(详解各种trick)YOLOv4
原文链接:https://blog.csdn.net/justsolow/article/details/106401065
YOLOv4—(详解各种trick)
参考自(https://zhuanlan.zhihu.com/p/139764729)

前段时间大名鼎鼎的yolov4终于面世了,可是看过以后确实大失所望。不是说yolov4不好,只不过没有什么革命性的创新,相当于作者尝试了计算机视觉领域的各种花里胡哨的trick,然后给了一个最佳方案的trick组合。而且,这些东西对于实际的工业生产并没有什么用。。。。也就是落地基本不可能。
下面来仔细看一下文章中提到的各种trick。
论文地址
github
文中将前人的工作主要分为Bag of freebies和Bag of specials,前者是指不会显著影响模型测试速度和模型复杂度的技巧,主要就是数据增强操作,对应的Bag of specials就是会稍微增加模型复杂度和速度的技巧,但是如果不大幅增加复杂度且精度有明显提升,那也是不错的技巧。本文按照论文讲的顺序进行分析。由于每篇论文其实内容非常多,我主要是分析思想和一些核心细节。
本篇文章分析如下技术:random erasing、cutout、hide-and-seek、grid mask、Adversarial Erasing、mixup、cutmix、mosaic、Stylized-ImageNet、label smooth、dropout和dropblock。 下一篇分析网络结构、各种层归一化技术、以及其他相关技术。
1 数据增强相关
1.1 Random erasing data augmentation
论文名称:Random erasing data augmentation
论文地址
github
随机擦除增强,非常容易理解。作者提出的目的主要是模拟遮挡,从而提高模型泛化能力,这种操作其实非常make sense,因为我把物体遮挡一部分后依然能够分类正确,那么肯定会迫使网络利用局部未遮挡的数据进行识别,加大了训练难度,一定程度会提高泛化能力。其也可以被视为add noise的一种,并且与随机裁剪、随机水平翻转具有一定的互补性,综合应用他们,可以取得更好的模型表现,尤其是对噪声和遮挡具有更好的鲁棒性。具体操作就是:随机选择一个区域,然后采用随机值进行覆盖,模拟遮挡场景。

在细节上,可以通过参数控制擦除的面积比例和宽高比,如果随机到指定数目还无法满足设置条件,则强制返回。 一些可视化效果如下:

对于目标检测,作者还实现了3种做法,如下图所示(然而我打开开源代码,发现只实现了分类的随机擦除而已,尴尬)。

当然随机擦除可以和其他数据增强联合使用,如下所示。

torchvision已经实现
注意:torchvision的实现仅仅针对分类而言,如果想用于检测,还需要自己改造。调用如下所示:
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
- 1
1.2 Cutout
论文名称:Improved Regularization of Convolutional Neural Networks with Cutout
论文地址
github
出发点和随机擦除一样,也是模拟遮挡,目的是提高泛化能力,实现上比random erasing简单,随机选择一个固定大小的正方形区域,然后采用全0填充就OK了,当然为了避免填充0值对训练的影响,应该要对数据进行中心归一化操作,norm到0。
本文和随机擦除几乎同时发表,难分高下(不同场景下谁好难说),区别在于在cutout中,擦除矩形区域存在一定概率不完全在原图像中的。而在Random Erasing中,擦除矩形区域一定在原图像内。Cutout变相的实现了任意大小的擦除,以及保留更多重要区域。
需要注意的是作者发现cutout区域的大小比形状重要,所以cutout只要是正方形就行,非常简单。具体操作是利用固定大小的矩形对图像进行遮挡,在矩形范围内,所有的值都被设置为0,或者其他纯色值。而且擦除矩形区域存在一定概率不完全在原图像中的(文中设置为50%)
论文中有一个细节可以看看:作者其实开发了一个早期做法,具体是:在训练的每个epoch过程中,保存每张图片对应的最大激活特征图(以resnet为例,可以是layer4层特征图),在下一个训练回合,对每张图片的最大激活图进行上采样到和原图一样大,然后使用阈值切分为二值图,盖在原图上再输入到cnn中进行训练,有点自适应的意味。但是有个小疑问:训练的时候不是有数据增强吗?下一个回合再用前一次增强后的数据有啥用?我不太清楚作者的实现细节。如果是验证模式下进行到是可以。 这种做法效果蛮好的,但是最后发现这种方法和随机选一个区域遮挡效果差别不大,而且带来了额外的计算量,得不偿失,便舍去。就变成了现在的cutout了。
可能和任务有关吧,按照我的理解,早期做法非常make sense,效果居然和cutout一样,比较奇怪。并且实际上考虑目标检测和语义分割,应该还需要具体考虑,不能照搬实现。
学习这类论文我觉得最重要的是思想,能不能推广到不同领域上面?是否可以在训练中自适应改变?是否可以结合特征图联合操作?

1.3 Hide-and-Seek
论文名称:Hide-and-Seek: A Data Augmentation Technique for Weakly-Supervised Localization and Beyond
论文地址
github
可以认为是random earsing的推广。核心思想就是去掉一些区域,使得其他区域也可以识别出物体,增加特征可判别能力。和大部分细粒度论文思想类型,如下所示:
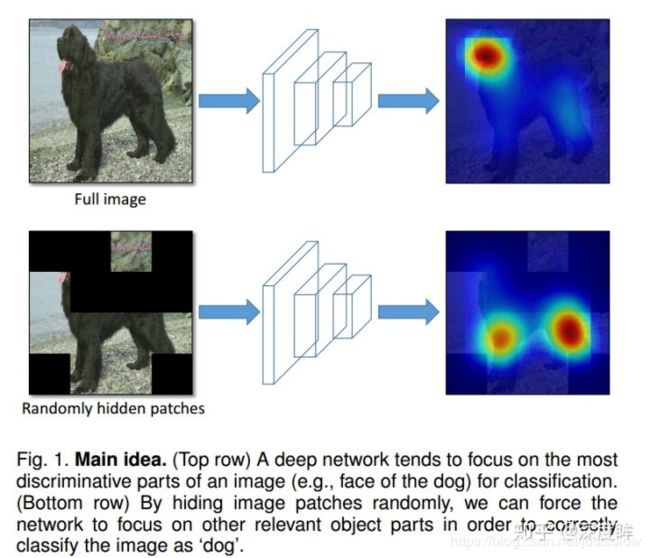
数据增强仅仅用于训练阶段,测试还是整图,不遮挡,如下所示。

做法是将图片切分为sxs个网格,每个网格采用一定概率进行遮挡,可以模拟出随机擦除和cutout效果。
至于隐藏值设置为何值,作者认为比较关键,因为可能会改变训练数据的分布。如果暴力填黑,认为会出现训练和测试数据分布不一致问题,可能不好,特别是对于第一层卷积而言。作者采用了一些理论计算,最后得到采用整个数据集的均值来填充造成的影响最小(如果采用均值,那么输入网络前,数据预处理减掉均值,那其实还是接近0)。
1.4 GridMask Data Augmentation
论文名称:GridMask Data Augmentation
论文地址
本文可以认为是前面3篇文章的改进版本。本文的出发点是:删除信息和保留信息之间要做一个平衡,而随机擦除、cutout和hide-seek方法都可能会出现可判别区域全部删除或者全部保留,引入噪声,可能不好。如下所示:

