【一起学数据结构与算法】0基础学习集合Map和Set(包含面试题)
目录
- 一、什么是Map和Set?
-
- 1.1 概念及场景
- 1.2 模型:
- 1.3 区别:
- 二、Map
-
- 2.1 注意事项
- 2.2 关于Map.Entry
- 2.3 Map的常用方法说明
- 2.4 TreeMap和HashMap的区别
- 2.5 遍历Map
- 三、Set
-
- 3.1 注意事项
- 3.2 Set接口中方法
- 3.3 TreeSet和HashSet的区别
- 3.4 遍历
- 四、面试题
-
- 4.1 只出现一次的数字
-
- 4.1.1 思路
- 4.1.2 代码
- 4.2 复制带随机指针的链表
-
- 4.2.1 思路
- 4.2.2 代码
- 4.3 宝石与石头
-
- 4.3.1 思路
- 4.3.2 代码
- 4.4 坏键盘打字
-
- 4.4.1 思路
- 4.4.2 代码
- 4.5 前K个高频单词
-
- 4.5.1 思路
- 4.5.2 代码
一、什么是Map和Set?
1.1 概念及场景
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。
以前常见的搜索方式有:
- 直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
- 二分查找,时间复杂度为O(logN),但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
- 根据姓名查询考试成绩
- 通讯录,即根据姓名查询联系方式
- 不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是一种适合动态查找的集合容器。
1.2 模型:
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
- 纯 key 模型,比如:
有一个英文词典,快速查找一个单词是否在词典中
快速查找某个名字在不在通讯录中 - Key-Value 模型,比如:
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
而 Map 中存储的就是 key-value 的键值对,Set 中只存储了 Key。
1.3 区别:
- Map是键值对,Set是值的集合,当然键和值可以是任何的值;
- Map可以通过get方法获取值,而set不能,因为它只有值;
- 都能通过迭代器进行for…of遍历;
- Set的值是唯一的可以做数组去重,Map由于没有格式限制,可以做数据存储
- map和set都是stl中的关联容器,map以键值对的形式存储,key=value组成pair,是一组映射关系。set只有值,可以认为只有一个数据,并且set中元素不可以重复且自动排序。
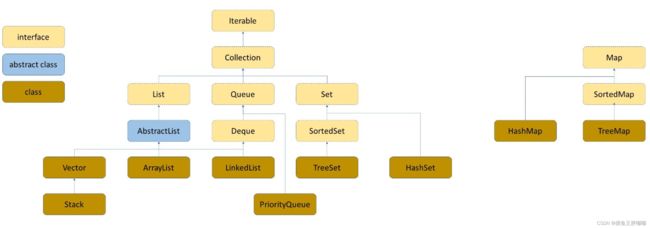
二、Map
Map是STL [1] 的一个关联容器,它提供一对一(其中第一个可以称为关键字,每个关键字只能在map中出现一次,第二个可能称为该关键字的值)的数据处理能力,由于这个特性,它完成有可能在我们处理一对一数据的时候,在编程上提供快速通道。
Map是一个接口类,该类没有继承自Collection,该类中存储的是
2.1 注意事项
- Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap
- Map中存放键值对的Key是唯一的,value是可以重复的
- Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
- Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
- Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
2.2 关于Map.Entry的说明
Map.Entry

