BERT |(3)BERT模型的使用--pytorch的代码解释
参考代码:https://github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
从名字可以看出来这个是做一个中文文本分类的的任务,具体就是做新闻文本分类的任务,具体有以下几个类,属于多分类的问题

目录
一、如何让你下载的代码跑起来
二、bert模型的使用
模型代码学习-CLS文本分类-Bert-Chinese-Text-Classification-Pytorch代码学习-训练并测试过程
模型代码学习-CLS文本分类-Bert-Chinese-Text-Classification-Pytorch代码学习-构建数据,数据Iter类
三、数据集的处理
./utils.py学习
全局
def build_dataset(config):
def load_dataset(path, pad_size=32):
class DatasetIterater(object):
def __init__(self, batches, batch_size, device):
def _to_tensor(self, datas):
def __next__(self):
def __iter__(self):
def __len__(self):
def build_iterator(dataset, config):
def get_time_dif(start_time):
四、训练评估
./train_eval.py学习
全局
def init_network(model, method='xavier', exclude='embedding', seed=123):
def train(config, model, train_iter, dev_iter, test_iter):
def evaluate(config, model, data_iter, test=False):
def test(config, model, test_iter):
五、run.py
总结
一、如何让你下载的代码跑起来
首先,讲一下如何将这个代码跑起来,不要问我为什么要写这一步,因为有人没跑起来,对,就是我!

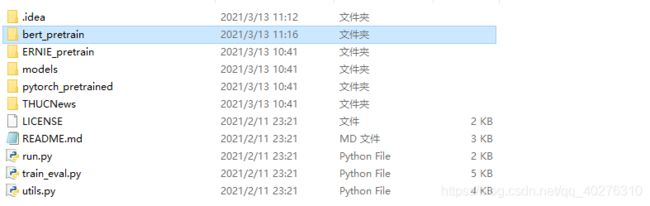
在“bert_pretrain”文件夹里面下载这几个文件夹

什么?你不知道在哪儿下载?https://huggingface.co/hfl,这个网址有所有的bert预训练模型。gogogo!
OK,啥?你不知道,怎么在pycharm中运行带参数的?

shift+Alt+F10,点击“编辑结构”,打开如下界面:
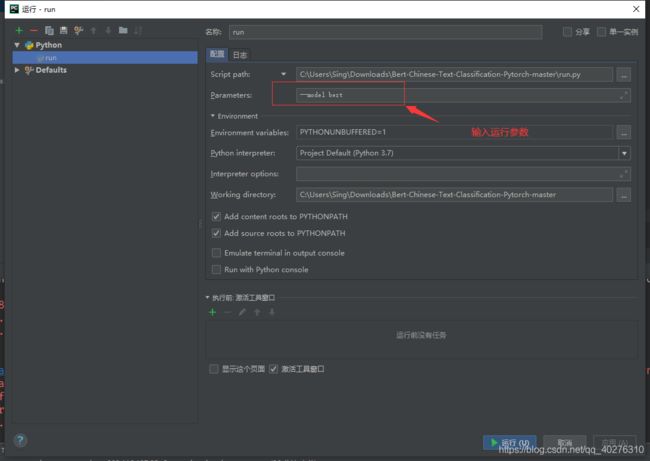
OK,点击运行,是不是代码就可以跑起来了?
以下是改代码跑的结果,用的学校的服务器Quadro RTX 8000 ,跑了3个epoch,花了26分52秒,结果如下:

和作者提供的94.83%还是差一点点的,不过我只跑了一次,多跑几次,估计也会跑出这个结果吧,毕竟作者也只是写代码练手,没必要谎报结果。其他的几个模型也懒得跑了,具体是要看看怎么用bert。
二、bert模型的使用
我当然第一步就是,打开model的文件夹,来瞄一瞄bert是怎么敲出来了,会不会有几十万行代码,结果打开一看:
# coding: UTF-8
import torch
import torch.nn as nn
# from pytorch_pretrained_bert import BertModel, BertTokenizer
from pytorch_pretrained import BertModel, BertTokenizer
class Config(object):
"""配置参数"""
def __init__(self, dataset):
self.model_name = 'bert'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt').readlines()] # 类别名单
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.num_epochs = 3 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-5 # 学习率
self.bert_path = './bert_pretrain'
self.tokenizer = BertTokenizer.from_pretrained(self.bert_path)
self.hidden_size = 768
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.bert = BertModel.from_pretrained(config.bert_path)
for param in self.bert.parameters():
param.requires_grad = True
self.fc = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
context = x[0] # 输入的句子
mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
_, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False)
out = self.fc(pooled)
return out
这短短的几十行代码,告诉我,我又可以开心的调包了,难怪之前师兄说,bert感觉没啥厉害的,模型你又不能动,参数又不能随便改。果然就是这样,貌似能动的就是有配置参数下面的几个东东了。
对了,这里
# from pytorch_pretrained_bert import BertModel, BertTokenizer from pytorch_pretrained import BertModel, BertTokenizer
这两行,大家可能只能百度到被注释哪一行的包,那个就是提供bert预训练模型的包,一般使用也都只是调用这两个包,一般使用以下两行代码,来调用bert去做预训练(也就是去处理你下载好的预训练模型)
# 加载bert的分词器
tokenizer = BertTokenizer.from_pretrained('你存放的路径/bert-base-uncased-vocab.txt')
# 加载bert模型,这个路径文件夹下有bert_config.json配置文件和model.bin模型权重文件
bert = BertModel.from_pretrained('你存放的路径/bert-base-uncased/')关于bert模型的参数配置都在你下好的预训练文件中的json文件里面,这个一般是不能修改的。
什么?你想知道怎么根据论文讲的去一步步建立bert模型?你去吧!我觉得调包会用就已经是我的能力极限了!

到此,你就会使用bert做预训练的任务了,剩下的工作就是做97行的数据处理,121行的实验评估和37行的参数设置了,说白,接下来就是,把买来的菜洗好切好,炒好,做成一个bert这个宝宝能吃的下的,然后设定喂多少,怎么喂,最后收到宝宝的反馈,是好吃还是不好吃,好吃的层度是多少,另一个宝宝喂给他吃,他又觉得怎么样。
但是,你还是想知道这个代码的这些过程是怎么样做的?好吧,满足你的愿望,不过我也没太仔细看,但是这里有两个人写得还算具体,不过老实说,我没看懂想说啥,说不定你们能看懂。

模型代码学习-CLS文本分类-Bert-Chinese-Text-Classification-Pytorch代码学习-训练并测试过程
模型代码学习-CLS文本分类-Bert-Chinese-Text-Classification-Pytorch代码学习-构建数据,数据Iter类
三、数据集的处理
这个部分主要是在utils.py这个文件里面:
既然是数据处理,我们首先看看,他给我们的是一个什么样的数据
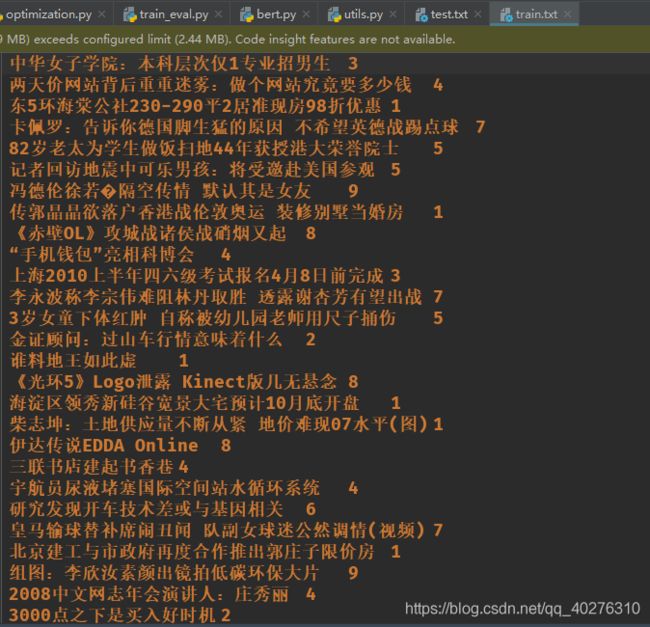
可以看到,前面是句子后面是标签分类,害,貌似前面还写错了,不是新闻文本分类,应该叫新闻标题分类……
至于每行代码是什么意思,我就不要脸的直接复制别人的博客了!就是刚刚说的上面那两篇。不对,我这是防止原作者删博客,以后找不到,我这是备份的思想!