要实现上述平衡,作者发现非常简单,只需要结构化drop操作,例如均匀分布似的删除正方形区域即可。并且可以通过密度和size参数控制,达到平衡。如下所示:

其包括4个超参,如下所示:
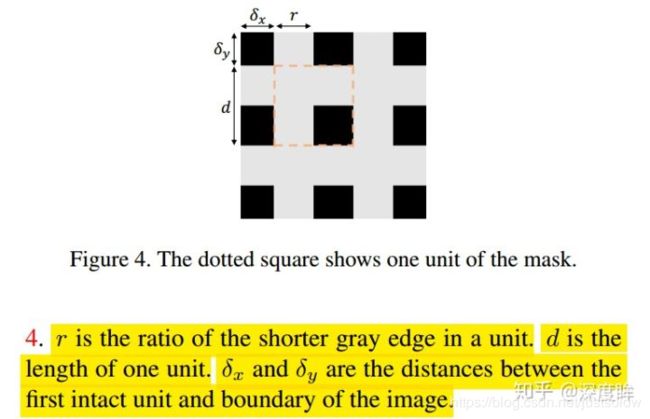
首先定义k,即图像信息的保留比例,其中H和W分别是原图的高和宽,M是保留下来的像素数,保留比例k如下,该参数k和上述的4个参数无直接关系,但是该参数间接定义了r:

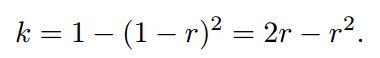
d决定了一个dropped square的大小, 参数 x和 y的取值有一定随机性.

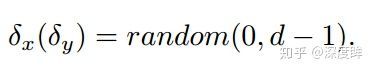
其实看起来,就是两个参数: r和d,r通过k计算而来,用于计算保留比例(核心参数),d用了控制每个块的大小。d越大,每个黑色块面积就越大,黑色块的个数就越少,d越小,黑色块越小,个数就越多。xy仅仅用于控制第一个黑色块的偏移而已。
对于应用概率的选择,可以采用固定值或者线性增加操作,作者表示线性增加会更好,例如首先选择r = 0.6,然后随着训练epoch的增加,概率从0增加到0.8,达到240th epoch后固定,这种操作也是非常make sense,为了模拟更多场景,在应用于图片前,还可以对mask进行旋转。这种策略当然也可以应用于前3种数据增强策略上。
1.5 object Region Mining with Adversarial Erasing
论文地址
本文在yolov4中仅仅是提了一下,不是重点,但是我觉得思想不错,所以还是写一下。
本文要解决的问题是使用分类做法来做分割任务(弱监督分割),思想比较有趣。如下所示:
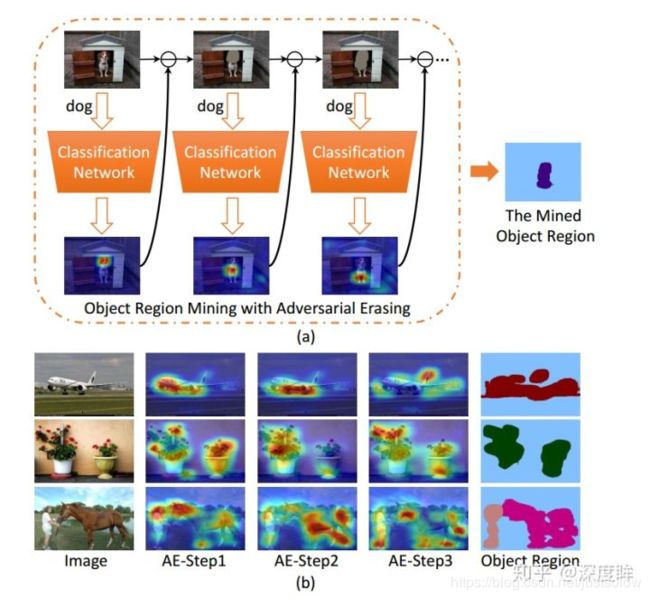
通过迭代训练的方式不断挖掘不同的可判别区域,最终组合得到完整的分割结果。第t次训练迭代(一次迭代就是指的一次完整的训练过程),对于每张图片都可以得到cam图(类别激活图),将cam图二值化然后盖在原图上,进行下一次迭代训练,每次迭代都是学习一个不同的可判别区域,迭代结束条件就是分类性能不行了,因为可判别区域全部被盖住了(由于该参数其实很难设置,故实验直接取3)。最后的分割结果就是多次迭代的cam图叠加起来即可。
本文是cvpr2017的论文,放在现在来看,做法其实超级麻烦,现在而言我肯定直接采用细粒度方法,采用特征擦除技术,端到端训练,学习出所有可判别区域。应该不会比这种做法效果差,但是在当时还是不错的思想。
但是其也提供了一种思路:是否可以采用分类预测出来的cam,结合弱监督做法,把cam的输出也引入某种监督,在提升分类性能的同时,提升可判别学习能力。
1.6 mixup
论文题目:mixup: BEYOND EMPIRICAL RISK MINIMIZATION
论文地址
mixup由于非常有名,我想大家都应该知道,而且网上各种解答非常多,故这里就不重点说了。
其核心操作是:两张图片采用比例混合,label也需要混合。

论文中提到的一些关键的Insight:
1 也考虑过三个或者三个以上的标签做混合,但是效果几乎和两个一样,而且增加了mixup过程的时间。
2 当前的mixup使用了一个单一的loader获取minibatch,对其随机打乱后,mixup对同一个minibatch内的数据做混合。这样的策略和在整个数据集随机打乱效果是一样的,而且还减少了IO的开销。
3 在同种标签的数据中使用mixup不会造成结果的显著增强
1.7 cutmix和Mosaic
论文名称:CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features
论文地址
github
简单来说cutmix相当于cutout+mixup的结合,可以应用于各种任务中。
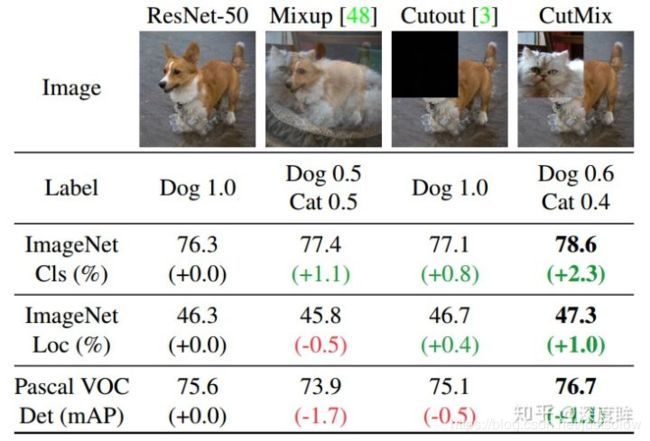
mixup相当于是全图融合,cutout仅仅对图片进行增强,不改变label,而cutmix则是采用了cutout的局部融合思想,并且采用了mixup的混合label策略,看起来比较make sense。
cutmix和mixup的区别是,其混合位置是采用hard 0-1掩码,而不是soft操作,相当于新合成的两张图是来自两张图片的hard结合,而不是Mixup的线性组合。但是其label还是和mixup一样是线性组合。作者认为mixup的缺点是:Mixup samples suffer from the fact that they are locally ambiguous and unnatural, and therefore confuses the model, especially for localization。

