【Designing ML Systems】第 5 章 :特征工程
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
学习特征与工程特征
通用特征工程操作
处理缺失值
删除
插补
缩放
离散化
编码分类特征
特征交叉
离散和连续位置嵌入
数据泄露
数据泄露的常见原因
随机而不是按时间拆分与时间相关的数据
拆分前缩放
用测试拆分的统计数据填充缺失的数据
拆分前数据重复处理不当
群漏
数据生成过程中的泄漏
检测数据泄露
工程优良特性
特征重要性
特征泛化
概括
2014 年,论文“Practical Lessons from Predicting Clicks on Ads at Facebook”声称,拥有正确的特征是开发他们的机器学习模型最重要的事情。从那时起,与我合作过的许多公司一次又一次地发现,与超参数调整等聪明的算法技术相比,一旦他们有了一个可行的模型,拥有正确的特性往往会给他们带来最大的性能提升。如果不使用一组好的特性,最先进的模型架构仍然会表现不佳。
由于其重要性,许多 ML 工程和数据科学工作的很大一部分是提出新的有用功能。在本章中,我们将讨论有关特征工程的常用技术和重要考虑因素。我们将专门用一节详细介绍一个微妙但灾难性的问题,该问题已使许多生产中的机器学习系统脱轨:数据泄漏以及如何检测和避免它。
我们将结束本章讨论如何设计好的特征,同时考虑特征重要性和特征泛化。说到特征工程,可能有人会想到特征存储。由于特征存储更接近于支持多个 ML 应用程序的基础设施,我们将在第 10 章介绍特征存储。
学习特征与工程特征
当我在课堂上讨论这个话题时,我的学生们经常问:“为什么我们要担心特征工程?难道深度学习不会向我们保证我们不再需要设计特征吗?”
他们是对的。深度学习的承诺是我们不必手工制作特征。因此,深度学习有时被称为特征学习。1许多特征可以通过算法自动学习和提取。然而,我们离所有功能都可以自动化的地步还很远。更不用说,在撰写本文时,生产中的大多数 ML 应用程序都不是深度学习。让我们通过一个示例来了解哪些特征可以自动提取,哪些特征仍然需要手工制作。
想象一下,您要构建情绪分析分类器,用于分类评论是否为垃圾邮件。在深度学习之前,当给定一段文本时,您必须手动应用经典的文本处理技术,例如词形还原、扩展收缩、删除标点符号和小写所有内容。之后,您可能希望将文本拆分为具有您选择的n 个值的 n-gram。
对于那些不熟悉的人,n-gram 是来自给定文本样本的n 个项目的连续序列。这项目可以是音素、音节、字母或单词。例如,给定帖子“我喜欢食物”,其单词级别的 1-gram 是 [“I”, “like”, “food”],其单词级别的 2-gram 是 [“I like”, “like食物”]。这句话的n-gram特征集,如果我们想让n为1和2,就是:[“I”,“like”,“food”,“I like”,“like food”]。
图 5-1显示了一个经典文本处理技术的示例,您可以使用这些技术为您的文本手工制作 n-gram 特征。

图 5-1。可用于为文本手工制作 n-gram 特征的技术示例
一旦你生成了 n-gram您的训练数据,您可以创建一个词汇表,将每个 n-gram 映射到一个索引。然后,您可以根据其 n-gram 索引将每个帖子转换为向量。例如,如果我们有一个包含 7 个 n-gram 的词汇表,如表 5-1所示,那么每个帖子都可以是一个包含七个元素的向量。每个元素对应于该索引处的 n-gram 在帖子中出现的次数。“我喜欢食物”将被编码为向量 [1, 1, 0, 1, 1, 0, 1]。然后可以将该向量用作 ML 模型的输入。
| I | like | good | food | I like | good food | like food |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |
特征工程需要特定领域技术的知识——在这种情况下,领域是自然语言处理 (NLP) 和文本的母语。它往往是一个迭代过程,可能很脆弱。当我在一个早期的 NLP 项目中采用这种方法时,我一直不得不重新启动我的过程,要么是因为我忘记了应用一种技术,要么是因为我使用的一种技术效果不佳,我不得不撤消它。
然而,自从深度学习兴起以来,这种痛苦在很大程度上得到了缓解。不必担心词形还原、标点符号或停用词删除,您只需将原始文本拆分为单词(即标记化),从这些单词中创建词汇表,然后使用此方法将每个单词转换为一次性向量词汇。您的模型有望学会从中提取有用的特征。在这种新方法中,文本的大部分特征工程已经自动化。图像也取得了类似的进展。您无需手动从原始图像中提取特征并将这些特征输入到您的 ML 模型中,您只需将原始图像直接输入到您的深度学习模型中即可。
但是,ML 系统可能需要的数据不仅仅是文本和图像。例如,在检测评论是否为垃圾邮件时,除了评论本身的文本之外,您可能还想使用有关以下内容的其他信息:
评论
它有多少赞成票/反对票?
发表此评论的用户
此帐户是何时创建的,他们多久发布一次,以及他们有多少赞成/反对票?
发表评论的线程
它有多少视图?流行的线程往往会吸引更多的垃圾邮件。
在您的模型中可以使用许多可能的功能。其中一些如图 5-2所示。选择要使用的信息以及如何将此信息提取为 ML 模型可用的格式的过程是特征工程。对于复杂的任务,例如推荐视频供用户在 TikTok 上观看,使用的功能数量可能高达数百万。对于特定领域的任务,例如预测交易是否欺诈,您可能需要具备专业知识的银行和欺诈能够想出有用的功能。
图 5-2。模型中包含的关于评论、话题或用户的一些可能特征
通用特征工程操作
由于特征工程在 ML 项目中的重要性和普遍性,已经开发了许多技术来简化流程。在本节中,我们将讨论在从数据中设计特征时可能需要考虑的几个最重要的操作。它们包括处理缺失值、缩放、离散化、编码分类特征,以及生成老式但仍然非常有效的交叉特征以及更新和令人兴奋的位置特征。此列表远非全面,但它确实包含了一些最常见和最有用的操作,可以为您提供一个良好的起点。让我们潜入吧!