./utils.py学习
utils.py中主要是对于数据集的预处理,最终目标是构造能用于训练的batch和iter
全局
- Tqdm 是一个快速,可扩展的Python进度条,可以在 Python 长循环中添加一个进度提示信息,用户只需要封装任意的迭代器 tqdm(iterator),使用方法可见:https://blog.csdn.net/zkp_987/article/details/81748098
import torch from tqdm import tqdm import time from datetime import timedelta PAD, CLS = '[PAD]', '[CLS]' # padding符号, bert中综合信息符号def build_dataset(config):
def load_dataset(path, pad_size=32):
- 读取作者提供的txt文件为f迭代器,for line in tqdm f可能可以指定一个进度条,通过strip方法去掉每行的空格,之后如果该行不存在了,则continue继续处理下一行
- 由于数据集中两个内容中间以\t分割,于是通过split方法拆分出content和label
- config.tokenizer.tokenize(content),其中config来自上层build_dataset方法的入参,run.py作为最终的运行文件进行调用train_data, dev_data, test_data = build_dataset(config),其中config再进一步来源于x = import_module('models.' + model_name) config = x.Config(dataset),来自于model bert.py中的class Config,最终config类中包括了self.tokenizer = BertTokenizer.from_pretrained(self.bert_path),于是综合来说config.tokenizer.tokenize(content)可以理解为了BertTokenizer.from_pretrained(self.bert_path).tokenize(content)
- token最开始前边手动拼接[CLS],根据一些讨论个人理解[CLS]首先是bert用作分类任务必须需要的一个字符,参考该篇博客中的说法https://blog.csdn.net/qq_42189083/article/details/102641087,[CLS]就是classification的意思,可以理解为用于下游分类的任务,主要用于以下两种任务:1)单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将与该符号对应的输出向量作为整篇文本的语义表示,用于文本分类。可以理解为:与本文中已有的其他字词相比,这个无明显语义信息的符号会更“公平”的融合文本中各个字/词的语义信息。2)语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分。
- token_ids的作用需要打印后查看,猜测应该是一个与vocab.txt中进行角标对应的过程,不过为什么要进行这个对应->为了输入过程中的进一步输入进入bert进行位置embedding等
- pad_size指定了希望的最长文本长度,并对不足的文本进行pad补充,于是在该分支内进行判断,如果token的长度小于pad_size超参,首先对mask进行拼接,拼接为前边token_ids长度个数的1和最后补齐pad_size的0,由于token_ids的后半部分没有补东西,现在也把token_ids的最后补上0,这里为什么把token_ids的最后补上0,是否和词表中的对应关系有关?->vocat.txt中角标是0的位置对应的是[PAD]->个人感觉一般来说vocab.txt中的第0位应该都是[PAD]
- 如果token的长度已经等于或超过了pad_size超参了,则mask中不设置任何忽略,为pad_size长度的1,同时把token_ids进行截取,并重置seq_len
- 把每一条数据放入contents中,每一条为(token_ids, int(label), seq_len, mask),依次是:vocab.txt中的角标、类别int类型,文本长度,一个待使用的mask
def load_dataset(path, pad_size=32):
contents = []
with open(path, 'r', encoding='UTF-8') as f:
for line in tqdm(f):
lin = line.strip()
if not lin:
continue
content, label = lin.split('\t')
token = config.tokenizer.tokenize(content)
token = [CLS] + token
seq_len = len(token)
mask = []
token_ids = config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token) < pad_size:
mask = [1] * len(token_ids) + [0] * (pad_size - len(token))
token_ids += ([0] * (pad_size - len(token)))
else:
mask = [1] * pad_size
token_ids = token_ids[:pad_size]
seq_len = pad_size
contents.append((token_ids, int(label), seq_len, mask))
return contents- 这里执行完token = config.tokenizer.tokenize(content)后,打印输出当前的token,也希望把token_ids打印输出->但这里其实根据后文datas的打印结果就可以进行如下的猜测了
datas中的token_ids字段,之前的tokenizer.tokenize应该就是把中文文本split一下,如果用英文数据这里应该还需要变通一下
[101, 1367, 2349, 7566, 2193, 782, 7028, 4509, 2703, 680, 5401, 1744, 2190, 6413, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],- 对于mask拼接的实验尝试如下,希望验证[1] * 100这样在python中的输出打印效果->如下
>>> print([1]*10)
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]在def build_dataset()这一上层函数中对编写的load_dataset进行数据调用,经过学长提醒这里可能存在不能区分训练测试过程,导致训练测试过程都需要进行数据加载,虽然数据大小应该不大,但是批量加载也是一个过程。
train = load_dataset(config.train_path, config.pad_size)
dev = load_dataset(config.dev_path, config.pad_size)