M是和原图大小一样的矩阵,只有0-1值, λ λ λ λλ \lambda λλλλ 参数可以控制裁剪矩形大小,

伪代码如下:

而Mosaic增强是本文提出的,属于cutmix的扩展,cutmix是两张图混合,而马赛克增强是4张图混合,好处非常明显是一张图相当于4张图,等价于batch增加了,可以显著减少训练需要的batch size大小。

1.8 Stylized-ImageNet
论文名称:ImageNet-trained cnns are biased towards texture; increasing shape bias improves accuracy and robustness
本文非常有意思,得到的结论非常有意义,可以指导我们对于某些场景测试失败的分析。本质上本文属于数据增强论文,做的唯一一件事就是:对ImageNet数据集进行风格化。
本文结论是:CNN训练学习到的实际是纹理特征(texture bias)而不是形状特征,这和人类的认知方式有所区别,如论文题目所言,存在纹理偏置。而本文引入风格化imagenet数据集,平衡纹理和形状偏置,提高泛化能力。
本文指出在ImageNet上训练的CNN强烈的偏向于识别纹理而不是形状,这和人的行为是极为不同的,存在纹理偏差,所以提出了Stylized-ImageNet数据,混合原始数据训练就可以实现既关注纹理,也关注形状(也就是论文标题提到的减少纹理偏向,增加形状偏向)。从而不仅更适合人类的行为,更惊讶的是提升了目标检测的精度,以及鲁棒性,更加体现了基于形状表示的优势。
文章从一只披着象皮的猫究竟会被识别为大象还是猫这个问题入手,揭示了神经网络根据物体的texture进行识别而非我们以为的根据物体的形状。
作者准备了6份数据,分别是正常的图片,灰色图,只包含轮廓的,只包含边缘的,只有纹理没有形状,纹理和形状相互矛盾(大象的纹理,猫的形状),对于第六份数据(纹理和形状冲突的数据),作者采用Stylized-ImageNet随机地将物体的纹理替换掉(也就是本文创新点),如下(c)所示:

采用了4个主流网络,加上人类直观评估。原图其实是作者除了物体外,其余都是白色背景的数据集,目的是去除干扰。 对于前面5份数据,采用原图和灰度图,神经网络都可以取得非常高的准确率,而对于只包含轮廓和只包含边缘的图片,神经网络的预测准确率则显著降低。更有意思的是,对于只包含纹理的图片,神经网络取得特别高的准确率。因而不难推断出,神经网络在识别中,主要是参考纹理信息而不是形状信息。
作者先构造数据集,然后再进行后面的深入实验,IN就是指的ImageNet,SIN是指的风格化的ImageNet,如下所示

SIN的特点是保留shape,但是故意混淆掉纹理信息。
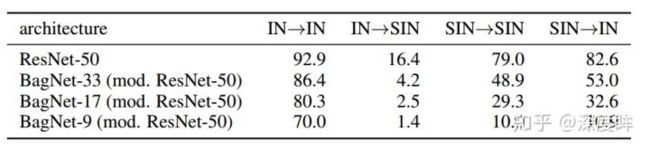
从上表的第一行可以看出,在原始图片IN上训练的模型不能适应去除纹理SIN的图片(IN-SIN),而使用去除纹理的图片进行训练和测试效果会差于使用原始图片进行训练和测试(SIN-SIN),这说明纹理信息在图像识别中确实起到了一定的作用,去除了纹理信息会提高模型识别的难度。最后,当我们使用去除纹理的图片进行训练而在原图进行测试的时候(SIN-IN),效果比在去除纹理的图片上面效果好(SIN-SIN)。
后面三行的实验采用的是第一行resnet的网络结构,其主要特征是限制模型的感受野,从而让模型无法学习到空间的信息,其对应的感受野分别是3333, 17 * 17,99,对于训练原始的图片,其结果测试误差跟没有加上感受野限制的误差差别不大,从而说明纹理信息起到主导作用(IN-IN),而对应去除掉纹理信息的图片,其测试结果下降十分明显(SIN-SIN),说明形状信息起到主要的作用,证明了SIN的模型确实在学习形状的信息而不是纹理的信息。这个实验是要说明提出的SIN数据集由于强制抹掉了固定纹理,网络训练难度增大,在没有限制感受野情况下可以学的蛮好,但是一旦限制了感受野就不行了,说明SIN模型学习到的不仅仅是纹理(因为纹理是局部的,如果依靠纹理来分类,那么准确率应该下降不了这么多),更多的是依靠shape分类,因为感受野外限制了,导致无法看到整个shape,并且通过更加限制感受野,SIN-SIN准确率下降更多可以发现。 也就是说SIN数据集由于替换掉了纹理,迫使网络学习shape和纹理,达到了本文目的。SIN上训练的ResNet50展示出更强的形状偏向,符合人类常理。
增强形状偏向也改变了表示,那么影响了CNN的性能和鲁棒性了吗?我们设置了两个训练方案:
1 同时在SIN和IN上训练
2 同时在SIN和IN上训练,在IN上微调。称为Shape-ResNet。

作者把去掉纹理的数据和原图一起放进去模型中进行训练,最后用原图进行finetune,发现这种方法可以提高模型的性能。Shape-ResNet超过了原始ResNet的准确率,说明SIN是有用的图像增强。
总结:CNN识别强烈依赖于纹理,而不是全局的形状,但是这是不好的,为了突出形状bias,可以采用本文的SIN做法进行数据增强,SIN混合原始数据训练就可以实现既关注纹理,也关注形状,不仅符合人类直观,也可以提高各种任务的准确率和鲁邦性。所以本文其实是提出了一种新的数据增强策略。是不是很有意思的结论?
1.9 label smooth
论文题目:Rethinking the inception architecture for computer vision
label smooth是一个非常有名的正则化手段,防止过拟合,我想基本上没有人不知道,故不详说了,核心就是对label进行soft操作,不要给0或者1的标签,而是有一个偏移,相当于在原label上增加噪声,让模型的预测值不要过度集中于概率较高的类别,把一些概率放在概率较低的类别。
2 特征增强相关
2.1 DropBlock
论文题目:DropBlock: A regularization method for convolutional networks
论文地址
github
由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。
dropout,训练阶段在每个mini-batch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。
dropout操作流程:参数是丢弃率p
1)在训练阶段,每个mini-batch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元置零)。用一个mask向量与该层神经元对应元素相乘,mask向量维度与输入神经一致,元素为0或1。
2)然后对神经元rescale操作,即每个神经元除以保留概率1-P,也即乘上1/(1-P)。
3)反向传播只对保留下来的神经元对应参数进行更新。
4)测试阶段,Dropout层不对神经元进行丢弃,保留所有神经元直接进行前向过程。
为啥要rescale呢?是为了保证训练和测试分布尽量一致,或者输出能量一致。可以试想,如果训练阶段随机丢弃,那么其实dropout输出的向量,有部分被屏蔽掉了,可以等下认为输出变了,如果dropout大量应用,那么其实可以等价为进行模拟遮挡的数据增强,如果增强过度,导致训练分布都改变了,那么测试时候肯定不好,引入rescale可以有效的缓解,保证训练和测试时候,经过dropout后数据分布能量相似。
dropout方法多是作用在全连接层上,在卷积层应用dropout方法意义不大。文章认为是因为每个feature map的位置都有一个感受野范围,仅仅对单个像素位置进行dropout并不能降低feature map学习的特征范围,也就是说网络仍可以通过该位置的相邻位置元素去学习对应的语义信息,也就不会促使网络去学习更加鲁邦的特征。
既然单独的对每个位置进行dropout并不能提高网络的泛化能力,那么很自然的,如果我们按照一块一块的去dropout,就自然可以促使网络去学习更加鲁邦的特征。思路很简单,就是在feature map上去一块一块的找,进行归零操作,类似于dropout,叫做dropblock。(小声哔哔一句,这跟上面数据增强的方法不是一个道理呢。。。不过就是操作方式上有点区别而已。)

绿色阴影区域是语义特征,b图是模拟dropout的做法,随机丢弃一些位置的特征,但是作者指出这中做法没啥用,因为网络还是可以推断出来,©是本文做法。

dropblock有三个比较重要的参数,一个是block_size,用来控制进行归零的block大小;一个是γ,用来控制每个卷积结果中,到底有多少个channel要进行dropblock;最后一个是keep_prob,作用和dropout里的参数一样。

M大小和输出特征图大小一致,非0即1,为了保证训练和测试能量一致,需要和dropout一样,进行rescale。
上述是理论分析,在做实验时候发现,block_size控制为7*7效果最好,对于所有的feature map都一样,γ通过一个公式来控制,keep_prob则是一个线性衰减过程,从最初的1到设定的阈值(具体实现是dropout率从0增加到指定值为止),论文通过实验表明这种方法效果最好。如果固定prob效果好像不好。
实践中,并没有显式的设置 γ 的值,而是根据keep_prob(具体实现是反的,是丢弃概率)来调整。
DropBlock in ResNet-50 DropBlock加在哪?最佳的DropBlock配置是block_size=7,在group3和group4上都用。将DropBlock用在skip connection比直接用在卷积层后要好,具体咋用,可以看代码。
class DropBlock2D(nn.Module): r"""Randomly zeroes 2D spatial blocks of the input tensor.As described in the paper `DropBlock: A regularization method for convolutional networks`_ , dropping whole blocks of feature map allows to remove semantic information as compared to regular dropout. Args: drop_prob (float): probability of an element to be dropped. block_size (int): size of the block to drop Shape: - Input: `(N, C, H, W)` - Output: `(N, C, H, W)` .. _DropBlock: A regularization method for convolutional networks: https://arxiv.org/abs/1810.12890 """ def __init__(self, drop_prob, block_size): super(DropBlock2D, self).__init__() self.drop_prob = drop_prob self.block_size = block_size def forward(self, x): # shape: (bsize, channels, height, width) assert x.dim() == 4, \ "Expected input with 4 dimensions (bsize, channels, height, width)" if not self.training or self.drop_prob == 0.: return x else: # get gamma value gamma = self._compute_gamma(x) # sample mask mask = (torch.rand(x.shape[0], *x.shape[2:]) < gamma).float() # place mask on input device mask = mask.to(x.device) # compute block mask block_mask = self._compute_block_mask(mask) # apply block mask out = x * block_mask[:, None, :, :] # scale output out = out * block_mask.numel() / block_mask.sum() return out def _compute_block_mask(self, mask): # 比较巧妙的实现,用max pool来实现基于一点来得到全0区域 block_mask = F.max_pool2d(input=mask[:, None, :, :], kernel_size=(self.block_size, self.block_size), stride=(1, 1), padding=self.block_size // 2) if self.block_size % 2 == 0: block_mask = block_mask[:, :, :-1, :-1] block_mask = 1 - block_mask.squeeze(1) return block_mask def _compute_gamma(self, x): return self.drop_prob / (self.block_size ** 2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
2.1 BN、GN、IN和LN
这4种归一化技术非常有名,网上分析文章非常多,故本文不打算从头到尾详细分析一遍,而是从计算角度分析4种归一化手段的计算区别。
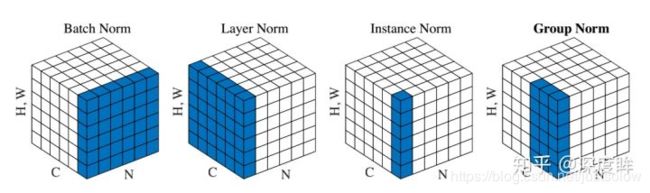
假设输入维度是(N,C,H,W),不管哪一层归一化手段,都不会改变输出大小,即输出维度也是(N,C,H,W)。
(1) BN
对于BN,其归一化维度是N、HxW维度,故其可学习权重维度是(C,),其实就是BN的weight和bias维度,也就是论文中的 α,β 。

BN本质意思就是在Batch和HxW维度进行归一化,可以看出和batch相关,如果batch比较小,那么可能统计就不准确。并且由于测试时候batch可能和训练不同,导致分布不一致,故还多了两个参数:全局统计的均值和方差值,从而eval模式是必须开的,其调用实例如下所示:
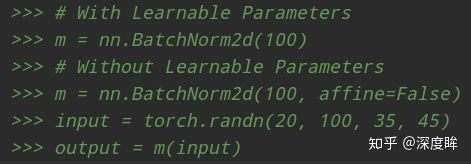
上述中C=100 其流程是:对batch输入计算均值和方差(N、H和W维度求均值),得到维度为(C,),然后对输入(N,C,H,W)采用计算出来的(C,)个值进行广播归一化操作,最后再乘上可学习的(C,)个权重参数即可
(2) LN
对于LN,其归一化维度是C、HxW维度或者HxW维度或者W维度,但是不可以归一化维度为H,可以设置,比较灵活,其对每个batch单独进行各自的归一化操作,归一化操作时候不考虑batch,所以可以保证训练和测试一样。 例如:
m = nn.LayerNorm(normalized_shape=[100 ,35 ,45])
input = torch.randn(20, 100, 35, 45)
- 1
- 2
如上所示,其可学习权重维度是(100,35,45):对batch输入计算均值和方差(C、H和W维度求均值),输出维度为(N,),然后对输入(N,C,H,W)采用计算出来的(N,)个值进行广播归一化操作,最后再乘上可学习的(C,H,W)个权重参数即可。当然也可以设置为(35,45),意思同样理解。
可以看出其归一化是在指定输入shape情况下的归一化,和batch无关。故可以保证训练和测试一致,不需要强制开启eval模式。
通过设置输入参数shape为(H,W),其实就是IN归一化了,比较灵活。
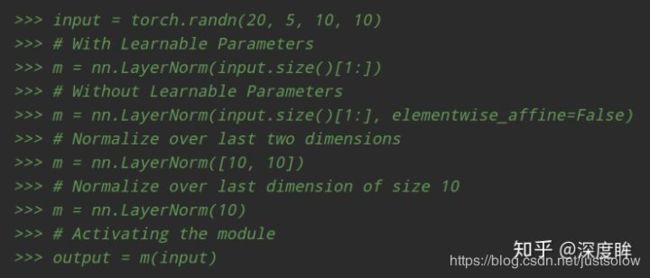
(3) IN
对于IN,其归一化维度最简单,就是HxW,如下所示:
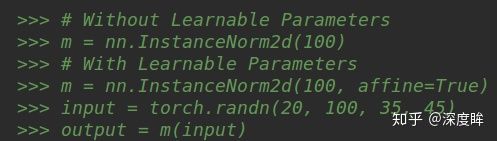
输入参数必须且只能是C,其内部计算是:对batch输入计算均值和方差(H,W维度求均值方差),输出维度为(N,C),然后对输入(N,C,H,W)采用计算出来的(N,C)个值进行广播归一化操作,最后再乘上可学习的(C,)个权重参数即可。
由于其计算均值和方差和batch没有关系,故也不需要强制开启eval模式。
(4) GN
GN是介于LN和IN之间的操作,多了一个group操作,例子如下:
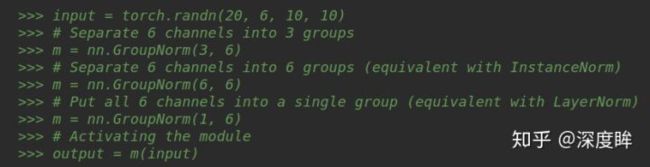
注意第一个参数分组数必须能够将输入通道整除,否则会报错,因为无法均匀分组。其内部计算是:对batch输入计算均值和方差(C/组数、H,W维度求均值方差),输出维度为(N,组数),然后对输入(N,C,H,W)采用计算出来的(N,组数)个值进行广播归一化操作,最后再乘上可学习的(C,)个权重参数即可。不需要强制开启eval模式。
2.2 FRN
论文名称:Filter response normalization layer: Eliminating batch dependence in the training of deep neural networks
论文地址
虽然GN解决了小batch size时的问题,但在正常的batch size时,其精度依然比不上BN层。有什么办法能解决归一化既不依赖于batch,又能使精度高于BN呢?FRN就是为了解决这个问题。

要解决batch依赖问题,则不能对batch维度进行归一化。FRN层由两部分组成,Filtere Response Normalization (FRN)和Thresholded Linear Unit (TLU)。

(1) FRN
N是HxW,表面看起来计算方式非常类似IN,计算过程是:对输入的batch个样本在HxW维度上计算方差,不计算均值,得到输出维度(batch,c),然后对(batch,c,h,w)进行除方差操作,并且引入可学习参数,权重维度是(C,),最后对上述输出乘以可学习参数即可输出。
其中,ϵ是一个很小的正常数,防止除以零。
(2) TLU
由于在FRN操作中没有减去均值,会导致“归一化”后的特征值不是关于零对称,可能会以任意的方式偏移零值。如果使用ReLU作为激活函数的话,会引起误差,产生很多零值,性能下降。所以需要对ReLU进行增强,即TLU,引入一个可学习的阈值τ

从上面来看,FRN层引入了γ、β和τ三个可学习的参数,分别学习变换重构的尺度、偏移和阈值,他们都具有C个值,对应每一个通道。
一般情况下,特征图的大小N=H×W都比较大,但也有N=1的情况(全连接或者特征图为1×1)。在N=1的情况下,若ϵ很小,则会变成一个sign函数,梯度值变得很小,不利于优化;若ϵ相对较大,则曲线会平滑一点,容易优化。

故在实现方面,在N=1的情况下,将ϵ变成一个可学习的参数(初始化为10−4);而对于N≠1时,将其固定为10−6。为了保证可学习参数ϵ>0,对其进行一定限制
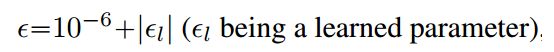
其tf实现如下所示:

另外在实验上,存在几个细节:
1 由于FRN层没有均值中心化,所以会有一些模型对初始学习率的选择十分敏感,特别是那些使用了多个最大池化层的网络。为了缓解这个问题,作者建议使用warm-up来对学习率进行调整。
2 一般而言,FC层后一般都不会接归一化层,这是因为均值和方差计算的数量太少,难以正确估计。但如果FC层后接FRN层,性能不会下降,反而会有上升。
3 作者对BN+TLU或者GN+TLU或者FRN+ReLU等都做过实验对比,还是发现FRN+TLU的搭配是最好。
在一些大佬实践中表明warm-up策略比较关键,如果不用效果可能不太稳定。同时整片论文都是实验性质的,没有啥原理性解释,不太好理解。而且本文看起来也蛮麻烦的,对目前的代码结构还是有蛮大的侵入性,还需要配合warm-up,用到的地方好像没有很多。
2.3 CBN
论文名称:Cross-Iiteration Batch Normalization
github
大家都知道当batch比较小时候,BN在batch维度统计不准确,导致准确率下降,前面的FRN也是为了解决该问题,而本文从另一个角度解决问题,思想比较make sense。在无法扩大batch训练的前提下,是否可以通过收集最近几次迭代信息来更新当前迭代时刻的均值和方差,这样就变向实现了扩大batch目的? 但是我们知道在当前迭代时刻,参数已经更新了N次,存储的前几个迭代的参数肯定无法直接和当前迭代次数进行合并计算,也就是由于网络权重的变化,不同迭代产生的网络激活无法相互比较。故需要找到一种解决办法。所幸作者指出:由于梯度下降机制,模型训练过程中相近的几个iter所对应的模型参数的变化是平滑的(smoothly),其权重变化可以用泰勒级数拟合出来,因此通过基于泰勒多项式的拟合来补偿网络权重的变化,从而可以准确地估计统计量,并可以有效地应用批次归一化。
在训练yolo中,常用的一个技巧是设置mini batch和batch,即网络前向batch/ mini batch次,然后再进行一次梯度更新,也是为了变相扩大batch size,但是其缺点是bn操作无法实现等价的扩大N倍,本文就相当于可以解决这个问题。通常在多卡情况下一般采用SyncBN,其也叫作Cross-GPU Batch Normalization ,主要是解决batch特别小的场景,例如语义分割中batch通常都是1的情况训练效果不够好的问题,其在多个gpu上计算BN,实现了跨GPU上计算,使用多卡构造了大batch训练,属于技术改进。而本文想在单卡下实现同样效果,因为不是每个人都有多张卡。
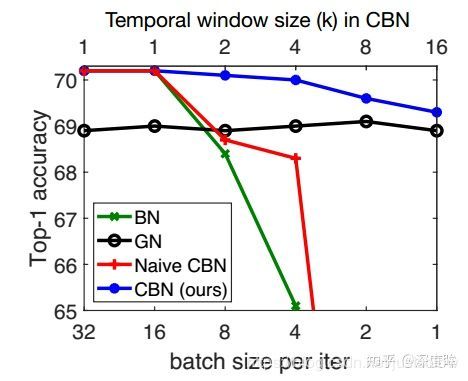
上述图表是基于ResNet-18在ImageNet上面训练得到的top 准确率,可以看出当batch大于16后,BN的精度就蛮好了,随着batch减少,精度快速下降,GN虽然性能还可以,但是batch大的时候精度不如BN,而Naive版本的CAN效果其实和BN差不多,Naive版本是指收集最近K个迭代信息,然后用于计算当前迭代时刻的统计量,可以发现由于梯度更新原因,直接计算统计量其实没有效果,而本文的CBN可以比较好的克服。
假设当前迭代时刻为t,则 t-τ 时刻中的统计量在t时刻的值,可以用泰勒级数近似:


对于上述式子,代码就比较好写了,只要存储前k个时刻的统计量及其梯度即可。最后进行汇总就行:

注意求方差时候,采用了max操作,作者指出这样可以保留有用的统计信息(不太好理解)。得到统计量后,后面直接进行归一化即可,和标准BN计算方式一样。
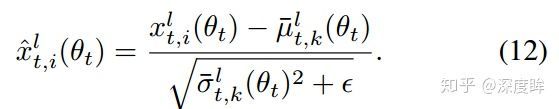
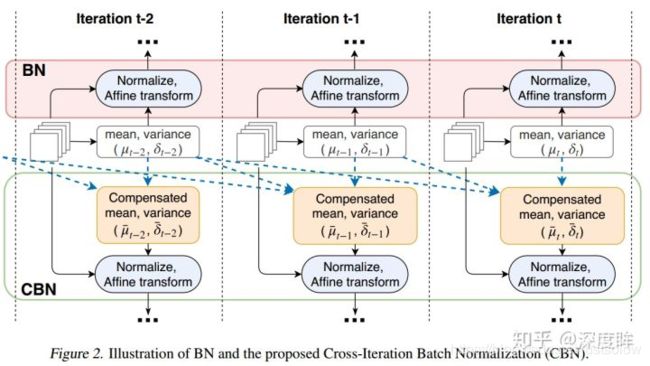
上图可以很好的反映出计算过程,BN就是仅仅利用当前迭代时刻信息进行norm,而CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些,比GN还慢。

论文做的实验比较多,这里不详细说了,有兴趣的可以下载原文查看。有一个细节是:CBN多了一个window size,实验中设定为8。并且需要在网络训练初期要用较小的窗大小,随着网络的训练,模型参数也会越来越稳定,再用较大的窗大小可以获得更好的结果。
2.4 CmBN
CmBN是yolov4中提出的,属于CBN的小改动,但是作者论文图绘制的比较隐晦,不太好理解,本文详细说下流程。
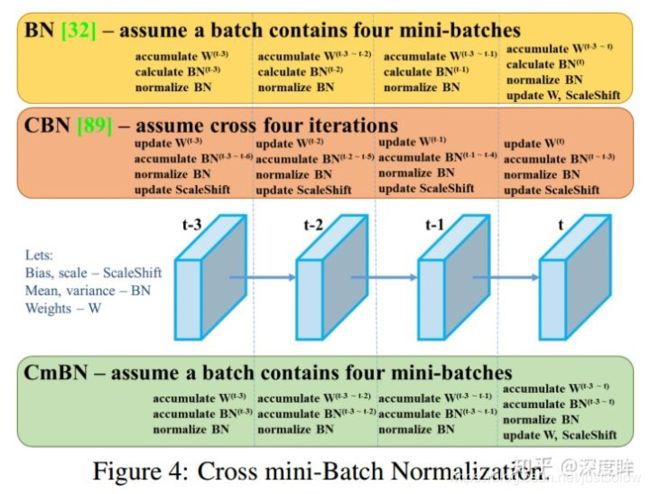
注意此时 [公式] 是没有进行更新的,使用的是前面时刻梯度更新得到的值。橙色流程的意思其实就是前面提到的yolo中常用的变相扩大batch size做法,其网络前向batch/ mini batch次,然后再第N-1迭代时刻进行统一的梯度更新,包括更新权重W以及BN可学习参数[公式],可以看出其无法变相扩大batch大小,实现更加精确的batch维度统计,但是实际上用起来还是有点效果的,不然大家训练时候也就不会用了。最好的办法其实应该还是同步BN好用,跨卡统计batch参数,但是不是人人都有多卡的,所以CBN还是有用武之地的。
在理解了BN流程基础上,理解CBN就非常容易了,CBN由于在计算每个迭代时刻统计量时候会考虑前3个时刻的统计量,故变相实现了大batch,然后在每个mini batch内部,都是标准的BN操作即:1 计算BN统计量;2 应用BN;3 更新可学习参数和网络权重
而CmBN的做法和前面两个都不一样,其把大batch内部的4个mini batch当做一个整体,对外隔离,主要改变在于BN层的统计量计算方面,具体流程是:假设当前是第t次迭代时刻,也是mini-batch的起点,
(1) 在第t时刻开始进行梯度累加操作
(2) 在第t时刻开始进行BN统计量汇合操作,这个就是和CBN的区别,CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,其仅仅在mini batch内部进行汇合操作
(3) 就是正常的应用BN,对输入进行变换输出即可
(4) 在mini batch的最后一个时刻,进行参数更新和可学习参数更新
可以明显发现CmBN是CBN的简化版本,其唯一差别就是在计算第t时刻的BN统计量时候,CBN会考虑前一个mini batch内部的统计量,而CmBN版本,所有计算都是在mini batch内部。我怀疑是为了减少内存消耗,提高训练速度,既然大家都是近似,差距应该不大,而且本身yolo训练时候,batch也不会特别小,不至于是1-2,所以CmBN的做法应该是为了yolov4专门设计的,属于实践性改进。
3、网络改进
3.1 增加感受野技巧
论文中主要是提到了三种结构:SPP层、ASPP和RFB。
(1) SPP层

