58同城一面面经:Redis数据更新,是先更新数据库还是先更新缓存?
点击上方“Java基基”,选择“设为星标”
做积极的人,而不是积极废人!
每天 14:00 更新文章,每天掉亿点点头发...
源码精品专栏
原创 | Java 2021 超神之路,很肝~
中文详细注释的开源项目
RPC 框架 Dubbo 源码解析
网络应用框架 Netty 源码解析
消息中间件 RocketMQ 源码解析
数据库中间件 Sharding-JDBC 和 MyCAT 源码解析
作业调度中间件 Elastic-Job 源码解析
分布式事务中间件 TCC-Transaction 源码解析
Eureka 和 Hystrix 源码解析
Java 并发源码
来源:blog.csdn.net/qq_41689567/
article/details/103664475
项目部分:
基础部分:
-
(1)先更新数据库,再更新缓存
(2)先删缓存,再更新数据库
(3)先更新数据库,再删缓存
存粒度控制

项目部分:
1、项目背景还有项目流程
2、从抓包开始到最终显示的时间是多少?
3、有没有调研?每天某个时段的数据流量?
4、如果我在这边频繁刷流量,大约多长时间可以发现异常??
5、redis作为高速缓存和数据库的数据一致性的问题,如果数据更新的话是先更新数据库还是先更新缓存?若果先更新数据库再更新缓存会涉及什么问题
推荐下自己做的 Spring Boot 的实战项目:
https://github.com/YunaiV/ruoyi-vue-pro
基础部分:
1、hashMap底层?为什么jdk1.8要用红黑树实现?什么时候会出现线程不安全?怎么解决线程不安全?默认初始容量是16,如果我改成7,容量会变成7么?为什么?
2、数组和链表的区别是什么?如果一个数组大小超过堆中剩下的内存大小,还会为这个数组分配内存么?
3、常见的线程池有哪些?线程池中一个线程死了,就没有线程了么?如果在线程池中new了一个线程,这个线程是存在还是不存在?线程池中的一些参数有哪些?newCachedPool最大可开启的线程数是多少?
4、如何实现其他线程和主线程的同步?
5、volatile关键字的特性有哪些?
6、10个线程,如何实现和主线程的同步?场景是:10个人在山下聚齐之后才可以一起爬山,怎么实现?不用synchronized关键字、volatile等同步的关键字。
7、平时建mysql表的时候会考虑一些什么?
8、写sql语句的时候where会考虑什么?
redis作为高速缓存和数据库的数据一致性的问题,如果数据更新的话是先更新数据库还是先更新缓存?若果先更新数据库再更新缓存会涉及什么问题
首先,缓存由于其高并发和高性能的特性,已经在项目中被广泛使用。在读取缓存方面,大家没啥疑问,都是按照下图的流程来进行业务操作。
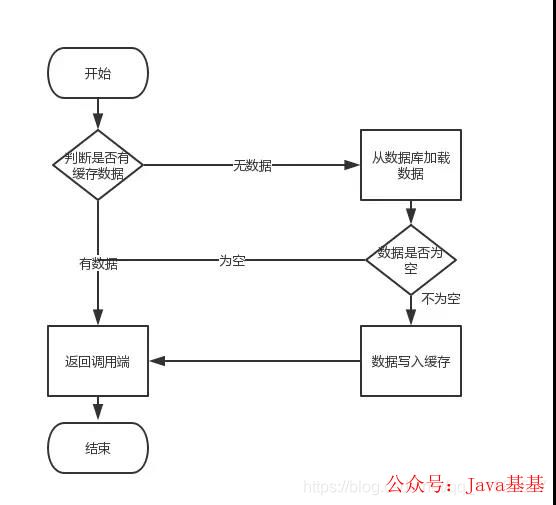 图片
图片
但是在更新缓存方面,对于更新完数据库,是更新缓存呢,还是删除缓存。又或者是先删除缓存,再更新数据库,其实大家存在很大的争议。
先做一个说明,从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。
也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。因此,接下来讨论的思路不依赖于给缓存设置过期时间这个方案。
在这里,我们讨论三种更新策略:
先更新数据库,再更新缓存
先删除缓存,再更新数据库
先更新数据库,再删除缓存
应该没人问我,为什么没有先更新缓存,再更新数据库这种策略。
(1)先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?有如下两点原因。
原因一(线程安全角度)
同时有请求A和请求B进行更新操作,那么会出现
线程A更新了数据库
线程B更新了数据库
线程B更新了缓存
线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
原因二(业务场景角度)
有如下两点:
如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。
如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
接下来讨论的就是争议最大的,先删缓存,再更新数据库。还是先更新数据库,再删缓存的问题。
(2)先删缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
请求A进行写操作,删除缓存
请求B查询发现缓存不存在
请求B去数据库查询得到旧值
请求B将旧值写入缓存
请求A将新值写入数据库
上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
那么,如何解决呢?采用延时双删策略
伪代码如下
public void write(String key,Object data){
redis.delKey(key);
db.updateData(data);
Thread.sleep(1000);
redis.delKey(key);
}
转化为中文描述就是
先淘汰缓存
再写数据库(这两步和原来一样)
休眠1秒,再次淘汰缓存
这么做,可以将1秒内所造成的缓存脏数据,再次删除。
那么,这个1秒怎么确定的,具体该休眠多久呢?