处理缺失值
您可能会注意到的第一件事在生产中处理数据时,缺少某些值。但是,我采访过的许多 ML 工程师不知道的一件事是,并非所有类型的缺失值都是相等的。2为了说明这一点,请考虑预测某人是否会在未来 12 个月内买房的任务。我们掌握的部分数据在表 5-2中。
| ID | Age | Gender | Annual income | Marital status | Number of children | Job | Buy? |
|---|---|---|---|---|---|---|---|
| 1 | A | 150,000 | 1 | Engineer | No | ||
| 2 | 27 | B | 50,000 | Teacher | No | ||
| 3 | A | 100,000 | Married | 2 | Yes | ||
| 4 | 40 | B | 2 | Engineer | Yes | ||
| 5 | 35 | B | Single | 0 | Doctor | Yes | |
| 6 | A | 50,000 | 0 | Teacher | No | ||
| 7 | 33 | B | 60,000 | Single | Teacher | No | |
| 8 | 20 | B | 10,000 | Student | No |
缺失值分为三种类型。这些类型的官方名称有点混乱,因此我们将通过详细的示例来减轻混淆。
非随机缺失 (MNAR)
这是缺少值的原因是因为真值本身。在这个例子中,我们可能会注意到一些受访者没有披露他们的收入。经调查发现,未报告的受访者的收入往往高于已披露的受访者。由于与值本身相关的原因,收入值缺失。
随机缺失 (MAR)
这是当一个值丢失的原因不是由于值本身,而是由于另一个观察到的变量。在在这个例子中,我们可能会注意到性别“A”的受访者经常缺少年龄值,这可能是因为本次调查中性别 A 的人不喜欢透露他们的年龄。
完全随机缺失 (MCAR)
这是当没有模式的时候缺少值。在这个例子中,我们可能认为“工作”列的缺失值可能是完全随机的,不是因为工作本身,也不是因为任何其他变量。人们有时会无缘无故忘记填写该值。然而,这种类型的失踪是非常罕见的。缺少某些值通常是有原因的,您应该进行调查。
遇到缺失值时,既可以用一定的值填充缺失值(插补),也可以去掉缺失值(删除)。我们将讨论两者。
删除
当我问候选人如何在面试过程中处理缺失值,许多人倾向于删除,不是因为它是一种更好的方法,而是因为它更容易做到。
删除的一种方法是删除列:如果一个变量有太多缺失值,只需删除它多变的。例如,在上面的示例中,变量“婚姻状况”的 50% 以上的值缺失,因此您可能想从模型中删除此变量。这种方法的缺点是您可能会删除重要信息并降低模型的准确性。婚姻状况可能与买房高度相关,因为已婚夫妇比单身人士更有可能成为房主。3
另一种删除方法是行删除:如果样本有缺失值,只需删除该样本。这种方法可以在缺失值完全随机(MCAR)且缺失值的示例数量较少(例如小于 0.1%)时起作用。如果这意味着删除了 10% 的数据样本,则您不想执行行删除。
但是,删除数据行也可能会删除模型进行预测所需的重要信息,尤其是在缺失值不是随机 (MNAR) 的情况下。例如,您不想删除收入缺失的性别 B 受访者样本,因为收入缺失的事实本身就是信息(收入缺失可能意味着更高的收入,因此与买房更相关)并且可以使用做出预测。
最重要的是,删除数据行可能会在模型中产生偏差,尤其是在缺失值是随机 (MAR) 的情况下。例如,如果您删除表 5-2中数据中所有缺失年龄值的示例,您将从数据中删除所有性别为 A 的受访者,您的模型将无法对性别为 A 的受访者做出良好的预测。
插补
即使删除很诱人,因为这很容易做到,删除数据会导致丢失重要信息并在模型中引入偏差。如果您不想删除缺失值,则必须估算它们,这意味着“用某些值填充它们”。决定使用哪些“特定值”是困难的部分。
一种常见的做法是用默认值填充缺失值。例如,如果作业丢失,您可以用空字符串“”填充它。另一种常见的做法是用平均值、中位数或众数(最常见的值)填充缺失值。例如,如果月份值为 7 月的数据样本缺少温度值,则使用 7 月的温度中值填充它不是一个坏主意。
这两种做法在许多情况下都很好用,但有时它们会导致毛毛虫。有一次,在我帮助的一个项目中,我们发现模型正在吐出垃圾,因为应用程序的前端不再要求用户输入他们的年龄,因此缺少年龄值,模型用 0 填充它们。但是该模型在训练期间从未看到年龄值为 0,因此无法做出合理的预测。
一般来说,要避免用可能的值来填充缺失值,例如用 0-0 填充缺失的子代数是子代数的可能值。这使得很难区分信息丢失的人和没有孩子的人。
可以同时或依次使用多种技术来处理特定数据集的缺失值。不管你使用什么技术,有一件事是肯定的:没有完美的方法来处理缺失值。删除后,您可能会丢失重要信息或加剧偏见。通过插补,您可能会注入自己的偏见向您的数据中添加噪音,或者更糟糕的是,数据泄漏。如果您不知道什么是数据泄漏,请不要惊慌,我们将在“数据泄漏”部分进行介绍。
缩放
考虑预测任务未来12个月是否有人买房,数据见表5-2。我们数据中变量 Age 的值范围为 20 到 40,而变量年收入的值范围为 10,000 到 150,000。当我们将这两个变量输入到 ML 模型中时,它不会理解 150,000 和 40 代表不同的事物。它只会将它们都视为数字,并且因为数字 150,000 比 40 大得多,它可能会赋予它更多的重要性,而不管哪个变量实际上对生成预测更有用。
在将特征输入模型之前,将它们缩放到相似的范围很重要。这个过程称为特征缩放。这是您可以做的最简单的事情之一,通常可以提高模型的性能。忽视这样做可能会导致您的模型做出胡言乱语的预测,尤其是使用梯度提升树和逻辑回归等经典算法时。4
