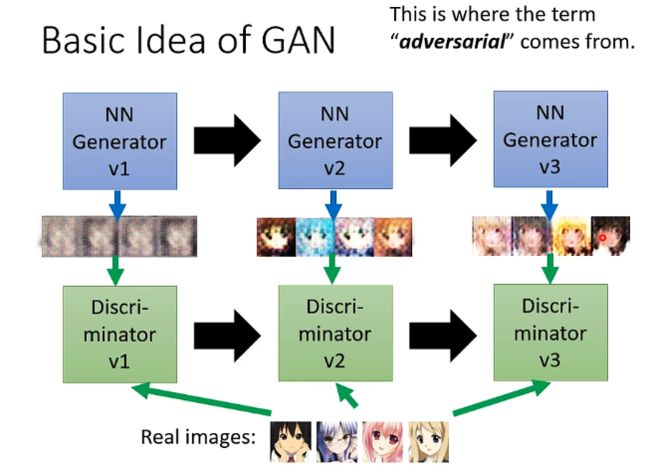
- 有一个Generator和一个Discriminator,那么一开始生成器的参数基本都是随机化的,那么它所产生的图像也很难接近真实的动漫人脸,而辨别器的主要任务就是找出生成器生成的图片与真实的动漫图片之间的不同,例如在下面的图片中它第一次辨认的依据是眼睛
- 那么第二轮呢生成器就学习到应该要产生出眼睛来骗过辨别器,那么其参数调整后就生成出有眼睛的动漫人脸,那么辨别器就需要找出更多的特别来进行辨认,例如嘴巴、头发
- 第三轮呢生成器就再次调整,生成出嘴巴、头发等,那么这时候辨别器就需要再次调整寻找新的特征
- 因此生成器和辨别器就是在这个对抗的过程中不断进步
1.5、训练的方法
生成器和辨别器具体的训练步骤如下所示:
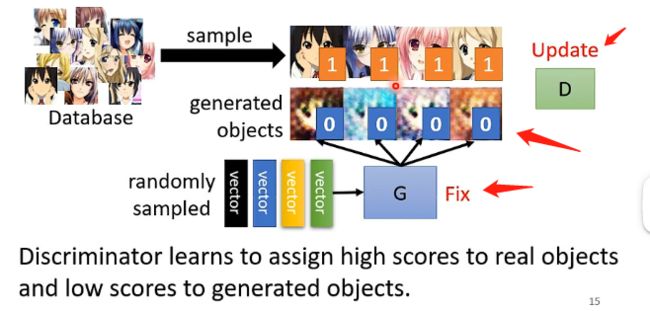
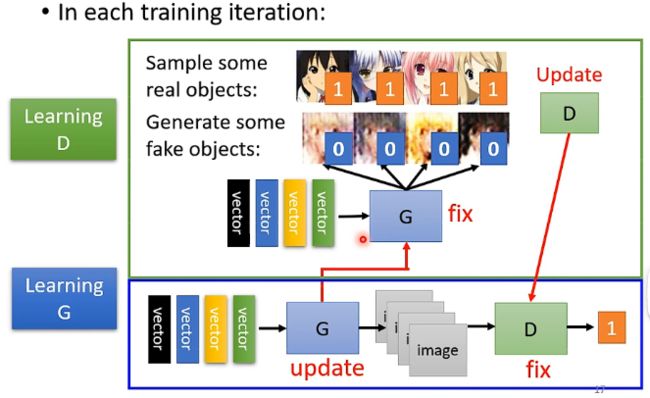
Step1:随机初始化生成器和辨别器的参数,并固定住生成器的参数,让生成器接受向量并产生一些图像的输出;另外在真实动漫人脸数据库中采样一些样本出来标识为1,而生成器生成的假图标识为0,然后用这些样本去训练辨别器,让它输出一个0到1之间的数值,1代表越接近于真实的图片。如下所示:
Step2:固定住辨别器的参数,让生成器生成一张图片并传给辨别器得到一个输出,代表该图片为真实图片的可能性,然后调整生成器的参数使辨别器的输出越高越好,那么这里调整的方法跟普通的神经网络类似, 可以把生成器和辨别器连在一起看成一个大的网络,是接受一个向量的输入然后输出一个数值,那么就同样可以采用梯度下降等的方式来调整生成器的参数。这个步骤也可以看成是生成器在学习如何欺骗辨别器。
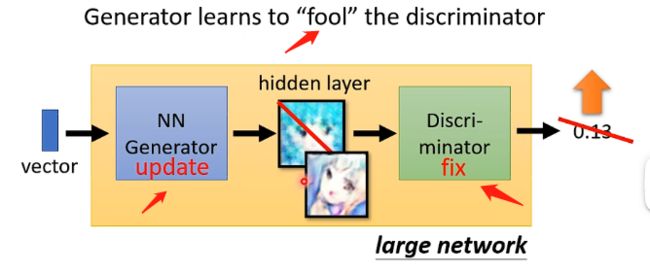
Step3:不断重复Step1和Step2的训练,直到生成器输出的图片能够满足要求
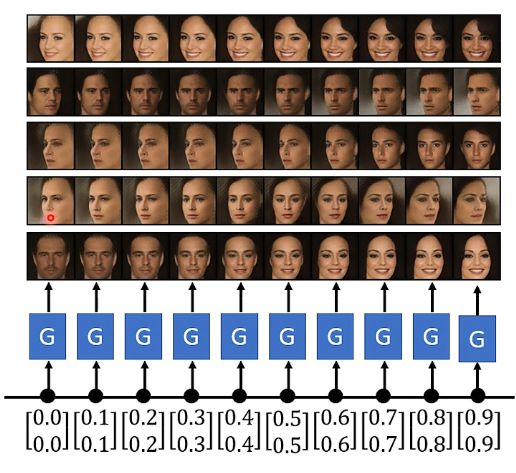
