【读论文】DDcGAN
DDcGAN: A Dual-Discriminator ConditionalGenerative Adversarial Network for Multi-Resolution Image Fusion
- 简介
-
- 贡献
- 提出的方法
-
- 损失函数
- 网络结构
-
- 生成器结构
- 辨别器结构
- MRI和PET图像融合
-
- 处理思路
- 公式
- 损失函数
- 处理过程
- 训练
- 总结
- 参考
论文: https://ieeexplore.ieee.org/document/9031751
代码: https://github.com/jiayi-ma/DDcGAN
如有侵权请点击蓝字联系博主
简介
和FusionGAN的作者是同一个人,不得不说,真的强。
论文中提出了一种基于CGAN的双鉴别器的图像融合模型,称为DDcGAN,网络结构包含两个鉴别器,分别为了保持融合图像有红外图像和可视图像的重要特征;在训练过程中,希望辨别器无法区分源图像(红外图像和可视图像)和融合图像,这个过程中不需要自己设计特定的融合机制,同时也不需要ground truth图像;论文中提出的方法还可以应用到医学图像融合问题。
因为红外图像的分辨率往往不如可视图像,因此论文中提到的方法可以融合不同分辨率的红外以及可视图像。
贡献
- 论文中提出的方法可以使多模态的图像融合的更好,而不是仅仅与一种源图像有着很高的相似性。
- 双辨别器使得生成器可以得到更充分的训练
- 在多分辨率图像的融合工作上体现更好的性能
- 可以扩展到医学影像的融合
提出的方法
采用双鉴别器的gan,其中Dv用来鉴别融合图像和可视图像;Di用来鉴别融合图像和红外图像,因为我们假设红外图像的分辨率是可视图像的1/16,而融合图像的分辨率和可视图像是相同的,所以我们需要对可视图像进行下采样,采用平均池化(因为与最大池相比,平均池化保留了低频信息,热辐射信息主要以这种形式呈现),再与可视图像进行比较。
损失函数

ψ指的是下采样,两个层的卷积核都是3x3大小,步长为2。
生成器的目标如上图所示,这里设后面的公式为V,即在V的取值最大时(在现在的情况下,辨别器可以较好的辨别图像是融合图像还是可视图像,红外图像),调整G的参数,从而使得辨别器无法很好的分辨融合图像和可视图像,红外图像,即V的值最小。
我自己的理解就是,此时,辨别器已经经历了k次的训练(k是超参数),辨别器相对于训练前,已经可以较好的分辨是融合图像还是可视/红外图像,这时训练生成器,也是训练k次,按照损失函数进行G的参数的调节,从而使得辨别器无法判断图像时融合图像还是可视/融合图像。
辨别器的目标则是最大化上述公式。
在大致了解我们的目标之后,就可以来聊损失函数了。
生成器损失函数
![]()


第一项是为了实现生成器和辨别器之间的对抗,第二项则是为了保证生成图像与红外图像有着尽可能相同的辐射信息,与可视图像有着尽可能相同的纹理信息。
为什么采用下采样的红外图像与融合图像进行比较,文中介绍如下
通过约束下采样融合图像和低分辨率红外图像的像素强度的关系,我们可以显著地防止由于压缩或模糊而导致的纹理信息的丢失以及由于强制上采样而导致的不准确。
第一项中的第一项是促进生成器参数向着生成器认为融合图像是可视图像的概率增加的方向变化,第一项中的第二项是促进生成器参数向着生成器认为融合图像是红外图像的概率增加的方向变化,这两项的作用就是使得辨别器犯错。
第二项中的第一项采用F范数是为了保证生成图像和红外图像的辐射信息尽可能相同,第二项的采用TV范数是为了保证生成图像在纹理上尽可能与可视图像相同。
经过这样的对抗,我们可以保证融合图像和可视/红外图像在辨别器眼里越来越相似,同时我们控制了生成器生成的方向,即向着更多可视纹理和红外辐射的方向变化。
辨别器损失函数

相比生成器来说就简单了,其实就是通过训练使得红外/可视图像辨别器分辨图像是融合图像还是可视/红外图像的能力越来越强。
以可视图像辨别器为例来介绍
这里第一项希望Dv可以把可视图像源图像v识别为可视图像的概率越大越好,即logDv越大越好,-logD越小越好;第二项则是希望Dv可以将融合图像G识别为可视图像的概率越小越好,即Dv(G)越小越好,1-Dv(G)越好越好,-(1-Dv(G))越小越好。第二项同理。
一般来说我们都是先通过生成器G生成融合图像,然后将融合图像和可视/红外图像作为训练数据来训练辨别器k次(这里的k是我们自己设定的,不宜太大,也不宜太小,太大会导致生成器在训练时训练几乎没效果,太小了会导致辨别器训练不到位),然后使用训练好的辨别器再去训练生成器k次,这样一直循环,直到辨别器无法分辨融合图像和可视/红外图像时,就已经训练好了,此时生成器生成的图像就是我们想要的融合图像。论文中的训练与这里有点小出入,当辨别器未完成k次训练,但损失已经到一个阈值之后,就会停止训练,转而训练生成器k次,同样,若生成器也到了一个阈值,也会提前停止。
网络结构
生成器结构

接下来我们一步步来讲这个网络
首先我们对输入的红外图像和可视图像都进行反卷积,这里红外图像经过反卷积生成的图像是高分辨率的红外图像(为啥是高分辨率的,博主不是很了解),反卷积的算子也是经过学习获得的;可视图像也经历了一次反卷积,生成了相同分辨率的特征图,即在连接之前,可视图像先进行了一次处理;然后将反卷积的红外图像与可视图像的特征图进行连接,作为编码器的输入。
接下来数据就来到了编码器,编码器是一个五层的densenet结构,densenet可以加强特征的传播,即每一层都可以使用前面每一层提取的特征,所有的层都使用3x3的卷积核,步长为1,为了避免梯度爆炸/消失,应用批量归一化,ReLU激活函数用于加快收敛。解码器在论文中没有介绍,但是看图的话也可以大致了解,五层cnn,每个层的卷积核都是3x3,最终的输出就是融合图像。
辨别器结构

这里鉴别器的网络结构相对简单一些,但是鉴别器有一个问题,网络中有两个鉴别器,分别促使生成器的融合图像有更多的纹理细节和红外辐射强度信息,但是这两个促进是存在冲突的,即当融合图像中可是图像的细节较好时,红外辐射信息可能会缺失,因此需要对二者进行平衡,文中平衡的方式是当G,Dv和Di一旦有其中一个处理能力较差时,就会多训练这个部分。举例来说,当Di和Dv都可以轻易分辨融合图像和可视图像时,说明需要对G进行训练,而减少对Di和Dv的训练,当Di和Dv的辨别能力较差时,也是进行相同的操作。
每一层都是3x3的卷积核,步长为2,最后一层是一个全连接层,最终的激活函数是tanh,生成一个标量,即是源图像的概率。
MRI和PET图像融合
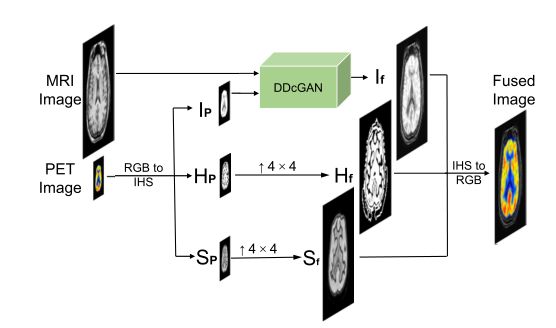
处理思路
关于两种图像的介绍,原文中有大量的描写,这里我们只需要知道PET是有颜色,且分辨率低,MRI可以捕捉结构细节。
我们希望融合之后,融合图像可以保留PET的颜色信息,也可以保留MRI的结构信息。
使用IHS(强度,色调和饱和度)来表示PET图像,之类的色调和饱和度都影响颜色信息,因此我们要保持这两个分量的不变,用强度信息来与MRI图像融合。
如下图所示,可以看到PET图像的I通道(强度通道)的结构细节不够清晰,但是MRI很清晰,因此可以融合强度通道(I通道)与MRI从而弥补PET图像结构信息不足的问题。

这里PET图像的强度通道的信息保存血流之类的信息,而MRI保存软骨结构之类的信息,二者结合之后,就可以得到一个较为完整的图片信息,看到这里就感觉有点熟悉了,这个过程和我们融合红外图像很像,不同就在于红外图像提供热辐射信息,而可视图像提供细节信息。
公式
以下公式为RGB与IHS的转换公式



损失函数
这里和前面的红外图像融合的损失函数大致相同,这里的MRI图像对应可视图像,PET的I通道分量对应红外图像,如下的损失函数一一对应即可。
生成器损失函数
![]()

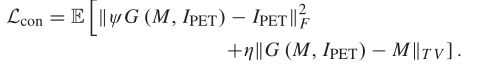
辨别器损失函数

处理过程
处理过程如下,首先将RGB图像转换为IHS表示,然后将I通道与MRI图像进行融合,再将H,和S通道进行上采样(双三次插值),将其上采样至与融合图像相同大小的分辨率,然后再将三个通道转为RGB通道,就是最后的结果。
双三次插值可以参考该博客双三次插值(BiCubic插值)
训练
损失函数中的λ=0.5和η=1.2。
学习率为2x10-3,批量设置为24,衰减为0.75
辨别器使用SGD优化器
生成器使用RMSProp优化器
总结
在GAN的结构上,相比于FusionGAN来说,DDcGAN设置了两个辨别器,分别是保证红外辐射信息和纹理信息,而FusionGAN中仅仅使用可视图像辨别器来使融合图像和可视图像进行对抗,DDcGAN则是将融合图像和红外图像,可视图像都进行对抗,从而使得融合图像尽可能的保留纹理信息和红外辐射信息。
在生成器的网络结构上来说,FusionGAN只是进行了5层卷积,而DDcGAN的网络结构则是采用编码解码器结构,其中编码器采用DenseNet的结构。
以下是论文中给出的图像融合的效果,可见DDcGAN的融合效果有很大的提升。

其他融合图像论文解读
【读论文】Self-supervised feature adaption for infrared and visible image fusion
【读论文】FusionGAN: A generative adversarial network for infrared and visible image fusion
【读论文】DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs
【读论文】DenseFuse: A Fusion Approach to Infrared and Visible Images
参考
[1] DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion