轻量化网络:ShuffleNet V2
-
- Guideline 1-4:
- ShuffleNet V2
- 疑问:
ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
由Face++及清华的研究者共同发表,已被ECCV-2018收录
论文下载地址:https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw
prototxt 可从此处获得: https://github.com/farmingyard/ShuffleNet
该论文虽然以ShuffleNet V2打头,但ShuffleNet V2 只是该论文的副产品,最亮眼的还是该论文提出的两个原则,四个指导方针,这为轻量级模型的设计者提供了巨大的帮助。
创新点:
两个原则和四个指导方针
两个原则:
1. 衡量模型运行速度,应采用如运行时间(speed\runtime)这样的指标;
2. 应在具体的运行平台上进行评估、衡量。
四个指导方针:
1. 卷积核数量尽量与输入通道数相同(即输入通道数等于输出通道数);
2. 谨慎使用group convolutions,注意group convolutions的效率;
3. 降低网络碎片化程度;
4. 减少元素级运算。
至于ShuffleNet V2的结构,就不提了,都在后面呢
前言:
近几年轻量化卷积神经网络设计都以浮点运算数flops为指导,网络设计时在保证精度的同时尽可能的获得更小的flops。然而,在实际应用过程中,网络的耗时不仅看“软件”上的设计,还要考虑到硬件实现的效率。软硬兼并,双管齐下,才能获得更好的移动端网络模型。“软件”上主要考虑权值参数数量(占内存小)以及具体的运算方式(更小的flops),硬件上要考虑MAC(memory access cost ),并行度(degree of parallelis),数据的读取方式等等,更多硬件上的讨论可参考论文(SqueezeNext: Hardware-Aware Neural Network Design)第三小节。
本文作者就是在“软件”和硬件上综合考虑之后,得出四点指导方针,再基于shufflenet-v1进行改动,就得到了shufflenet-v2 。
正文:
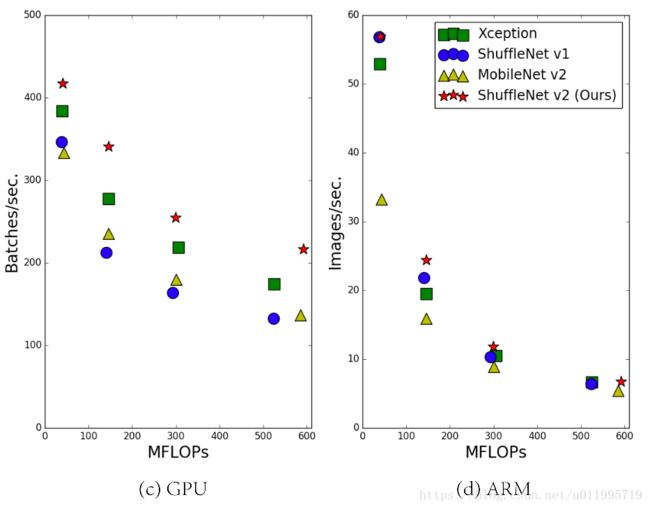
近几年,轻量级模型的设计都是朝着 light-weight 结构进行设计,在 light-weight结构中,主要得益于 Group convolution 和 depth-wise convolution。为了衡量模型的是否是轻量级,通常都采用flops这一单一指标。但我们知道,flpos并不能等价于一个网络的速度,flops相同的网络模型,其运算速度也会存在差异,这种差异大多是由硬件的特性引起的。如图1中的c,d所示,采用四种不同的网络设计思想,在具有相同的flops时,它们的运算速度却不同。
这就值得思考了,之前仅通过指标flops“指导”设计轻量级卷积神经网络,是否完美?是否还需要考虑其他指标? 答案不言而喻。请接着往下看,到底还需要用什么指标来衡量网络的轻呢?
经本文分析,模型的flops不能直接代表其速度的原因有二:
影响模型运行速度还有别的指标,例如,MAC(memory access ),并行度(degree of parallelism)
不同平台有不同的加速算法,这导致flops相同的运算可能需要不同的运算时间。
基于上述发现,该文提出设计轻量级网络时需要考虑的两个原则(指导方针):
1. 衡量模型运行速度,应采用如运行时间(speed\runtime)这样的指标;
2. 应在具体的运行平台上进行评估、衡量
Guideline 1-4:
先看看两种轻量化模型的runtime分析
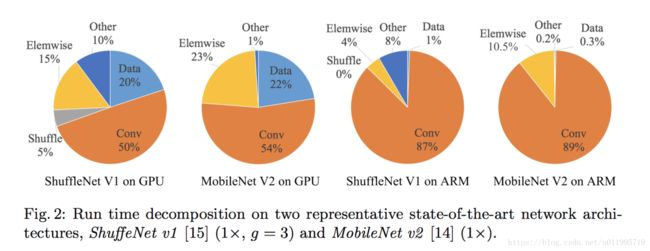
可以发现,模型的runtime主要由卷积主导,但不是绝对主导,模型的runtime还受到 data I/O , data shuffle, element-wise operations(AddTensor, ReLU,etc)的影响,因此可知道要设计一个轻量模型,应该综合考虑那些会影响runtime的因素。基于上述发现,该文从不同角度进行分析模型runtime,并提出四个设计轻量模型的guidelines
G1. Equal channel width minimizes memory access cost(MAC)
先理论分析,再试验验证:
基本假设与条件,假设内存足够大一次性可存储所有feature maps and parameters;卷积核大小为1*1 ;输入通道有c1个;输出通道有c2个;feture map的分辨率为 h*w;
则 the flops of the 1*1 convolutions is
B=hwc1c2 B = h w c 1 c 2 ;
MAC=hw(c1+c2)+c1c2 M A C = h w ( c 1 + c 2 ) + c 1 c 2
从MAC公式,以及B的公式,以及均值不等式 (c1−c2)2≥0 ( c 1 − c 2 ) 2 ≥ 0 ,
可以推出: MAC≥2hwB‾‾‾‾√+Bhw M A C ≥ 2 h w B + B h w
推到过程如下
(c1−c2)2≥0⇒(c1+c2)2≥4c1c2⇒ ( c 1 − c 2 ) 2 ≥ 0 ⇒ ( c 1 + c 2 ) 2 ≥ 4 c 1 c 2 ⇒
(c1+c2)≥2c1c2‾‾‾‾√⇒ ( c 1 + c 2 ) ≥ 2 c 1 c 2 ⇒
hw(c1+c2)≥2hw∗hwc1c2‾‾‾‾‾‾‾‾‾‾‾‾√⇒ h w ( c 1 + c 2 ) ≥ 2 h w ∗ h w c 1 c 2 ⇒
hw(c1+c2)+c1c2≥2hw∗B‾‾‾‾‾‾‾√+c1c2⇒ h w ( c 1 + c 2 ) + c 1 c 2 ≥ 2 h w ∗ B + c 1 c 2 ⇒
MAC≥2hwB‾‾‾‾√+Bhw M A C ≥ 2 h w B + B h w
从公式中我们可以得出MAC的一个下界,即当c1==c2 时,MAC取得最小值。
试验验证,这仅是理论分析,实际情况中,内存是没办法达到要求的,因此需要用试验来验证是否当c1==c2时,MAC达到下限,从而较少runtime。
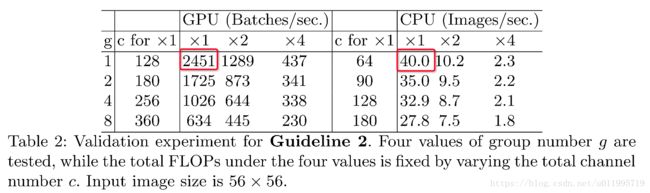
该文在flops相同,并采取4种不同的c1:c2比值分别在gpu 和 arm上进行试验,试验结果如下表:

可以发现,当c1==c2时,无论在GPU平台还是ARM平台,均获得了最快的runtime
(Ps: 抛出一个疑问:从表中发现,随着c1:c2值的增加,速度变快,那么当c1 大于c2的情况下,是否会更快呢?
不过在实际应用中,我们输出的feature maps数量还是会小于输入的)
通过理论及试验结果的分析,得出G1
G2 Excessive group convolution increases MAC
先理论分析,再试验验证:
同G1中一样,假设 卷积核大小为1*1 ;输入通道有c1个;输出通道有c2个;feture map的分辨率为 h*w;group 为g
则
MAC=hw(c1+c2)+c1c2g=hwc1+Bgc1+Bhw; M A C = h w ( c 1 + c 2 ) + c 1 c 2 g = h w c 1 + B g c 1 + B h w ;
B=hwc1c2g B = h w c 1 c 2 g
文中是这样分析的,当fixed input shape c1*h*w and the computational cost B, MAC increases with the growth of g.
但是g的变动,B也变动了呀!如何做到固定 c1*h*w 和B ,去分析MAC 随g的变化呢?
实在想不明白,暂且跳过~
理论分析得出,g的增加,会导致MAC的增加,那么实际情况是不是这样? 请看试验结果
可以发现,当g=1时,速度达到最快,随着g的增加,速度逐渐变慢
G3 Network fragmentation reduces degree of parallelis
理论上,网络的碎片化虽然能给网络的accuracy带来帮助,但是在平行计算平台(如GPU)中,网络的碎片化会引起并行度的降低,最终增加runtime,同样的该文用实验验证,详细可看论文中的表3
G4 Element-wise operations are non-negligible
从图2中可以看到, element-wise operations也占了不少runtime,尤其是GPU平台下,高达15%。什么是element-wise operations? 如ReLU、AddTensor及AddBias等这一类的操作就属于element-wise operations. 这一类操作,虽然flops很低,但是MAC很大,因而也占据相当时间。同样地,通过实验分析element-wise operations 越少的网络,其速度是否越快? 答案是肯定的,详情可查看原文表4.
综上(G1-4),可以得出设计轻量级网络的四个指导方针:
- 卷积核数量尽量与输入通道数相同(即输入通道数等于输出通道数);
- 谨慎使用group convolutions,注意group convolutions的效率;
- 降低网络碎片化程度;
- 减少元素级运算
简单回顾一下,早一批的轻量级网络都违背了哪些guideline。
ShuffleNet V1 严重依赖组卷积(违反 G2)和瓶颈形态的构造块(违反 G1)。MobileNet V2 使用倒置的瓶颈结构(违反G1),并且在“厚”特征图上使用了深度卷积和 ReLU 激活函数(违反了 G4)。
有了以上四个指导方针,就可以开始设计新的网络(ShuffleNet V2)啦
ShuffleNet V2
ShuffleNet V2 的结构是在ShuffleNet V1基础上进行改进,先简单回顾ShuffleNet V1,详细可参见博客轻量化网络:ShuffleNet
在ShuffleNet V1中,特色在于:
1. pointwise group convolution , 这违反了本文提出的G2; 2. channel shuffle
ShuffleNet V1还采用了 bottleneck-like 结构,在bottleneck unit中,shortcut connection中的element-wise operations——add tensor,又违反了G4;
接下来,主角登场,看看ShuffleNet V2
ShuffleNet V2主要结构是多个blocks堆叠构成,block又分为两种,一种是带Channel Spilit的,一种是带Stride=2的(为了降分辨率)
我将分三个部分剖析 ShuffleNet V2:分别是
1. 带Channel Spilit的block;
2. 带Stride=2的block;
3. ShuffleNet V2 的整体结构
第一:带Channel Spilit的block
先看看Channel Split的是长什么样,它又是如何从ShuffleNet V1中 ,并参照G1-4之后演变而来的呢?
图(a)为ShuffleNet V1中的block,(c)为ShuffleNet V2 中带Channel Split的block

我们发现,不同之处有四处,这就一一道来:
1. 增加了Channel Split ,这这这,这是为什么,看没明白
2. 两处1*1的Group Conv变成了 1*1 Conv, 这遵循了G2
3. Add 操作变成了 Concat,这遵循了G4
4. Channel Shuffle 移到了最后面,这个东西就想多说两句了,在ShuffleNet V1当中,Channel Shuffle 是因Group Convolution 带来的信息流通不畅而设计的,这里取消掉了Group Conv,自然没必要放在里面了,这个可以参看原文,或者我之前的博客有分析到;
然后为什么放在这里了呢? 我们看到,一开始Channel Split,会有一部分的Channel没有被“动”过(即,没有被卷积),如果在送入下一个block时,不“搞一搞”,直接送下去的话, 还是会造成信息流通不畅的问题,因此在这里加一个 Channel Shuffle 。
正如ShuffleNet V1中 3.1标题:Channel Shuffle for Group Convolutions,那么在ShuffleNet V2 中的这个block,是否可以理解为:Channel Shuffle for Channel Split 呢??
第二,带Stride=2的block;
为什么要带Stride=2的block? 因为之前都没有降分辨率啊!
图(b)为ShuffleNet V1中的block,(d)为ShuffleNet V2 中带Channel Split的block
可以看出,不同之处有:
- 左路3*3 AVG Pool 换成了 3*3的DWConv + 1*1 Conv 用来降低分辨率;
- 右路的两个1*1 Goup Conv 变成了1*1 Conv, 遵循了G2,看来ShuffleNet V2 是彻底地摒弃了 Group Convolution啊!
- Concat 之后增加了一个 Channel Shuffle; 咦,为什么有Channel Shuffle? 哪里引起了信息流通不畅嘛? 如果没有,那么Channel Shuffle的意义又是什么呢?
第三部分:ShuffleNet V2 的整体结构
如下表:

第一列,Layer中,大部分都能看得明白,这里主要将 Stage里边,可以发现,每个Stage首先由一个带Stride=2的block将feature maps 降分辨率,然后重复的使用数个带Channel Split的block进行“搞特征”
至此,ShuffleNet V2的结构扒拉差不多了。
以上讲的都是优化速度,那么精度如何? 不用说,肯定不赖,那么,为什么还能保持高精度?原因有两个:
the high efficiency in each building block enables using more feature channels and larger network capacity. (自己感受一下吧)
feature reuse !! 又看到它了,DenseNet (CVPR-2017 Best Paper)将 feature reuse用到了极致,详情可参见博客:https://blog.csdn.net/u011995719/article/details/76687476
ShuffleNet V2是如何有特征重用这一特点的呢? 我们可以faxing,在带Channel Split的block中,最后会有一部分(这里是去二分之一,即一半)的Channel 是没有动过的,这些Channel会流到下一个Block中,被再次利用
原文中的图4,没看明白,就不瞎扯了。
由于前面讲太多了,实验部分就不讲了,一句话,ShuffleNet V2 分别在ImageNet2012和COCO任务上,以及不同的平台——GPU and ARM上,精度速度都很OK啊,都很good
疑问:
最后还是有一些疑问,总结如下:
1.G2分析中,B会受到g的影响而变化,那么文中提到,在让B不变的情况下,g的增加会导致MAC的增加,这应该怎么理解呢?
2.Channel Split 具体的意义是什么?
3.在带Channel Split的block中,是否可以理解为:Channel Shuffle for Channel Split ?
4.带Stride = 2 的block中采用了Channel Shuffle,这里采用Channel Shuffle的意义是什么? 为什么要去Shuffle?
如果有朋友理解以上4个问题,麻烦在评论区留言呗~~谢谢!
PS:以上所有均是个人观点,不代表原文作者观点,若有不正确的地方,请大家指正,谢谢!
转载请注明出自:https://blog.csdn.net/u011995719/article/details/81409245,谢谢!