更有趣的应用,如果我们用来训练产生真实人脸,可以实现两张人脸之间的过度,具体我们可以看下图,就是在两张人脸对应的向量之间做插值,我相信这个效果也有很多小伙伴在网络上看过,我也是此刻才明白具体的原理,也就是用各式各样的GAN来实现。
2、GAN的理论
2.1、基础理论介绍
在GAN中,我们可以把我们的目标进行简化,就比如下图,我们希望能够找到一组G的参数,它能够对分布z的输入产生对应的分布 P G P_G PG,而假设我们真实的分布为 P d a t a P_{data} Pdata,我们希望它们能够越接近越好,即:
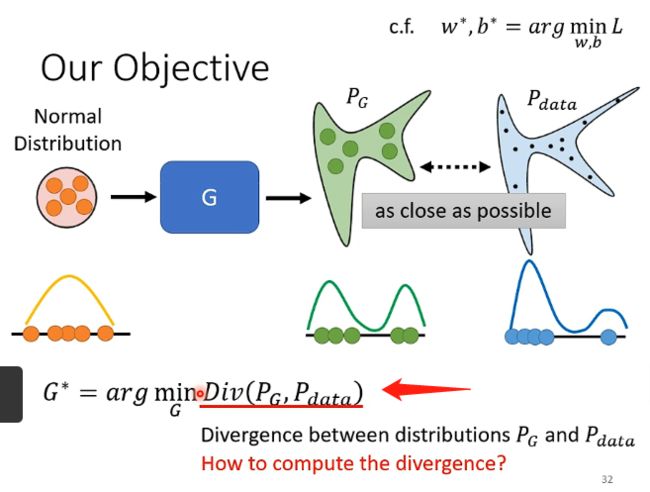
其中Div可以用来衡量两个分布之间的距离,例如KL散度等等。但是目前的问题是这个Div很可能写出来是一个非常复杂的积分等等,因为我们根本不知道两个分布是什么,我们根据就不知道怎么表示出来或者说怎么进行最小化,因此这也是GAN在训练的时候会遇到的常见问题。而GAN告诉我们的解决方案就是:不需要知道两个分布的具体函数,只需要有办法能够从分布中进行采样即可,即 P G P_G PG和 P d a t a P_{data} Pdata只需要知道怎么采样即可,如下图:

具体的实现还是有辨别器来做到的。见下图:

在训练辨别器的时候,像我们之前说到的,使用了从真实数据中采样的数据和生成的假的数据来分别加上标签进行训练,然后重点就在于损失函数的确定,从图中可以看到损失函数的具体是式子为:
V ( G , D ) = E y − P d a t a [ l o g D ( y ) ] + E y − P G [ l o g ( 1 − D ( y ) ) ] V(G,D)=E_{y-P_{data}}[logD(y)]+E_{y-P_G}[log(1-D(y))] V(G,D)=Ey−Pdata[logD(y)]+Ey−PG[log(1−D(y))]
