极智AI | 比特大陆 SE5 边缘盒子 caffe SSD 量化与转换部署模型
本教程详细记录了在比特大陆 SE5 边缘盒子上对 caffe SSD 检测模型进行量化和转换部署模型的方法。
文章目录
-
- 1、准备 ssd 模型
- 2、转换 fp32 bmodel
-
- 2.1 转 fp32 bmodel
- 2.2、模型精度验证
- 3、Int 8 量化与模型转换
-
- 3.1 模型转换 fp32umodel
- 3.2 模型转换 int8 umodel
-
- 3.2.1 准备lmdb数据集
- 3.2.2 生成 int8 umodel
- 3.3 Int8 umodel 转换 Int8 bmodel
首先介绍一下 BMNETC 转换工具,在比特大陆的 SDK 中,BMNETC 是针对 caffe 的模型编译器,可将模型的 caffemodel 和 prototxt 编译成 BMRuntime 执行所需的 bmodel。
BMNETC 工具的传参如下:
/path/to/bmnetc [--model=<path>] \
[--weight=<path>] \
[--shapes=<string>] \
[--net_name=<name>] \
[--opt=<value>] \
[--dyn=<bool>] \
[--outdir=<path>] \
[--target=<name>] \
[--cmp=<bool>] \
[--mode=<string>] \
[--enable_profile=<bool>]
[--show_args]
[--check_model]
其中传参的含义如下:

下面我们开始了。
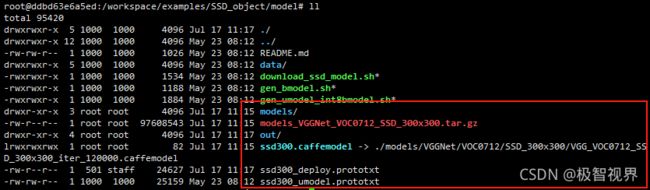
1、准备 ssd 模型
创建一个 download_ssd_model.sh
cd /workspace/examples/SSD_object/model
touch download_ssd_model.sh
在以上脚本中加入如下内容:
# download_ssd_model.sh
#-----------------------------------------
# SSH: Single Stage Headless Face Detector
# Download script
#-----------------------------------------
#!/bin/bash
url="https://docs.google.com/uc"
method_name="export=download"
file_id="0BzKzrI_SkD1_WVVTSmQxU0dVRzA"
file_name="models_VGGNet_VOC0712_SSD_300x300.tar.gz"
cur_dir=${PWD##*/}
target_dir="./"
if [ ! -f ${file_name} ]; then
echo "Downloading ${file_name}..."
# wget -c --no-check-certificate 'https://docs.google.com/uc?export=download&id=0BzKzrI_SkD1_WVVTSmQxU0dVRzA' -O models_VGGNet_VOC0712_SSD_300x300.tar.gz
# wget -c "${url}?${method_name}&id=${file_id}" -O "${target_dir}${file_name}"
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id='${file_id}'' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=${file_id}" -O "${target_dir}${file_name}" && rm -rf /tmp/cookies.txt
echo "Done!"
else
echo "File already exists! Skip downloading procedure ..."
fi
echo "Unzipping the file..."
tar -xvzf "${target_dir}${file_name}" -C ${target_dir}
sync
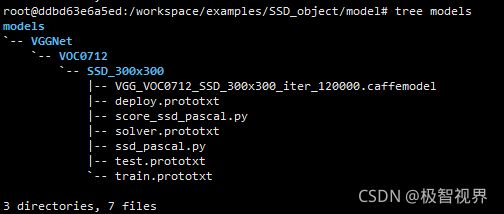
ln -sf ./models/VGGNet/VOC0712/SSD_300x300/VGG_VOC0712_SSD_300x300_iter_120000.caffemodel ssd300.caffemodel
ln -sf ./models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt ssd300_deploy.prototxt
echo "Cleaning up..."
#rm "${target_dir}${file_name}"
echo "All done!"
