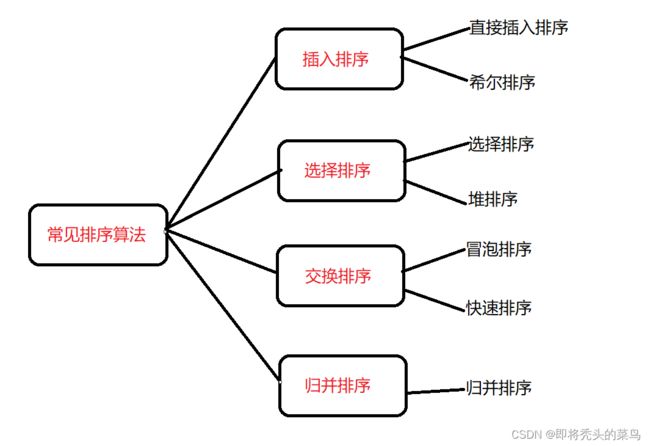
七大排序算法(插排,希尔,选择排序,堆排,冒泡,快排,归并)--图文详解
目录
引言
一、直接插入排序
概念
图文解析
1、起始状态
2、循环时
3、最后细节
代码实现
代码
复杂度
稳定性
二、希尔排序
概念
图文解析
1、算法实现
2、设置增量
3、进行交换
4、缩小增量
代码实现
代码
时间复杂度
空间复杂度
稳定性
三、直接选择排序
概念
图文解析
1、初始化
2、交换
代码实现
代码
时间复杂度
空间复杂度
稳定性
四、堆排序
概念
代码实现
代码
时间复杂度
空间复杂度
稳定性
五、冒泡排序
概念
图文解析
代码实现
代码
时间复杂度
空间复杂度
稳定性
六、快速排序
概念
图文解析
Hoare法
挖坑法
前后指针法
代码实现
Hoare法代码
挖坑法代码
前后指针法代码
快排优化
三数取中法
三数取中代码
加入插排
时间复杂度
空间复杂度
稳定性
七、归并排序
概念
图文解析
代码实现
代码
时间复杂度
空间复杂度
稳定性
引言
排序算法,或许是我们日常最常见也是使用频率最多的算法。比如你在电商网站买东西,推荐商品往往基于相似度或者基于销售量等维度排序。我们每日接收的邮件是程序中按照时间进行排序好的,我们点外卖时候推送的列表是按照评分和地理位置进行排序的。搜索引擎检索内容也是按照一定的相似度算法进行排序好才呈现给你的,所以搜索引擎实际上就是一个排序引擎。
本篇文章通过图例的方式逐一讲解最常使用的七大排序算法。
我下面所写的排序都按从小到达排
一、直接插入排序
概念
插入排序是一种原址(in-place)排序,原址的意思就是对于任何的输入数据序列都可以在不占用或者只占用常量的额外存储空间的情况下完成排序。插入排序对于已经排序好的数据可以实现O(n)的最佳排序时间,对于逆序的数据序列排序运行时间最差O(n^2).
总结:插入排序就是把待排序的每条记录按照值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列 。
插入排序的理解,我们可以想象一下,我们与朋友一起玩扑克牌。在摸牌阶段,从牌堆中一张张的取牌,为了保持手里面一副牌一直保持有序状态,每次都会把新取得的扑克牌与手头的牌进行比较,比较的方式是从右向左,找到合适的位置,插入即可,这就是一种典型的插入排序。唯一需要注意的是,排序算法中的插入实际上是一种逐个交换实现的,而不是直接插到指定的位置。
图片来自于百度图片。
图文解析
1、起始状态
最开始的时候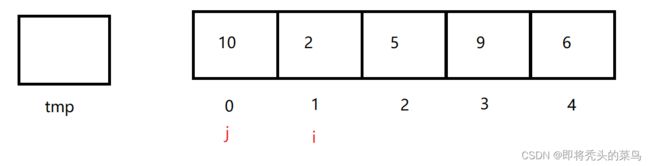
2、循环时
将 arr[i] 放到 tmp 里,让 arr[j] 和 tmp 中的值比较大小,要是 arr[j] > tmp,那么就交换值,要 是小于的话就跳出这次循环。例如下图:(请大家比对最开始的图片想一下)
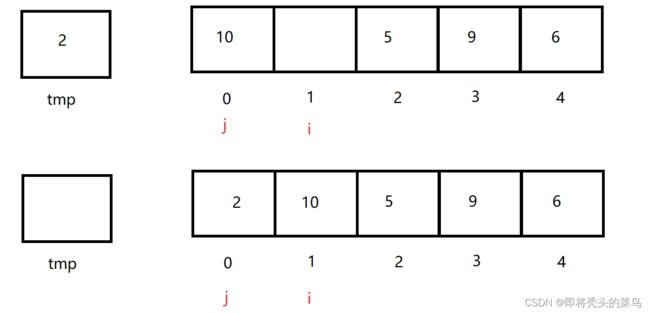
3、最后细节