那么实际上 V ( G , D ) V(G,D) V(G,D)就是加了负号的交叉熵,那我们希望最大化 V ( G , D ) V(G,D) V(G,D)就相当于最小化交叉熵,也就相当于将辨别器看成一个二分类的贝叶斯分类器来训练。而另外一个需要注意的点是当你最大化 V ( G , D ) V(G,D) V(G,D)的时候,解出来的这个 V ( G , D ) V(G,D) V(G,D)的值实际上和 J S d i v e r g e n c e JS ~divergence JS divergence是有关的。这个观点可以直观地进行理解:
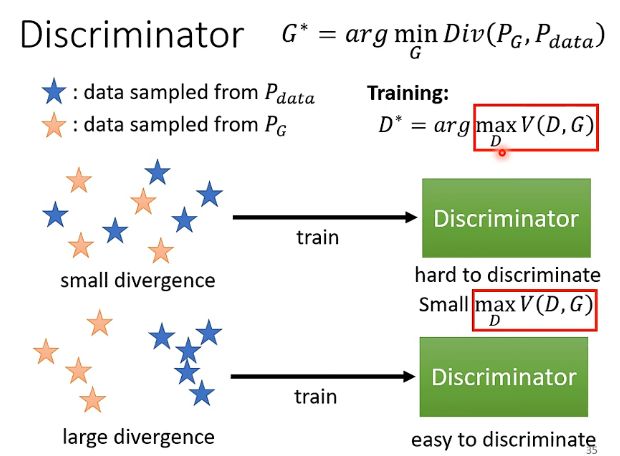
- 当两个分布很接近的时候,即它们之间的divergence很小的时候,辨别器很难完全地将它们分开,因此实际上它训练参数之后得到的最大化的 V ( G , D ) V(G,D) V(G,D)还是比较小的,那么跟divergence比较小是对应的
- 当两个分布不接近,即它们之间的divergence很大的时候,辨别器就能够轻易地将它们分开,因此实际上它训练参数之后得到的最大化的 V ( G , D ) V(G,D) V(G,D)就会比较大的,那么跟divergence比较大是对应的
因此,divergence的值和 V ( G , D ) V(G,D) V(G,D)的值之间可以认为存在一定的正比例关系,那么我们在一开始中用到Div的目标函数就可以用 V ( G , D ) V(G,D) V(G,D)进行替换,即:

而我们之前说到了G和D之间对抗不断调整的过程实际上就是这个新的目标函数的求解过程。
2.2、JS divergence is not suitable
我们需要先了解一下为什么JS divergence存在问题,之后再来了解著名的WGAN。
首先,我们要明确 P G P_G PG和 P d a t a P_{data} Pdata它们之间相交的部分实在是太少了,具体的理由有两个:
- 它们都是高维空间中的能够表示为图片(或者说我们想要的动漫人脸)的向量,但是在高维空间中满足条件的向量只占非常小的一部分,例如可以认为它们分别只占二维空间中的一条直线或者曲线,那么它们之间相交之处只能是几个点而已(除非它们重合),那么就可以认为它们之间相交的部分实在特别少