其结构如上所示,内部采用不同大小的kernel size和strdie实现不同感受野特征输出,然后concat即可,在yolov3-spp里面有具体结构:
---- START SPP -----
[maxpool]
stride=1
size=5
[route]
layers=-2
[maxpool]
stride=1
size=9
[route]
layers=-4
[maxpool]
stride=1
size=13
[route]
layers=-1,-3,-5,-6
----End SPP ----
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
即上一层的特征图输入是13x13x512,然后三个分支分别是stride=1,kernel size为5,9,13,然后三个图拼接,得到13x13x2048的图,然后
[convolutional]
batch_normalize=1
filters=512
size=1
stride=1
pad=1
activation=leaky
- 1
- 2
- 3
- 4
- 5
- 6
- 7
接一个1x1卷积,得到13x13x512的特征图,然后进行后续操作。
(2) ASPP

ASPP和SPP的差别是,并不是采用max pool得到不同感受野的特征图,而是采用卷积实现,且其kernel size全部是3,但是引入了不同的空洞率来变相扩大感受野。其余操作和SPP一致,ASPP来自DeepLab论文。
(3) RFB
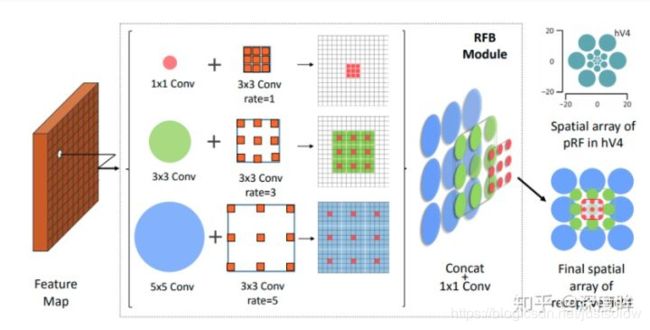
RFB结构来自RFBNet,效果不错,计算量也不大,可以看出RFB是ASPP的推广,其采用了不同大小的kernel和不同的空洞率,相比ASPP,计算量减少不少,效果应该差不多。RFB在推理阶段引入的计算量非常小,但是在ssd中AP提高蛮多,是个不错的选择。
3.2 注意力机制技巧
论文中主要是提到了SE和SAM模块
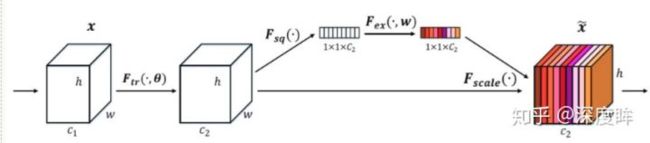
SE模块比较简单,目的是对特征通道进行重新加权,如上图所示。
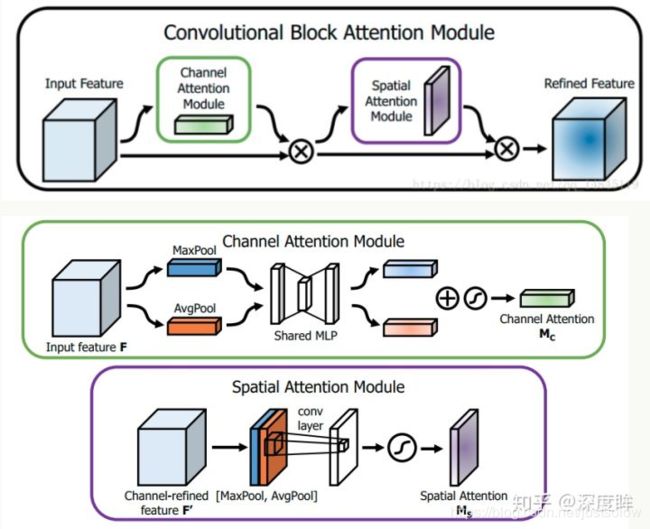
SAM是CBAM论文中的空间注意力模块。其流程是:将Channel attention模块输出特征图作为本模块的输入特征图。首先做一个基于channel的global max pooling 和global average pooling,然后将这2个结果基于channel 做concat操作。然后经过一个卷积操作,降维为1个channel。再经过sigmoid生成spatial attention feature。最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
SE模块可以提升大概1%的ImageNet top-1精度,增加2%计算量,但推理时有10%的速度损失,对GPU不太友好,而SAM模块仅仅增加0.1%计算量,提升0.5%的top-1准确率,故本文选择的其实是SAM模块。
yolov4对SAM进行简单修改,如下所示:
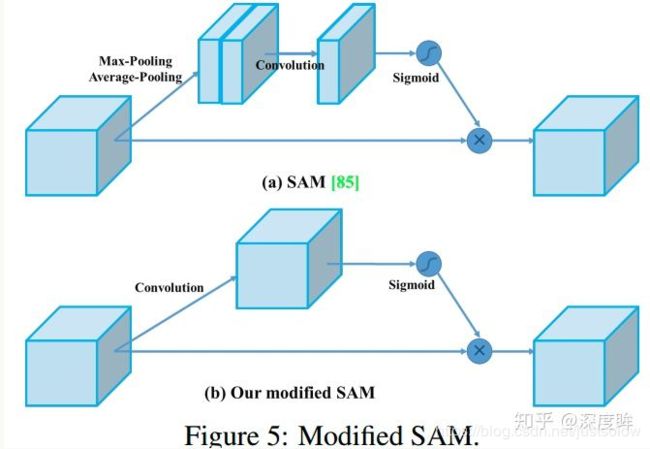
修改spatial-wise attention 为 pointwise attention,简化了流程,目的应该也是为了提高训练速度。
3.3 特征融合技巧
特征融合,主要是指不同输出层直接的特征融合,主要包括FPN、PAN、SFAM、ASFF和BiFPN。
(1) FPN
FPN是目前最主流的不同层融合方案,应用非常广泛,其结构为:
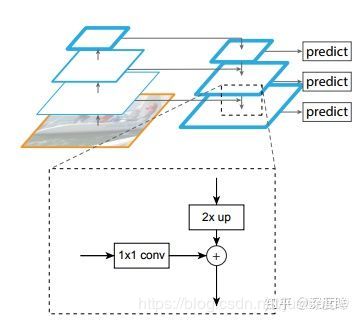
FPN仅仅融合相邻层的特征图,采用上采样或者下采样操作得到尺度一致的特征图,然后采用add操作得到融合后特征图。
(2) PAN
PAN来自论文:Path Aggregation Network for Instance Segmentation。其结构如下所示:
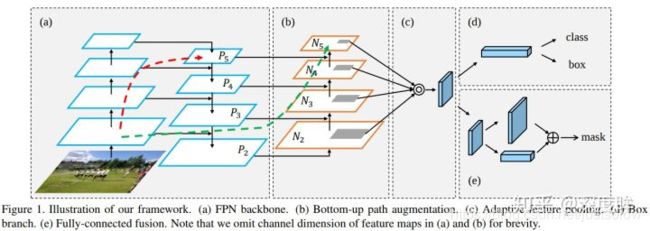
FPN加入top-down的旁路连接,能给feature增加high-level语义,有利于分类。但是PAN论文作者觉得low-level的feature很有利于定位,虽然FPN中P5也间接融合了low-level的特征,但是信息流动路线太长了如红色虚线所示,其中会经过超多conv操作,本文在FPN的P2-P5又加了low-level的特征,最底层的特征流动到N2-N5只需要经过很少的层如绿色需要所示,主要目的是加速信息融合,缩短底层特征和高层特征之间的信息路径。down-top的融合做法是:

其实不管作者如何解释motivation,这种top-down和donw-top的做法,看起来也比较make sense,后面的很多FPN改进都用到了这个思想。
(3) SFAM
SFAM来自M2det: A single-shot object detector based on multi-level feature pyramid network

其中SFAM结构如下所示:
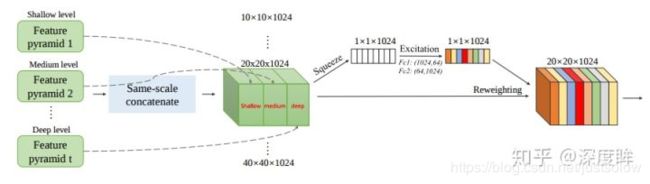
SFAM全称是Scale-wise Feature Aggregation Module,不同尺度的特征进行重组和融合,基本原理是对不同TUM的输出(每个TUM有6个不同尺度的输出),将其中相同尺度的特征进行concat,然后经过一个SE模块(对通道进行reweighting)输出,然后进行检测。其实就是把相同尺度的各层金字塔特征提取出来,然后concat,经过se模块,进行通道加权,再进行后续的预测,实现对不同通道进行不同加权功能。看起来开销有点大呀,因为要多个stage。
和FPN及其改进版本的不同是SFAM的融合是尺度感知的,只融合相同尺度的特征,而不是像FPN那样,强制上下采样然后进行融合。
(4) ASFF
ASFF来自论文:Learning Spatial Fusion for Single-Shot Object Detection,也就是著名的yolov3-asff
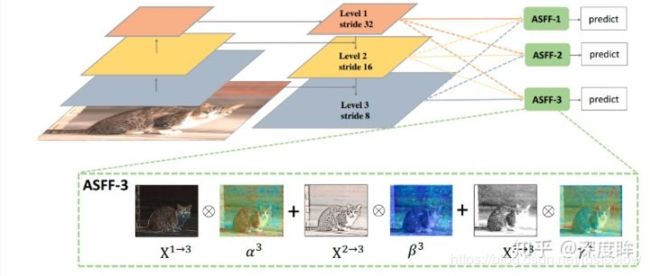
FPN操作是一个非常常用的用于对付大小尺寸物体检测的办法,作者指出FPN的缺点是不同尺度之间存在语义gap,举例来说基于iou准则,某个gt bbox只会分配到某一个特定层,而其余层级对应区域会认为是背景(但是其余层学习出来的语义特征其实也是连续相似的,并不是完全不能用的),如果图像中包含大小对象,则不同级别的特征之间的冲突往往会占据要素金字塔的主要部分,这种不一致会干扰训练期间的梯度计算,并降低特征金字塔的有效性。一句话就是:目前这种concat或者add的融合方式不够科学。本文觉得应该自适应融合,自动找出最合适的融合特征, 简要思想就是:原来的FPN add方式现在变成了add基础上多了一个可学习系数,该参数是自动学习的,可以实现自适应融合效果,类似于全连接参数。 ASFF具体操作包括 identically rescaling和adaptively fusing。
定义FPN层级为l,为了进行融合,对于不同层级的特征都要进行上采样或者下采样操作,用于得到同等空间大小的特征图,上采样操作是1x1卷积进行通道压缩,然后双线性插值得到;下采样操作是对于1/2特征图是采样3 × 3 convolution layer with a stride of 2,对于1/4特征图是add a 2-stride max pooling layer然后引用stride 卷积。其自适应融合过程如下:

具体操作为:
(1) 首先对于第l级特征图输出cxhxw,对其余特征图进行上下采样操作,得到同样大小和channel的特征图,方便后续融合
(2) 对处理后的3个层级特征图输出,输入到1x1xn的卷积中(n是预先设定的),得到3个空间权重向量,每个大小是nxhxw
(3) 然后通道方向拼接得到3nxhxw的权重融合图
(4) 为了得到通道为3的权重图,对上述特征图采用1x1x3的卷积,得到3xhxw的权重向量
(5) 在通道方向softmax操作,进行归一化,将3个向量乘加到3个特征图上面,得到融合后的cxhxw特征图
(6) 采用3x3卷积得到输出通道为256的预测输出层
(5) BIFPN
BiFPN来自论文:EfficientDet: Scalable and efficient object detection 。ASFF思想和BiFPN非常类似,也是可学习参数的自适应加权融合,但是比ASFF更加复杂。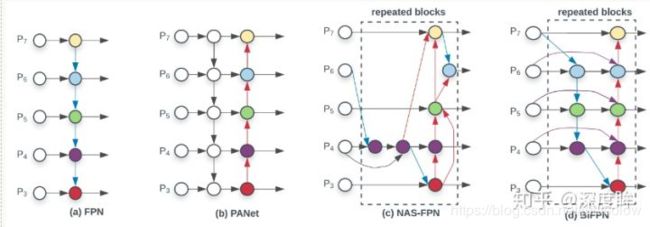
思想都差不多,多尺度融合不仅仅是从下到上,也要从上到下,并且融合的参数都是学习出来的,不是简单的add或者concat就Ok的。由于BiFPN操作非常有名,这里就不详细说了,大家可以参考知乎文章。
4. 总结
读了这篇文章以后,给人留下深刻印象的不是创新点,而是Bag of freebies和Bag of specials。所以有人多人都说YOLOv4是拼凑trick得到的。YOLOv4中Bag of freebies和Bag of Specials两部分总结的确实不错,对研究目标检测有很大的参考价值,涵盖的trick非常广泛。但是感觉AB大神并没有将注意力花在创新点上,没有花更多篇幅讲解这创新性,这有些可惜。(ASFF中就比较有侧重,先提出一个由多个Trick组成的baseline,然后在此基础上提出ASFF结构等创新性试验,安排比较合理)
此外,笔者梳理了yolov4.cfg并没有发现在论文中提到的创新点比如modified SAM, 并且通过笔者整理的YOLOv4结构可以看出,整体架构方面,可以与yolov3-spp进行对比,有几个不同点:
换上了更好的backbone: CSDarknet53
将原来的FPN换成了PANet中的FPN
结构方面就这些不同,不过训练过程确实引入了很多特性比如:
Weighted Residual Connections(论文中没有详细讲)
CmBN
Self-adversarial-training
Mosaic data augmentation
DropBlock
CIOU loss
总体来讲,这篇文章工作量还是非常足的,涉及到非常非常多的trick, 最终的结果也很不错,要比YOLOv3高10个百分点。文章提到的Bag of freebies和Bag of specials需要好好整理,系统学习一下。
但是缺点也很明显,创新之处描述的不够,没能有力地证明这些创新点的有效性。此外,yolov4.cfg可能并没有用到以上提到的创新点,比如SAM。