一直这样慢慢的比下去,到最后还需要把tmp里的值放回 arr[j+1]。如下图需要放回。
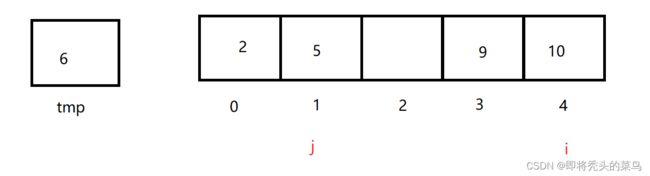
代码实现
代码
public static void insertSort(int[] arr) {
for (int i = 1; i < arr.length; i++) {
int tmp = arr[i];
for (int j = i - 1; j >= 0; j--) {
if (arr[j] > tmp) {
arr[j+1] = arr[j];
}else {
break;
}
arr[j+1] = tmp;
}
}
}复杂度
时间复杂度:
- 最好 O(n) 有序
- 最好 O(n^2) 逆序
- 结论:对于直接插入排序,数据越有序越快。
- 应用场景:当数据基本上是有序的时候,使用直接插入排序。
空间复杂度:
O(1)
稳定性
稳定的排序
二、希尔排序
概念
希尔排序是把序列按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量的逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个序列恰好被分为一组,算法便终止。
图文解析
1、算法实现
希尔排序需要定义一个增量,这里选择增量为 gap = length / 2,缩小增量以 gap = gap / 2 的方式,这个增量可以用一个序列来表示,{n/2,(n/2)/2…1},称为增量序列,这个增量是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。
2、设置增量
对于一个无序序列[8,9,1,7,2,3,5,4,6,0]来说,我们初始增量为 gap = length / 2 => 5,所以这个序列要被分为5组,分别是[8,3],[9,5],[1,4],[7,6],[2,0],对这5组分别进行直接插入排序,则小的元素就被调换到了前面,然后再缩小增量 gap = gap / 2 => 2。
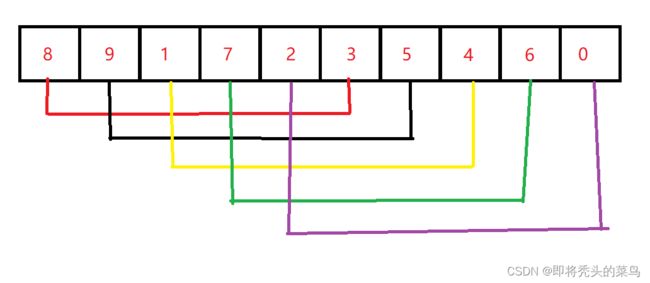
3、进行交换
下图是第一次交换后的结果,大家观察,希尔排序的一次交换能交换几个值,就不是直接插入排序那样需要一个个的去交换,这样就节省了时间。
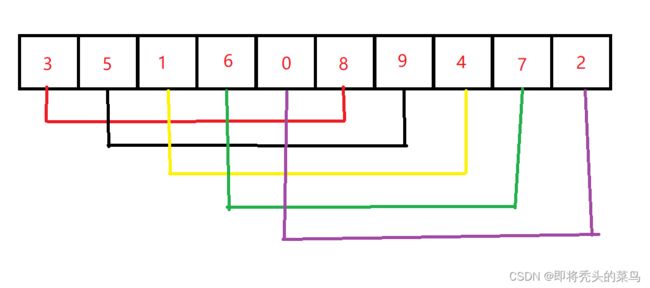
4、缩小增量
缩小增量后第二次交换:
序列再次被分为2组,分别是 [3,1,0,9,7] 和 [5,6,8,4,2],再对这两组进行直接插入排序,那么序列就更加有序了。
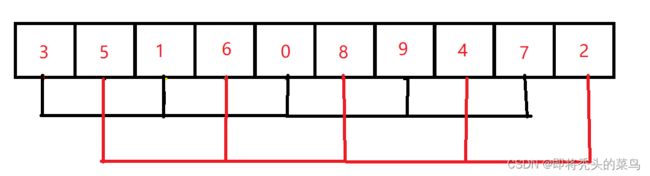

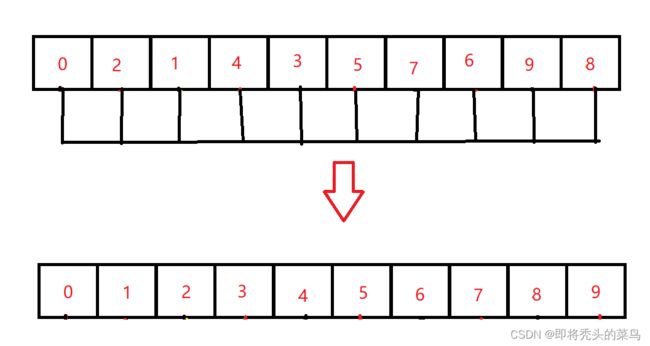
然后再缩小增量,gap = gap / 2 => 1,这时整个序列就被分为一组即 [0,2,1,4,3,5,7,6,9,8],最后再进行调整,就得到了有序序列 [0,1,2,3,4,5,6,7,8,9]。