- 我们是对真实的两个分布之间进行采样的,就算原始的真正的分布它们之间存在重叠的部分,但如果我们采样的不是特别多,不能够完全地描述出两个原来的分布,那还是可以找到一个分界将这两类采样出来的点完全分开,那么也可以认为它们是没有相交的部分的。
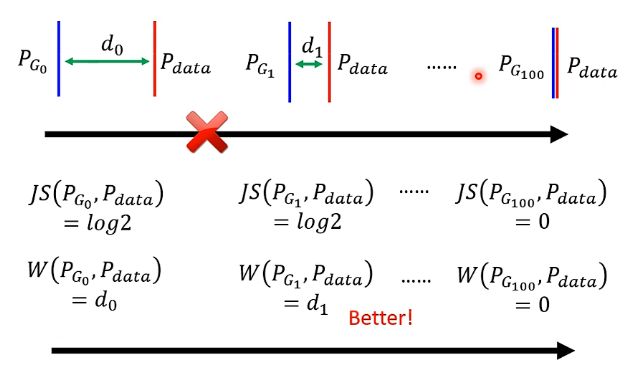
而JS divergence的特性在于如果两个分布没有交叠,计算出来永远时log2,可以看下图:
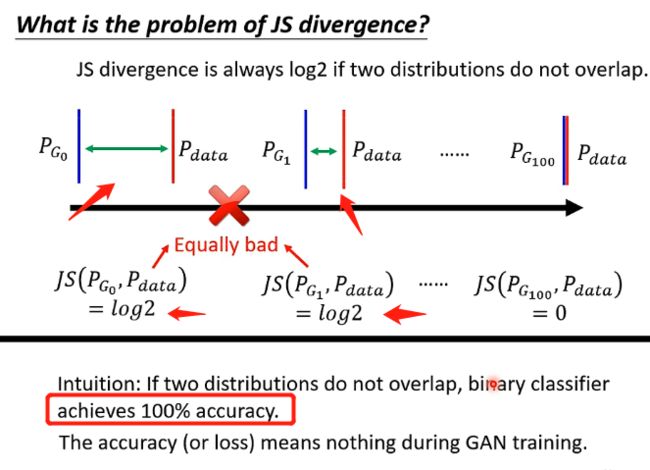
从图中可以看到,第二个情况明明比第一个情况更加接近,但是实际上JS计算出来的值还是一直都是log2,除非它们真的出现了交叠,才会计算出新的值,这样就导致假设我们在分布中采样的样本数不是非常非常多,那我们用之前类似于贝叶斯的思想来训练分类器的时候可以发现我们总是100%的正确率,因为根据这个JS就无法提供指导性的作用,它无法告诉机器说让两个分布越来越接近可以让损失函数越来越小,因此无法训练成功。
2.3、Wasserstein distance
Wasserstein distance是另一种衡量两个分布之间的距离,可以通俗的想象成两个分布分别是两堆土,如下图:
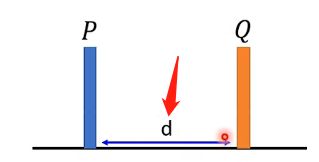
那么两个分布之间的距离就是用推土机将分布P推到分布Q的位置时经过的距离。但实际上的分布可能更复杂一点:
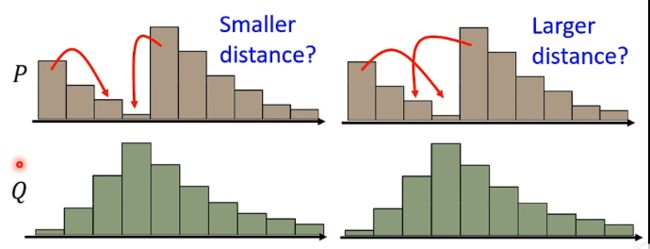
例如上图,那么从分布P经过推土机的操作得到分布Q可以有很多种方式,可以认为每一种方式的d都不一样,那么Wasserstein distance的定义就是穷举所有的d,选取里面最小的d来作为真正的Wasserstein distance。那么也就是说我们还需要解这个Wasserstein distance的优化问题。
