介绍知识蒸馏
一、什么是知识蒸馏?
知识蒸馏指的是模型压缩的思想,通过使用一个较大的已经训练好的网络去教导一个较小的网络确切地去做什么。
二、为什么要进行知识蒸馏?
深度学习在计算机视觉、语音识别、自然语言处理等内的众多领域中均取得了令人难以置信的性能。但是,大多数模型在计算上过于昂贵,无法在移动端或嵌入式设备上运行。因此需要对模型进行压缩,且知识蒸馏是模型压缩中重要的技术之一。
1. 提升模型精度
如果对目前的网络模型A的精度不是很满意,那么可以先训练一个更高精度的teacher模型B(通常参数量更多,时延更大),然后用这个训练好的teacher模型B对student模型A进行知识蒸馏,得到一个更高精度的A模型。
2. 降低模型时延,压缩网络参数
如果对目前的网络模型A的时延不满意,可以先找到一个时延更低,参数量更小的模型B,通常来讲,这种模型精度也会比较低,然后通过训练一个更高精度的teacher模型C来对这个参数量小的模型B进行知识蒸馏,使得该模型B的精度接近最原始的模型A,从而达到降低时延的目的。
3. 标签之间的域迁移
假如使用狗和猫的数据集训练了一个teacher模型A,使用香蕉和苹果训练了一个teacher模型B,那么就可以用这两个模型同时蒸馏出一个可以识别狗、猫、香蕉以及苹果的模型,将两个不同域的数据集进行集成和迁移。
三、教师网络的作用
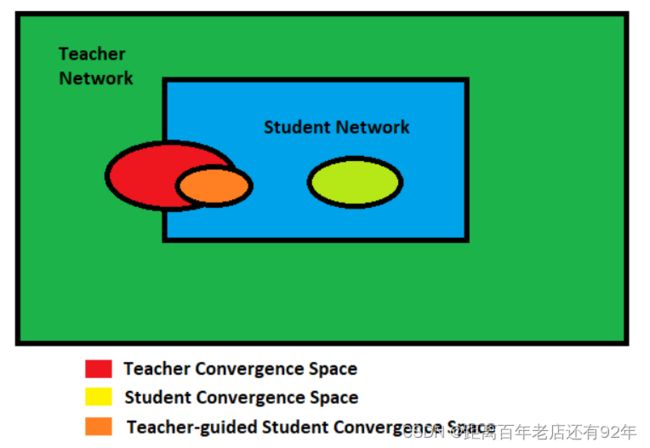
对于更复杂的模型,理论搜索空间要大于较小网络的搜索空间。但是,如果我们假设使用较小的网络可以实现相同(甚至相似)的收敛,则教师网络的收敛空间应与学生网络的解空间重叠。
不幸的是,仅此一项并不能保证学生网络在同一位置收敛。学生网络的收敛可能与教师网络的收敛大不相同。但是,如果指导学生网络复制教师网络的行为(教师网络已经在更大的解空间中进行了搜索),则可以预期其收敛空间与原始教师网络收敛空间重叠。
四、知识蒸馏的理论依据?
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
- 原始模型训练: 训练"Teacher模型", 简称为Net-T,它的特点是模型相对复杂,也可以由多个分别训练的模型集成而成。我们对"Teacher模型"不作任何关于模型架构、参数量、是否集成方面的限制,唯一的要求就是,对于输入X, 其都能输出Y,其中Y经过softmax的映射,输出值对应相应类别的概率值。
- 精简模型训练: 训练"Student模型", 简称为Net-S,它是参数量较小、模型结构相对简单的单模型。同样的,对于输入X,其都能输出Y,Y经过softmax映射后同样能输出对应相应类别的概率值。
- Teacher学习能力强,可以将它学到的知识迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正部署上线进行预测任务的是灵活轻巧的Student小模型。
五、知识蒸馏分类
知识蒸馏是对模型的能力进行迁移,根据迁移的方法不同可以简单分为基于目标蒸馏(也称为Soft-target蒸馏或Logits方法蒸馏)和基于特征蒸馏的算法两个大的方向。
5.1目标蒸馏-Logits方法
分类问题的共同点是模型最后会有一个softmax层,其输出值对应了相应类别的概率值。在知识蒸馏时,由于我们已经有了一个泛化能力较强的Teacher模型,我们在利用Teacher模型来蒸馏训练Student模型时,可以直接让Student模型去学习Teacher模型的泛化能力。一个很直白且高效的迁移泛化能力的方法就是:使用softmax层输出的类别的概率来作为“Soft-target” 。
5.1.1.Hard-target 和 Soft-target
(注:soft target“软标签”指的是大网络在每一层卷积后输出的特征映射。)
1.区别
传统training过程(hard targets): 对ground truth求极大似然
(原始数据集标注的 one-shot 标签,除了正标签为 1,其他负标签都是 0。)
KD的training过程(soft targets): 用large model的class probabilities作为soft targets
(Teacher模型softmax层输出的类别概率,每个类别都分配了概率,正标签的概率最高。)
2.KD的训练过程为什么更有效?
softmax层的输出,除了正例之外,负标签也带有大量的信息,比如某些负标签对应的概率远远大于其他负标签。而在传统的训练过程(hard target)中,所有负标签都被统一对待。也就是说,KD的训练方式使得每个样本给Net-S带来的信息量大于传统的训练方式。
【举个例子】
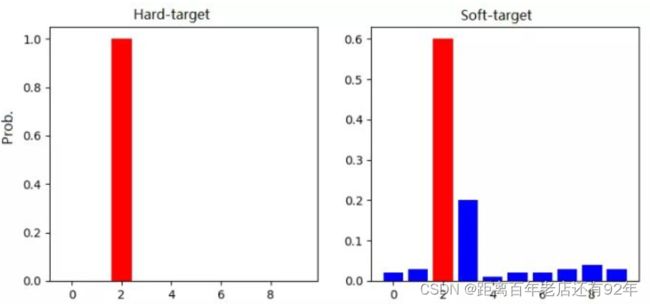
在手写体数字识别任务MNIST中,输出类别有10个。

假设某个输入的“2”更加形似"3",softmax的输出值中"3"对应的概率为0.2,而其他负标签对应的值都很小,而另一个"2"更加形似"7","7"对应的概率为0.2。这两个"2"对应的hard target的值是相同的,但是它们的soft target却是不同的,由此我们可见soft target蕴含着比hard target多的信息。并且soft target分布的熵相对高时,其soft target蕴含的知识就更丰富。

综上:
(1)在使用 Soft-target 训练时,Student模型可以很快学习到 Teacher模型的推理过程。
(2)传统的 Hard-target 的训练方式,所有的负标签都会被平等对待。Soft-target 给 Student模型带来的信息量要大于 Hard-target,并且Soft-target分布的熵相对高时,其Soft-target蕴含的知识就更丰富。
(3)使用 Soft-target 训练时,梯度的方差会更小,训练时可以使用更大的学习率,所需要的样本也更少。
这也解释了为什么通过蒸馏的方法训练出的Student模型相比使用完全相同的模型结构和训练数据只使用Hard-target的训练方法得到的模型,拥有更好的泛化能力。
5.1.2.知识蒸馏的具体方法
1.数值含义
(1) :对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 ,某个类别的数值越大,则模型认为输入图片属于这个类别的可能性就越大。
:对于一般的分类问题,比如图片分类,输入一张图片后,经过DNN网络各种非线性变换,在网络最后Softmax层之前,会得到这张图片属于各个类别的大小数值 ,某个类别的数值越大,则模型认为输入图片属于这个类别的可能性就越大。
(2)Logits:这些汇总了网络内部各种信息后,得出的属于各个类别的汇总分值 ,i代表第i个类别,代表属于第i类的可能性。
(3)softmax:因为Logits并非概率值,所以一般在Logits数值上会用Softmax函数进行变换,得出的概率值作为最终分类结果概率。(Softmax一方面把Logits数值在各类别之间进行概率归一,使得各个类别归属数值满足概率分布;另外一方面,它会放大Logits数值之间的差异,使得Logits得分两极分化,Logits得分高的得到的概率值更偏大一些,而较低的Logits数值,得到的概率值则更小。)
2.softmax函数
神经网络使用 softmax 层来实现 logits 向 probabilities 的转换
原始函数
![]()
但要是直接使用softmax层的输出值作为soft target, 这又会带来一个问题: 当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。
加了温度这个变量之后的softmax函数:
![]()
 是每个类别输出的概率
是每个类别输出的概率
是每个类别输出的 logits
 是温度。当温度=1时,这就是标准的 Softmax 公式。T越高,softmax的输出概率分布(output probability distribution)越趋于平滑,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
是温度。当温度=1时,这就是标准的 Softmax 公式。T越高,softmax的输出概率分布(output probability distribution)越趋于平滑,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。
3.蒸馏步骤

- 训练好Teacher模型;
- 利用高温
 产生 Soft-target;
产生 Soft-target; - 使用
 和
和 同时训练 Student模型;
同时训练 Student模型; - 设置温度 ,Student模型线上做inference。
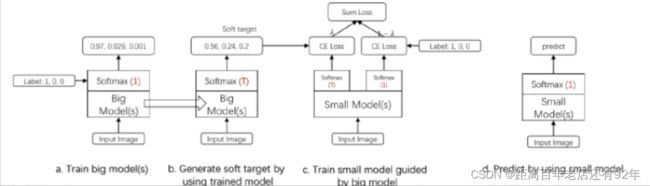
下面详细讲讲第二步:高温蒸馏的过程。高温蒸馏过程的目标函数由distill loss(对应soft target)和student loss(对应hard target)加权得到。
![]()
符号含义:
 : Net-T的logits
: Net-T的logits
: Net-S的logits
![]() : Net-T的在温度=T下的softmax输出在第i类上的值
: Net-T的在温度=T下的softmax输出在第i类上的值
![]() : Net-S的在温度=T下的softmax输出在第i类上的值
: Net-S的在温度=T下的softmax输出在第i类上的值
 : 在第i类上的ground truth值, , 正标签取1,负标签取0.
: 在第i类上的ground truth值, , 正标签取1,负标签取0.
 : 总标签数量
: 总标签数量
第一步:Net-T 和 Net-S同时输入 transfer set (这里可以直接复用训练Net-T用到的training set), 用Net-T产生的softmax distribution (with high temperature) 来作为soft target
第二步:Net-S在相同温度T条件下的softmax输出和soft target的cross entropy就是Loss函数的第一部分 ![]()

第三步:Net-S在T=1的条件下的softmax输出和ground truth的cross entropy就是Loss函数的第二部分 ![]()

(注:1.第二部分![]() 的必要性: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。2.实验发现第二部分所占比重比较小的时候,能产生最好的结果)
的必要性: Net-T也有一定的错误率,使用ground truth可以有效降低错误被传播给Net-S的可能。打个比方,老师虽然学识远远超过学生,但是他仍然有出错的可能,而这时候如果学生在老师的教授之外,可以同时参考到标准答案,就可以有效地降低被老师偶尔的错误“带偏”的可能性。2.实验发现第二部分所占比重比较小的时候,能产生最好的结果)
3.温度说明
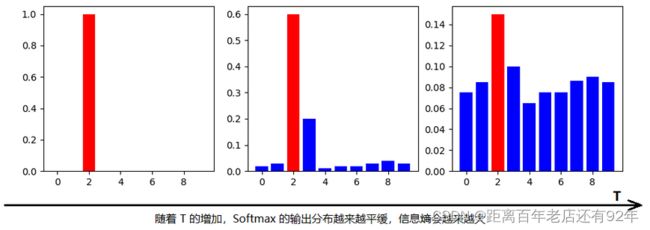