代码实现
代码
确定增量代码
public static void shellSort(int[] arr) {
int gap = arr.length;
while (gap > 1) {
shell(arr,gap);
gap /= 2;
}
shell(arr,1);
}排序代码
public static void shell(int[] arr, int gap) {
for (int i = gap; i < arr.length; i++) {
int tmp = arr[i];
for (int j = i - gap; j >= 0; j -= gap) {
//加上等号 就是不稳定
if(arr[j] > tmp) {
arr[j+gap] = arr[j];
}else {
break;
}
arr[j+gap] = tmp;
}
}
}时间复杂度
参考资料:《数据结构(C语言版)》--- 严蔚敏
希尔排序的分析是一个复杂的问题,因为它的时间是所取“增量”序列的函数,这涉及一些数学上尚未解决的难题。因此,到目前为止尚未有人求得-种最好的增量序列,但大量的研究已得出一-些局部的结论。如有人指出,当增量序列为 dlta[k] = 2^(-k+1) -1时,希尔排序的时间复杂度为 O(n^3/2) 其中 t 为排序趟数, 1 ≤ k ≤ t ≤ [log2(n+1)]。还有人在大量的实验基础上推出,当n在某个特定范围内,希尔排序所需的比较和移动次数约为n^1.3,当n→∞时,可减少到n(log2n)2。 增量序列可以有各种取法中,但需注意:应使增量序列中的值没有除1之外的公因子,并且最后一个增量值必须等于1。
总结来说就是经过很多大佬的计算,希尔排序的时间复杂度没有一个确定的值,确定的大概范围是:O(N^1.3 - N^1.5)
空间复杂度
O(1)
稳定性
不稳定的排序
三、直接选择排序
概念
直接选择排序是一种简单直观的排序算法。它的工作原理是:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零,选择排序是一种不稳定的排序方法。
图文解析
1、初始化
假设 arr[0] 是数组最小值,然后分别与其他几个数进行比较,如果遇到比其小的就与其交换,经过一轮循环后最小的数就在最始端。重复上述操作直至剩余最后一个数。
2、交换
设 minIndex 是最小值的下标,让 arr[minIndex] 和 arr[j] 比较,寻找 arr[i] 后面的最小值,来放到前面。
第一次交换:
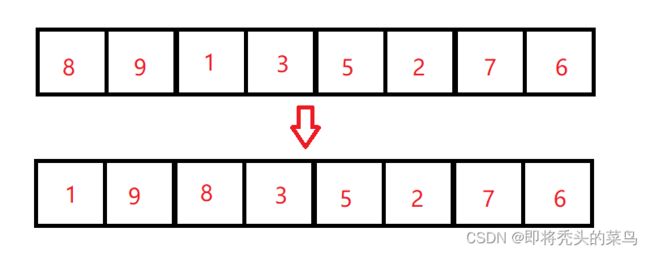 第二次交换:
第二次交换:
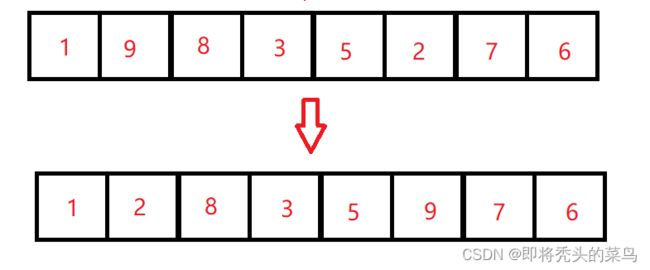
重复上述操作,直至最后一个数。
代码实现
代码
特点: 当数组趋于有序的时候,运行速度就会很快.