那么将计算距离更换为Wasserstein distance,便可以让我们发现在两个分布越来越接近的时候计算出来的距离越来越小,这样就可以指导我们的网络往这个方向去调整。
2.4、WGAN
当用Wasserstein distance取代JS divergence的时候,此时的GAN就称为WGAN。那么现在的问题就在于Wasserstein distance这个距离应该怎么距离计算呢?推导过于复杂,结论就是解下面这个函数,最终得到的值(目标函数的值)就是我们要计算的两个分布之前的Wasserstein distance:
m a x D ∈ 1 − L i p s c h i t z { E y − P d a t a [ D ( x ) ] − E y − P G [ D ( x ) ] } max_{D\in 1-Lipschitz}~\{E_{y-P_{data}}[D(x)]-E_{y-P_G}[D(x)]\} maxD∈1−Lipschitz {Ey−Pdata[D(x)]−Ey−PG[D(x)]}
这跟前面那个将目标函数Div更换成贝叶斯那个是同理的。
但是此处对于评估函数D还是有限制的,要求它是足够平滑的,不能够是具有剧烈变化的,否则例如下图:
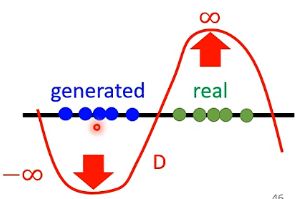
只要这两堆没有重叠,就会将取值推向两个无穷的极端。
3、生成器效能评估与条件式生成
3.1、训练的问题
虽然已经将评估分布的距离更换成Wasserstein distance,但实际上GAN还是很难训练的,主要原因是生成器和辨别器它们彼此之间是相互砥砺、相互进步的,只要其中有一个训练发生了差错,那么另外一个肯定也无法继续提升,即只要其中一个在某次更新过程中没有更新,那么可能整个训练过程就坏掉了,无法再继续提升下去了。
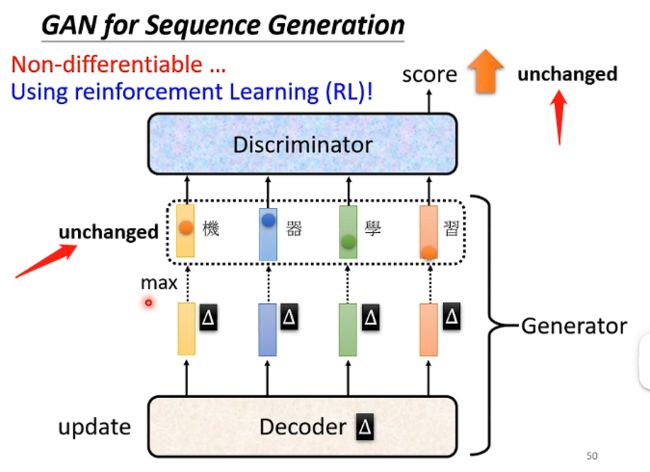
特别是在将GAN用于生成文字的时候更难训练,例如在下图的模型中,我们产生了一段文字然后让辨别器查看文字是否是机器生成的并且打分,那么如果采用梯度下降的方法我们给生成器的参数带来了一点微小的变动,但由于各个输出向量都是采用取那个概率最大的文字作为输出的方式,因此微小的变化计算能够改变各个概率的值,但一般不会使得概率最大的文字改变,也就是输出没有发生改变,那么也就没有办法进行微分。
另外一个需要注意的点是应该如何评估GAN这种模型所生成结果的好坏呢。
3.2、评估生成器的好坏
这个问题没有一个标注性的答案,在GAN刚出现的时候,对于生成结果都是由人们自己来判断效果,这样主观性太强而且不够稳定。
现在对于生成图像的系统,可以再另外训练一个影像辨识系统来进行验证,例如生成的都是狗的图片,那么在这个影像辨识系统中接受输入,并且输出是概率分布,那我们就希望这个概率分布能够有一个分类,其概率能够越接近于1越好,就说明大部分图片我们将其归为一类,这样就说明可能生成效果还是不错的;而如果分成了很多类而且概率都差不多,那么说明生成效果就不好了。但是在这个评估策略中可能会遇到一个问题,称为Mode Collapse,可以通过下图直观理解,这种问题就是说虽然能够产生出效果比较好的结果,但可能那些结果具有很高的相似性,例如左下方的红色星星都集中的同一个点,很难像真实的分布能够较为广阔;在右边的例子中很可能产生的图像越来越相似,例如我指出来的那几张基本上都一样了,这种情况可能训练到最后只能够输出这一张图片而已。

产生这个现象的原因可以直观理解为:例如左下方的例子中,聚集的地方可以称为辨别器的盲点,只要产生在这附近的结果那么辨别器就无法辨认出来是假的,因此生成器就会不断产生这附近的图片。
另外一个问题是Mode Dropping,它比上一个问题更难侦测到,先来直观说明问题的内容,看下图:

就是虽然产生的数据能够不集中于某一处,分布看起来也还行,但是只学习到真实分布的一部分,另外一部分完全没有学习到,从下图的例子中可以很明显地看出来,虽然在两次产生的图像集中看起来好像有分布得很均匀,但是我们可以发现第一次只有白人,第二次只有黄种人,这就说明它没有学习到真正的分布,只学习到其中某一部分的分布,黑色人种的图片完全没有学习到。

