python决策树 value_直播案例 | 决策树、随机森林和 AdaBoost 的 Python 实现
获取案例链接、直播课件、数据集在本公众号内发送“机器学习”。
本案例使用 Python 逐步实现了三种基于树的模型:分类回归决策树(CART)、随机森林和 AdaBoost 。在实现的过程中,我们借助 Matplotlib 和 Networkx 等工具对决策树进行了可视化,并使用简单的样例数据对三种算法的表现进行了分析。

1 分类决策树 Python 实现
我们首先加载一份鸢尾花数据集以便于测试。鸢尾花数据集包含 150 个鸢尾花样本,每个样本包含 4 个特征和一个类别标签,数据集下载地址为 UCI鸢尾花[1]。在 Sklearn 中可以使用 datasets.load_iris 方法直接加载该数据集。
from sklearn.datasets iris_df.head()
| sepal_len | sepal_width | petal_len | petal_width | targ | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5 | 3.6 | 1.4 | 0.2 | 0 |
下面我们开始实现 CART 决策树算法。首先,我们需要创建一个 TreeNode 类代表决策树的节点。CART 使用基尼系数 (Gini index) 作为不纯度度量,我们随后将实现一个 gini 函数来计算基尼系数。完成节点的定义和基尼系数的计算,我们就可以开始实现决策树的生成算法。为了直观地展示学习到的决策树的结构,我们将借助 matplotlib 和 networkx 实现决策树的可视化。
1.1 定义决策树节点
创建一个表示决策树节点的类TreeNode。决策树节点需要存储的最重要的信息为当前节点代表的特征 f 和切分点 v 。其次如果节点是非叶子节点,还需要存储左儿子节点 left 和右儿子节点 right。为了便于决策树进行预测,我们在每个节点中还要保存当前节点样本的分布 label_dist,它将在决策树生成时提供。在本案例的后续,我们还将把决策树绘制出来,为了方便绘制,我们给每一个节点还保存节点的坐标信息 pos ,也将在决策树生成时计算。
class TreeNode:上面的代码中,__str__ 函数定义调用打印函数 print 时输出的信息。对于非叶子节点(判断条件self.f != None),打印节点的特征和切分点;对于叶子节点,打印节点训练样本的类别分布和样本数量。这些信息将在绘制决策树时作为节点的标签信息。
1.2 基尼系数计算
Gini系数是一种度量落在决策树中某一个节点的样本分布不纯度的指标。假设数据集中样本一共有 个类别,在节点 中第 类样本的比例为 ,则节点 的不纯度为
假设样本的类别为正负两类,假设某个节点一共有 10 个样本,包括 5 个正样本和 5 个负样本,则基尼系数为
假设另一个节点有 20 个样本,包含 15 个正样本和 5 个负样本,则基尼系数为
实现一个不纯度计算方法 gini ,它的输入是当前节点样本的标签序列 。 是 Pandas 的 Series 结构。我们使用 value_counts 方法计算每一类样本的数量,然后借助 np.square 和 sum 函数计算其平方和。
import numpy 下图详细演示了基尼系数的计算过程。

import pandas 0.48
1.3 分类决策树生成
实现 generate 函数,输入数据子集,输出创建好的节点。其中 X 和 y 分别为训练集特征部分和标签部分,是该函数的主要输入,其余的输入参数为一些辅助参数,其主要含义如下表所示。
| 输入参数 | 含义说明 |
|---|---|
X |
数据子集特征部分,格式为 DataFrame |
y |
数据子集特征部分,格式为 Series |
x_pos |
节点x轴坐标 |
y_pos |
节点y轴坐标 |
nodes |
用户保存决策树中所有节点的列表 |
min_leaf_samples |
叶子节点最少样本数量 |
max_depth |
决策树最大深度 |
layer |
当前节点的层数,等于该节点父节点层数加1 |
class_labels |
样本的标签集合,格式为 Series |
决策树生成函数 generate 的主要流程为:
1 创建当前节点
current_node,计算其样本分布label_dist2 if 当前样本数量太少,决策树层数超过最大深度或者节点的基尼系数小于某个阈值
节点不再分裂,返回
current_node3 else
3.1 遍历所有候选特征和切分点对 ,计算其基尼系数,找出最佳的分裂特征和切分点
3.2 根据 将数据子集分为两个子集 和
3.3 使用 调用
generate函数创建current_node的左儿子节点3.3 使用 调用
generate函数创建current_node的左儿子节点4 返回当前节点
current_node
def generate(X,y,x_pos,y_pos,nodes,min_leaf_samples,max_depth,layer,class_labels):为了后续使用方便,我们创建一个封装函数 decision_tree_classifier,其输入为训练数据,叶子节点最小样本和树的最大深度。返回树的根,节点集合。
1.4 使用 Networkx 将决策树可视化
`Networkx`[2] 是一个 Python 中流行的网络分析工具,实现了网络的可视化函数。我们将使用该工具的 draw_networkx 函数对生成的决策树进行可视化。draw_networkx 函数需要输入 Networkx 中的网络对象,节点坐标,节点颜色,节点大小等参数,列举如下表所示。
| 参数 | 含义说明 |
|---|---|
G |
Networkx网络对象 |
pos |
指定节点坐标的字典对象,键为节点,值为坐标(x,y) |
ax |
Matplotlib Axes对象,将网络绘制在该子图上 |
node_shape |
节点形状,常见的有圆形("o"),方形("s"),上三角形("^")等 |
font_color |
节点标签字体颜色 |
node_size |
节点大小 |
node_color |
节点颜色 |
编写一个函数,将训练得到的决策树转换成 networkx 中的网络对象 G。
def get_networkx_graph(G, root):在决策树生成函数中,已经计算了节点的坐标。现在我们实现一个函数,输入节点集合,返回其位置布局词典对象。
def get_tree_pos(G):在决策树中,如果是叶子节点,则根据其预测类别显示不同颜色。如果是非叶子节点,则显示灰色。
def get_node_color(G):在鸢尾花数据集上训练决策树,然后将学习到的决策树绘制出来。
import matplotlib.pyplot (-10.1, 14.1, -3.315, 0.31500000000000006)