test = load_dataset(config.test_path, config.pad_size)
return train, dev, testclass DatasetIterater(object):
从名称上猜测DatasetIterater类应该是把数据的dataset变为可迭代形式的,或者说batch形式的
def __init__(self, batches, batch_size, device):
- 在后续的def build_iterator(dataset, config):函数中对该类进行了实例化,iter = DatasetIterater(dataset, config.batch_size, config.device),可以看到传入的参数是经过def build_dataset()后的dataset(多条(token_ids, int(label), seq_len, mask)的集合),期望的batch_size,还有config的device。
- 在该初始化中定义了batch_size,数据集的batches(dataset传入),n_batches代表batch的数目,如果不能正好n_batches等分,则置self.residue为true,self.index和device的用处需要后文
- 看了后文,index应该是来标记走到了第几个iter的
def __init__(self, batches, batch_size, device):
self.batch_size = batch_size
self.batches = batches
self.n_batches = len(batches) // batch_size
self.residue = False # 记录batch数量是否为整数
if len(batches) % self.n_batches != 0:
self.residue = True
self.index = 0
self.device = devicedef _to_tensor(self, datas):
- 前边这个短下划线有没有什么特殊的考虑,在一些材料中看到如果加个短下划线不会被import到->一种较为习惯性的写法,在实际上只要保证不冲突即可
- datas中应该是一条条的(token_ids, int(label), seq_len, mask)(有待print验证),torch.LongTensor() Long类型的张量,对于BERT经过这样的转化就可以进行输入到模型中吗,因为如果理解没错的话此时的token_ids只是一个列表向量,代表了对应词汇的index标签,而且从表达形式来看,x就是数据,y就是标签
- 在return的时候把x seqlen mask组合了一下,不知道有什么考虑
def _to_tensor(self, datas):
x = torch.LongTensor([_[0] for _ in datas]).to(self.device)
y = torch.LongTensor([_[1] for _ in datas]).to(self.device)
# pad前的长度(超过pad_size的设为pad_size)
seq_len = torch.LongTensor([_[2] for _ in datas]).to(self.device)
mask = torch.LongTensor([_[3] for _ in datas]).to(self.device)
return (x, seq_len, mask), y对这里的datas进行打印,一个datas包含了一个batch的数据,这里展示一个batch中的一条数据,可以看到总长度为32,也就是超参中指定的长度
_to_tensor datas [
(
[101, 1367, 2349, 7566, 2193, 782, 7028, 4509, 2703, 680, 5401, 1744, 2190, 6413, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
6,
14,
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
),
(
[101, 4125, 3215, 1520, 840, 2357, 7371, 1778, 1079, 1355, 4385, 3959, 3788, 3295, 2100, 1762, 6395, 2945, 113, 1745, 114, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
4,
21,
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
),
…
]希望对这里的LongTensor进行打印查看(显示数据的打印查看,也打印查看维度),如下所示
x.shape torch.Size([128, 32]) y.shape torch.Size([128]) seq_len torch.Size([128]) mask torch.Size([128, 32])x tensor([[ 101, 837, 5855, ..., 0, 0, 0],
[ 101, 2343, 3173, ..., 0, 0, 0],
[ 101, 2512, 6228, ..., 0, 0, 0],
...,
[ 101, 6122, 4495, ..., 0, 0, 0],
[ 101, 1849, 1164, ..., 0, 0, 0],
[ 101, 860, 7741, ..., 0, 0, 0]], device='cuda:0')
y tensor([2, 9, 3, 6, 1, 9, 6, 7, 6, 8, 1, 6, 3, 3, 7, 7, 2, 0, 9, 2, 2, 2, 2, 0,
9, 4, 0, 3, 1, 1, 5, 0, 7, 6, 0, 6, 4, 5, 0, 5, 1, 4, 3, 3, 1, 2, 7, 9,
4, 4, 2, 2, 0, 6, 3, 1, 7, 8, 4, 4, 7, 7, 4, 6, 6, 9, 0, 7, 4, 8, 1, 9,
6, 4, 7, 6, 8, 0, 5, 2, 6, 9, 7, 1, 3, 1, 4, 9, 9, 9, 9, 3, 8, 7, 1, 9,
1, 9, 0, 4, 2, 0, 0, 4, 4, 7, 0, 4, 7, 4, 7, 7, 7, 7, 6, 6, 8, 7, 1, 3,
1, 3, 7, 6, 5, 0, 6, 3], device='cuda:0')
seq_len tensor([16, 20, 20, 21, 19, 20, 16, 23, 21, 17, 21, 16, 18, 19, 25, 22, 16, 13,
18, 15, 22, 21, 20, 11, 23, 17, 15, 17, 23, 21, 20, 9, 23, 17, 17, 20,
14, 19, 20, 15, 21, 19, 20, 20, 22, 14, 27, 22, 20, 19, 21, 14, 16, 19,
13, 21, 23, 17, 17, 12, 23, 25, 19, 16, 22, 21, 12, 24, 19, 16, 21, 23,