扩展特征的一种直观方法是使它们在 [0, 1] 范围内。给定一个变量x,它的值可以使用以下公式重新调整到这个范围内:

您可以验证如果x是最大值,则缩放值x ' 将为 1。如果x是最小值,则缩放值x ' 将为 0。
如果您希望您的特征在任意范围 [ a , b ] 中——根据经验,我发现范围 [–1, 1] 比 [0, 1] 范围更好——你可以使用以下公式:

当您不想对变量做出任何假设时,缩放到任意范围效果很好。如果您认为您的变量可能服从正态分布,则将它们归一化以使它们具有零均值和单位方差可能会有所帮助。这个过程称为标准化:

和X¯是变量x的平均值,并且p是它的标准差。
在实践中,ML 模型倾向于与遵循偏态分布的功能作斗争。为了帮助减轻偏度,一种常用的技术是对数转换:将对数函数应用于您的特征。图 5-3显示了一个日志转换如何减少数据偏差的示例。虽然这种技术可以在许多情况下产生性能提升,但它并不适用于所有情况,您应该警惕对日志转换数据而不是原始数据执行的分析。5

图 5-3。在许多情况下,对数转换可以帮助减少数据的偏斜
关于缩放有两件重要的事情需要注意。一是它是数据泄漏的常见来源(这将在“数据泄漏”部分更详细地介绍)。另一个是它通常需要全局统计——你必须查看整个或一部分训练数据来计算它的最小值、最大值或平均值。在推理过程中,您可以重复使用在训练期间获得的统计数据来扩展新数据。如果新数据与训练相比发生了显着变化,那么这些统计数据将不是很有用。因此,经常重新训练您的模型以考虑到这一点很重要对于这些变化。
离散化
该技术包含在本书中,用于完整性,尽管在实践中,我很少发现离散化有帮助。假设我们已经使用表 5-2中的数据构建了一个模型。在训练过程中,我们的模型已经看到了“150,000”、“50,000”、“100,000”等的年收入值。在推理过程中,我们的模型遇到了一个年收入为“9,000.50”的例子。
直观地说,我们知道每年 9,000.50 美元与每年 10,000 美元没有太大区别,我们希望我们的模型以同样的方式对待这两者。但模型不知道这一点。我们的模型只知道 9,000.50 和 10,000 不同,它会区别对待它们。
离散化是将连续特征转化为离散特征的过程。这个过程也称为量化或分箱。这是通过为给定值创建存储桶来完成的。对于年收入,您可能希望将它们分为三个桶,如下所示:
-
较低的收入:低于 35,000 美元/年
-
中等收入:35,000 至 100,000 美元/年
-
高收入:超过10万美元/年
我们的模型不必学习无限数量的可能收入,而是可以只专注于学习三个类别,这是一项更容易学习的任务。这种技术应该对有限的训练数据更有帮助。
尽管根据定义,离散化是针对连续特征的,但它也可以用于离散特征。年龄变量是离散的,但将值分组到如下桶中可能仍然有用:
-
小于 18
-
18 至 22 岁之间
-
22 到 30 之间
-
30 到 40 之间
-
40 到 65 之间
-
65岁以上
缺点是这种分类在类别边界处引入了不连续性——34,999 美元现在被视为与 35,000 美元完全不同,后者被视为与 100,000 美元相同。选择类别的边界可能并不那么容易。你可以尝试绘制值的直方图并选择有意义的边界。一般来说,常识、基本分位数,有时甚至是主题专业知识都会有所帮助。
编码分类特征
我们已经讨论过如何转为连续特征转化为分类特征。在本节中,我们将讨论如何最好地处理分类特征。
没有在生产中使用过数据的人倾向于认为类别是静态的,这意味着类别不会随着时间而改变。许多类别都是如此。例如,年龄段和收入等级不太可能发生变化,并且您可以提前确切知道有多少类别。处理这些类别很简单。你可以给每个类别一个数字,你就完成了。
但是,在生产中,类别会发生变化。想象一下,您正在构建一个推荐系统来预测用户可能想从亚马逊购买哪些产品。您要使用的功能之一是产品品牌。在查看亚马逊的历史数据时,您会发现品牌众多。早在 2019 年,亚马逊上就已经有超过 200 万个品牌!6
品牌的数量是压倒性的,但你认为:“我仍然可以处理这个。” 您将每个品牌编码为一个数字,所以现在您有 200 万个数字,从 0 到 1,999,999,对应于 200 万个品牌。您的模型在历史测试集上表现出色,并且您获准在今天的 1% 的流量上对其进行测试。
在生产中,您的模型会崩溃,因为它遇到了以前从未见过的品牌,因此无法编码。新品牌一直在加入亚马逊。为了解决这个问题,您创建了一个值为 2,000,000 的类别 UNKNOWN,以捕获您的模型在训练期间未见过的所有品牌。
您的模型不再崩溃,但您的卖家抱怨他们的新品牌没有获得任何流量。这是因为您的模型在火车集中没有看到类别 UNKNOWN,所以它不推荐任何 UNKNOWN 品牌的产品。您可以通过仅将前 99% 最受欢迎的品牌编码并将后 1% 的品牌编码为 UNKNOWN 来解决此问题。这样,至少您的模型知道如何处理 UNKNOWN 品牌。
您的模型似乎可以正常工作大约一小时,然后产品推荐的点击率直线下降。在过去的一个小时内,有 20 个新品牌加入了您的网站;其中一些是新的奢侈品牌,其中一些是粗略的仿冒品牌,其中一些是老牌品牌。但是,您的模型对待它们的方式与处理训练数据中不受欢迎的品牌的方式相同。
这不是一个极端的例子,只有在亚马逊工作时才会发生。这个问题经常发生。例如,如果您想预测评论是否为垃圾邮件,您可能希望将发布此评论的帐户用作一项功能,并且一直在创建新帐户。新产品类型、新网站域、新餐厅、新公司、新 IP 地址等也是如此。如果你与他们中的任何一个一起工作,你将不得不处理这个问题。
找到解决这个问题的方法被证明是非常困难的。您不想将它们放入一组存储桶中,因为这真的很难——您甚至会如何将新用户帐户放入不同的组中?
