GAN与WGAN——对抗神经网络
GAN不是进行分类或图像识别语音识别等功能的,它的功能是通过深度学习网络学习到某些特征,然后自动生成符合这种特征的数据(比如图像等)。
GAN
- Generator
- Discriminator

Generator是一个神经网络,负责将一组随机噪声生成一个图像
Discriminator也是一个神经网络,它负责判断由Generator生成的图像与真实图像之间的差距,并返回这个图像是真是假的判断。
无论是Generator还是Discriminator,它们的目的都是学习到真实Training Set 图像中的特征,从而生成一个越来越像真图像的假图像,或者判断假图像是假图像。
说起来可能有些拗口,大致就是这个意思,通过不断的Train,最终可达到让人眼也无法分辨出一个图像到底是真实的拍摄出来的图像还是仅仅是由计算机自动生成的图像。很神奇是不是,这就是人工智能的魅力!
How to train?
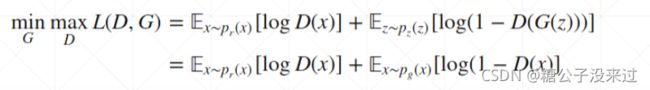
整个网络的损失函数,要让Discriminator的Loss最大,以便可以准确的分辨真假,要让Generator的Loss最小,以便可以生成足以混淆Discriminator的图像。
后面第一项表示Discriminator的期望值,第二项表示Generator的期望值
示例图像
下面是GAN刚提出时能够生成的图像

可以看到还是有点糊的,那时候的GAN生成的图像的效果与当时同期发表的VAE的效果差不多,但是经过了几年的发展后,GAN已经达到了VAE望尘莫及的地步。

这些是后来经过发展后的GAN生成的图片,看起来与真实的图片几乎一样,Magic!
接下来的问题是,如果固定住G,D的最优情况能训练成什么样呢?如果固定住最优的D*,G能训练成什么样呢?
Where will D go(fixed G)?

通过公式的计算推导可以知道,D*(x)=Pr(x)/[Pr(x)+Pg(x)]
KL Divergence V.S. JS Divergence
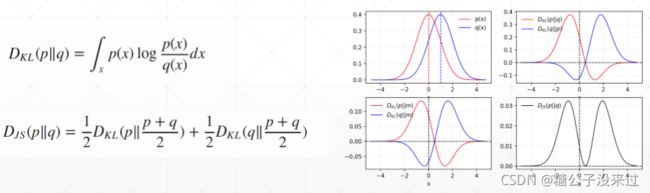
这里引入了一种新的度量,JS Divergence,它是将之前的KL Divergence 的公式分成两部分,互换pq进行计算
Where will G go(after D*)?

Djs(pr||pg)>=0,那么L(G, D*)的最小值就是2log2(Loss应该是没有负数) ,当pr=pg时
由之前的公式知道,当pr = pg时,D*(x) = 1/2,符合直觉(Intuition)

在GAN发表之后,GAN的各种改进版本如雨后春笋般出现,字母表都快不够用了。。。有一些还是非常重要的突破。
DCGAN
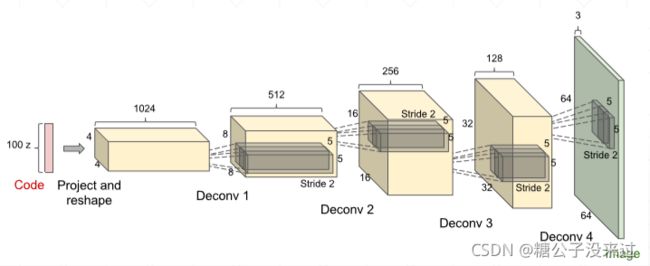
Transposed Convolution
Transposed Convolution是一种用于把小shape的图像通过卷积放大的卷积方式。在之前的学习中,卷积操作一般是将图像缩小,我们可以通过padding的方式使得图像shape保持不变,但是在GAN中的Generator中,我们是要将一组随机噪声放大成一张图像的shape,Transposed Convolution的操作由此诞生。

Training Stability
GAN容易出现训练不稳定现象,也就是随着训练的深入,生成的图片并没有明显的变清楚。
Why?
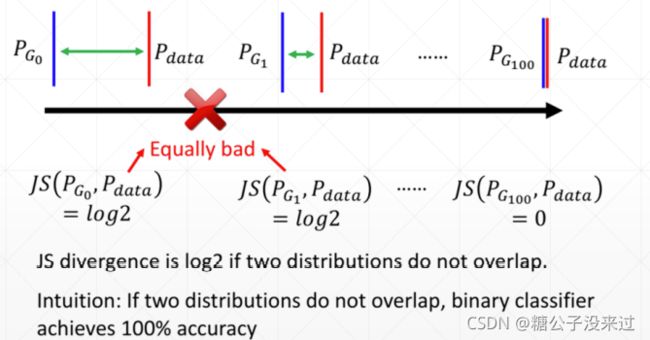
在大多数情况下,PG和Pdata都不是overlap的,也就是数据分布不重合
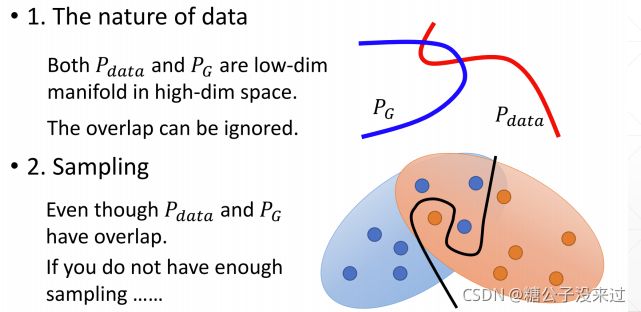
在下面这个例子中,红线用来表示Pdata,蓝线用来表示PG,θ是可以变动的,但是当θ!=0时,通过公式
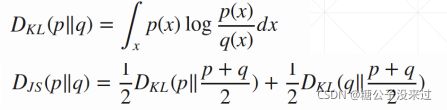
可以计算得到KL Divergence为∞,而JS Divergence 的值为 log2。这时无论是KL 还是 JS 都不能取得梯度使得PG得到很好的更新,也就出现了Training 不稳定的现象

在下面的图示中可以看到当mean of q 大于20后无论是KL还是JS都会出现梯度弥散的情况
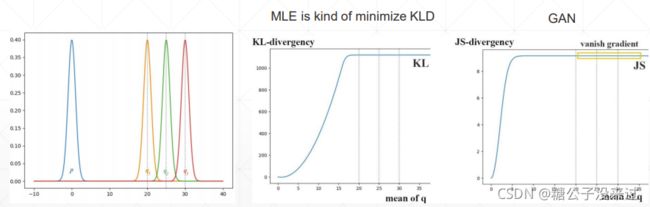
Gradient Vanishing(梯度弥散)
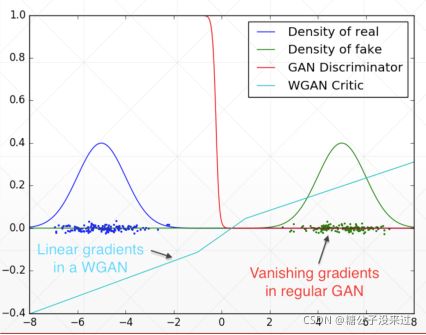
左边蓝色是real data 的分布,右侧绿色的是fake img 的分布,红色线可以看出GAN 的Discriminator的梯度变化,在没有overlap的情况下,梯度为0
可以看到在新的WGAN的方法下,已经把梯度优化成一个线性的形状
WGAN
如何改变?
Earth Mover,搬土
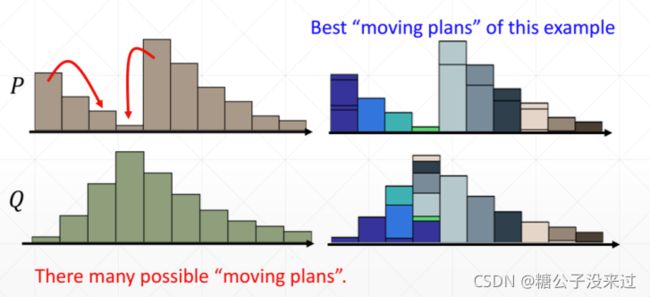
找到搬土的最佳方案,∑步数*搬土数量 最小者
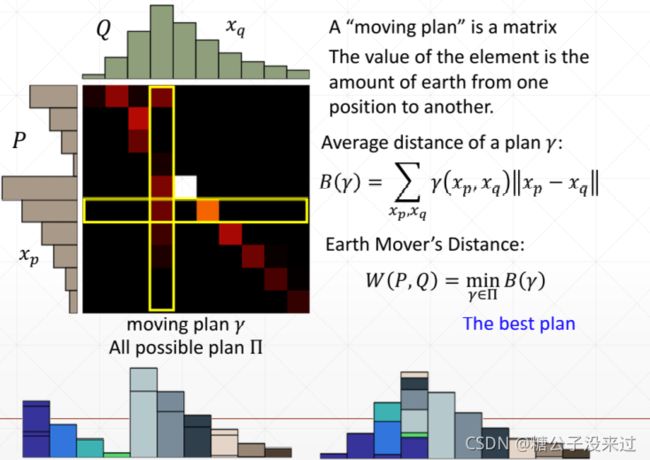
上面的“搬土”方法就是计算Wasserstein Distance的思想,Wasserstein Distance是用来替代KL 和JS Divergence方法的一种方法,是一种新的度量方法
How to compute Wasserstein Distance

Weight Clipping的方法是将w硬性控制在某范围之中,像是一种工程上的做法

也类似于Regularization
WGAN-Gradient Penalty
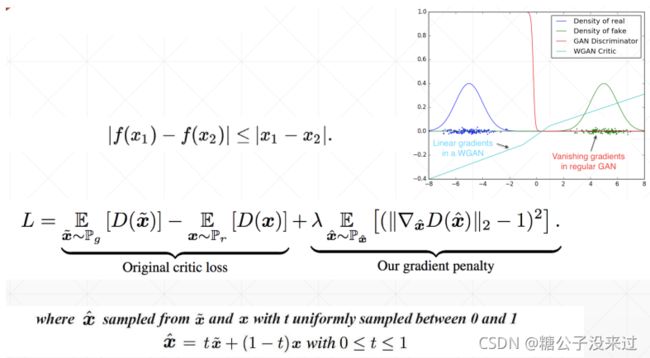 Gradient Penalty的方法是在原始的GAN的损失函数后面加上一项,带有超参数λ
Gradient Penalty的方法是在原始的GAN的损失函数后面加上一项,带有超参数λ
x-hat 是介于data和generator产生的图像数据之间的数据
More stable

这是几种算法的效果的一个对比,可以看到DCGAN train的还是很快效果还是很好的,但是Gradient Penalty 版的比较稳定
最后
GAN和WGAN就介绍到这。事实上里面的一些理论推导过程有些我还没有弄清楚,希望通过之后的学习能够加深理解,再进一步!