Inception-v2和Inception-v3来源论文《Rethinking the Inception Architecture for Computer Vision》读后总结
- deep
- learning
- 深度学习
- 神经网络
- 卷积神经网络
- Inception-v3
- Inception-v2
- Inception-v3
- deep
- learning
- 深度学习
- 神经网络
- 卷积神经网络
Inception-v2和Inception-v3来源论文《Rethinking the Inception Architecture for Computer Vision》读后总结
- 前言
- 文章主要内容
-
- 更详细的对卷积的分解进行了解释和说明,并且提出了向量化的卷积
- 使用了特殊的正则化
- 设计了升级版的Inception模型
- 分析了低分辨率输入的性能并表示即使是低分辨率的输入也能拥有不输于高分辨率的结果
- 辅助分类器
- 实验结果
前言
这是一些对于论文《Rethinking the Inception Architecture for Computer Vision》的简单的读后总结,文章下载地址奉上:Rethinking the Inception Architecture for Computer Vision
这篇文章是谷歌公司的研究人员所写的论文, 第一作者是Christian Szegedy,其余作者分别是Vincent Vanhoucke、Sergey Ioffe和Jonathon Shlens,其是2014年ImageNet竞赛冠军网络GoogLeNet的改进版。该文章主要是改进了Inception模块,降低了计算量的同时增加了模型的性能。
废话不多说,直接进入主题。
文章主要内容
在该文章主要内容是:
- 更详细的对卷积的分解进行了解释和说明,并且提出了向量化的卷积;
- 使用了特殊的正则化;
- 设计了升级版的Inception模型;
- 分析了低分辨率输入的性能并表示即使是低分辨率的输入也能拥有不输于高分辨率的结果;
- 辅助分类器。
更详细的对卷积的分解进行了解释和说明,并且提出了向量化的卷积
为了减少计算量,不仅从 7 × 7 7\times7 7×7或 5 × 5 5\times5 5×5的卷积降级成了多个 3 × 3 3\times3 3×3或 1 × 1 1\times1 1×1卷积,还针对 3 × 3 3\times3 3×3再进一步的进行分解,将其分解为向量化的 3 × 1 3\times1 3×1和 1 × 3 1\times3 1×3的卷积,在保证模型性能的前提下进一步降低了算法的参数数量。
例如
- 5 × 5 5\times5 5×5的卷积的参数数量是 3 × 3 3\times3 3×3的卷积的 25 / 9 = 2.78 25/9=2.78 25/9=2.78倍,通常使用两个 3 × 3 3\times3 3×3的卷积即可代替 5 × 5 5\times5 5×5的卷积,此时 5 × 5 5\times5 5×5的卷积的参数数量是两个 3 × 3 3\times3 3×3的卷积的 25 / ( 9 × 2 ) = 1.39 25/(9\times2)=1.39 25/(9×2)=1.39倍;
- 3 × 3 3\times3 3×3的卷积的参数数量是 3 × 1 3\times1 3×1或 1 × 3 1\times3 1×3的卷积的 9 / 3 = 3 9/3=3 9/3=3倍,通常使用一个 3 × 1 3\times1 3×1和一个 1 × 3 1\times3 1×3的卷积即可代替 3 × 3 3\times3 3×3的卷积,此时 3 × 3 3\times3 3×3的卷积的参数数量是一个 3 × 1 3\times1 3×1加一个 1 × 3 1\times3 1×3的卷积的 9 / ( 3 × 2 ) = 1.5 9/(3\times2)=1.5 9/(3×2)=1.5倍。
使用了特殊的正则化
通过光滑化标签来实现模型的正则化,该方法是基于交叉熵的,该文章提出了一种鼓励模型不那么自信的机制。如果目标是最大限度地提高训练标签的对数似然性,则可能不需要这样做,它对模型进行了正则化,使其具有更强的适应性。这个方法非常简单,考虑与训练样本x无关标签 u ( k ) {u}(k) u(k)上的分布和光滑化参数 ϵ \epsilon ϵ。对于一个样本的真实标签y,将标签分布 q ( k ∣ x ) = δ k , y q(k|x)=\delta_{k,y} q(k∣x)=δk,y替换为
q ′ ( k ∣ x ) = ( 1 − ϵ ) δ k , y + ϵ u ( k ) q'(k|x)=(1-\epsilon)\delta_{k,y}+\epsilon{u}(k) q′(k∣x)=(1−ϵ)δk,y+ϵu(k)
上式是原始真实分布 q ( k ∣ x ) q(k|x) q(k∣x)和固定分布 u ( k ) {u}(k) u(k)的一个组合,权重分别是 1 − ϵ 1-\epsilon 1−ϵ和 ϵ \epsilon ϵ。该实验中取 u ( k ) = 1 / K {u}(k)=1/K u(k)=1/K,即
q ′ ( k ∣ x ) = ( 1 − ϵ ) δ k , y + ϵ K q'(k|x)=(1-\epsilon)\delta_{k,y}+\dfrac\epsilon K q′(k∣x)=(1−ϵ)δk,y+Kϵ
该文章将这种真实标签分布的变化称作标签光滑正则化(label-smoothing regularization, LSR)。
通过考虑交叉熵,可以得到对LSR的另一种解释
H ( q ′ ∣ p ) = − ∑ k = 1 K log p ( k ) q ′ ( k ) = ( 1 − ϵ ) H ( q ∣ p ) + ϵ H ( u ∣ p ) H(q'|p)=-\sum\limits_{k=1}^K\log{p}(k)q'(k)=(1-\epsilon)H(q|p)+\epsilon H(u|p) H(q′∣p)=−k=1∑Klogp(k)q′(k)=(1−ϵ)H(q∣p)+ϵH(u∣p)
因此,LSR等价于用一对交叉熵损失 H ( q , p ) H(q,p) H(q,p)和 H ( u , p ) H(u,p) H(u,p)代替单个交叉熵损失 H ( q , p ) H(q,p) H(q,p)。第二损失惩罚预测的标签分布p与先前u的偏差,相对权重为 ϵ 1 − ϵ \dfrac {\epsilon}{1-\epsilon} 1−ϵϵ。注意,由于 H ( u , p ) = D K L ( u ∣ ∣ p ) + H ( U ) H(u,p)=D_{KL}(u||p)+H(U) H(u,p)=DKL(u∣∣p)+H(U)和 H ( u ) H(u) H(u)是固定的,这种偏差可以等价地被KL散度捕获。当u是均匀分布时, H ( u , p ) H(u,p) H(u,p)是衡量预测分布p与一致分布有多大不同的一种度量,它也可以用负熵 − H ( p ) -H(p) −H(p)来度量(但不是等价的);该文章作者还没有试验过这种方法。
在ImageNet实验中有 K = 1000 K=1000 K=1000个类,所以 u ( k ) = 1 / 1000 u(k)=1/1000 u(k)=1/1000和 ϵ = 0.1 \epsilon=0.1 ϵ=0.1。对ILSVRC 2012,可以同时绝对的提升top-1误差和top-5误差0.2%。
设计了升级版的Inception模型
首先是原始的Inception模型的结构图:
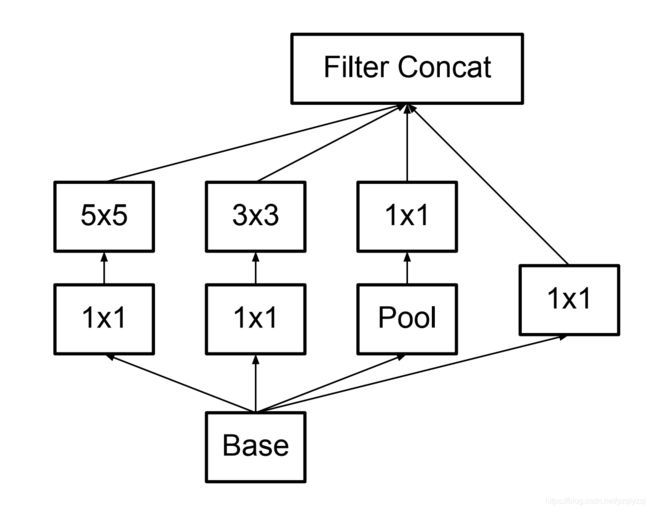
接下来是升级版的Inception模型的结构图,其将 5 × 5 5\times5 5×5的卷积替换为了两个 3 × 3 3\times3 3×3的卷积(对应后面网络结构表中的figure 5):

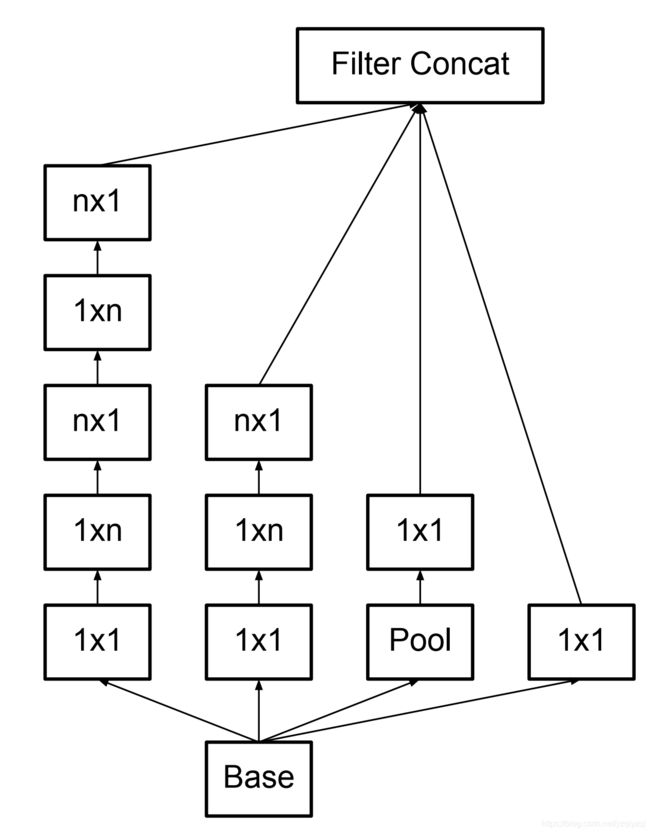
随后是总结出来的广义的Inception模型的结构图(对应后面网络结构表中的figure 6):
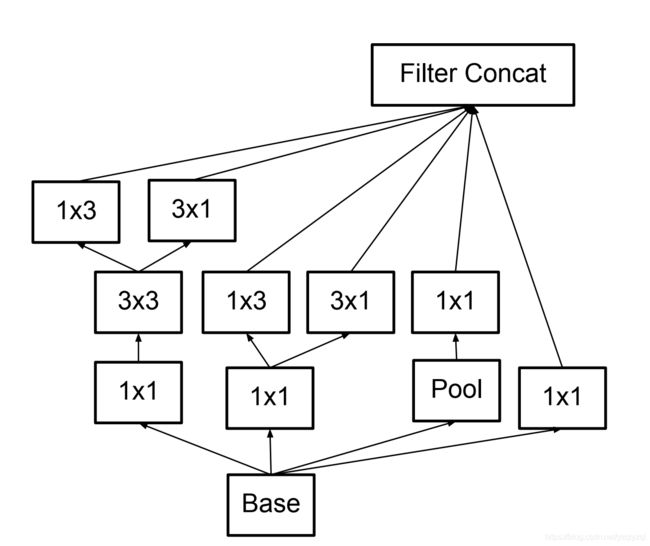
上述模型细化到该文章则变为(对应后面网络结构表中的figure 7):
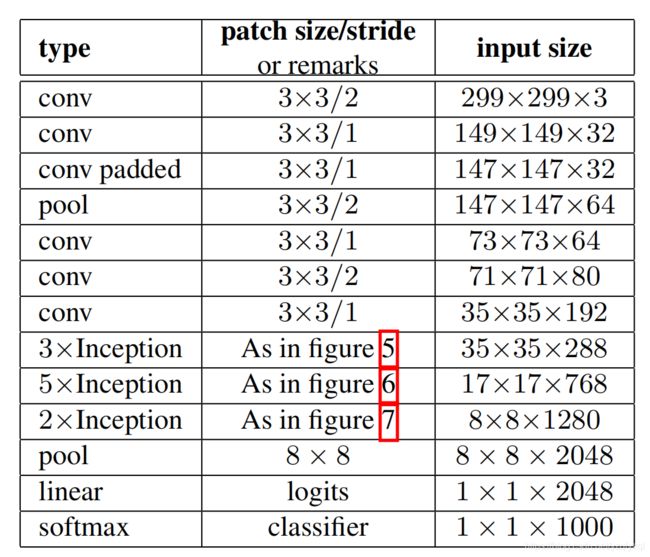
网络的结构变为:
分析了低分辨率输入的性能并表示即使是低分辨率的输入也能拥有不输于高分辨率的结果
对于不同分辨率的输入使用不同的初始层,例如
- 对于 299 × 299 299\times299 299×299的输入,第一层后使用最大池化,步长为2;
- 对于 151 × 151 151\times151 151×151的输入,第一层后使用最大池化,步长为1;
- 对于 151 × 151 151\times151 151×151的输入,第一层后不使用池化,步长为1。
它们的计算成本几乎一样,低分辨率输入的模型收敛稍慢,最终的性能差异很小:
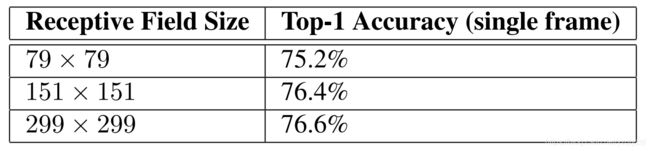
辅助分类器
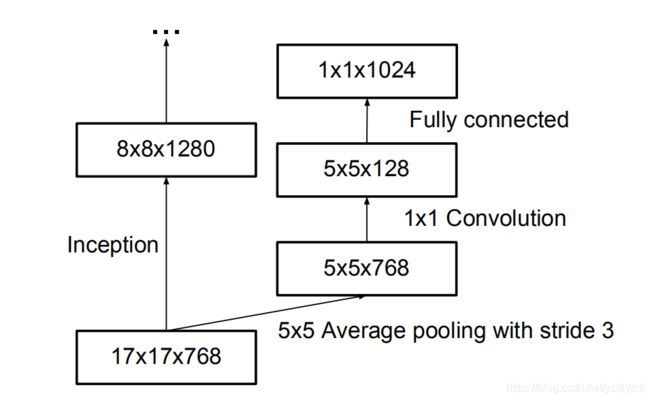
使用如下辅助分类器使得准确率提高了 0.4 % 0.4\% 0.4%:
实验结果
实验结果图如下:
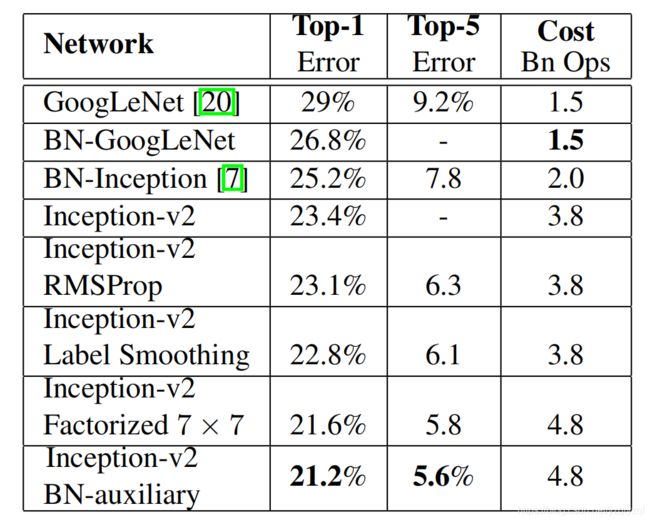
最后一行使用了本文提出的所有的策略,也被称为Inception-v3。
下图的top-5和top-1应该是写反了:

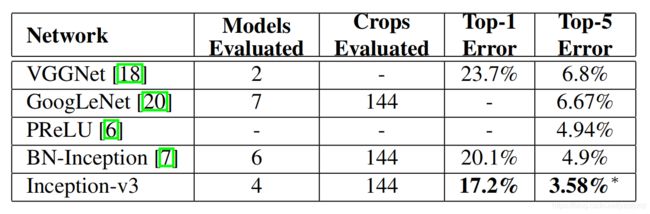
可以看见Inception-v3的提升相较于原始的GoogLeNet非常大,特别是Top-5错误率几乎降为GoogLeNet的一半。