21, 15, 23, 17, 19, 21, 20, 16, 18, 19, 24, 16, 19, 19, 14, 22, 17, 20,
18, 18, 16, 23, 21, 22, 22, 22, 20, 15, 16, 18, 18, 20, 22, 22, 16, 15,
23, 18, 24, 24, 23, 25, 15, 16, 17, 24, 22, 16, 21, 21, 22, 19, 21, 22,
21, 18], device='cuda:0')
mask tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], device='cuda:0')def __next__(self):
- 怎么理解next前后的双横线,看起来next是为了走到下一个iter,或许在调用的时候会根据iter自动往后边一个走?->__next__ __iter__ __len__ 都是为了构造一个可迭代的对象,即一个数据的iter class,在写法上一般可以模仿类似的数据预处理过程
- 如果self.residue(不是正好能分成n个batch),并且现在的index已经达到了n个batch,也就是说剩下那一小部分没法归为一个正好的batch了,拆分出一个batches为self.batches[self.index * self.batch_size: len(self.batches)],也就是从最后上一个batch到结尾的,作为一个新的batch,并使得self.index += 1。并把这个batches进行_to_tensor()操作
- elif情况(即在不满足如果self.residue(不是正好能分成n个batch),并且现在的index已经达到了n个batch的情况下),如果现在的index超过并且等于(这个是应对正好的情况)了,重置self.index=0为下一个Epoch进行准备,并且raise StopIteration
- 其他情况(可以理解为不遇到终止等特殊情况,正常往后迭代的情况):切分batches:batches = self.batches[self.index *self.batch_size: (self.index + 1) * self.batch_size]
def __next__(self):
if self.residue and self.index == self.n_batches:
batches = self.batches[self.index * self.batch_size: len(self.batches)]
self.index += 1
batches = self._to_tensor(batches)
return batches
elif self.index >= self.n_batches:
self.index = 0
raise StopIteration
else:
batches = self.batches[self.index * self.batch_size: (self.index + 1) * self.batch_size]
self.index += 1
batches = self._to_tensor(batches)
return batchesdef __iter__(self):
- 这个怎么理解,是可以作为一个迭代器?->__next__ __iter__ __len__ 共同构成一个可迭代的类
def __len__(self):
- 返回batch的长度,也就是说有多少个batch
def build_iterator(dataset, config):
- 把dataset转化为一个DatasetIterater类的iter
- 这个iter是否是一个可迭代的->是
def build_iterator(dataset, config):
iter = DatasetIterater(dataset, config.batch_size, config.device)
return iterdef get_time_dif(start_time):
def get_time_dif(start_time):
"""获取已使用时间"""
end_time = time.time()
time_dif = end_time - start_time
return timedelta(seconds=int(round(time_dif)))四、训练评估
./train_eval.py学习
全局
- 在import来看,从sklearn里import了metrics,或许是测试过程中使用?->在测试过程中进行了使用,看起来加入normalize=False后是统计有几个对的,不加入后就是相较于整体个数的百分比
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0,0,0,2,1,3,4,5]
>>> y_true = [0,0,0,6,6,6,6,6]
>>> accuracy_score(y_true, y_pred)
0.375
>>> accuracy_score(y_true, y_pred, normalize=False)
3- import了pytorch_pretrained_bert.optimization中的BertAdam,BERT版本具有权值衰减固定、预热和学习速率线性衰减的Adam Optimizer。
# coding: UTF-8
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from pytorch_pretrained_bert.optimization import BertAdamdef init_network(model, method='xavier', exclude='embedding', seed=123):
- 这个函数在哪里被调用了,怎么感觉没有找到->似乎没有,暂时忽略了
-
从入参来看,seed=123该怎么理解,似乎没有用到?->所有seed字段的目标似乎都是为了结果的“可复现”,根据讨论后,在同一台机器上如果使用完全相同的seed,这样可能会在各类参数随机初始化的过程中成为一定的“随机定值”,使得结果可复现。但是讨论后认为在一些实验中如果不同机器使用了相同的seed,可能也没有效果。
# 权重初始化,默认xavier
def init_network(model, method='xavier', exclude='embedding', seed=123):
for name, w in model.named_parameters():
if exclude not in name:
if len(w.size()) < 2:
continue
if 'weight' in name:
if method == 'xavier':
nn.init.xavier_normal_(w)
elif method == 'kaiming':
nn.init.kaiming_normal_(w)
else:
nn.init.normal_(w)
elif 'bias' in name:
nn.init.constant_(w, 0)
else:
passdef train(config, model, train_iter, dev_iter, test_iter):
- 入参是config,模型model,还有train,valid,test三个数据集的iter
- 当前时间作为开始时间
- model.train怎么理解,追溯传参来源run.py model = x.Model(config).to(config.device) ,model_name = args.model # bert x = import_module('models.' + model_name) config = x.Config(dataset),所以这里的model.train是否是来自pretrain bert的.train()方法?->目前来看model.train()是把model切换到train的状态,与model.eval()把模型切换到evaluate状态相对应,由于dropout等问题,模型在训练和测试过程中可能需要具有不同的状态(例如在验证、测试过程中不希望不同次的验证、测试有不同的结果,所以需要关闭dropout)
- 所有config内容来自于./models/bert.py中,如果要对超参进行调整,在bert.py进行调整即可
- 以下关于optimizer的设置怎么理解->这里的warmup可以理解为让学习率先增大,后减小,或许这样可以尽快锁定一个区间,从而在这个区间来细化优化,另注,在讨论后认为在fine-tune过程中学习率不宜过大,要稍微小写
- param_optimizer = list(model.named_parameters())
- no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
- optimizer_grouped_parameters = [{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
- optimizer = BertAdam(optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
- total_batch参数记录进行到了多少的batch
- 初始化在验证集上的loss为inf:dev_best_loss = float('inf')
- last_import 初始化为0,记录上次在验证集上loss下降的batch数(训练是一个batch一个batch的,当所有数据组合完成训练后,会是一个Epoch)
- flag = False 记录是否很久没有效果提升,可能会被用作break用
- 又调用了一次model.train(),这里怎么理解,bert的.train()是什么效果->切换为train状态,和.eval()对应出现
- ※开始config.num_epochs个epoch的循环,这里循环的时候直接for ... in ..train_iter,所以是否就像之前认为的train_iter是一个可迭代对象?trains是(x, seq_len, mask)的tuple组合,这就被看做是输入模型的x,在模型的那篇博客中,forward函数如下context = x[0] # 输入的句子 mask = x[2] # 对padding部分进行mask,和句子一个size,padding部分用0表示,如:[1, 1, 1, 1, 0, 0]
- _, pooled = self.bert(context, attention_mask=mask, output_all_encoded_layers=False) out = self.fc(pooled) 所以这里是一个拆分
- model.zero_grad() 虽然是标准写法,不过该怎么理解一下->pytorch中的梯度是累积的,但是以batch来看每个batch都需要清空一下。
- loss = F.cross_entropy(outputs, labels),loss.backward(),交叉熵损失函数,这里的loss.backward()是否就理解为自动梯度反向传播,然后由于模型中的全程允许梯度传递,所以不存在frozen的情况?为什么能把output和labels直接比交叉熵损失函数?->打印输出output和labels进行查看,从打印结果来看似乎想起,对于softmax和交叉熵一类的损失函数,需要的是第几个labels是正确的!
outputs tensor([[ 0.3079, 0.1015, -0.5626, ..., -0.0208, 0.2517, 0.1984],
[-0.1730, 0.1862, -0.6964, ..., -0.2710, 0.4122, 0.3804],
[-0.2523, 0.0576, -0.1686, ..., -0.2864, 0.3397, 0.0802],
...,
[ 0.1749, -0.2050, -0.2825, ..., -0.5576, -0.0727, 0.1467],
[ 0.1107, -0.3328, -0.5910, ..., -0.5746, -0.1585, 0.1143],
[ 0.3721, -0.0540, -0.5997, ..., -0.2982, 0.0122, 0.4152]],
device='cuda:0', grad_fn=)
outputs size torch.Size([128, 10])
labels tensor([7, 5, 8, 1, 9, 9, 0, 6, 7, 2, 9, 9, 2, 3, 9, 3, 7, 0, 5, 6, 1, 7, 6, 5,
1, 4, 0, 4, 0, 8, 9, 0, 9, 9, 0, 4, 4, 7, 1, 8, 3, 6, 9, 3, 1, 6, 7, 7,
5, 3, 6, 0, 7, 9, 2, 8, 5, 6, 7, 6, 6, 6, 7, 0, 0, 7, 2, 3, 6, 6, 3, 5,
5, 9, 4, 1, 0, 8, 5, 4, 7, 4, 2, 3, 1, 4, 3, 3, 7, 8, 3, 3, 1, 9, 5, 5,
1, 4, 5, 2, 7, 3, 3, 0, 6, 5, 8, 8, 4, 1, 8, 3, 0, 2, 8, 5, 6, 4, 0, 6,
4, 0, 3, 6, 3, 3, 3, 7], device='cuda:0')
labels len 128 - 分析F.cross_entropy(outputs, labels)代码:https://blog.csdn.net/CuriousLiu/article/details/109995539 见此篇博客中
- optimizer.step() 怎么理解:所有的optimizer都实现了step()方法,这个方法会更新所有的参数。一旦梯度被如backward()之类的函数计算好后,我们就可以调用这个函数,是否理解为在这里进行了optimizer的处理->默认一种写法,个人感觉可以理解为对optimizer进行更新
- 每100轮输出一下在训练集和验证集上的效果(提到训练集和验证集,过拟合问题)
- true = labels.data.cpu()、predic = torch.max(outputs.data, 1)[1].cpu() 这两句话需要打印查看,看起来是调用labels所处类的中的一个data参数,但是为什么要放在cpu上,另外使用torch.max怎么理解,这里需要print labels和.data等进行查看->如下图所示,主要是取label后,查看是否对应使用的
true tensor([3, 4, 1, 7, 5, 5, 9, 1, 8, 4, 3, 7, 5, 2, 1, 8, 1, 1, 8, 4, 4, 6, 7, 1,
9, 4, 2, 9, 4, 2, 2, 9, 8, 9, 1, 3, 9, 5, 9, 6, 7, 2, 9, 5, 9, 4, 5, 6,
8, 1, 2, 1, 4, 0, 5, 4, 9, 6, 5, 5, 2, 4, 5, 5, 7, 8, 6, 7, 7, 2, 9, 0,
4, 6, 7, 2, 9, 7, 9, 0, 2, 9, 9, 4, 9, 0, 0, 4, 1, 2, 5, 5, 7, 0, 5, 9,
5, 3, 4, 6, 8, 3, 5, 9, 3, 9, 4, 9, 5, 4, 6, 2, 3, 6, 7, 4, 6, 2, 2, 2,
0, 1, 6, 4, 4, 2, 2, 3])
——————————————————————————————————————————————————————————————————————————————————
predict tensor([8, 5, 5, 0, 5, 1, 5, 5, 8, 5, 0, 5, 8, 5, 5, 5, 9, 5, 5, 0, 0, 6, 5, 9,
4, 8, 5, 5, 5, 5, 0, 5, 5, 5, 5, 6, 5, 5, 5, 9, 5, 5, 5, 5, 5, 5, 5, 5,
5, 9, 5, 5, 5, 0, 5, 5, 5, 5, 5, 0, 5, 5, 5, 5, 5, 6, 5, 0, 0, 5, 5, 5,
5, 0, 5, 5, 5, 5, 5, 5, 5, 5, 5, 1, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
0, 8, 5, 5, 5, 5, 5, 5, 0, 5, 5, 5, 5, 5, 6, 5, 0, 5, 5, 5, 5, 5, 1, 5,
0, 5, 5, 5, 5, 8, 0, 5])
——————————————————————————————————————————————————————————————————————————————————
torch.max(outputs.data, 1) torch.return_types.max(
values=tensor([0.5065, 0.7543, 0.6870, 0.5797, 0.8060, 0.5807, 0.8916, 0.8384, 0.6661,
0.7025, 0.6533, 0.5792, 0.4674, 0.4923, 0.7330, 0.6329, 0.7567, 0.8452,
0.5539, 0.5508, 0.8430, 0.7644, 0.4222, 0.6187, 0.4145, 0.4590, 0.6177,
0.7669, 0.7348, 0.7471, 0.5506, 0.5542, 0.8766, 0.7319, 0.8065, 0.7228,
0.5451, 0.9202, 0.7277, 0.3017, 0.6730, 0.5296, 0.8899, 0.9897, 0.7398,
0.6049, 0.7202, 0.6861, 0.6422, 0.5075, 0.8285, 0.6734, 0.7960, 0.6078,
0.6625, 0.6545, 0.7238, 0.6220, 0.6018, 0.8207, 0.9552, 0.7145, 0.7219,
0.7507, 0.6705, 0.4326, 0.6819, 0.4687, 0.8995, 0.6956, 0.5216, 0.6844,
0.6044, 0.5092, 0.5973, 0.6014, 0.9122, 0.7713, 0.8200, 0.7941, 0.6144,
0.5310, 0.7001, 0.3465, 0.5593, 0.4223, 0.6370, 0.6482, 0.7080, 0.6428,
0.7696, 0.8263, 0.5839, 0.7708, 0.7660, 0.8303, 0.7790, 0.6033, 0.4704,
0.7534, 0.6832, 0.5292, 0.8298, 0.6661, 0.5930, 0.6637, 0.5390, 1.1338,
0.9344, 0.2917, 0.4034, 0.8946, 0.6636, 0.4957, 0.8308, 0.9687, 0.6173,
0.7422, 0.5396, 0.6783, 0.6139, 0.8782, 0.9697, 0.8204, 0.5765, 0.3932,
0.8845, 0.7806], device='cuda:0'),
indices=tensor([8, 5, 5, 0, 5, 1, 5, 5, 8, 5, 0, 5, 8, 5, 5, 5, 9, 5, 5, 0, 0, 6, 5, 9,
4, 8, 5, 5, 5, 5, 0, 5, 5, 5, 5, 6, 5, 5, 5, 9, 5, 5, 5, 5, 5, 5, 5, 5,
5, 9, 5, 5, 5, 0, 5, 5, 5, 5, 5, 0, 5, 5, 5, 5, 5, 6, 5, 0, 0, 5, 5, 5,
5, 0, 5, 5, 5, 5, 5, 5, 5, 5, 5, 1, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5,
0, 8, 5, 5, 5, 5, 5, 5, 0, 5, 5, 5, 5, 5, 6, 5, 0, 5, 5, 5, 5, 5, 1, 5,
0, 5, 5, 5, 5, 8, 0, 5], device='cuda:0'))从sklearn import了metrics用作度量计算?metrics.accuracy_score(true, predict)也需要进行查看,reference:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.accuracy_score.html
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
2- 调用evaluate方法得到在验证机上的acc和loss,这里evaluate方法见之后补充
- 为什么在total_batch%100 == 0的时候调用model.train(),调用model.train是在进行什么操作? 因为这里的model对应的应该是bert的那个pretrain?->在evaluate中切换到了eval状态,现在需要切换回train状态
- 最终调用一个test()来在最终的测试集上进行测试,test方法见之后补充
def train(config, model, train_iter, dev_iter, test_iter):
start_time = time.time()
model.train()
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}]
# optimizer = torch.optim.Adam(model.parameters(), lr=config.learning_rate)
optimizer = BertAdam(optimizer_grouped_parameters,
lr=config.learning_rate,
warmup=0.05,
t_total=len(train_iter) * config.num_epochs)
total_batch = 0 # 记录进行到多少batch
dev_best_loss = float('inf')
last_improve = 0 # 记录上次验证集loss下降的batch数
flag = False # 记录是否很久没有效果提升
model.train()
for epoch in range(config.num_epochs):
print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs))
for i, (trains, labels) in enumerate(train_iter):
outputs = model(trains)
model.zero_grad()
loss = F.cross_entropy(outputs, labels)
loss.backward()
optimizer.step()
if total_batch % 100 == 0:
# 每多少轮输出在训练集和验证集上的效果
true = labels.data.cpu()
predic = torch.max(outputs.data, 1)[1].cpu()
train_acc = metrics.accuracy_score(true, predic)
dev_acc, dev_loss = evaluate(config, model, dev_iter)
if dev_loss < dev_best_loss:
dev_best_loss = dev_loss
torch.save(model.state_dict(), config.save_path)
improve = '*'
last_improve = total_batch
else:
improve = ''
time_dif = get_time_dif(start_time)
msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}'
print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve))
model.train()
total_batch += 1
if total_batch - last_improve > config.require_improvement:
# 验证集loss超过1000batch没下降,结束训练
print("No optimization for a long time, auto-stopping...")
flag = True
break
if flag:
break
test(config, model, test_iter)def evaluate(config, model, data_iter, test=False):
- evaluate在可被用来在训练集,验证集上进行数据验证,在train函数中进行了调用
- model.eval()如何理解,这里的model似乎就是来自于pretrain的bert这个model?所以在这里的.eval()如何理解
- 初始化两个空的numpy arr
- 为什么with torch.no_grad()->torch.no_grad()是一个上下文管理器,被该语句 wrap 起来的部分将不会track 梯度,所以看起来在evaluate的时候,需要抑制模型的参数更新过程
- test是evalutate中传入的参数,在训练过程的test传为False,在测试过程的test传为True
def evaluate(config, model, data_iter, test=False):
model.eval()
loss_total = 0
predict_all = np.array([], dtype=int)
labels_all = np.array([], dtype=int)
with torch.no_grad():
for texts, labels in data_iter:
outputs = model(texts)
loss = F.cross_entropy(outputs, labels)
loss_total += loss
labels = labels.data.cpu().numpy()
predic = torch.max(outputs.data, 1)[1].cpu().numpy()
labels_all = np.append(labels_all, labels)
predict_all = np.append(predict_all, predic)
acc = metrics.accuracy_score(labels_all, predict_all)
if test:
report = metrics.classification_report(labels_all, predict_all, target_names=config.class_list, digits=4)
confusion = metrics.confusion_matrix(labels_all, predict_all)
return acc, loss_total / len(data_iter), report, confusion
return acc, loss_total / len(data_iter)def test(config, model, test_iter):
- 测试代码,调用了evaluate函数并将test传为True
- 这里也使用model.eval(),该怎么理解?
def test(config, model, test_iter):
# test
model.load_state_dict(torch.load(config.save_path))
model.eval()
start_time = time.time()
test_acc, test_loss, test_report, test_confusion = evaluate(config, model, test_iter, test=True)
msg = 'Test Loss: {0:>5.2}, Test Acc: {1:>6.2%}'
print(msg.format(test_loss, test_acc))
print("Precision, Recall and F1-Score...")
print(test_report)
print("Confusion Matrix...")
print(test_confusion)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)五、run.py
这部分就没啥说的了,主要是运行时需要的参数配置
下载好预训练模型就可以跑了。
# 训练并测试:
# bert
python run.py --model bert
# bert + 其它
python run.py --model bert_CNN
# ERNIE
python run.py --model ERNIE总结
周六就应该待在实验室学习,摸鱼(建议大家看看清华大学的摸鱼导论,多多摸鱼!),对的,没错!