这个问题的一种解决方案是散列技巧,由微软开发的包 Vowpal Wabbit 推广。7这个技巧的要点是您使用散列函数来生成每个类别的散列值。散列值将成为该类别的索引。因为可以指定散列空间,所以可以预先固定一个特征的编码值数量,而不必知道会有多少类别。例如,如果您选择一个 18 位的散列空间,对应于 2 18 = 262,144 个可能的散列值,那么所有类别,即使是您的模型从未见过的类别,都将由 0 到 262,143 之间的索引编码。
散列函数的一个问题是冲突:两个类别被分配了相同的索引。然而,对于许多散列函数,冲突是随机的;新品牌可以与任何现有品牌共享索引,而不是总是与不受欢迎的品牌共享索引,当我们使用前面的 UNKNOWN 类别时会发生这种情况。幸运的是,碰撞散列特征的影响并没有那么糟糕。在 Booking.com 的研究中,即使是 50% 的碰撞特征,性能损失也小于 0.5%,如图 5-4所示。8

图 5-4。50% 的碰撞率只会导致 log loss 增加不到 0.5%。资料来源:卢卡斯·伯纳迪
你可以选择一个足够大的散列空间来减少冲突。您还可以选择具有所需属性的散列函数,例如位置敏感的散列函数,其中相似的类别(例如具有相似名称的网站)被散列为彼此接近的值。
因为这是一个技巧,所以它经常被学者们认为是 hacky 并且被排除在 ML 课程之外。但它在行业中的广泛采用证明了该技巧的有效性。它对 Vowpal Wabbit 至关重要,它是 scikit-learn、TensorFlow 和 gensim 框架的一部分。它在模型的持续学习环境中特别有用从生产中的传入示例中学习。我们将在第 9 章介绍持续学习。
特征交叉
特征交叉是技术组合两个或多个特征以生成新特征。该技术可用于对特征之间的非线性关系进行建模。例如,对于预测某人是否会在未来 12 个月内买房的任务,您怀疑婚姻状况和孩子数量之间可能存在非线性关系,因此您将它们结合起来创建一个新特征“婚姻和儿童”,如表 5-3 所示。
表 5-3。如何组合两个功能以创建新功能的示例
| Marriage | Single | Married | Single | Single | Married |
| Children | 0 | 2 | 1 | 0 | 1 |
| Marriage and children | Single, 0 | Married, 2 | Single, 1 | Single, 0 | Married, 1 |
因为特征交叉有助于对变量之间的非线性关系进行建模,所以对于无法学习或不善于学习非线性关系的模型(例如线性回归、逻辑回归和基于树的模型)来说,它是必不可少的。它在神经网络中不太重要,但它仍然很有用,因为显式特征交叉有时有助于神经网络更快地学习非线性关系。DeepFM 和 xDeepFM 是成功利用显式特征交互进行推荐系统和点击率预测的模型家族。9
特征交叉的一个警告是它可以让你的特征空间爆炸。假设特征 A 有 100 个可能的值,而特征 B 有 100 个可能的特征;交叉这两个特征将产生一个具有 100 × 100 = 10,000 个可能值的特征。您将需要更多的模型数据来学习所有这些可能的值。另一个需要注意的是,由于特征交叉增加了模型使用的特征数量,它会使模型过度拟合训练数据。
离散和连续位置嵌入
在论文“Attention Is All You Need” (Vaswani et al. 2017)中首次向深度学习社区介绍,位置嵌入已成为一种适用于计算机视觉和 NLP 中许多应用的标准数据工程技术。我们将通过一个示例来说明为什么位置嵌入是必要的以及如何做到这一点。
考虑语言建模任务,您希望根据先前的标记序列预测下一个标记(例如,单词、字符或子词)。在实践中,序列长度可以达到 512,如果不是更大的话。然而,为简单起见,让我们使用单词作为我们的标记,并使用 8 的序列长度。给定 8 个单词的任意序列,例如“有时我真正想做的是”,我们想要预测下一个单词。
嵌入
嵌入是一个向量代表一段数据。我们将由同一算法为一类数据生成的所有可能嵌入集合称为“嵌入空间”。同一空间中的所有嵌入向量具有相同的大小。
嵌入最常见的用途之一是词嵌入,您可以在其中用向量表示每个单词。然而,其他类型数据的嵌入越来越受欢迎。例如,Criteo 和 Coveo 等电子商务解决方案具有产品嵌入。10 Pinterest 嵌入了图像、图表、查询甚至用户。11鉴于嵌入的数据类型如此之多,人们对为多模态数据创建通用嵌入很感兴趣。
如果我们使用循环神经网络,它将按顺序处理单词,这意味着单词是隐式输入的。但是,如果我们使用像转换器这样的模型,单词是并行处理的,因此需要显式输入单词的位置,以便我们的模型知道这些单词的顺序(“a dog beats a child”与“a孩子咬狗”)。我们不想将绝对位置 0、1、2、...、7 输入到我们的模型中,因为根据经验,神经网络不能很好地处理非单位方差的输入(这就是我们缩放特征的原因,如前面“缩放”部分所述)。
