简记Inception系列
《简记Inception系列》
Inception系列模型的发展过程,以及其中利用的很多经典的模块,包括产生的一些结论,在后续的分类网络,包括图像语义分割网络当中的一些模块都是如出一辙的。所以对Inception系列模型的整理和记录,有助于对深度学习模型设计的理解,从演化过程来理解Google团队的科研思路,对于不同的问题的不同解决方案,从而形成自己的创新思维,本文简单记录一下Inception系列网络的各个关键概念。其中BN和LabelSmooth等都是举足轻重的idea,以及对卷积的通道解耦和空间解耦打开了移动端卷积神经网络的大门。
Key Words:Inception moudule、Batch Norm、Factorization into smaller convolutions、Spatial Factorization into Asymmetric Convolutions、Label Smooth
Beijing, 2020
作者:RaySue
Agile Pioneer
文章目录
-
-
- Inceptioin系列的思想
- Inception V1
- Inception V2&V3
-
- Internal Covariate Shift
- 小卷积代替大卷积 Factorization into smaller convolutions
- 空间卷积分解为非对称卷积 Spatial Factorization into Asymmetric Convolutions
- LabelSmooth
- 模型下采样模块
- Inception V4
- Xception
-
- 极致的Inception的进化过程
- Q&A
- 参考
-
Inceptioin系列的思想
-
v1: 多分支的网络结构,采用不同大小的卷积核,拥有不同大小的感受野;不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
-
v2: Batch Normalization:Reducing Internal Covariate Shift
-
v3: Factorization into smaller convolutions即多个小卷积核的串联来代替大卷积核,比如3层3x3的卷积核和一个7x7的卷积核拥有相同的感受野,相当于正则化的7x7的卷积核。
-
v3: Spatial Factorization into Asymmetric Convolutions:利用1x3和3x1的卷积串联来代替3x3的卷积,提高了33%效率,增加了网络的非线性(因为每层都ReLU),减小过拟合的概率,但有一些精度损失,注意在模型初期使用该方案效果不好,建议在中后期 (17 <= grid_size <= 20) 使用
-
v3: Label Smoothing (加入到损失函数中的一种正则化类型,防止模型过度确信某一类别,防止过拟合)
-
v4: 修改了Inception的Stem,添加了Reduction Block
-
XCeption: 假设跨通道相关性和空间相关性可以完全分开映射,解耦通道相关性和空间相关性,深度可分离卷积
Inception V1
Going deeper with Convolutions
- Dimension reductions by 1x1 conv
- 网络更深
- 网络更宽
- 利用1x1 3x3 5x5,增加了网络对尺度的适应性
- 网络最后采用了average pooling(平均池化)来代替全连接层,该想法来自NIN(Network in Network)
GoogLeNet 最早的Inception结构下图左,Inception降维之后的模块下图右,通过1x1的卷积进行降维,能够降低计算量,而且对feature map做了scale,对识别精度有提升。

Inception V2&V3
Inception V2
Inception V3
InceptionV2 主要引入了 batch norm,其余的改变很小,所以把V2和V3放在一起
-
Batch Normalization:Reducing Internal Covariate Shift
-
大卷积分解为小卷积:小卷积的串联可以认为是大卷积的正则表示。
-
卷积空间分解为非对称卷积:GoogLeNet团队发现在网络的前期使用这种分解效果并不好,在中度大小的特征图(feature map)上使用效果才会更好(特征图大小建议在12到20之间)。
-
模型下采样模块融合了pool和conv,ENet的初始下采样估计也是从这里来的。
Internal Covariate Shift
机器学习和深度学习的一个假设就是训练数据和测试数据满足独立同分布。这样通过训练数据获得的模型能够在测试集中获得很好的效果的一个基本保障。
Covariate Shift
统计机器学习中的一个经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。如果不一致,那么就出现了新的机器学习问题,如 transfer learning / domain adaptation 等。而 covariate shift 就是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同即:
P s ( Y ∣ x = X ) = P t ( Y ∣ x = X ) P_s(Y|x = X) = P_t(Y|x=X) Ps(Y∣x=X)=Pt(Y∣x=X)
P s ( x = X ) ≠ P t ( x = X ) P_s(x = X) \neq P_t(x=X) Ps(x=X)=Pt(x=X)
也就是说,经过模型之后的数据分布改变了,但是标签肯定是不会变的,比如分类,还是和以前一样即就是条件概率不变,但是边缘概率不同了,边缘概率是X出现的概率,如果模型无法捕捉数据的分布,那么就无法提取出更具有代表性的抽象特征,直接影响模型的泛化性。
Internal Covariate Shift
深度学习模型学习的就是数据的分布,细化到神经网络的每一层输出的分布,相同的输入,但每轮训练时的分布都是不一致的,和统计学习当中的Covariate Shift如出一辙,这里每层输出的分布就相当于边缘分布的概率密度函数,最终的结果对应的条件概率。
由于底层的参数随着训练更新,导致相同的输入分布得到的输出分布改变了。随着网络层数的加深,输入分布经过多次线性非线性变换,已经被改变了,所以导致了以下问题:
- 上层网络需要不断适应新的输入数据分布,降低学习速度
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止
- 每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎
解决思路
我们要让模型的每一层输出的分布均值和标准差一致,即做数据标准化,使得每层的输入都是均值为0,方差为1的分布。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传

卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一整张特征图当做一个神经元进行处理。BN计算的是输出结果的每个 channel 的均值和方差,即BN针对每个样本 x x x 的单个维度 x i x_i xi,计算大小为mini-batch中n个 x i x_i xi的均值与方差,以及后续的平移和缩放。
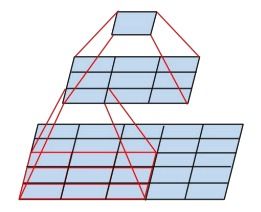
小卷积代替大卷积 Factorization into smaller convolutions
大卷积是为了增大感受野,小卷积可以提高运算速度,降低过拟合的风险,而且小卷积的叠加可以达到和大卷积一样的感受野,并且参数量也相应的减少了,可以认为小卷积的堆叠可以作为大卷积的正则表示。
Inception V3 中将大卷积分解为小卷积如下图所示:
空间卷积分解为非对称卷积 Spatial Factorization into Asymmetric Convolutions
利用1x3和3x1两层卷积达到的感受野和3x3的卷积是一样的,如下图所示,而且参数量又减小了,计算量也减少了。实际上使用的时候发现非对称卷积在网络的开始阶段使用效果不好,但是在中期,在 m * m 的特征图上 m的范围在 12 到 20 的时候结果很好,在这个水平上使用1x7和7x1最为理想。

两种分解可以让网络更深,而且增加了非线性表达,V3 的网络输入从224x224变为了299x299。
LabelSmooth
参见我的博客: https://blog.csdn.net/racesu/article/details/107214035
模型下采样模块

对于下采样,上图有两种方式,先池化再作Inception卷积,或者先作Inception卷积再作池化。但是方法一(左图)先作pooling(池化)会导致特征表示遇到瓶颈(特征缺失),方法二(右图)是正常的缩小,但计算量很大。

为了兼顾特征表示和降低计算量,将采用上图进行下采样模块,使用两个并行化的模块来降低计算量(卷积、池化并行执行,再进行合并)。和分割网络ENet的初始处的下采样方式思路基本一致。
Inception V4
Inception V4
Inception V4研究了Inception模块与残差连接的结合。ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。并讨论了残差连接对学习的影响。
原始的残差模块如下图左所示,融合了Inception后如下图右所示:

Xception
-
Xception 是 Google 继 Inception 后提出的对 Inception-v3 的另一种改进。
-
作者认为,通道之间的相关性 与 空间相关性 最好要分开处理。采用 Separable Convolution(极致的 Inception 模块)来替换原来 Inception-v3中的卷积操作。
Inception模块背后的想法是,通过将其明确地分解为一系列可独立查看跨通道相关性和空间相关性的操作,从而使此过程更轻松、更高效。更准确地说,典型的Inception模块首先通过一组1x1卷积查看跨通道相关性,然后将输入数据映射到小于原始输入空间的3或4个独立空间中,然后将这些相关性映射到这些较小的3D空间中,通过常规3x3或5x5卷积。实际上,Inception背后的基本假设是跨通道相关性和空间相关性充分解耦,因此最好不要将它们共同映射。
极致的Inception的进化过程
在 Inception 中,特征可以通过 1x1 卷积,3x3 卷积,5×5 卷积,pooling 等进行提取,Inception 结构将特征类型的选择留给网络自己训练,也就是将一个输入同时输给几种提取特征方式,然后做 concat 。Inception-v3的结构图如下:

对 Inception-v3 进行简化,去除 Inception-v3 中的 avg pool 后,输入的下一步操作就都是 1×1 卷积:

提取出 1x1 卷积的公共部分:

Xception(极致的 Inception):先进行普通卷积操作,再对 1×1 卷积后的每个channel分别进行 3×3 卷积操作,最后将结果 concat:

注意:作者发现,在“极致的 Inception”模块中,用于学习空间相关性的 3×3 的卷积,和用于学习通道间相关性的 1×1 卷积之间,不使用非线性激活函数时,收敛过程更快、准确率更高。
Q&A
Q1: 1x1卷积的作用有哪些:
A1:
- 用于修正激活函数ReLU
- 对channel维度进行升维或降维
- 对通道信息进行融合,相当于对featureMap做了一个scale
- 代替全连接层
Q2: 解释一下covariate shift?
A2:
- convariate shift 其实就是条件概率p(y|x)相同,边缘概率p(x)不同的一个偏移
- 这里面的边缘概率代表的就是某一样本x出现的概率,条件概率代表的是某一样本x出现且这一样本属于某一类y的概率
Q3: 为什么BN层需要 γ \gamma γ 和 β \beta β 做平移变换?
A3: 强制的数据归一化操作会影响模型训练,比如对某一层网络A输出的数据做归一化,然后传入到下层网络B中,未做归一化之前可能A会分布在S型激活函数的两侧,而归一化后就会强制的让其分布在S型激活函数的中间了,这会直接导致模型不work,而如果加入两个学习参数 γ \gamma γ做放缩 β \beta β做平移就能够重构标准化后的分布仍旧保持原来的分布的特征但是却能够限制输出的分布在合理的范围内,防止过大过小,落入激活函数饱和区域。
Q4: Inception 提出的通用设计准则?
A4:
- 避免representation瓶颈,尤其是网络前面的层。representation就是activations,activations的size应该是逐渐减减小的
- 更高维的representation更容易处理,更容易训练(收敛)
- 可以在低维上进行空间聚合(Spatial aggregation),比如执行一个3x3卷积之前,可以先使用1x1卷积进行降维,几乎不会影响representation能力。解释是相连神经元之间具有很强的相关性,信息有冗余
- 网络宽度和深度的平衡。两者的平衡能带来更好的性能
Q5: 极致的Iception和MoblieNet的深度可分离卷积相同吗?
A5: 不相同,
- depthwise和pointwise的顺序相反,Inception,先利用1x1卷积来映射通道相关性,然后再分别对每个输出通道映射空间相关性,
- 第一次操作后是否存在非线性。在Inception中,两个操作都跟随ReLU非线性。即分离卷积在非线性之后。实验证明分离卷积在线性操作后的效果更好,所以点卷积之后不要有激活函数。
参考
https://blog.csdn.net/u011021773/article/details/80791650
ICS问题
https://blog.csdn.net/zxyhhjs2017/article/details/79405591
https://blog.csdn.net/u013841196/article/details/80956828
https://blog.csdn.net/lx10271129/article/details/78984623
各种 Normalization
https://zhuanlan.zhihu.com/p/127042277
https://blog.csdn.net/lk3030/article/details/84847879