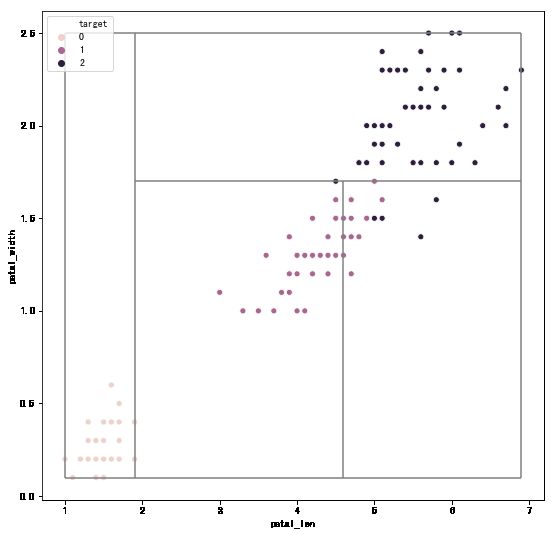
1.5 决策树的决策边界
对于二维数据,我们可以将决策树的决策边界可视化。基本想法是遍历决策树的节点,查看节点的分裂特征和切分点。如果分裂特征对应横轴,则在切分点坐标绘制一条竖线。如果分裂特征对应纵轴,则在切分点绘制一条水平线。下面,我们选取鸢尾花数据集中的petal_len和petal_width 这两个特征,在二维数据集上训练决策树,然后将决策树的决策边界绘制出来。
import seaborn 绘制决策边界。
#开始绘制决策边界 
同样,为了方便,我们将边界绘制代码其封装为一个函数 plot_tree_boundary 。
def plot_tree_boundary(X,y,tree,nodes):plot_tree_boundary(X,y,tree_two_dimension,nodes)
下面我们生成一个边界稍微复杂的"环形"随机数据集,来进一步加深对决策树的决策边界的理解。
from sklearn 
生成一份随机分类数据集,查看决策树边界。
from sklearn 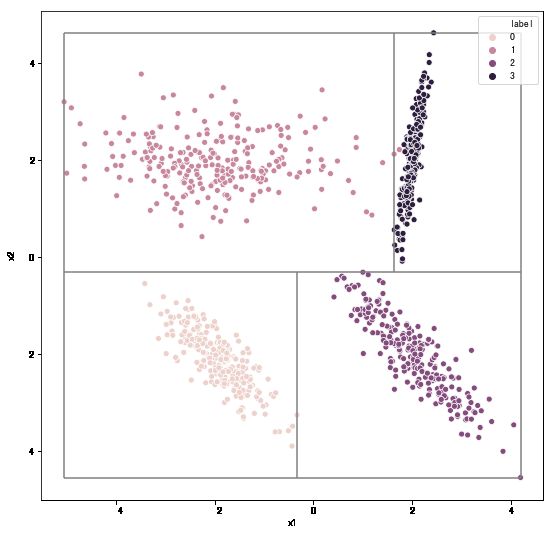
1.6 实现决策树的预测函数
训练得到一个决策树,新到一个样本后,对样本的标签进行预测。我们需要给 TreeNode 类添加一个 predict 方法。如果当前节点是叶子节点,则直接预测最多的类标签。如果当前节点是内部节点,则根据当前样本在节点特征上的取值情况,调用左儿子节点或右儿子节点的 predict 方法。
class TreeNode:再次训练决策树模型。
10,max_depth=选取样本进行测试。
77,:]1 1.0
y_pred = []
for _,sample in iris_df.iterrows():
y_pred.append(tree.predict(sample))
y_pred[:10]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
from sklearn.metrics Text(0.5, 1.0, '混淆矩阵热力图')
2 回归决策树 Python 实现
对于回归问题,不纯度的度量是均方误差。模型的预测是对应叶子节点的均值。
2.1 回归树节点实现
修改树节点类,与分类决策树的节点中存储不同类样本数量不同的是,在回归决策树的节点中,我们需要保存该节点样本的目标值的均值。在预测方法中,如果当前节点是叶子节点,则直接输出均值进行预测。
class TreeNodeRegression:2.2 回归决策树生成
在回归决策树中,不纯度的度量是均方误差。修改决策树生成函数。
def generate_regression(X,y,x_pos,y_pos,nodes,min_leaf_samples,max_depth,layer):同理,创建一个封装的决策树回归函数。
def decision_tree_regression(X,y,min_leaf_samples,max_depth):2.3 在鲍鱼数据集上测试回归效果
我们已经完成了回归决策树的实现,现在使用机器学习第二讲中使用回归模型预测鲍鱼年龄案例中的鲍鱼数据集来进行测试。
"./input/abalone_dataset.csv")def get_node_color2(G):(-18.15, 18.15, -4.42, 0.42000000000000004)

在鲍鱼数据集中,我们构建的回归分类树的效果怎样呢?我们计算模型在训练集中的均方根误差和决定系数 。
#记录预测值均方根误差: 1.6513
决定系数:0.4873
3 实现随机森林算法
随机森林的基本思想是:随机选择特征和有放回随机抽样与原始样本同等大小的样本,然后在抽样的数据子集上训练决策树。算法的基本流程如下:
1 输入:训练集 ,特征维度 ,随机选取的特征数 ,决策树算法 ,树的数量
2 for
2.1 从训练集 中有放回地抽样 个样本,记为子集
2.2 从 个特征中随机选取 个特征
2.3 使用决策树算法,使用 中选择的 个特征训练一棵决策树
3 输出:分类:;回归:
def random_forest(X,y,num_trees=10,num_features = 10,min_leaf_samples=10,max_depth=5):我们将通过鸢尾花数据集对随机森林的表现进行分析,首先将鸢尾花数据集随机划分为训练集和测试集。
from sklearn.model_selection 训练随机森林算法,树的数量设置为 10,每棵树随机选择 3 个特征进行训练,决策树最大深度为 3, 叶子节点最小样本数为 10。
10,num_features = 将随机森林的树绘制出来。
%matplotlib inline
fig, ax = plt.subplots(figsize=(30, 30))
for i in range(len(trees)): # 遍历随机森林中的每棵树
plt.subplot(3,4,i+1)
graph = nx.DiGraph()
get_networkx_graph(graph, trees[i]) #将决策树转换成 networkx 网络对象
pos = get_tree_pos(graph)
nx.draw_networkx(graph,pos = pos,node_shape="o",font_color="w",node_size=5000,node_color=get_node_color(graph)) #绘制决策树
plt.box(False)
plt.axis("off")