如果我们将位置重新缩放到 0 和 1 之间,那么 0, 1, 2, ..., 7 变为 0, 0.143, 0.286, ..., 1,这两个位置之间的差异将太小,神经网络无法学习区分。
处理位置嵌入的一种方法是像对待词嵌入一样对待它。对于词嵌入,我们使用一个以词汇量大小作为列数的嵌入矩阵,每一列是该列索引处的词的嵌入。使用位置嵌入,列数就是位置数。在我们的例子中,因为我们只使用之前的序列大小 8,所以位置从 0 到 7(见图 5-5)。
位置的嵌入大小通常与单词的嵌入大小相同,以便它们可以相加。例如,位置 0 处单词“food”的嵌入是单词“food”的嵌入向量和位置 0 的嵌入向量之和。这是截至 8 月在 Hugging Face 的 BERT 中实现位置嵌入的方式2021. 因为嵌入随着模型权重的更新而变化,所以我们说位置嵌入是学习的。
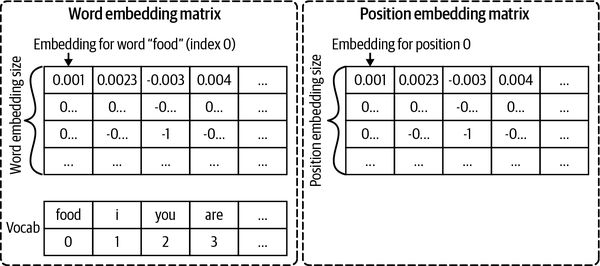
图 5-5。嵌入位置的一种方法是像对待词嵌入一样对待它们
位置嵌入也可以固定。每个位置的嵌入仍然是一个包含S个元素的向量(S是位置嵌入大小),但每个元素都是使用函数预定义的,通常是正弦和余弦。在原始的 Transformer 论文中,如果元素位于偶数索引处,请使用正弦。否则,使用余弦。请参见图5-6。
图 5-6。固定位置嵌入的示例。H 是模型产生的输出的维度。
固定位置嵌入是所谓的傅立叶特征的一个特例。如果位置嵌入中的位置是离散的,则傅立叶特征也可以是连续的。考虑涉及 3D 对象表示的任务,例如茶壶。茶壶表面的每个位置都用一个连续的三维坐标表示。当位置连续时,很难构建具有连续列索引的嵌入矩阵,但使用正弦和余弦函数的固定位置嵌入仍然有效。
以下是通用格式在坐标v处嵌入向量,也称为坐标v的傅里叶特征。傅立叶特征已被证明可以提高模型的性能对于将坐标(或位置)作为输入的任务。如果有兴趣,您可能想在“傅里叶特征让网络学习低维域中的高频函数”(Tancik 等人,2020 年)中阅读更多相关信息。

数据泄露
2021 年 7 月,《麻省理工科技评论》发表了一篇具有煽动性的文章,标题为“已经构建了数百种 AI 工具来应对新冠病毒。他们都没有帮助。” 这些模型被训练成通过医学扫描预测 COVID-19 风险。该文章列出了多个示例,其中在评估期间表现良好的 ML 模型无法在实际生产环境中使用。
在一个例子中,研究人员在患者躺下和站立时进行的混合扫描训练他们的模型。“因为躺着扫描的患者更有可能患重病,该模型学会了从一个人的位置预测严重的新冠病毒风险。”
在其他一些情况下,模型“被发现使用某些医院用来标记扫描的文本字体。结果,来自具有更严重病例的医院的字体成为了新冠病毒风险的预测指标。” 12
这两个都是数据泄露的例子。数据泄漏是指一种形式的标签“泄漏”到用于进行预测的特征集中,并且在推理过程中无法获得相同的信息。
数据泄漏具有挑战性,因为泄漏通常是不明显的。这很危险,因为即使经过广泛的评估和测试,它也可能导致您的模型以意想不到的惊人方式失败。让我们通过另一个示例来演示什么是数据泄漏。
假设您要构建一个 ML 模型来预测肺部 CT 扫描是否显示癌症迹象。您从医院 A 获取数据,从数据中删除医生的诊断,并训练您的模型。它在医院 A 的测试数据上表现非常好,但在医院 B 的数据上表现不佳。
经过广泛调查,您了解到在 A 医院,当医生认为患者患有肺癌时,他们会将患者送至更先进的扫描机,该扫描机输出的 CT 扫描图像略有不同。您的模型学会了依赖扫描机器上的信息来预测扫描图像是否显示肺癌迹象。医院 B 将患者随机发送到不同的 CT 扫描机,因此您的模型没有可依赖的信息。我们说标签在训练期间泄漏到特征中。
数据泄露不仅可能发生在该领域的新手身上,而且也发生在几位经验丰富的研究人员身上,我钦佩他们的工作,以及在我自己的一个项目中。尽管数据泄漏很普遍,但机器学习课程中很少涉及数据泄漏。
警示故事:KAGGLE 竞赛导致数据泄露
2020 年,利物浦大学在 Kaggle 上发起了 Ion Switching 比赛。任务是确定每个时间点打开的离子通道的数量。他们从训练数据中合成了测试数据,还有一些人们能够逆向工程并从泄漏中获取测试标签。13本次比赛的两支获胜球队是能够利用漏洞的两支球队,尽管他们可能在不利用漏洞的情况下仍然能够获胜。14
数据泄露的常见原因
在本节中,我们将讨论一些导致数据泄漏的常见原因以及如何避免它们。
随机而不是按时间拆分与时间相关的数据
当我在大学学习 ML 时,我被教导将我的数据随机拆分为训练、验证和测试拆分。据报道,这也是机器学习研究论文中数据经常被拆分的方式。然而,这也是数据泄露的常见原因之一。
在许多情况下,数据是时间相关的,这意味着数据生成的时间会影响其标签分布。有时,相关性是显而易见的,例如股票价格。简单地说,类似股票的价格往往会一起波动。如果今天 90% 的科技股下跌,那么其他 10% 的科技股很可能也会下跌。在构建预测未来股票价格的模型时,您希望按时间拆分训练数据,例如根据前六天的数据训练模型并根据第七天的数据对其进行评估。如果您随机拆分数据,则从第 7 天开始的价格将包含在您的火车拆分中,并将当天的市场状况泄漏到您的模型中。我们说来自未来的信息被泄露到训练过程中。
然而,在许多情况下,相关性并不明显。考虑预测某人是否会点击歌曲推荐的任务。一个人是否会听一首歌不仅取决于他们的音乐品味,还取决于当天的总体音乐趋势。如果某天某位艺术家去世,人们将更有可能聆听该艺术家的作品。通过在火车拆分中包含某一天的样本,有关当天音乐趋势的信息将传递到您的模型中,使其更容易在同一天对其他样本进行预测。
为了防止未来的信息泄漏到训练过程中并允许模型在评估期间作弊,请尽可能按时间拆分数据,而不是随机拆分。例如,如果您有 5 周的数据,则使用前 4 周进行训练拆分,然后将第 5 周随机拆分为验证和测试拆分,如图 5-7所示。
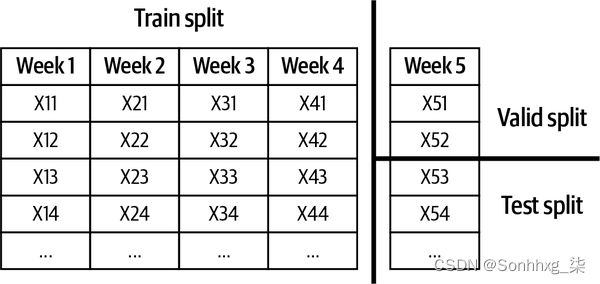
图 5-7。按时间拆分数据,防止未来信息泄漏到训练过程中
拆分前缩放
正如“缩放”一节中所讨论的,缩放你的特征。缩放需要数据的全局统计数据,例如均值、方差。一个常见的错误是使用整个训练数据生成全局统计数据,然后将其拆分为不同的拆分,将测试样本的均值和方差泄漏到训练过程中,从而允许模型调整其对测试样本的预测。此信息在生产中不可用,因此模型的性能可能会降低。
为避免这种类型的泄漏,请始终在缩放之前先拆分数据,然后使用训练拆分的统计信息来缩放所有拆分。有些人甚至建议我们在进行任何探索性数据分析和数据处理之前拆分我们的数据,这样我们就不会意外获得有关测试拆分的信息。
用测试拆分的统计数据填充缺失的数据
处理缺失值的一种常用方法一个特征是用所有存在的值的平均值或中值填充(输入)它们。如果使用整个数据而不是仅训练拆分来计算平均值或中位数,则可能会发生泄漏。这种类型的泄漏类似于由缩放引起的泄漏类型,可以通过仅使用来自 train split 的统计信息来填充所有 split 中的缺失值来防止这种泄漏。
拆分前数据重复处理不当
如果您的数据中有重复或接近重复,在拆分数据之前未能将其删除可能会导致相同的样本出现在训练和验证/测试拆分中。数据重复在业界非常普遍,并且在流行的研究数据集中也有发现。例如,CIFAR-10 和 CIFAR-100 是用于计算机视觉研究的两个流行数据集。它们于 2009 年发布,但直到 2019 年,Barz 和 Denzler 才发现来自 CIFAR-10 和 CIFAR-100 数据集的测试集的 3.3% 和 10% 的图像在训练集中有重复。15
数据重复可能源于数据收集或不同数据源的合并。一篇 2021 Nature文章将数据重复列为使用 ML 检测 COVID-19 时的常见缺陷,这是因为“一个数据集结合了其他几个数据集,而没有意识到其中一个组件数据集已经包含另一个组件”。16数据重复也可能因数据处理而发生——例如,过采样可能会导致某些示例重复。
为避免这种情况,请务必在拆分之前和拆分后检查重复项以确保。如果您对数据进行过采样,请在拆分后进行。
群漏
一组实例强烈相关标签,但分为不同的部分。例如,一个患者可能有两次间隔一周的肺部 CT 扫描,它们可能具有相同的标签,说明它们是否包含肺癌的迹象,但其中一个是在 train split 中,第二个是在 test split 中。这种类型的泄漏对于包含相隔几毫秒的同一物体的照片的客观检测任务很常见——其中一些落在火车分割中,而另一些落在测试分割中。如果不了解您的数据是如何生成的,就很难避免这种类型的数据泄漏。
数据生成过程中的泄漏
前面关于 CT 扫描是否显示肺癌迹象的信息如何通过扫描泄露的示例机器就是这种泄漏的一个例子。检测这种类型的数据泄漏需要深入了解数据的收集方式。例如,如果您不了解不同的扫描机或两家医院的程序不同,则很难弄清楚该模型在 B 医院的表现不佳是由于其扫描机程序不同造成的。
没有万无一失的方法可以避免此类泄漏,但您可以通过跟踪数据来源并了解数据的收集和处理方式来降低风险。规范化您的数据,以便来自不同来源的数据可以具有相同的均值和方差。如果不同的 CT 扫描机输出具有不同分辨率的图像,将所有图像归一化为具有相同的分辨率将使模型更难知道哪个图像来自哪台扫描机。并且不要忘记将可能对如何收集和使用数据有更多背景的主题专家纳入 ML 设计过程!
检测数据泄露
数据泄漏可能发生在许多步骤中,从生成、收集、采样、拆分和处理数据到特征工程。在 ML 项目的整个生命周期中监控数据泄漏非常重要。
测量每个特征或一组特征对目标变量(标签)的预测能力。如果某个特征具有异常高的相关性,请调查该特征是如何生成的以及相关性是否有意义。有可能两个特征独立不包含泄漏,但是两个特征一起可以包含泄漏。例如,在构建模型来预测员工将在公司停留多长时间时,开始日期和结束日期分别不能告诉我们他们的任期,但两者一起可以为我们提供这些信息。
进行消融研究以衡量一个特征或一组特征对您的模型的重要性。如果删除某个特征会导致模型的性能显着下降,请调查该特征为何如此重要。如果你有大量的特征,比如一千个特征,对它们的每一个可能的组合进行消融研究可能是不可行的,但是偶尔用你最怀疑的特征子集进行消融研究仍然很有用. 这是主题专业知识如何在特征工程中派上用场的另一个例子。消融研究可以按照您自己的计划离线运行,因此您可以在停机期间利用您的机器来实现此目的。
留意添加到模型中的新功能。如果添加新功能显着提高了模型的性能,则要么该功能非常好,要么该功能仅包含有关标签的泄露信息。
每次查看测试拆分时都要非常小心。如果您以除报告模型最终性能之外的任何方式使用测试拆分,无论是提出新功能的想法还是调整超参数,您都有可能将未来的信息泄露到您的训练过程中。
工程优良特性
通常,添加更多特征会导致更好的模型性能。根据我的经验,用于生产模型的功能列表只会随着时间的推移而增加。然而,更多的特征并不总是意味着更好的模型性能。由于以下原因,在训练和服务模型期间拥有太多特征可能会很糟糕:
-
您拥有的功能越多,数据泄露的机会就越多。
-
太多的特征会导致过拟合。
-
太多的功能会增加为模型提供服务所需的内存,这反过来可能需要您使用更昂贵的机器/实例来为您的模型提供服务。
-
在进行在线预测时,过多的特征会增加推理延迟,尤其是当您需要从原始数据中提取这些特征以进行在线预测时。我们将在第 7 章深入探讨在线预测。
-
无用的功能变成技术债。每当您的数据管道发生变化时,都需要相应地调整所有受影响的功能。例如,如果有一天您的应用程序决定不再接收有关用户年龄的信息,那么所有使用用户年龄的功能都需要更新。
理论上,如果一个特征不能帮助模型做出好的预测,像 L1 正则化这样的正则化技术应该将该特征的权重降低到 0。然而,在实践中,如果不再有用的特征(和甚至可能有害)被删除,优先考虑好的功能。
您可以存储已删除的功能以供以后添加。您还可以只存储通用功能定义,以便在组织中的团队之间重复使用和共享。在谈论特征定义管理时,有些人可能会认为特征存储是解决方案。但是,并非所有特征存储都管理特征定义。我们将在第 10 章进一步讨论特征存储。
在评估一个特征是否适合模型时,您可能需要考虑两个因素:对模型的重要性和对未见数据的泛化。
特征重要性
有许多不同的方法衡量一个特征的重要性。如果您使用经典的 ML 算法,例如提升梯度树,衡量特征重要性的最简单方法是使用实现的内置特征重要性函数通过 XGBoost。17对于更多与模型无关的方法,您可能需要查看 SHAP(SHapley Additive exPlanations)。18 InterpretML是一个出色的开源软件包,它利用特征重要性来帮助您了解模型如何进行预测。
特征重要性测量的精确算法很复杂,但直观地说,特征的重要性如果从模型中删除该特征或包含该特征的一组特征,则该模型的性能下降多少来衡量模型的性能。SHAP 很棒,因为它不仅可以衡量一个特征对整个模型的重要性,还可以衡量每个特征对模型特定预测的贡献。图5-8和5-9显示了 SHAP 如何帮助您了解每个特征对模型预测的贡献。

图 5-8。每个特征对模型的单一预测有多大贡献,由 SHAP 衡量。值 LSTAT = 4.98 对这一特定预测的贡献最大。资料来源:斯科特·伦德伯格19

图 5-9。每个特征对模型的贡献程度,由 SHAP 衡量。特征 LSTAT 具有最高的重要性。资料来源:斯科特·伦德伯格
通常,少数特征占模型特征重要性的很大一部分。在测量点击率预测模型的特征重要性时,Facebook 的广告团队发现前 10 个特征约占模型总特征重要性的一半,而后 300 个特征贡献的特征重要性不到 1%,如图 5-10所示。20

图 5-10。提升特征重要性。X 轴对应于特征的数量。特征重要性以对数表示。资料来源:他等人。
不仅有利于选择正确的特征,特征重要性技术对可解释性也很有帮助,因为它们可以帮助您了解模型在后台是如何工作的。
特征泛化
由于 ML 模型的目标是对看不见的数据做出正确的预测,因此用于模型的特征应该泛化到看不见的数据。并非所有特征都具有同等的概括性。例如,对于预测评论是否为垃圾邮件的任务,每条评论的标识符根本无法泛化,不应该用作模型的特征。但是,发布评论的用户的标识符(例如用户名)可能仍然有助于模型进行预测。
衡量特征泛化远没有衡量特征重要性的科学性,它需要在统计知识之上的直觉和主题专业知识。总的来说,关于泛化,您可能需要考虑两个方面:特征覆盖和特征值的分布。
覆盖率是数据中具有此特征值的样本的百分比,因此缺失的值越少,覆盖率就越高。一个粗略的经验法则是,如果此功能出现在您数据的一小部分中,那么它就不会很普遍。例如,如果你想建立一个模型来预测某人是否会在未来 12 个月内买房,并且你认为某人拥有的孩子数量将是一个很好的特征,但你只能获得 1% 的这个信息您的数据,此功能可能不是很有用。
这个经验法则很粗略,因为即使您的大多数数据中缺少某些功能,它们仍然有用。当缺失值不是随机的时尤其如此,这意味着是否具有该特征可能是其价值的强烈指示。例如,如果某个特征仅出现在 1% 的数据中,但 99% 的具有此特征的示例都有 POSITIVE 标签,则此特征很有用,您应该使用它。
随着时间的推移,不同数据切片甚至同一数据切片中的特征覆盖范围可能会有很大差异。如果一个特征的覆盖率在训练集和测试集之间有很大差异(例如它出现在训练集的 90% 的示例中,但仅出现在测试集的 20% 的示例中),这表明您的训练和测试分裂不是来自同一个分布。您可能想调查拆分数据的方式是否有意义,以及此功能是否会导致数据泄漏。
对于存在的特征值,您可能需要查看它们的分布。如果出现在可见数据(例如训练拆分)中的值集与出现在未见过数据(例如测试拆分)中的值集没有重叠,则此功能甚至可能会损害模型的性能。
作为一个具体的例子,假设你想建立一个模型来估计给定出租车所需的时间。您每周重新训练此模型,并且您希望使用过去六天的数据来预测今天的 ETA(预计到达时间)。其中一项功能是 DAY_OF_THE_WEEK,您认为这很有用,因为工作日的流量通常比周末差。此功能覆盖率为 100%,因为它存在于每个功能中。但是,在火车拆分中,此特征的值是周一到周六,而在测试拆分中,此特征的值是周日。如果您在模型中包含此功能而没有巧妙的方案来编码日期,则它不会推广到测试拆分,并且可能会损害模型的性能。
另一方面,HOUR_OF_THE_DAY 是一个很棒的特征,因为一天中的时间也会影响交通,并且火车拆分中此特征的值范围与测试拆分 100% 重叠。
在考虑特征的泛化性时,需要在泛化性和特异性之间进行权衡。您可能会意识到一个小时内的流量仅根据该小时是否是高峰时间。因此,您生成特征 IS_RUSH_HOUR 并将其设置为 1,如果时间介于上午 7 点和上午 9 点之间或下午 4 点和下午 6 点之间,IS_RUSH_HOUR 更通用但不如 HOUR_OF_THE_DAY 特定。在没有 HOUR_OF_THE_DAY 的情况下使用 IS_RUSH_HOUR 可能会导致模型丢失有关小时的重要信息。
概括
由于当今 ML 系统的成功仍然取决于其功能,因此对于有兴趣在生产中使用 ML 的组织来说,将时间和精力投入到特征工程中非常重要。
如何设计好的功能是一个复杂的问题,没有万无一失的答案。最好的学习方式是通过经验:尝试不同的功能并观察它们如何影响模型的性能。也可以向专家学习。我发现阅读 Kaggle 比赛的获胜团队如何设计他们的功能以了解更多关于他们的技术和他们所经历的考虑非常有用。
特征工程通常涉及主题专业知识,而主题专家可能并不总是工程师,因此以允许非工程师参与流程的方式设计工作流程非常重要。
以下是特征工程最佳实践的总结:
-
按时间将数据拆分为训练/有效/测试拆分,而不是随机进行。
-
如果您对数据进行过采样,请在拆分后进行。
-
拆分后对数据进行缩放和规范化以避免数据泄漏。
-
仅使用来自火车分割的统计数据,而不是整个数据,来扩展您的特征并处理缺失值。
-
了解您的数据是如何生成、收集和处理的。如果可能,请让领域专家参与进来。
-
跟踪数据的沿袭。
-
了解特征对模型的重要性。
-
使用泛化良好的特征。
-
从您的模型中删除不再有用的功能。
有了一组好的特性,我们将进入工作流程的下一部分:训练 ML 模型。在我们继续之前,我只想重申,转向建模并不意味着我们已经完成了处理数据或特征工程。我们永远不会完成数据和功能。在大多数现实世界的 ML 项目中,只要您的模型处于生产状态,收集数据和特征工程的过程就会继续进行。我们需要使用新的传入数据来不断改进模型,这将在第 9 章中介绍。