#https://drive.google.com/file/d/0BzKzrI_SkD1_WVVTSmQxU0dVRzA/view
直接执行上述脚本可能会下载不了,需要。
实际下载链接为 这个
下载文件存放地址:
/workspace/examples/SSD_object/model/models_VGGNet_VOC0712_SSD_300x300.tar.gz
![]()
再次执行上述脚本 ./download_ssd_model.sh
2、转换 fp32 bmodel
2.1 转 fp32 bmodel
创建 gen_fp32_bmodel.sh
touch gen_fp32_bmodel.sh
在以上脚本中加入如下内容:
#!/bin/bash
model_dir=$(dirname $(readlink -f "$0"))
echo $model_dir
top_dir=$model_dir/../../..
sdk_dir=$top_dir
export LD_LIBRARY_PATH=${sdk_dir}/lib/bmcompiler:${sdk_dir}/lib/bmlang:${sdk_dir}/lib/thirdparty/x86:${sdk_dir}/lib/bmnn/cmodel
export PATH=$PATH:${sdk_dir}/bmnet/bmnetc
# modify confidence_threshold to improve inference performance
sed -i "s/confidence_threshold:\ 0.01/confidence_threshold:\ 0.2/g" ${model_dir}/ssd300_deploy.prototxt
#generate 1batch bmodel
mkdir -p out/ssd300
bmnetc --model=${model_dir}/ssd300_deploy.prototxt \
--weight=${model_dir}/ssd300.caffemodel \
--shapes=[1,3,300,300] \
--outdir=./out/ssd300 \
--target=BM1684
cp out/ssd300/compilation.bmodel out/ssd300/f32_1b.bmodel
#generate 4 batch bmodel
mkdir -p out/ssd300_4batch
bmnetc --model=${model_dir}/ssd300_deploy.prototxt \
--weight=${model_dir}/ssd300.caffemodel \
--shapes=[4,3,300,300] \
--outdir=./out/ssd300_4batch \
--target=BM1684
cp out/ssd300_4batch/compilation.bmodel out/ssd300_4batch/f32_4b.bmodel
#combine bmodel
bm_model.bin --combine out/ssd300/f32_1b.bmodel out/ssd300_4batch/f32_4b.bmodel -o out/fp32_ssd300.bmodel
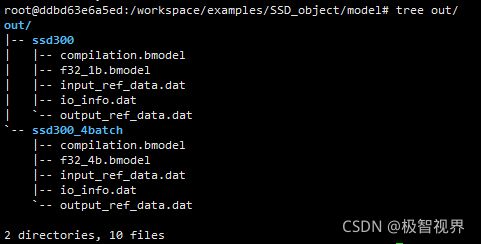
编译生成的模型文件目录树:
2.2、模型精度验证
cd /workspace/scripts/
source envsetup_cmodel.sh
bmrt_test --context_dir=./out/ssd300/
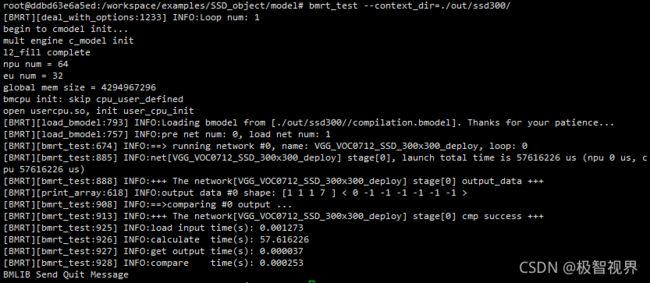
有 “+++ The network[ssd300-caffe] stage[0] cmp success +++” 的提示,则模型编译流程正确,与原生模型的精度一致。
此外,BMNETC 还有 python 版本支持,使用方式如下:
import bmnetc
compile fp32 model
bmnetc.compile(
model = "/path/to/prototxt", ## Necessary
weight = "/path/to/caffemodel", ## Necessary
outdir = "xxx", ## Necessary
target = "BM1682", ## Necessary
shapes = [[x,x,x,x], [x,x,x]], ## optional, if not set, default use shape in prototxt
net_name = "name", ## optional, if not set, default use the network name in prototxt
opt = 2, ## optional, if not set, default equal to 2
dyn = False, ## optional, if not set, default equal to False
cmp = True, ## optional, if not set, default equal to True
enable_profile = False ## optional, if not set, default equal to False
)
bmnetc 执行成功后,将在指定的文件夹中生成一个 compilation.bmodel 的文件,这个文件其实就是转换成功的 fp32 bmodel,是可以直接用于模型推理的。 若在执行 bmnetc 传参 cmp=true,则会在指定的文件夹中生成一个 input_ref_data.dat 和一个 output_ref_data.dat,可用于 bmrt_test 验证生成的 fp32 bmodel 在SE5盒子上运行时结果是否正确。其中:
- input_ref_data.dat:网络输入参考数据
- output_ref_data.dat:网络输出参考数据
3、Int 8 量化与模型转换
3.1 模型转换 fp32umodel
在比特大陆 SE5 盒子上,支持 int8 低比特精度模型的部署。 Qantization-Tools 是比特大陆SDK中提供的模型量化工具,可接主流框架(caffe、mxnet、tf、pytorch、darknet)出的 32 比特浮点网络模型,生成 8 比特的定点网络模型。
Quantization-Tools 工具架构如下:
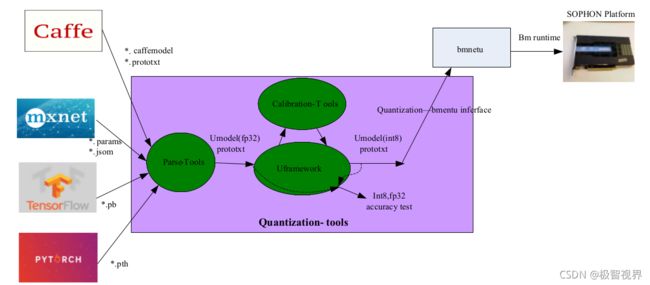
基于 AI 训练框架的模型首先需要借助于量化工具转换转换成 fp32umodel,基于 fp32umodel 后续量化流程已经跟开源框架解耦,作为通用流程执行 int8 量化校准。 比特大陆量化平台框架参考 caffe 框架,因此天然支持 caffemodel,在 caffemodel 无需借助量化工具进行 fp32umodel 的转换,可直接作为 int8 校准的输入。但 tf、pytorch、mxnet、darknet 出来的模型必须先通过量化工具转换为 fp32umodel,在进行进一步的量化。
3.2 模型转换 int8 umodel
我们这里使用的是 caffe ssd model,无需通过量化工具进行 fp32umodel 的转换,直接进行 int8 的量化,主要骤如下:
-
准备 lmdb 数据集
-
生成 int8umodel
-
生成 int8bmodel
3.2.1 准备lmdb数据集
将校准数据集转换成 lmdb 格式,供后续校准量化使用。
lmdb 数据集合的生成,有两种方式:
- 一是通过 convert_imageset 工具直接针对测试图片集合生成;
- 二是通过 u_framework 框架接口来生成,主要针对级联网络,后级网络的输入依赖前级网络的输出,例如 mtcnn;
这里主要使用 convert_imageset 工具来生成校准集,可以参考我的这篇《【经验分享】使用 caffe SSD 生成 VOC0712 lmdb 数据集》来制作 VOC0712 lmdb 数据集。
将生成的 lmdb 放到目录 /workspace/examples/SSD_object/model/data/VOC0712/lmdb
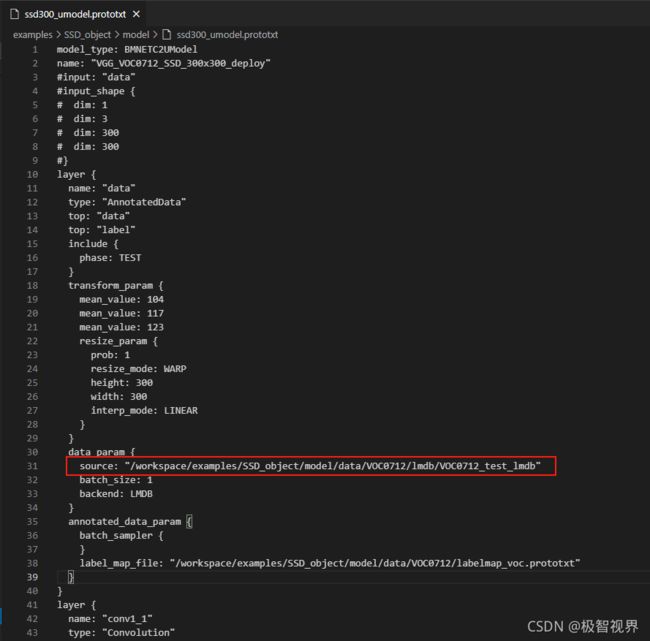
修改 /workspace/examples/SSD_object/model/ssd300_umodel.prototxt 中
3.2.2 生成 int8 umodel
比特大陆的 SDK 内提供了转换的工具,可以直接把 fp32umodel(.caffemodel) 转换成中间临时模型 (int8umodel)。 量化时使用 calibration_use_pb 来执行校准,命令如下:
calibration_use_pb \
release \ #固定参数
-model= PATH_TO/**.prototxt \ #描述网络结构的文件
-weights=PATH_TO/**.fp32umodel \#网络系数文件(caffemodel可以直接使用)
-iterations=1000 \ #迭代的次数(定点化过程中使用多少张图片,每次迭代使用一张图片)
-bitwidth=TO_INT8 #固定参数
对于我们这里的 caffe SSD 模型来说就是这样:
calibration_use_pb release \
-model=./ssd300_umodel.prototxt \
-weights=./ssd300.caffemodel \
-iterations=1000 \
-bitwidth=TO_INT8
量化过程很漫长,因为我们用了 VOC0712 比较大的数据集
正常输出产生如下文件:
├── ssd300_deploy_fp32_unique_top.prototxt
├── ssd300_deploy_int8_unique_top.prototxt
├── ssd300.int8umodel
├── ssd300_test_fp32_unique_top.prototxt
├── ssd300_test_int8_unique_top.prototxt
└── ssd300_umodel.prototxt
3.3 Int8 umodel 转换 Int8 bmodel
Int8umodel 作为一个临时中间存在形式,需要进一步转换为可以在比特大陆 SE5 盒子上执行的 bmodel。
这里会使用到比特大陆 SDK 里的 BMNETU 工具:
/path/to/bmnetu -model=<path> \
-weight=<path> \
-shapes=<string> \
-net_name=<name> \
-opt=<value> \
-dyn=<bool> \
-prec=<string> \
-outdir=<path> \
-cmp=<bool> \
-mode=<string>
其中传参的含义如下:

我们这里 caffe SSD 例程中,具体转换命令如下:
mkdir int8model
bmnetu -model=ssd300_deploy_int8_unique_top.prototxt \
-weight=ssd300.int8umodel \
-max_n=1 \
-prec=INT8 \
-dyn=0 \
-cmp=1 \
-target=BM1684 \
-outdir=./int8model
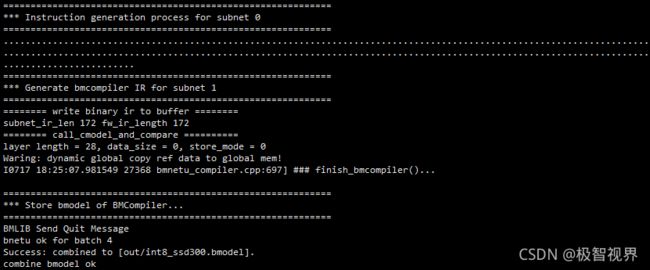
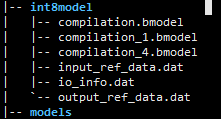
最终会在较长运行时间后生成目标模型 int8bmodel,这个模型就是最后可以直接在比特大陆 SE5 盒子上运行的模型。
int8model
├── compilation_1.bmodel //n,c,h,w (1,3,300,300)
├── compilation_4.bmodel //n,c,h,w (4,3,300,300)
out/
├── int8_ssd300.bmodel //compilation_1.bmodel 和 compilation_4.bmodel进行combine后的bmodel
![]()
好了,收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !