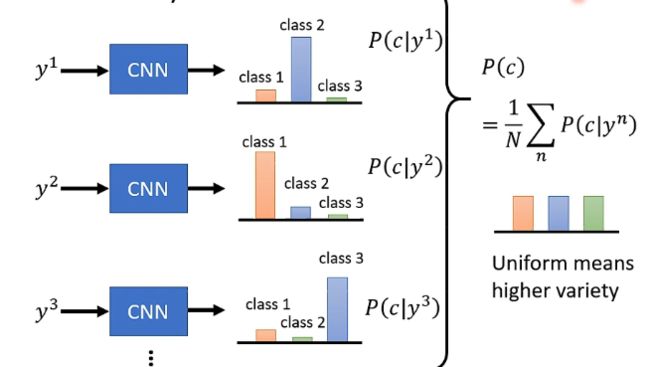
那么评估结果多样性的一个思路是:将产生的所有图片都丢进去一个图像分类系统之中,那么每张图片就会产生对应的分布,我们再将所有分布求和取平均,那么如果得到的最终分布越平坦,就说明多样性越好,如下图:
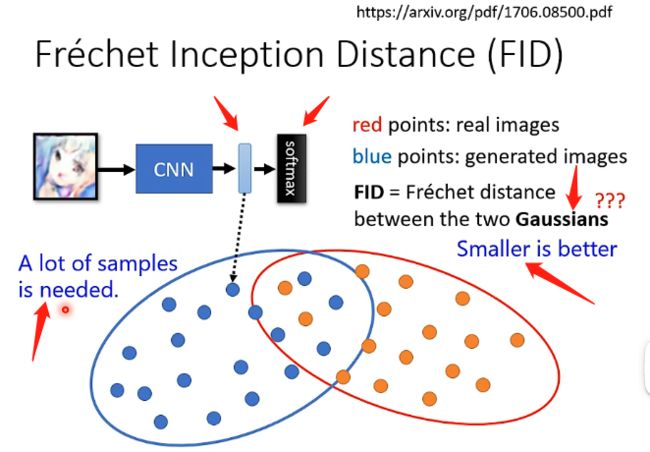
另外一种测量指标成为FID,其具体的做法为:将图片放进去影像辨识系统之后,由于要进行分类因此肯定最后会经过一个softmax环节,我们将进入softmax之前的最后一层的的输出的这个向量,用来代表这个图片,那么对于真实的图片和生成的图片就都可以得到很多的向量,再将这些向量来计算FID(具体的计算方法就不拓展了),那么FID的评价标准是两个分布越接近其数值就越小,不过计算过程中会假设两个都是高斯分布。这个方法还有一个问题就是为了模拟出真实的分布,它需要很多的样本经过影像辨识系统得到的向量,因此计算量会很大。
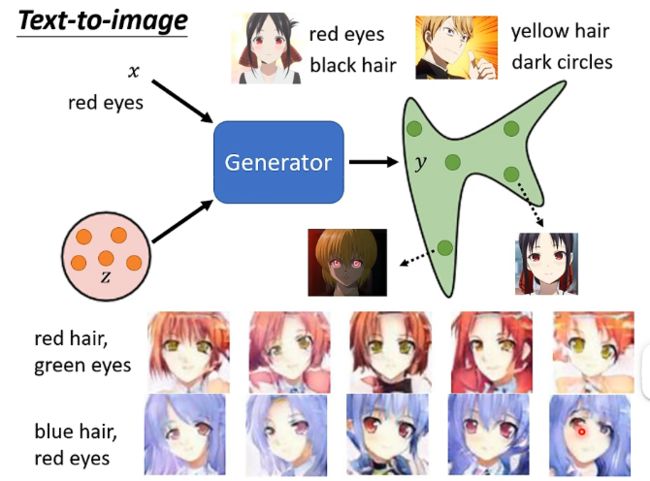
4、Conditional Generator
Conditional GAN就是输入的时候除了之前从分布中采样得到的z之外,还有一个x,它可以用x来指定y的输出,例如应用于文字转图像的例子:
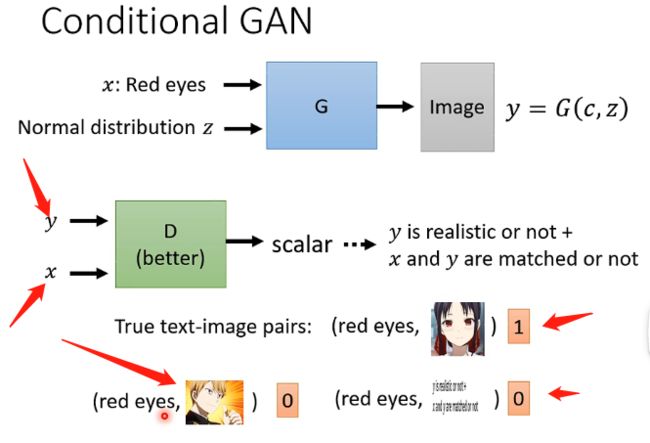
那么这种情况下的训练过程也要进行调整,在训练辨别器的时候不仅仅要输入产生的图片,更要输入原始输入x,并且需要将它们进行配对,才能够让机器学习到看到这样配对的文字和图像才能够给高分,而往往在训练辨别器时还要加入一部分特殊的训练资料,即我们将原本数据中图和文字已经配对好的样本,都进行打乱,使得文字和图像并没有关系,那么用这种样本告诉机器说看到这样的样本也要给低分,那么机器才能够一方面学习到图像要接近于真实动漫人脸,还学习到要满足我们的输入x,如下图:
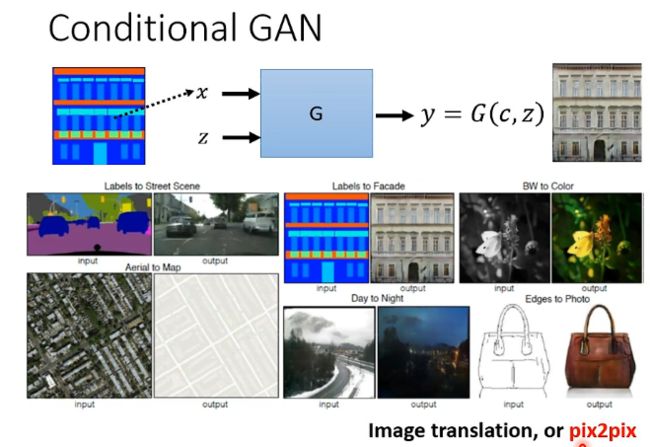
还有另外一种应用是输入x是一张影像,然后希望能够产生另一张图片来满足我们的需求,例如:
