深度学习网络篇——Inception v3
文章目录
-
- 先夸一夸我们的GoogLeNet
- Inception v3的薅羊毛顺序
- 第一部分 总体设计原则
-
- 1、避免表达的瓶颈,特别是在网络前面的部分
- 2、高维度特征更适合在网络局部中处理
- 3、在较低维度的输入上进行空间聚合,不会降低网络表示能力
- 4、平衡网络的宽度和深度
- 第二部分 分解大卷积核
-
- 1、大卷积分解为小卷积
- 2、非对称卷积的空间分解
- 第三部分 使用辅助分类器
- 第四部分 有效网格尺寸缩减
- 第五部分 Inception-v2
- 第六部分 通过标签平滑进行模型正则化
- 第七部分 训练方法
- 第八部分 低分辨率输入的性能
- 第九部分 实验结果
- 第十部分 总结
Rethinking the Inception Architecture for Computer Vision计算机视觉初始结构的再思考再思考......
先夸一夸我们的GoogLeNet
概括来说,它占用计算资源少,性能还超级好 。
来对比一下其他的网络: GoogleNet有5,000,000----五百万个参数; 它的前辈AlexNet有60,000,000----六千万个参数(12倍鸭) ; VGGNet 有 180,000,000----一千八百万个参数(36倍鸭鸭);
----这些参数如果都能变成钱我们大概可以去环游世界了,嗯,美元就行。
Inception的计算成本比很多网络低得多,所以可以用在需要以合理的成本处理大量数据的场景中,或者在存储器或计算能力有限的场景中。虽然我们也可以针对目标存储器和通过计算技巧优化某些操作的执行来解决大数据或存储不够的问题,也可以用于优化Inception体系结构,从而再次扩大效率差距,但是这会增加额外的复杂性。
那我们节约出来的计算资源可以用来干什么呢?
可以用来继续扩大网络的架构,增加它的容量,适用于更大的数据集。
Inception架构是很复杂的,如果Inception架构只是简单地按比例放大,那么会增加大量计算,我们之前节约出来的收益会被挥霍一空。所以我们要想一种办法, 有效的利用计算机的资源来扩大卷积网络。这就是Inception v3要讨论的内容。
Inception v3的薅羊毛顺序
我们按照Inception v3的论文顺序将本篇文章的内容组织如下:
1.可以有效扩展卷积网络的一般原则和优化思想。
2. GoogLeNet 中的降维处理----分解卷积核
3. 辅助分类器的作用
4. 如何有效缩减特征图网格尺寸
5. 通过估计训练过程中标签dropout的边缘化效应来规范分类器层的机制。
6. 低分辨率输入的性能评估
7. Inception的优越性(对比其他模型)
第一部分 总体设计原则
Emmm,以下这些原则只是原理性的,还需要进一步的实验证据来评估它们的准确性和有效性,但是作者指出,凡是严重背离这些原则的框架表现都不好,但是如果发现有背离这个原则的设计,进行修正后总体上是能改善网络的。但是作者同时指出单纯使用这些原则改善网络并不容易,只有在模棱两可的情况下才能更好地使用它们。