public static void selectSort(int[] arr) {
for (int i = 0; i < arr.length; i++) {
int minIndex = i;
for (int j = i+1; j < arr.length; j++) {
if (arr[minIndex] > arr[j]) {
minIndex = j;
}
}
swap(arr,minIndex,i);
}
}
//交换函数
public static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}时间复杂度
根据代码就能看出有两层循环,不管是无序数组还是有序数组。所以
时间复杂度:O(n^2)
空间复杂度
O(1)
稳定性
不稳定的排序
四、堆排序
概念
关于堆排大家可以看看我这篇关于堆的博客: 堆--图文详解_即将秃头的菜鸟的博客-CSDN博客
代码实现
代码
public static void heapSort(int[] arr) {
createHeap(arr);
int end = arr.length-1;
while (end >= 0) {
swap(arr,0,end);
shiftDown(arr,0,end);
end--;
}
}
public static void createHeap(int[] arr) {
for (int parent = (arr.length-1-1)/2; parent >= 0; parent--) {
shiftDown(arr, parent, arr.length);
}
}
public static void shiftDown(int[] arr, int parent, int len) {
int child = parent*2 + 1;
//保证有左孩子
while (child < len) {
if (child < len && arr[child] < arr[child+1]) {
child++;
}
if (arr[child] > arr[parent]) {
swap(arr, child, parent);
parent = child;
child = parent*2 + 1;
}else {
break;
}
}
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}时间复杂度
O(n*logn)
空间复杂度
O(1)
稳定性
不稳定的
五、冒泡排序
概念
冒泡排序的英文Bubble Sort,是一种最基础的交换排序。之所以叫做冒泡排序,因为每一个元素都可以像小气泡一样,根据自身大小一点一点向数组的一侧移动。
图文解析
原理:
每一趟只能确定将一个数归位。即第一趟只能确定将末位上的数归位,第二趟只能将倒数第 2 位上的数归位,依次类推下去。如果有 n 个数进行排序,只需将 n-1 个数归位,也就是要进行 n-1 趟操作。而 “每一趟 ” 都需要从第一位开始进行相邻的两个数的比较,将较大的数放后面,比较完毕之后向后挪一位继续比较下面两个相邻的两个数大小关系,重复此步骤,直到最后一个还没归位的数。
冒泡排序就懒得画图了,从C语言写到现在.
就有一点优化, 在每一层循环中间可以检查是否还需要交换,不需要交换直接进入下一躺循环.
代码实现
代码
public static void bubbleSort(int[] arr) {
for (int i = 0; i < arr.length-1; i++) {
boolean flg = false;
for (int j = 0; j < arr.length-1-i; j++) {
if (arr[j] > arr[j+1]) {
swap(arr, j, j+1);
flg = true;
}
}
if (!flg) {
break;
}
}
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}时间复杂度
O(n^2)
空间复杂度
O(1)
稳定性
稳定的排序
六、快速排序
概念
快速排序之所以快,是相对于冒泡排序,不再是只有相邻的数之间交换,它是可以跳跃式的交换,交换的距离会变得大的多,所以速度就提高了,当然也会存在最坏的结果,仍然是跟冒泡一样是相邻的两数之间进行了交换,所以它最差的时间复杂度和冒泡排序是一样的.
图文解析
Hoare法
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
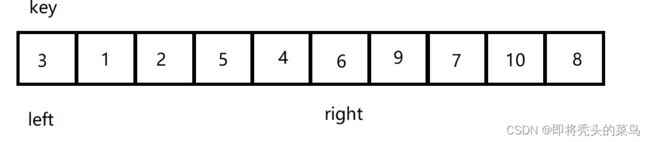
数组最开始的状态:

每次由 right 先走, 遇到比 key 小的停下, 然后 left 走, 遇到比 key 大的停下, 交换两值,如下图:
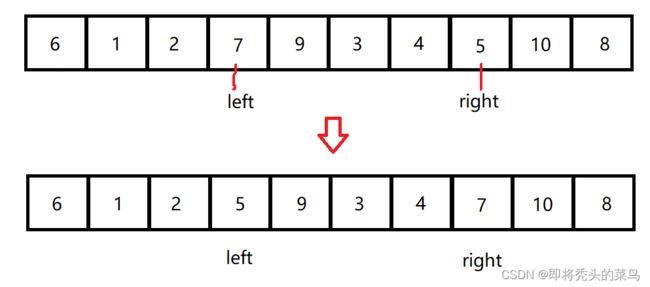
然后呢, right 继续往前走, left 继续往后走, 直到两个相遇:
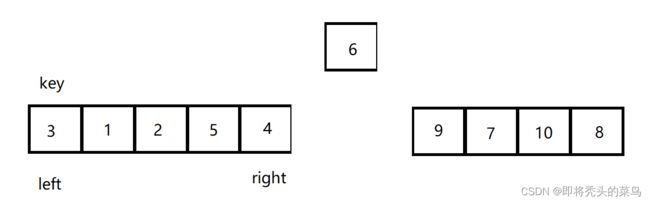
这个时候再让 key 和 left 交换, 就达到了目的, 使得 key 左边是比 key 小的数字, key 右边是比 key 大的数字,效果如下:
然后再以 key 为基准, 将 6 的左右两边继续排序,有点类似于二叉树.