(1)温度T有这样几个特点:
- 原始的softmax函数是T=时的特例;T<1 时,概率分布比原始更“陡峭”,也就是说,当 T->0时,Softmax 的输出值会接近于 Hard-target;T>1时,概率分布比原始更“平缓”。
- 随着T的增加,Softmax 的输出分布越来越平缓,信息熵会越来越大。温度越高,softmax上各个值的分布就越平均,思考极端情况,当
 ,此时softmax的值是平均分布的。
,此时softmax的值是平均分布的。 - 不管温度T怎么取值,Soft-target都有忽略相对较小的
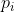 (Teacher模型在温度为T时softmax输出在第i类上的值)携带的信息的倾向。
(Teacher模型在温度为T时softmax输出在第i类上的值)携带的信息的倾向。
(2)温度的高低改变的是Student模型训练过程中对负标签的关注程度。当温度较低时,对负标签的关注,尤其是那些显著低于平均值的负标签的关注较少;而温度较高时,负标签相关的值会相对增大,Student模型会相对更多地关注到负标签。
(3)实际上,负标签中包含一定的信息,尤其是那些负标签概率值显著高于平均值的负标签。但由于Teacher模型的训练过程决定了负标签部分概率值都比较小,并且负标签的值越低,其信息就越不可靠。因此温度的选取需要进行实际实验的比较,本质上就是在下面两种情况之中取舍:
- 当想从负标签中学到一些信息量的时候,温度 应调高一些;
- 当想减少负标签的干扰的时候,温度 应调低一些;
总的来说,温度的选择和Student模型的大小有关,Student模型参数量比较小的时候,相对比较低的温度就可以了。因为参数量小的模型不能学到所有Teacher模型的知识,所以可以适当忽略掉。
5.2特征蒸馏方法
5.2.1特征蒸馏特点
1.它不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。这种情况下,Teacher中间特征层的响应,就是传递给Student的知识,本质是Teacher将特征级知识迁移给Student。
2.既宽又深的模型通常需要大量的乘法运算,从而导致对内存和计算的高需求。为了解决这类问题,我们需要通过模型压缩(也称为知识蒸馏)将知识从复杂的模型转移到参数较少的简单模型。到目前为止,知识蒸馏技术已经考虑了Student网络与Teacher网络有相同或更小的参数。这里有一个洞察点是,深度是特征学习的基本层面,到目前为止尚未考虑到Student网络的深度。一个具有比Teacher网络更多的层但每层具有较少神经元数量的Student网络称为“thin deep network”。
因此,该篇论文主要针对Hinton提出的知识蒸馏法进行扩展,允许Student网络可以比Teacher网络更深更窄,使用teacher网络的输出和中间层的特征作为提示,改进训练过程和student网络的性能。
5.2.2模型结构
- Student网络不仅仅拟合Teacher网络的Soft-target,而且拟合隐藏层的输出(Teacher网络抽取的特征);
- 第一阶段让Student网络去学习Teacher网络的隐藏层输出(特征蒸馏);
- 第二阶段使用Soft-target来训练Student网络(目标蒸馏)。
把“宽”且“深”的网络蒸馏成“瘦”且“更深”的网络,需要进行两阶段的训练:
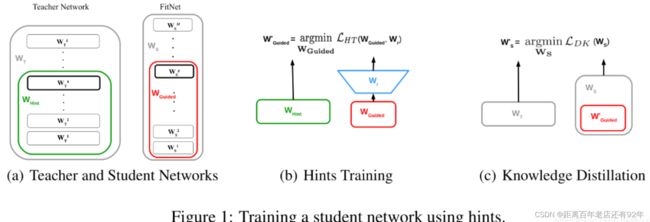 (注:Hint定义是:teacher的隐含层输出,用来引导student的学习过程。类似的又从student中选择一个隐含层叫做guided layer,我们希望guided layer能预测出与hint layer相近的输出。)
(注:Hint定义是:teacher的隐含层输出,用来引导student的学习过程。类似的又从student中选择一个隐含层叫做guided layer,我们希望guided layer能预测出与hint layer相近的输出。)
第一阶段:首先选择待蒸馏的中间层(即Teacher的Hint layer和Student的Guided layer),如图中绿框和红框所示。由于两者的输出尺寸可能不同,因此,在Guided layer后另外接一层卷积层,使得输出尺寸与Teacher的Hint layer匹配。接着通过知识蒸馏的方式训练Student网络的Guided layer,使得Student网络的中间层学习到Teacher的Hint layer的输出.