1、避免表达的瓶颈,特别是在网络前面的部分
前馈网络可以用一个从输入层到分类器或回归器的无环图来表示,信息的流动方向就是从输入到输出,对于分离输入和输出的任何切割,都可以得到通过切割面的信息量。
- 表示的尺寸(也就是特征图的大小)应该从输入逐渐减少到输出,然后才能得到用于当前任务的最终表示,不应该出现急剧的衰减,如果某些层(尤其是卷积层)的信息过度的压缩,将会丢失大量的信息,对模型的训练也造成了困难。
- 也不能仅仅通过维度得到信息,因为它已经丢弃了许多重要特征例如相关结构,维度只能代表信息的粗略估计。
2、高维度特征更适合在网络局部中处理
在网络中对高维的表达进行局部的处理,在卷积网络中逐步增加非线性激活响应可以解耦合更多的特征,那么网络就会训练的更快。
3、在较低维度的输入上进行空间聚合,不会降低网络表示能力
例如在进行大尺寸的卷积(如3*3)之前,我们可以在空间聚合前先对输入信息进行降维处理,因为我们假设在特征图上,临近单元上的表达具有很高的相关性,如果输出是为了空间聚合,那么临近单元的强相关性在降维过程中信息损失会很少,考虑到这些信号容易压缩,降维会加速学习过程。
4、平衡网络的宽度和深度
增加宽度或深度都会带来性能上的提升,两者同时增加带来了并行提升,但是要考虑计算资源的合理分配,才能最大化的提高模型的性能。
第二部分 分解大卷积核
GoogLeNet 网络优异的性能主要源于大量使用降维处理。这种降维处理可以看做卷积网络的因式分解,就比如一个11的卷积后面跟着一个33的卷积。因为在一个计算机视觉网络中,相邻激活响应的输出是高度相关的,所以在聚合前减少这些激活响应的数目可以得到近似的局部表达。所以我们要讨论几种分解卷积的方法来提高计算效率。
因为Inception结构是全卷积,每一个激活值对应一个权重,因此减小计算量意味着减少参数,所以通过解耦和参数,可以加快训练。节省下来的内存和计算资源就可以用于增加过滤器组。
1、大卷积分解为小卷积
虽然大滤波器学习到的东西多,但是它引入的计算量也大(平方增长),所以我们考虑用一个参数较少的多层网络代替这个大卷积层。多层的表达能力不会受到影响,同时增加了非线性修正,对模型的效果进行了改善。
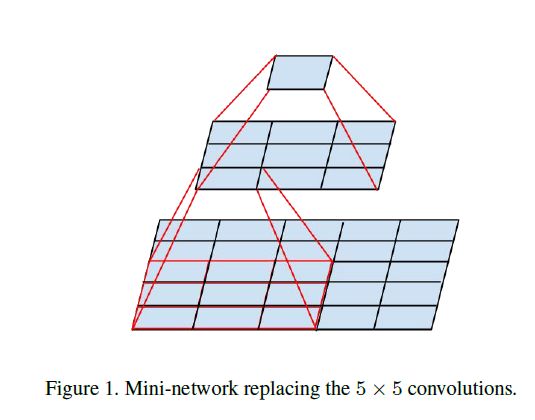
这样的分解替代是否会带来表达的损失?如果我们只想分解计算中线性的部分,直接在第一层用线性激活不就行了?
对照实验证明线性激活不如Relu,作者认为变量的空间加强增益是能被网络学习的,尤其是在输出激活被batch normalize以后。
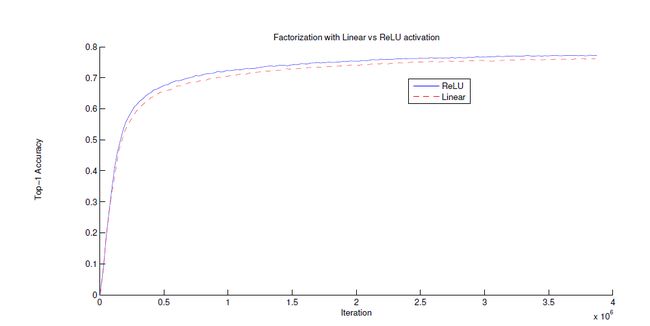
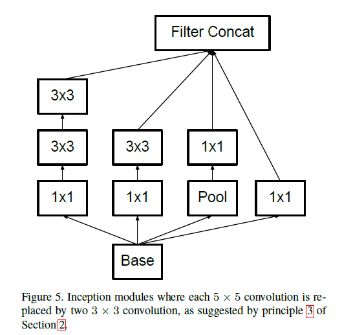
2、非对称卷积的空间分解
如果一个大的卷积核能分成一系列33卷积,能不能分成更小的22卷积?
用不对称卷积可以比2*2卷积做的好。
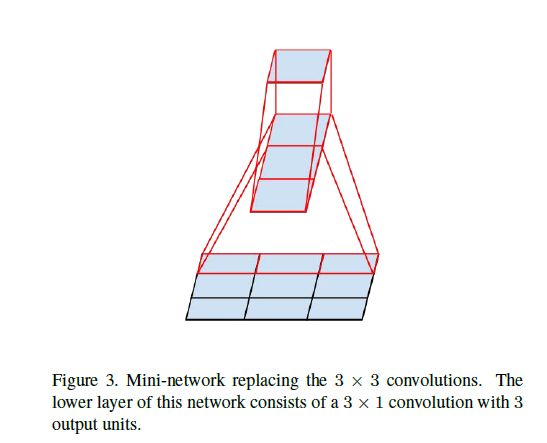
计算上,用31和13替代,32/9=66.7%,用2个22替代,42/9=88.9%
所以我们可以用n1和1n的卷积替代任何nn的卷积,计算变为原来的2/n
这个分解的方法在在中等网格尺寸(12x12–20x20)上有非常好的结果,但在低层中表现并不好。
第三部分 使用辅助分类器
在GoogLeNet的原始论文中提到了,在模型的中间层上使用了辅助的分类器,因为作者认为中间层的特征将有利于提高最终层的判别力,想通过在比较深的网络中解决消失梯度问题,将有效梯度传回较低层以使它们立即有效并在训练期间改善收敛。
但是在这篇文章中,作者发现辅助层在训练初期并没有起到很好的效果,而在训练快结束时才体现出较好的效果。这意味着最初的GoogLeNet的假设,即这些辅助分类器帮助区分低级特征,很可能是错误的。但是作者认为辅助分类器发现辅助分类器扮演着regularizer的角色,当辅助分类器使用了Batch Normalization或dropout时,主分类器效果会更好。这也为Batch Normalization作为正则化器的猜想提供了一个薄弱的支持证据。
第四部分 有效网格尺寸缩减
一般卷积网络都用池化操作来缩减特征图的尺寸,但是为了避免表达瓶颈(原则一的缩减太快),即更有效的保存图像信息,应在池化之前增加滤波器数目。
举个栗子:我们现在从一个有k个过滤器d x d的特征图开始,要达到一个有2k个过滤器(d/2)x(d/2)的特征图的方法有两种:
- 通过池化操作(得到d/2 x d/2 x k),再1*1卷积(得到d/2 x d/2 x 2k)。计算量为(d/2)2 x k x
2k=2(d/2)2k2 。 - 通过一个含有2k个过滤器,步长为1的卷积操作(应该是1*1卷积得到d x d x 2k),再进行池化操作(得到d/2 x d/2 x 2k)。那么总体计算量主要就是在大特征图上的计算量:d2 x k x 2k=
2 x d2 x k2
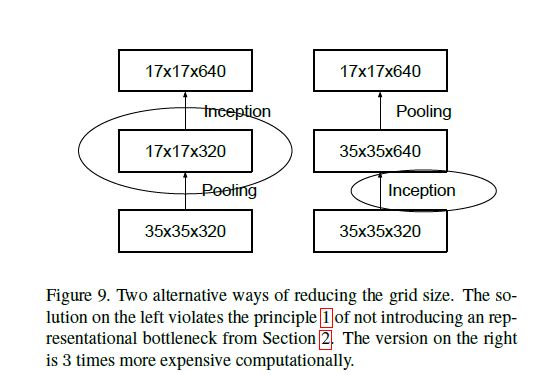
作者就想到了另外一种方法:

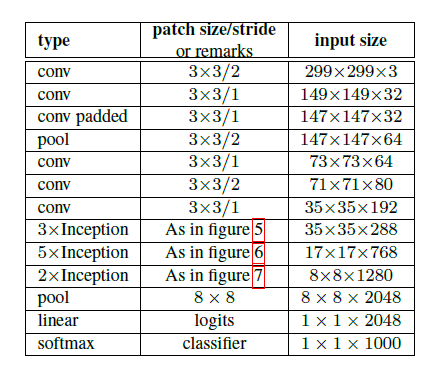
第五部分 Inception-v2
网络有42层,但是计算量只有GoogLeNet的2.5倍。
把传统卷积里的7x7分解成了3个3x3卷积。


第六部分 通过标签平滑进行模型正则化
通过估计训练期间标签dropout的边缘效应来规范分类器层。
对于每一个训练样本x,计算每一个标签 k ∈ { 1 , . . . , k } k\in \{1, ...,k \} k∈{1,...,k}的概率: p ( k ∣ x ) = e x p ( z k ) ∑ i = 1 K e x p ( z i ) p(k|x) = {exp(z_k)\over \sum_{i=1}^K exp(z_i)} p(k∣x)=∑i=1Kexp(zi)exp(zk), z i z_i zi是逻辑值或者非归一化对数概率。
样本x的实际标记分布为q(k|x),归一化后就有 ∑ K q ( k ∣ x ) \sum_K q(k|x) ∑Kq(k∣x)=1。
定义交叉熵损失函数为 l = − ∑ k = 1 K l o g ( p ( k ) ) q ( k ) l=-\sum_{k=1}^K log(p(k))q(k) l=−∑k=1Klog(p(k))q(k),最小化l就相当于最大化标签的似然概率,标签是根据真实分布q(k)选择的。对于一个标签y,q(y)=1且q(k)=0(k≠y)。
交叉熵函数对逻辑输出求导, 区间为[-1,1]: ∂ l ∂ z k = p ( k ) − q ( k ) {\partial l\over \partial z_k}= p(k)-q(k) ∂zk∂l=p(k)−q(k)
似然概率最大值对于一个有限的z_k来说是不可达到的,但是在真实值的逻辑值比其他的逻辑值明显大的情况下是可以逼近这个最大值的( z y z_y zy≫z_k k≠y)。
但是这可能会带来两个问题,因为模型对于结果预测太过自信:
过拟合。
损失函数对逻辑输出的导数(边界梯度 ∂ l ∂ z k \partial l\over \partial z_k ∂zk∂l变大,降低了模型的适应能力。
所以作者提出了一个使得模型预测不那么自信的机制,虽然这个机制在使训练样本的似然概率最大化的时候可能并不是我们想要的,但是它的确能够起到正则化的作用,并能提高泛化能力。
假设标签的分布是u(k)(与训练样本x相互独立),引入一个平滑参数 ϵ \epsilon ϵ。对于每一个真实标签为y的x,用 q ′ ( k ∣ x ) = ( 1 − ϵ ) δ k . y + ϵ u ( k ) q'(k|x)=(1-\epsilon)\delta_{k.y}+\epsilon u(k) q′(k∣x)=(1−ϵ)δk.y+ϵu(k)来替代它的真实概率 q ( k ∣ x ) = δ k , y q(k|x)=\delta_{k,y} q(k∣x)=δk,y。
对真实标签k=y,用平滑参数∈使k变成从标签的先验分布u(k)中取出来的一个值,在本文的实验中,取u(k)=1/K,所以 q ′ ( k ∣ x ) = ( 1 − ϵ ) δ k . y + ϵ K q'(k|x)=(1-\epsilon)\delta_{k.y}+{\epsilon \over K} q′(k∣x)=(1−ϵ)δk.y+Kϵ,我们把这种真实标签分布的变化叫做LSR(label-smoothing regularization)。
LSR能够防止最大的逻辑值比其他的逻辑值大很多。否则q(k) 就接近1,其他值接近0,不像 q ( k ) = δ ( x , y ) q(k)=\delta_(x,y) q(k)=δ(x,y) (1或0),所有的q’(k)都有一个大于零的低值,交叉熵损失函数就会很大。
考虑交叉熵损失函数:
H ( q ′ , p ) = − ∑ k = 1 K l o g p ( k ) q ′ ( k ) = ( 1 − ϵ ) H ( q , p ) + ϵ H ( u , p ) H(q',p) = - \sum_{k=1}^K logp(k)q'(k) = (1-\epsilon)H(q,p)+\epsilon H(u,p) H(q′,p)=−∑k=1Klogp(k)q′(k)=(1−ϵ)H(q,p)+ϵH(u,p)
LSR就相当于用一对损失函数 H(q,p) 和 H(u,p)替代单独的H(q,p)。其中H(u,p)惩罚了对于预测标签分布p对先验u的偏离,相对权重为 ϵ 1 − ϵ \epsilon \over {1-\epsilon} 1−ϵϵ
p对u的偏离程度可以用相对熵(又称KL散度)计算,这是描述两个概率分布P和Q差异的一种方法
(1)KL散度不是对称的,这意味着D(P||Q) ≠ D(Q||P)
(2)KL散度不满足三角不等式。
设P(x)和Q(x)是X取值的两个离散概率分布,则P对Q的相对熵为:
D ( P ∣ ∣ Q ) = ∑ ( P ( x ) l o g P ( x ) Q ( x ) ) D(P||Q) = \sum {(P(x) log {P(x)\over Q(x)})} D(P∣∣Q)=∑(P(x)logQ(x)P(x))
对于连续的随机变量,定义为:
D ( P ∣ ∣ Q ) = ∫ ( P ( x ) l o g P ( x ) Q ( x ) ) d ( x ) D(P||Q) = \int {(P(x) log {P(x)\over Q(x)}}) d(x) D(P∣∣Q)=∫(P(x)logQ(x)P(x))d(x)
相对熵是两个概率分布P和Q差别的非对称性的度量。
因为 H ( u , p ) = D K L ( u ∣ ∣ p ) + H ( u ) H(u,p) = D_{KL}(u||p)+H(u) H(u,p)=DKL(u∣∣p)+H(u),并且H(u)是固定的,当u是均匀分布时,H(u,p)就是p偏离均值的程度。在实验中,K=1000,取u(k)=1/1000, ϵ = 0.1 \epsilon = 0.1 ϵ=0.1。
第七部分 训练方法
- 随机梯度下降
- 在GPU上运行50个副本
- batch-size=32,epoch=100。
- SGD+momentum,momentum=0.9。
- RMSProp,decay=0.9,ϵ=0.1。
- Learning rate=0.045,每2个epoch,衰减0.94。
- 梯度最大阈值为2.0。
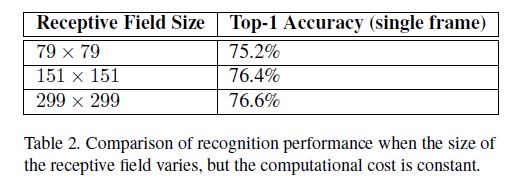
第八部分 低分辨率输入的性能
高分辨率输入的性能当然会好,但是在低层进行计算时,以及网络模型容量更大时,计算量也就特别更大。
那么在计算资源保持不变的情况下,高分辨率输入会有什么好处?
确保计算资源不变的方法是:在较低分辨率输入的情况下,减少前两层的步长,或者移除网络的第一个池化层。进行三组实验:
- 感知域为299*299,步长为2,第一层后连接最大池化层 ;
- 感知域为151*151,步长为1,第一层后连接最大池化层;
- 感知域为79*79,步长为1,仅有第一层;
第九部分 实验结果
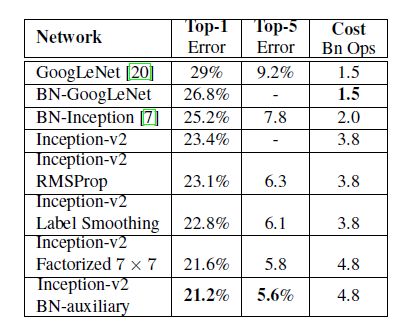
每个Inception-v2行都显示累积更改的结果,包括突出显示的新改进以及所有先前的改进。


第十部分 总结
----到结尾啦,开心吗?略略略~
- 提供了几个设计原则来扩展卷积网络,并在Inception架构中对其进行了研究。这些指导原则可以用于设计比单一架构更高性能、计算资源占用相对更少的视觉网络。
- 低分辨率输入也可以有高质量的输出。
- 将卷积核分解、大量减少维度能够减少占用的计算资源并保持高质量输出。
结合batch-normalization辅助分类器和标签平滑算法带来正则化效果,结合较少的参数,就能在相对较小的数据集上训练高质量的网络。
Inception –v3 表现超级好好好好好好好好好。
最后的最后,Inception v2和Inception v3是一个比较难的文章,所以分享的我们也有些不知所措,但也算是在前辈的基础上摸索过河,下周是我们的ResNet哦~我们下周见,嘻嘻嘻!