针对上面的情形,读者应该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
如果你用了mysql的读写分离架构怎么办?
ok,在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。
请求A进行写操作,删除缓存
请求A将数据写入数据库了,
请求B查询缓存发现,缓存没有值
请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值
请求B将旧值写入缓存
数据库完成主从同步,从库变为新值
上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
采用这种同步淘汰策略,吞吐量降低怎么办?
ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
第二次删除,如果删除失败怎么办?
这是个非常好的问题,因为第二次删除失败,就会出现如下情形。还是有两个请求,一个请求A进行更新操作,另一个请求B进行查询操作,为了方便,假设是单库:
请求A进行写操作,删除缓存
请求B查询发现缓存不存在
请求B去数据库查询得到旧值
请求B将旧值写入缓存
请求A将新值写入数据库
请求A试图去删除请求B写入对缓存值,结果失败了。
ok,这也就是说。如果第二次删除缓存失败,会再次出现缓存和数据库不一致的问题。
如何解决呢?
具体解决方案,且看博主对第(3)种更新策略的解析。
(3)先更新数据库,再删缓存
首先,先说一下。老外提出了一个缓存更新套路,名为《Cache-Aside pattern》。其中就指出
失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
命中:应用程序从cache中取数据,取到后返回。
更新:先把数据存到数据库中,成功后,再让缓存失效。
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。
这种情况不存在并发问题么?
不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
缓存刚好失效
请求A查询数据库,得一个旧值
请求B将新值写入数据库
请求B删除缓存
请求A将查到的旧值写入缓存
ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
假设,有人非要抬杠,有强迫症,一定要解决怎么办?
如何解决上述并发问题?
首先,给缓存设有效时间是一种方案。其次,采用策略(2)里给出的异步延时删除策略,保证读请求完成以后,再进行删除操作。
还有其他造成不一致的原因么?
有的,这也是缓存更新策略(2)和缓存更新策略(3)都存在的一个问题,如果删缓存失败了怎么办,那不是会有不一致的情况出现么。比如一个写数据请求,然后写入数据库了,删缓存失败了,这会就出现不一致的情况了。这也是缓存更新策略(2)里留下的最后一个疑问。
如何解决?
提供一个保障的重试机制即可,这里给出两套方案。
方案一:
如下图所示
 图片
图片
流程如下所示
更新数据库数据;
缓存因为种种问题删除失败
将需要删除的key发送至消息队列
自己消费消息,获得需要删除的key
继续重试删除操作,直到成功
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:
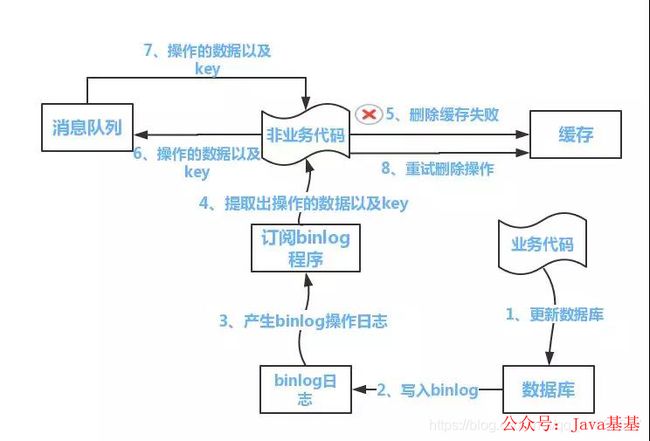 图片
图片
流程如下图所示:
更新数据库数据
数据库会将操作信息写入binlog日志当中
订阅程序提取出所需要的数据以及key
另起一段非业务代码,获得该信息
尝试删除缓存操作,发现删除失败
将这些信息发送至消息队列
重新从消息队列中获得该数据,重试操作。
备注说明:
上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。至于oracle中,博主目前不知道有没有现成中间件可以使用。
另外,重试机制,博主是采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试即可,这些大家可以灵活自由发挥,只是提供一个思路。
存粒度控制
选用全量属性,通用性会更好,也便于维护,像user表这种,用全量属性还可以,
但我们选用缓存就需要考虑性能和空间的问题,只保存我们需要的属性就好了(但后期表结构改了,维护性很差)
缓存穿透:(直接对存储层操作,失去了缓存层的意义)
查询一个数据库中不存在的数据,比如商品详情,查询一个不存在的ID,每次都会访问DB,如果有人恶意破坏,很可能直接对DB造成过大地压力。
解决方案:
当通过某一个key去查询数据的时候,如果对应在数据库中的数据都不存在,我们将此key对应的value设置为一个默认的值,比如“NULL”,并设置一个缓存的失效时间,这时在缓存失效之前,所有通过此key的访问都被缓存挡住了。后面如果此key对应的数据在DB中存在时,缓存失效之后,通过此key再去访问数据,就能拿到新的value了。
常见的则是采用布隆过滤器(可以用很小的内存保留很多的数据),将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被 这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。(布隆过滤器:实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
关于布隆过滤器:
 图片
图片
缓存雪崩:(缓存失效)
缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案:
将系统中key的缓存失效时间均匀地错开,防止统一时间点有大量的key对应的缓存失效;
重新设计缓存的使用方式,当我们通过key去查询数据时,首先查询缓存,如果此时缓存中查询不到,就通过分布式锁进行加锁,取得锁的进程查DB并设置缓存,然后解锁;其他进程如果发现有锁就等待,然后等解锁后返回缓存数据或者再次查询DB。
尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上
本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
假如已经崩溃了:也可以利用redis的持久化机制将保存的数据尽快恢复到缓存里。
缓存无底洞:
为了满足业务大量加节点,但是性能没提升反而下降。
当客户端增加一个缓存的时候,只需要 mget 一次,但是如果增加到三台缓存,这个时候则需要 mget 三次了(网络通信的时间增加了),每增加一台,客户端都需要做一次新的 mget,给服务器造成性能上的压力。
同时,mget 需要等待最慢的一台机器操作完成才能算是完成了 mget 操作。这还是并行的设计,如果是串行的设计就更加慢了。
通过上面这个实例可以总结出:更多的机器!=更高的性能
但是并不是没办法,一般在优化 IO 的时候可以采用以下几个方法。
命令的优化。例如慢查下 keys、hgetall bigkey。
我们需要减少网络通讯的次数。这个优化在实际应用中使用次数是最多的,我们尽量减少通讯次数。
降低接入成本。比如使用客户端长连接或者连接池、NIO 等等。
hashMap底层?为什么jdk1.8要用红黑树实现?什么时候会出现线程不安全?怎么解决线程不安全?默认初始容量是16,如果我改成7,容量会变成7么??为什么?
在JDK1.6,JDK1.7中,HashMap采用位桶+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,HashMap采用位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
不安全原因:
在put的时候,因为该方法不是同步的,假如有两个线程A,B它们的put的key的hash值相同,不论是从头插入还是从尾插入,假如A获取了插入位置为x,但是还未插入,此时B也计算出待插入位置为x,则不论AB插入的先后顺序肯定有一个会丢失 以下是put方法
 图片
图片
在扩容的时候,jdk1.8之前是采用头插法,当两个线程同时检测到hashmap需要扩容,在进行同时扩容的时候有可能会造成链表的循环,主要原因就是,采用头插法,新链表与旧链表的顺序是反的,在1.8后采用尾插法就不会出现这种问题,同时1.8的链表长度如果大于8就会转变成红黑树。
默认容量为16的原因:
关于这个默认容量的选择,JDK并没有给出官方解释,笔者也没有在网上找到关于这个任何有价值的资料。(如果哪位有相关的权威资料或者想法,可以留言交流)
根据作者的推断,这应该就是个经验值(Experience Value),既然一定要设置一个默认的2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。
所以,16就作为一个经验值被采用了。
常见的线程池有哪些?线程池中一个线程死了,就没有线程了么?如果在线程池中new了一个线程,这个线程是存在还是不存在?线程池中的一些参数有哪些?newCachedPool最大可开启的线程数是多少?
常见的线程池:
1、newCachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
这种类型的线程池特点是:
工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活的往线程池中添加线程。如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会造成系统瘫痪。
2、newFixedThreadPool
创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。FixedThreadPool是一个典型且优秀的线程池,它具有线程池提高程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务时,它不会释放工作线程,还会占用一定的系统资源。
3、newSingleThreadExecutor
创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。
4、newScheduleThreadPool
创建一个定长的线程池,而且支持定时的以及周期性的任务执行,支持定时及周期性任务执行。
手撕代码:
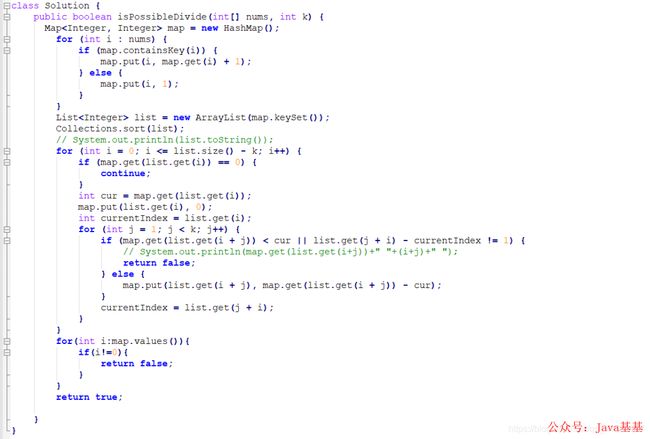
给你一个整数数组 nums 和一个正整数 k,请你判断是否可以把这个数组划分成一些由 k 个连续数字组成的集合。
如果可以,请返回 True;否则,返回 False。
示例 1:
输入:nums = [1,2,3,3,4,4,5,6], k = 4
输出:true
解释:数组可以分成 [1,2,3,4] 和 [3,4,5,6]。
示例 2:
输入:nums = [3,2,1,2,3,4,3,4,5,9,10,11], k = 3
输出:true
解释:数组可以分成 [1,2,3] , [2,3,4] , [3,4,5] 和 [9,10,11]。
示例 3:
输入:nums = [3,3,2,2,1,1], k = 3
输出:true
示例 4:
输入:nums = [1,2,3,4], k = 3
输出:false
解释:数组不能分成几个大小为 3 的子数组。
提示:
1 <= nums.length <= 10^5
1 <= nums[i] <= 10^9
1 <= k <= nums.length
 图片 - END -
图片 - END -
欢迎加入我的知识星球,一起探讨架构,交流源码。加入方式,长按下方二维码噢:

已在知识星球更新源码解析如下:




最近更新《芋道 SpringBoot 2.X 入门》系列,已经 101 余篇,覆盖了 MyBatis、Redis、MongoDB、ES、分库分表、读写分离、SpringMVC、Webflux、权限、WebSocket、Dubbo、RabbitMQ、RocketMQ、Kafka、性能测试等等内容。
提供近 3W 行代码的 SpringBoot 示例,以及超 6W 行代码的电商微服务项目。
获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。
文章有帮助的话,在看,转发吧。
谢谢支持哟 (*^__^*)