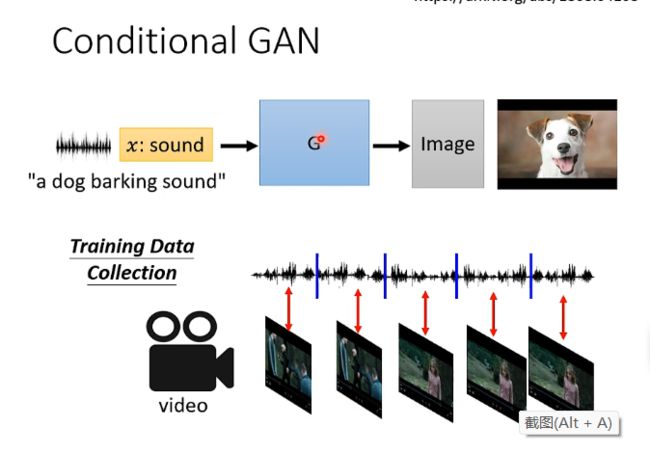
还有例如听一段声音然后产生一张图片,即:
5、Cycle GAN
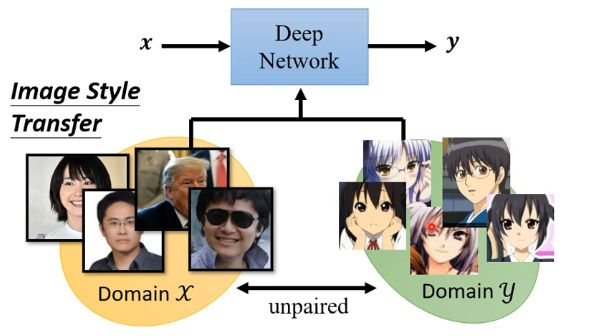
在之前的各种普通的网络结构中,一般样本都是有对应的标注的,即x和y之前的成对的,但是在一些训练任务中它们之间并没有成对,例如下图的影像风格转换的任务中,x是真实的人脸,而y要求是人脸的动漫版本,那么在这个任务中就不具有成对的x和y来进行训练了:
那么实际上,GAN在这种不成对的样本的训练任务中是可以发挥作用的。那么应该怎么应用呢?如果直接套用GAN的思想,如下图:
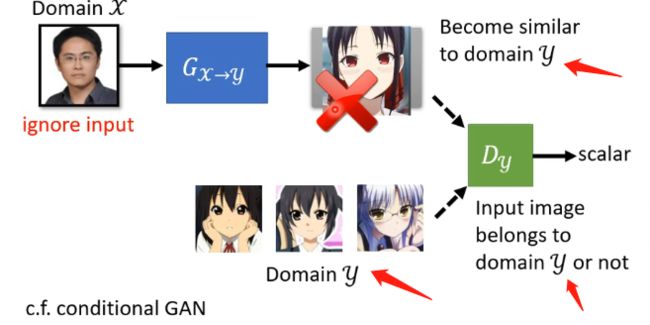
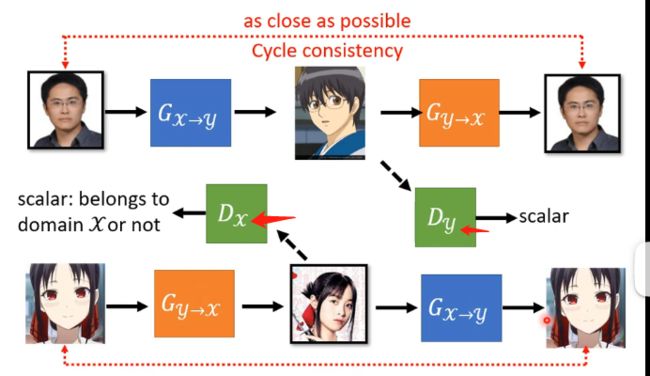
因为GAN的辨别器要求是辨别你生成器的输出是不是y的那个分布,那这个就会导致生成器发现只要生成一张是动漫人脸的图片就可以让辨别器打高分,而这个动漫人脸是否和输入的人脸相似这并不重要,可以说生成器完全忽略了输入,那么怎么解决这个问题呢?就用到了Cycle GAN,其具体的做法可以看下图:
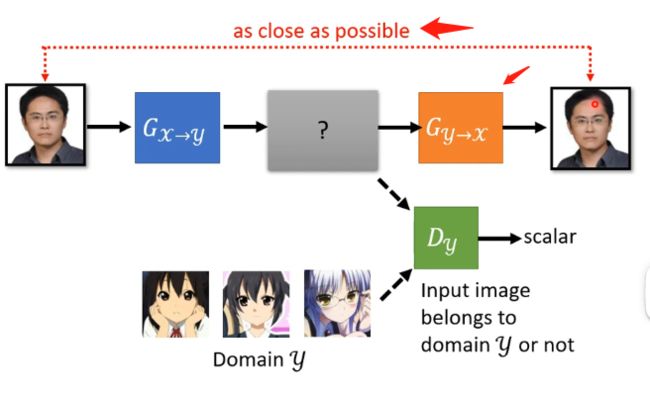
其最重要的特点在于训练了两个生成器,多出来的生成器用于将第一个生成器生成的动漫人脸还原成真实的人脸,而我们训练的时候会要求原先的人脸和还原的人脸越接近越好。
但这个Cycle GAN好像并没有限制中间产生的动漫人脸必须和原先的人脸非常地相像,例如机器可能学习到原始人脸戴着眼镜就将眼睛去掉然后加上一颗痣,第二个生成器就学习到看到一颗痣就将痣去掉然后加上一副眼镜,这说明在Cycle GAN是没有对原始输入和产生的动漫人脸的相似度进行限制,但在实际训练中这种情况其实很少发生,可以认为网络架构不会去做这么复杂的问题,它会尽量去输出相似的东西而已,这也是在理论上和实际上的不同。
并且这个Cycle GAN可以是双向的,例如下图: