机器学习概论整理与总结
问答题:
1、机器学习根据任务类型,可以划分为哪些?
根据处理的数据是否具有标签信息,我们可以将机器学习分为监督学习、无监督学习、半监督学习、强化学习等几种类型。
机器学习的种类及其主要任务_贾路飞的博客-CSDN博客_机器学习任务
2、机器学习根据算法类型,可以分为哪些?
分类
- KNN
- 向量机SVC
- 朴素贝叶斯
- 决策树DecisionTreeClassifier
- 随机森林RandomForestClassifier
- 逻辑回归--》softmax回归
回归
- 线性回归--》岭回归 lasso回归
- 向量机SVR
- 决策树DecisionTreeRegressor
- 随机森林回归RandomForestClassifier
机器学习算法分类 - 秋雨秋雨秋雨 - 博客园
常见机器学习分类_梦沁清风-CSDN博客_机器学习分类
3、什么是没有免费的午餐定理?
没有一种机器学习算法是适用于所有情况的,对于所有机器学习问题,任何一种算法(包括瞎猜)的期望效果都是一样的。
4、输入空间、输出空间、特征空间分别表示什么?
输入空间+输出空间
监督学习中,输入与输出所有可能的取值集合称为输入空间与输出空间。
通常输出空间远小于输入空间
特征空间
每一条样本被称作是一个实例,通常由特征向量表示,所有特征向量存在的空间称为特征空间。
特征空间有时候与输入空间相同,有时候不同(例如word embbeding),不同的情况是输入空间通过某种映射生成了特征空间。
补充:假设空间
假设空间一般是对于学习到的模型而言的。模型表达了输入到输出的一种映射集合,这个集合就是假设空间,假设空间表明着模型学习的范围。
机器学习中输入空间、特征空间、假设空间
5、监督学习为何称为‘监督’?
6、监督学习的目的是什么?
3、监督学习模型可以分为哪两类?
7、监督学习分为哪两个过程?
监督学习
1、机器学习的三要素是什么?
方法=模型+策略+算法
2、简单解释一下三要素?
模型就是我们要求的,可以由输入产生正确输出的函数或者概率模型。求出这个模型是我们最终的目标。因此我们第一步要确定模型的范围,也就是确定假设空间。
策略,就是考虑用什么准则来学习或选择最优模型
算法是指学习模型的具体的计算方法,也就是求模型中的具体的参数的方法。一般会用到最优化得算法,比如梯度下降等。
1、什么是损失函数?
2、什么是风险函数?
3、什么是经验风险?
4、什么是结构风险?
——损失函数,度量模型一次预测的好坏。是非负实值函数,值越小,模型越好。
——风险函数,度量模型平均预测的好坏。损失函数的期望就是风险函数或期望损失,是模型关于联合概率分布的平均损失,但是风险函数中的P(X,Y)联合分布是未知的,所以又提出经验风险。
——经验风险是模型关于训练数据集的平均损失,而期望风险是模型关于联合概率分布的平均损失,所以当训练数据集中的样本为无穷时,经验风险趋于期望风险。问题则转向经验风险最小化。
——经验风险最小化,当样本容量足够大时,效果显著。但是样本有限时就会出现偏差,出现“过拟合”现象。
——结构风险最小化,防止“过拟合”现象,由经验风险和模型复杂度构成,二者同时小时,就能有较好的预测。
总:监督学习的问题就变成了经验风险和结构风险最优化的问题,经验风险函数和结构风险函数就是目标函数。
注:梯度下降(gd)是最小化风险函数、损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路。
机器学习三要素及重要概念 - 知乎
数据处理之归一化、标准化、正则化
【机器学习】特征工程:特征组合
从神经元谈到深度神经网络
一文讲透神经网络的激活函数
优化算法要点
机器学习之基本定义
1、什么是机器学习?
机器学习是对大量数据进行分析,寻找统计规律,建模,并使用模型对新数据进行预测和分析的学科。
2、为什么要用机器学习?
- 对于现有解决方案需要大量人工手动执行或者判断规则非常多的时候,使用机器学习可以简化
- 对于传统技术无法解决的问题,比如语音识别,图像识别等
- 对于大数据时代产生的大量数据以及产生的复杂的问题
- 问题的结果受环境波动的影响
3、机器学习的对象、方法、目的、学科相关
- 机器学习的对象是数据,从数据中学习规律,并用于数据。数据是多样的,包括文本、图像、音视频等。机器学习的前提假设是数据具有一定的统计规律。
- 机器学习的方法是基于数据构建模型。
- 机器学习的目的是对于新数据用构建模型进行分析和预测。
- 机器学习是一门概率论、信息学、统计学、计算理论、最优化理论、计算机科学等多个领域的交叉科学,并在逐渐形成自己的方法论和理论体系。
4、实现机器学习的步骤
- 得到一个有限的训练数据集合
- 确定包含所有可能模型的假设空间,即学习模型的集合(自己判断)。
- 确定模型选择的准则
- 实现求解最优模型的算法
- 通过学习方法选择最优模型
- 利用学习到的模型对新数据进行预测和分析
5、机器学习方法的三要素
1、模型
模型就是所要学习的条件概率分布或决策函数。模型的假设空间包含所有可能的条件概率分布或决策函数。
条件分布函数:
![]()
决策函数:
![]()
2、策略
模型的假设空间中包含所有可能的条件概率分布或决策函数,那么我们如何选择最优的那个呢?这就是策略的作用。
- 损失函数与风险函数
损失函数是度量模型一次预测的好坏,即预测值与实际值之间的差别,而风险函数则是度量模型平均意义下预测的好坏。
损失函数f(X)与Y的非负实值函数,记作L(Y, f(X))。
- 0-1损失函数
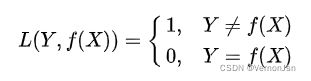
- 平方损失函数
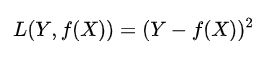
- 绝对损失函数

- 对数损失或对数似然损失函数
![]()
损失函数越小,则模型越优秀。模型的输入输出均为随机变量,且服从联合分布P(X,Y),所以损失函数的期望为

该期望为理论上模型f(X)在联合分布P(X,Y)下的平均意义下的损失,称为风险函数或期望损失。我们选择模型希望风险函数越小越好。虽然我们假设数据服从联合分布,但我们不知晓联合分布函数,所以我们就要找一个近似值,即经验风险。
给定一个训练数据集,
![]()
模型f(X)关于数据集的平均损失成为经验风险或经验损失,
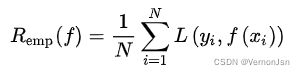
根据大数定律可知,当样本容量N趋于无穷大时,经验风险与期望风险的差距很小是必然的,所以可以使用经验风险估计期望风险。
如果样本容量不是足够大时,使用经验风险估计期望风险的效果不是很理想,此时就需要结构风险最小化。
结构风险最小化原则是因为样本容量小而导致过拟合现象,过拟合即是对训练样本预测效果好,但对未知样本预测效果差。
结构风险最小化等价于正则化,即在风险损失函数加上模型的复杂度的正则化项,定义为:

这是基于对过拟合现象的一个处置方法,即简化,其中包括选择较少参数的模型。此时,如果模型越复杂,则复杂度也就越大;相反也是如此。λ>=0是用来权衡经验风险和模型复杂度。
3、算法
从上面我们可以看出机器学习最后的问题都是求解经验风险或结构风险函数的最小值,也就是最优化问题,算法就是用于此处。
求解最优化方法有梯度、牛顿、拉格朗日乘法等。
参考:机器学习之基本定义