就是根据Teacher模型的损失来指导预训练Student模型。记Teacher网络的前h层作为 ![]() ,意为指导的意思。Student网络的前g层作为
,意为指导的意思。Student网络的前g层作为![]() ,即被指导的意思,在训练之初Student网络进行随机初始化。需要学习一个映射函数
,即被指导的意思,在训练之初Student网络进行随机初始化。需要学习一个映射函数 使得
使得![]() 的维度匹配
的维度匹配 ![]() ,得到Student模型在下一阶段的参数初始化值,并最小化两者网络输出的MSE(均方误差)差异作为损失(特征蒸馏),如下:
,得到Student模型在下一阶段的参数初始化值,并最小化两者网络输出的MSE(均方误差)差异作为损失(特征蒸馏),如下:
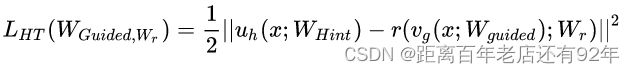
其中, ![]() 是教师网络的部分层的参数(绿框);
是教师网络的部分层的参数(绿框);![]() 是学生网络的部分层的参数(红框); 是一个全连接层,用于将两个网络输出的size配齐,因为学生网络隐藏层宽度比教师网络窄。
是学生网络的部分层的参数(红框); 是一个全连接层,用于将两个网络输出的size配齐,因为学生网络隐藏层宽度比教师网络窄。
第二阶段: 在训练好Guided layer之后,将当前的参数作为网络的初始参数,利用知识蒸馏的方式训练Student网络的所有层参数,使Student学习Teacher的输出。由于Teacher对于简单任务的预测非常准确,在分类任务中近乎one-hot输出,因此为了弱化预测输出,使所含信息更加丰富,作者使用Hinton等人论文《Distilling knowledge in a neural network》中提出的softmax改造方法,即在softmax前引入缩放因子 ,将Teacher和Student的pre-softmax输出均除以 。也就是上面我们讲的加了温度的softmax。此时的损失函数为:
,将Teacher和Student的pre-softmax输出均除以 。也就是上面我们讲的加了温度的softmax。此时的损失函数为:
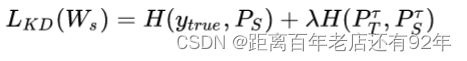
其中,H指交叉熵损失函数; 是一个可调整参数,以平衡两个交叉熵;第一部分为Student的输出与Ground-truth的交叉熵损失;第二部分为Student与Teacher的softmax输出的交叉熵损失。
是一个可调整参数,以平衡两个交叉熵;第一部分为Student的输出与Ground-truth的交叉熵损失;第二部分为Student与Teacher的softmax输出的交叉熵损失。
3. 知识蒸馏在NLP/CV中的应用
下面给出这两种蒸馏方式在自然语言处理和计算机视觉方面的一些顶会论文,方便大家扩展阅读。
3.1 目标蒸馏-Logits方法应用
- 《Distilling the Knowledge in a Neural Network 》,NIPS,2014。
- 《Deep Mutual Learning》,CVPR,2018。
- 《Born Again Neural Networks》,CVPR,2018。
- 《Distilling Task-Specific Knowledge from BERT into Simple Neural Networks》,2019。
3.2 特征蒸馏方法应用
- 《FitNets: Hints for Thin Deep Nets》,ICLR,2015。
- 《Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer》, ICLR,2017。
- 《A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning》,CVPR,2017。
- 《Learning Efficient Object Detection Models》,NIPS,2017。