继续让 right 先走, 碰到比 key 小的停下, 再让 left 走, 碰到比 key 大的停下, 然后交换.
这样一步步走下来, 最后就能得到有序的数列:

注意:
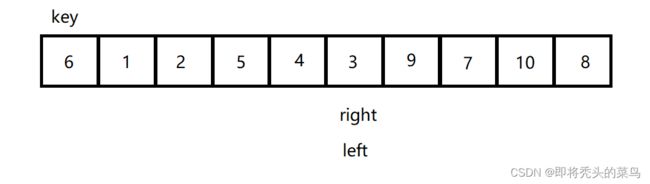
左边做 key , 为啥右边先走呢?
假设左边先走, 那么就会出现这样的情况:

如上图所示,最后 6 和 9 交换,但是当 9 换到前面去了数组还是无序的状态,所以这样是不行的. 只能从右边开始走.
挖坑法
最开始的时候把 key-6 当作坑位, 把 6 取出来, 此时当作坑位里面没放数据,
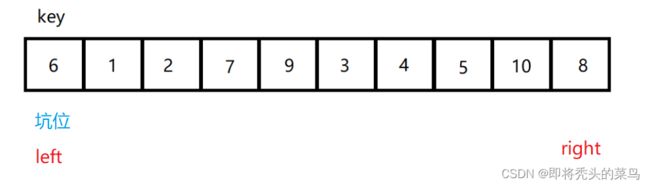
让 right 向左先走, 遇到比 key 小的数字就把 right 的值拿出来放进坑位中去, right 变成新的坑位, 然后让 left 向后走, 找到比 6 大的数字放进坑位中, 然后 left 位置又空出来变成一个坑位.
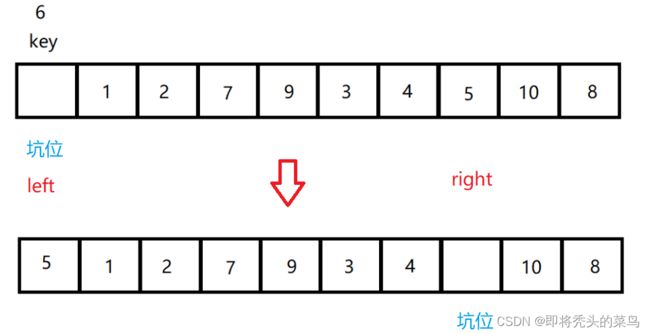
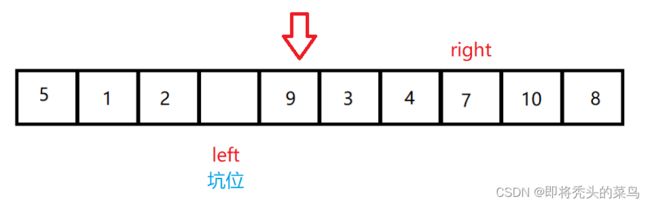
最后就是这样的情况 : 需要把开始拿出来的 6 给补进去.
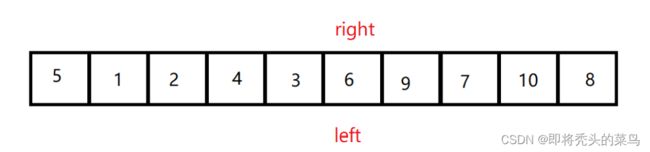
前后指针法
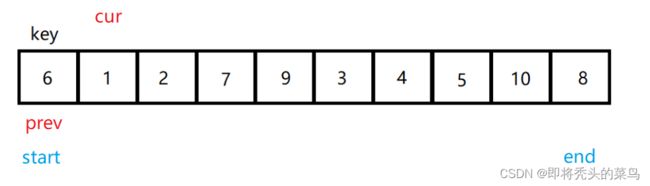
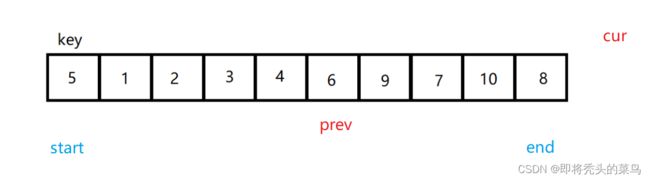
还是将第一个数字作为基准, 设置两个指针, cur 在前先走, prev 在后, 当 cur 位置的值不等于 key 位置的值, 那么就让 cur 和 prev 交换, 这样一步步走下去.
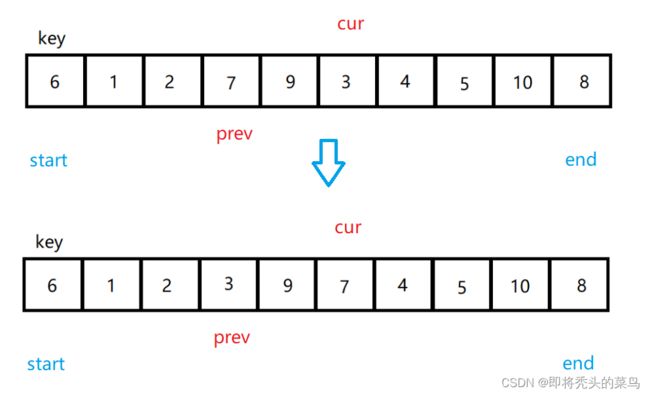
注意这个时候:
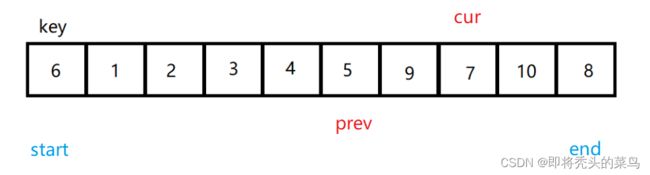
下面 cur 后一直往后走, 因为后面没有比 6 小的值, 所以后面就是 5 和 6 换.
代码实现
Hoare法代码
public static void quickSort(int[] array) {
quick(array,0,array.length-1);
}
public static void quick(int[] arr, int left, int right) {
//只有一个节点 大于号 ->有可能没有子树
if (left >= right) {
return;
}
int pivot = partitionHoare(arr,left,right);
quick(arr,left,pivot-1);
quick(arr,pivot+1,right);
}
/**
* Hoare法 找基准
* @param arr
* @param start
* @param end
* @return
*/
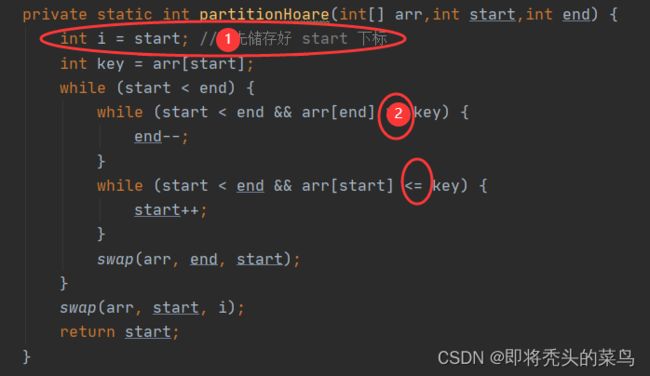
private static int partitionHoare(int[] arr,int start,int end) {
int i = start; //事先储存好 start 下标
int key = arr[start];
while (start < end) {
while (start < end && arr[end] >= key) {
end--;
}
while (start < end && arr[start] <= key) {
start++;
}
swap(arr, end, start);
}
swap(arr, start, i);
return start;
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}细节
1.要事先存储好 start 的下标.
2.这里为什么能加等号?
假设数组是这种情况:
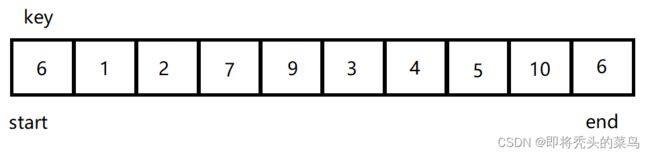
要是没有 = 的话, 6 就不大于 6 , 这里就会一直死循环.