注意:Map.Entry
2.3 Map的常用方法说明
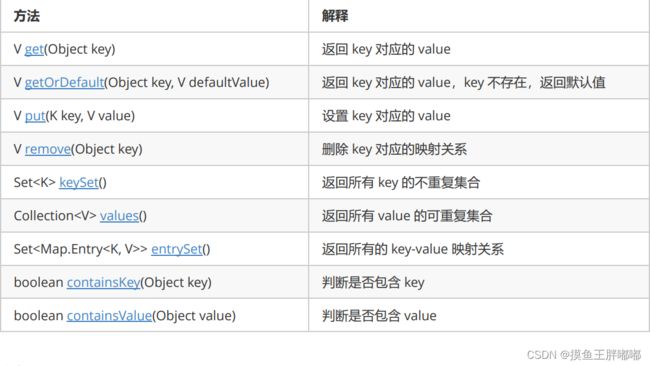
当我们通过get 获取的是Integer类型的值,让他赋值给整形会发生拆包,这里map中没有key,那么会返回null,此时拆包,就会发生空指针异常;
而使用 getOrDefault() , 如果map中没有key , 就会返回我们设置的默认值, 就不会进行拆包操作了 .
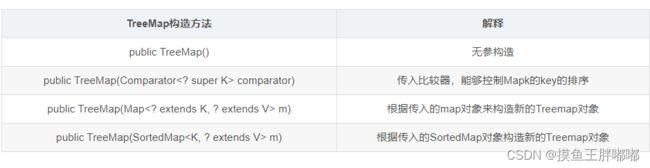
2.4 TreeMap和HashMap的区别
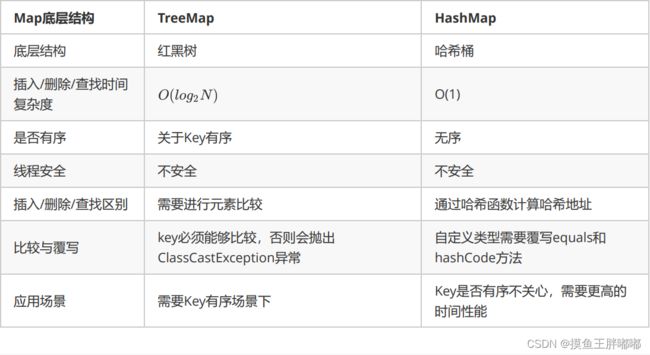
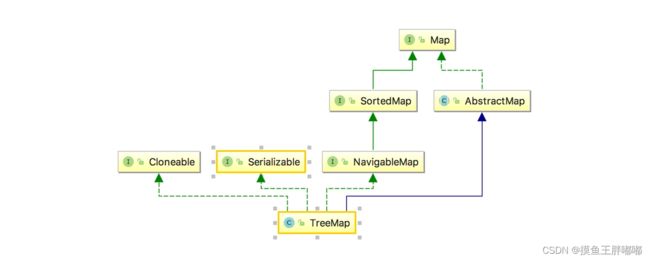
TreeMap继承关系图如下:
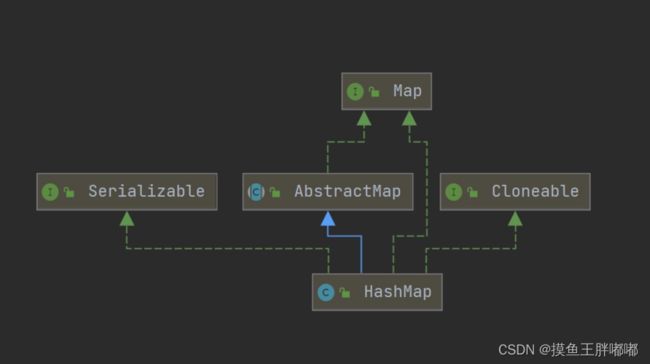
HashMap继承关系图如下:

2.5 遍历Map
Map当中没有实现Iterable接口, 所以遍历map的思路是将Map放到实现Iterable接口中的Set中即可;
- 通过keySet()方法
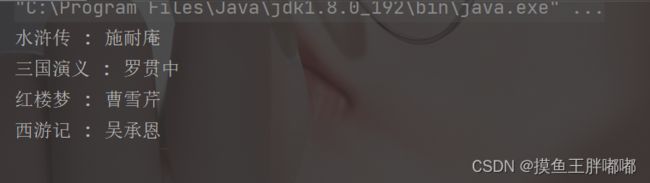
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("三国演义", "罗贯中");
map.put("西游记", "吴承恩");
map.put("水浒传", "施耐庵");
map.put("红楼梦", "曹雪芹");
Set<String> set = map.keySet();
for (String s : set) {
System.out.println(s+" : "+map.get(s));
}
}
- 通过entrySet()方法
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("三国演义", "罗贯中");
map.put("西游记", "吴承恩");
map.put("水浒传", "施耐庵");
map.put("红楼梦", "曹雪芹");
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
- 通过Map提供的forEach(BiConsumer)方法
BiConsumer是一个函数式接口,接受两个输入参数
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("三国演义", "罗贯中");
map.put("西游记", "吴承恩");
map.put("水浒传", "施耐庵");
map.put("红楼梦", "曹雪芹");
map.forEach(new BiConsumer<String, String>() {
@Override
public void accept(String key, String value) {
System.out.println(key+" : "+value);
}
});
}
三、Set
3.1 注意事项
- Set是继承自Collection的一个接口类
- Set中只存储了key,并且要求key一定要唯一
- Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
- Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入
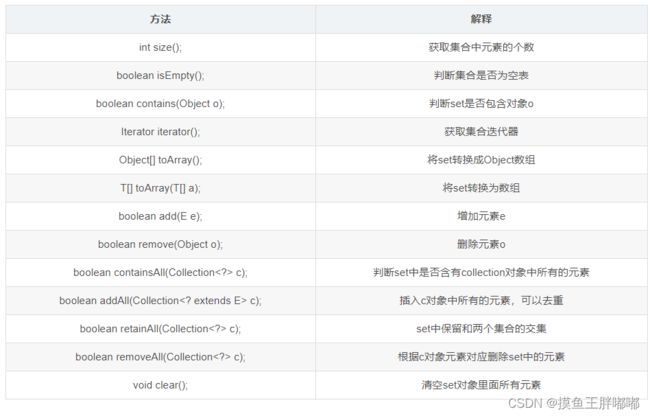
3.2 Set接口中方法
Set接口中大部分方法都是从Collection接口中扩展的,常用方法如下:
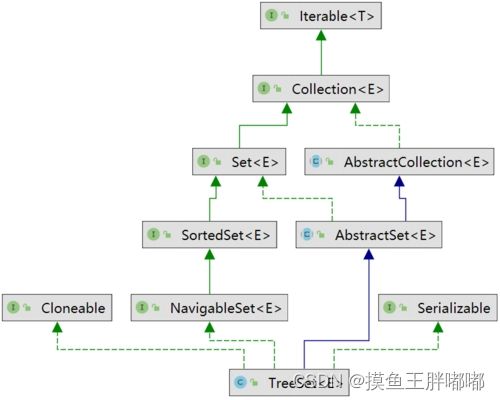
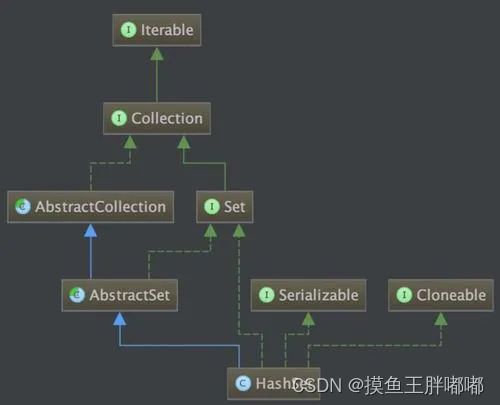
3.3 TreeSet和HashSet的区别

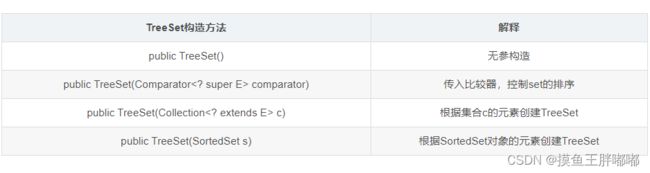
TreeSet继承关系图如下:
HashSet继承关系图如下:

3.4 遍历
- 通过迭代器遍历
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
Iterator<Integer> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next()+" ");
}
}

- foreach遍历
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
for (Integer integer : set) {
System.out.print(integer + " ");
}
}

- 通过Iterable接口中的forEach(Consumer)方法
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
set.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.print(integer+" ");
}
});
}

四、面试题
4.1 只出现一次的数字
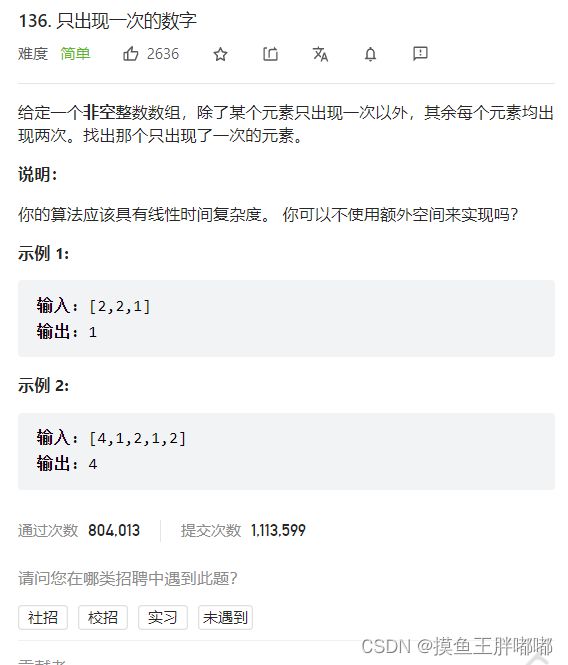
4.1.1 思路
- 思路1
- 思路一也是常规的思路: 使用异或,相同的两个数异或的结果是0,把数组所有数异或一遍,由于给定的数据一定有一个唯一的,所以最终得到的结果就是唯一数。
- 思路2
- 使用Set,Set中的元素不重复,遍历数组 , 判断Set中是否含有这个数,如果含有这个数,就将Set里面的这个数删除,否则存入该数,最终Set剩下的数为唯一数。
4.1.2 代码
class Solution { public int singleNumber(int[] nums) { HashSet<Integer> set = new HashSet<>(); for (int x : nums) { if (set.contains(x)) { set.remove(x); } else { set.add(x); } } for (int i = 0; i < nums.length; i++) { if (set.contains(nums[i])) { return nums[i]; } } return -1; } }4.2 复制带随机指针的链表
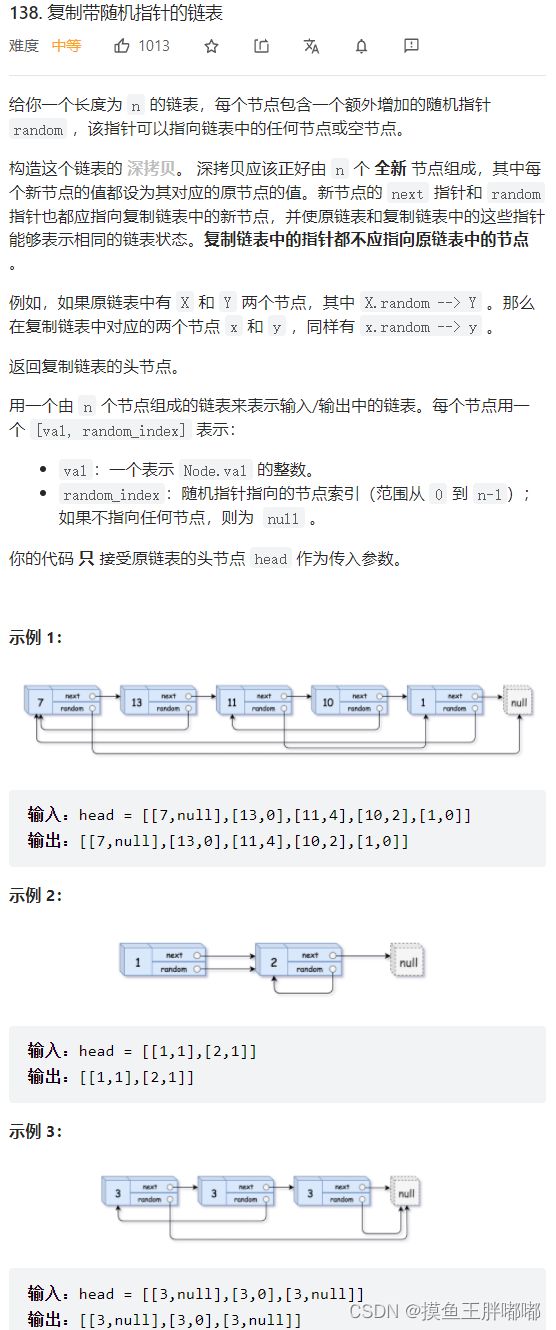
4.2.1 思路
使用Map,键值对为<已知链表结点地址, 复制链表结点地址>
第一次遍历已知链表时,创建复制链表对象的结点并将它们结点地址以<已知链表结点地址, 复制链表结点地址>键值对的形式存入Map中,然后第二次遍历已知链表,根据已知链表结点找到Map中对应复制链表的结点将复制链表结点链接起来
4.2.2 代码
/* // Definition for a Node. class Node { int val; Node next; Node random; public Node(int val) { this.val = val; this.next = null; this.random = null; } } */ class Solution { public Node copyRandomList(Node head) { Node cur = head; Map<Node, Node> map = new HashMap<>(); while (cur != null ) { Node node = new Node(cur.val); map.put(cur, node); cur = cur.next; } cur = head; while (cur != null) { map.get(cur).next = map.get(cur.next); map.get(cur).random = map.get(cur.random); cur = cur.next; } return map.get(head); } }4.3 宝石与石头

4.3.1 思路
把宝石放入Set中,设置以恶搞计数器,然后遍历石头判断宝石是否包含石头的字符,含有计算器就++;
4.3.2 代码
class Solution { public int numJewelsInStones(String jewels, String stones) { /* Map4.4 坏键盘打字
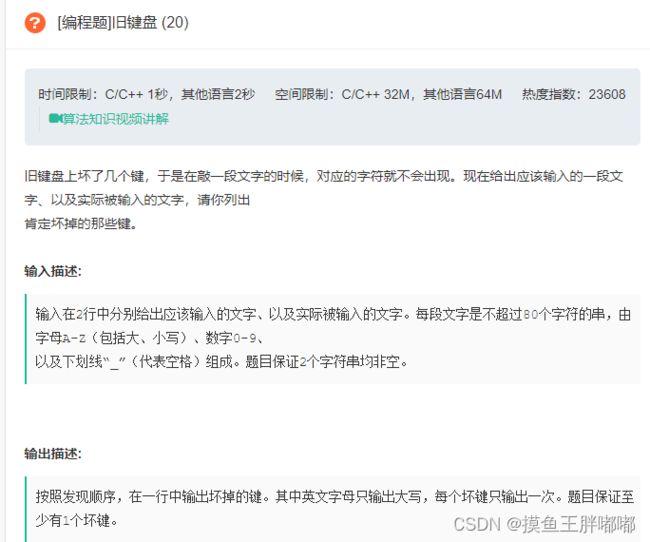
4.4.1 思路
假设预期输出的字符串为strInput,实际输出的字符串为strOutput,我们可以使用Set来存储我们实际输出的字符串,然后在遍历预期输出的字符串,如果发现不含在strOutput里面的就输出。
4.4.2 代码
import java.util.HashSet; import java.util.Scanner; import java.util.Set; public class Main { public static void func(String strInput, String strOutput) { Set<Character> set = new HashSet<>(); for (char ch : strOutput.toUpperCase().toCharArray()) { set.add(ch); } Set<Character> badSet = new HashSet<>(); for (char ch : strInput.toUpperCase().toCharArray()) { if(!badSet.contains(ch) && !set.contains(ch)) { badSet.add(ch); System.out.print(ch); } } } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); String strInput = scanner.nextLine(); String strOutput = scanner.nextLine(); func(strInput, strOutput); } }4.5 前K个高频单词

4.5.1 思路
- 使用Map统计单词词频。
- 利用topK求前k个词频频率最高的元素(所以需要小根堆),如果出现词频相同的单词,优先保留字典顺序在前的。
- 将堆里面的元素存入List,并使用Collections类工具逆序List。
- 返回List.
4.5.2 代码
class Solution { public static List<String> topKFrequent(String[] words, int k) { HashMap<String,Integer> map = new HashMap<>(); //1、统计每个单词出现的次数 map for (String s : words) { if(map.get(s) == null) { map.put(s,1); }else { int val = map.get(s); map.put(s,val+1); } } //2、建立一个大小为K的小根堆 PriorityQueue<Map.Entry<String,Integer>> minHeap = new PriorityQueue<>(k, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { if(o1.getValue().compareTo(o2.getValue()) == 0) { return o2.getKey().compareTo(o1.getKey()); } return o1.getValue()-o2.getValue(); } }); //3、遍历Map for (Map.Entry<String,Integer> entry : map.entrySet()) { if(minHeap.size() < k) { minHeap.offer(entry); }else { //说明堆中 已经放满了K个元素,需要看堆顶元素的数据 和当前的数据的大小关系 Map.Entry<String,Integer> top = minHeap.peek(); //判断频率是否相同,如果相同,比较单词的大小,单词小 的入堆 if(top.getValue().compareTo(entry.getValue()) == 0) { if(top.getKey().compareTo(entry.getKey()) > 0) { minHeap.poll(); minHeap.offer(entry); } }else { if(top.getValue().compareTo(entry.getValue()) < 0) { minHeap.poll(); minHeap.offer(entry); } } } } //System.out.println(minHeap); List<String> ret = new ArrayList<>(); for (int i = 0;i < k;i++) { Map.Entry<String,Integer> top = minHeap.poll(); ret.add(top.getKey()); } Collections.reverse(ret); return ret; } }