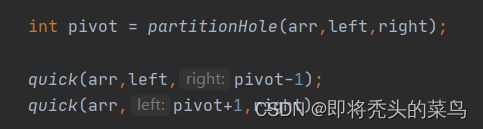
挖坑法代码
public static void quickSort(int[] array) {
quick(array,0,array.length-1);
}
public static void quick(int[] arr, int left, int right) {
//只有一个节点 大于号 ->有可能没有子树
if (left >= right) {
return;
}
int pivot = partitionHole(arr,left,right);
quick(arr,left,pivot-1);
quick(arr,pivot+1,right);
}
/**
* 挖坑法
* @param arr
* @param start
* @param end
* @return
*/
private static int partitionHole(int[] arr, int start, int end) {
int key = arr[start];
while (start < end) {
while (start < end && arr[end] >= key) {
end--;
}
arr[start] = arr[end];
while (start < end && arr[start] <= key) {
start++;
}
arr[end] = arr[start];
}
arr[start] = key;
return start;
}前后指针法代码
/**
* 前后指针法
* @param arr
* @param start
* @param end
* @return
*/
private static int partitionPointer(int[] arr, int start, int end) {
int prev = start;
int cur = start + 1;
while (start < end) {
if (arr[cur] < arr[start] && arr[++prev] != arr[cur]) {
swap(arr, cur, prev);
}
cur++;
}
swap(arr, prev, start);
return prev;
}注意
下图是Hoare法代码
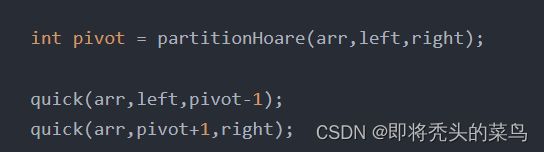
下图是挖坑法代码
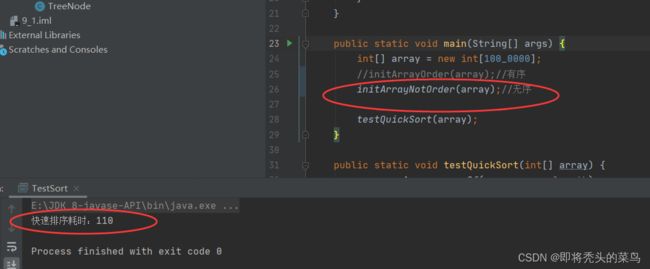
家人们,咱们看着代码说哦, 由代码我们可以知道这里是在进行递归, 那么在数组较大的时候,很大可能会发生栈溢出的情况,就像这种, 我创建数组来进行测试快排运行的时间和是否会造成栈溢出的情况 :
//无序数组
public static void initArrayNotOrder(int[] array) {
Random random = new Random();
for (int i = 0; i < array.length; i++) {
array[i] = random.nextInt(1000_0000);
}
}
//有序数组
public static void initArrayOrder(int[] array) {
for (int i = 0; i < array.length; i++) {
array[i] = array.length-i;
}
}
public static void main(String[] args) {
int[] array = new int[100_0000];
initArrayOrder(array);//有序
//initArrayNotOrder(array);//无序
testQuickSort(array);
}
public static void testQuickSort(int[] array) {
array = Arrays.copyOf(array,array.length);
long startTime = System.currentTimeMillis();
QuickSort.quickSort(array);
long endTime = System.currentTimeMillis();
System.out.println("快速排序耗时:"+(endTime-startTime));
}无序状态下:
有序状态下:
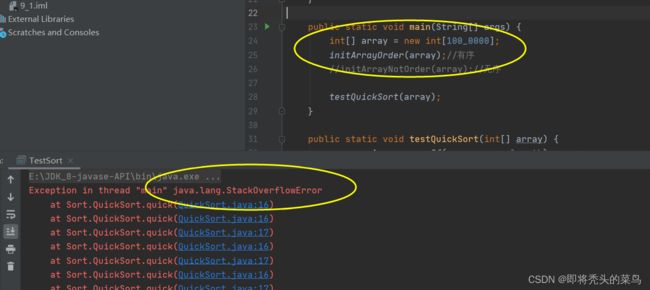
在有序状态下, 当数据较多的情况下, 就出现了栈溢出的情况, 这个时候就说明代码需要进行优化,并且说明快排在无序环境下更加适用.
所以我们就对快排进行了优化:
快排优化
三数取中法

如上图, 三数取中的意思就是, 在 left mid right 三个数之中选取中间的那个数作为基准, 以此来进行排序.
总的说来, 三数取中就是 解决递归深度问题 基本上 有了三数取中 你的待排序序列 基本上每次都是二分N*logn
三数取中代码
/**
* 三数取中法
* @param array
* @param left
* @param right
* @return
*/
private static int midNumIndex(int[] array,int left,int right) {
int mid = (left + right) / 2 ;
if (array[left] < array[right]) {
if (array[mid] < array[left]) {
return left;
}else if (array[mid] > array[right]) {
return right;
}else {
return mid;
}
}else {
if (array[mid] < array[right]) {
return right;
}else if (array[mid] > array[left]) {
return left;
}else {
return mid;
}
}
}加入插排
因为快排是递归进行的, 类似于二叉树最后几个元素的时候, 我们这个时候在进行递归其实是耗时的一件事情, 那么就想到了, 在数据较少的情况下, 插入排序更加适用于这种情况, 所以我们可以在最后元素较少的时候, 进行插入排序, 就能使得我们的运算更快.
private static void quick(int[] arr, int left, int right) {
//这里代表 只要一个节点了 大于号:有可能没有子树 有序 逆序
if(left >= right) {
return;
}
//小区间使用直接插入排序: 主要 优化了递归的深度
if(right - left + 1 <= 7) {
//使用直接插入排序
insertSort(arr,left,right);
return;
}
//三数取中:解决递归深度问题 基本上 有了三数取中 你的待排序序列 基本上每次都是二分N*logn
int index = midNumIndex(arr,left,right);
swap(arr,left,index);
int pivot = partitionHoare(arr,left,right);
quick(arr,left,pivot-1);
quick(arr,pivot+1,right);
}
public static void insertSort(int[] array, int start, int end) {
for (int i = start+1; i <= end; i++) {
int tmp = array[i];
int j = i-1;
for (; j >= start; j--) {
//加上等号 就是不稳定
if (array[j] > tmp) {
array[j+1] = array[j];
}else {
break;
}
}
array[j+1] = tmp;
}
}时间复杂度
O(N*logN) 理想 -> 每次都是均分待排序序列
空间复杂度
最好:O(logN)
最坏:O(N) 当N 足够大的时候 ,递归的深度就大
稳定性
不稳定的排序
七、归并排序
概念
核心思想:分治
当数据量很大的时候 nlogn 的优势将会比 n^2 越来越大,当 n=10^5 的时候,nlogn 的算法要比n^2 的算法快6000倍,那么6000倍是什么概念呢,就是如果我们要处理一个数据集,用 nlogn 的算法要处理一天的话,用 n^2 的算法将要处理 6020 天。这就基本相当于是15年。一个优化改进的算法可能比一个比一个笨的算法速度快了许多,这个时候归并排序就应运而生.
图文解析

看归并排序, 要是学了二叉树的话会更号理解一点.
假设数组最开始是这样的情况: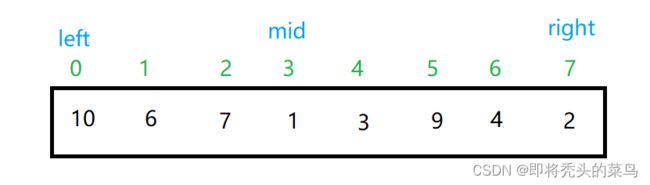
下面开始进行分治, 我取一半来画图, 大家应该就懂了.
也是设置了 left mid right 三个指针来更好的表示, 每次都递归下去, 这样一层一层的就会很简单了
代码实现
代码
public static void mergerSort(int[] array) {
mergeSortFunc(array,0,array.length-1);
}
private static void mergeSortFunc(int[] array,int left,int right) {
if(left >= right) {
return;
}
int mid = (left+right) / 2;
//1、分解左边
mergeSortFunc(array,left,mid);
//2、分解右边
mergeSortFunc(array,mid+1,right);
//3、进行合并
merge(array,left,right,mid);
}
private static void merge(int[] array, int start, int end, int midIndex) {
int[] tmpArr = new int[end-start+1];
int k = 0;//tmpArr数组的下标
int s1 = start;
int s2 = midIndex+1;
//两个归并段 都有数据
while (s1 <= midIndex && s2 <= end) {
if(array[s1] <= array[s2]) {
tmpArr[k++] = array[s1++];
}else {
tmpArr[k++] = array[s2++];
}
}
//当走到这里的时候 说明 有个归并段 当中 没有了数据 ,拷贝另一半的全部 到tmpArr数组当中
while (s1 <= midIndex) {
tmpArr[k++] = array[s1++];
}
while (s2 <= end) {
tmpArr[k++] = array[s2++];
}
//把排好序的数字 拷贝回 原数组
for (int i = 0; i < k; i++) {
array[i+start] = tmpArr[i];
}
}时间复杂度
O(n*logn)
空间复杂度
O(n)
稳定性
稳定的排序