对于分类问题,随机森林的预测是其中每棵树的预测的投票,我们实现 rf_predict 方法来实现随机森林预测。
def rf_predict(trees,X_test):这 10 个决策树组成的随机森林算法,效果如何?首先获得随机森林在预测集上的预测结果。
y_test_pred = rf_predict(trees,X_test)
from sklearn.metrics Text(0.5, 1.0, '混淆矩阵热力图')

训练单个决策树,打印效果。
from sklearn.metrics Text(0.5, 1.0, '混淆矩阵热力图')

4 实现 AdaBoost 算法
AdaBoost 的基本思想是通过改变样本的权重来串行地训练多个基模型。每个基分类器在权重分布的样本集下进行训练,根据其在训练样本中的加权误差来确定基分类器模型的权重。然后根据基分类器的权重以及对当前样本的预测情况更新样本的权重。算法流程如下:
1 初始化样本权重
2 for
2.1 根据当前样本权重,训练基分类器
2.2 计算 的加权误差
2.3 计算 的权重
2.4 更新样本权重
3 返回集成模型
为了简单,我们这里只实现二分类,且假设标签取值为 1 或 -1 。如果使用的基分类器为决策树,需要将决策树算法进行修改,以使得支持设置样本权重。而在决策树中,权重主要影响的是基尼系数的计算。实现函数ith_gini_wweight,它用对应分类的样本权重和的比例来代替传统基尼系数中样本数量的比例。
import numpy 然后,修改 generate 函数。
def generate_with_weights(X,y,x_pos,y_pos,nodes,min_leaf_samples,max_depth,layer,class_labels,sample_weights):对决策树进行修改以支持样本权重后,现在我们开始实现 AdaBoost 算法。
def adaboost(X,y,num_trees=10,min_leaf_samples=10,max_depth=5):我们使用随机数据集,训练由多棵决策树桩组成的 AdaBoost 模型,然后将多个决策树桩的决策边界绘制出来。
from sklearn 
10,min_leaf_samples=9, 
现在,我们实现 AdaBoost 的预测函数 adaboost_predict。
def adaboost_predict(trees,weights,X_test):5 基于树模型的个人信用风险评估
在个人信用真实问题上测试我们实现的算法。
"./input/credit-data.csv")Index(['serious_dlqin2yrs', 'revolving_utilization_of_unsecured_lines', 'age', 'number_of_time30-59_days_past_due_not_worse', 'debt_ratio', 'monthly_income', 'number_of_open_credit_lines_and_loans', 'number_of_times90_days_late', 'number_real_estate_loans_or_lines', 'number_of_time60-89_days_past_due_not_worse', 'number_of_dependents'], dtype='object')
"sd"].value_counts()-1 104905
1 7510
Name: sd, dtype: int64
可见正负样本严重不均衡,我们从正负类样本中随机抽取部分样本。
"sd"] == 
from sklearn.model_selection 5.1 训练决策树、随机森林和 AdaBoost 模型
#训练决策树将生成的决策树可视化。
%matplotlib inline
fig, ax = plt.subplots(figsize=(10, 10))
graph = nx.DiGraph()
get_networkx_graph(graph, credit_tree)
pos = get_tree_pos(graph)
nx.draw_networkx(graph,pos = pos,ax = ax,node_shape="o",font_color="w",node_size=5000,node_color=get_node_color(graph),font_size=10)
plt.box(False)
plt.axis("off")
(-267.68, 235.68, -3.315, 0.31500000000000006)

#训练随机森林#训练AdaBoost5.2 三种模型效果的评估
使用正确率作为评价指标,查看训练的模型在测试集上的效果。
credit_tree_pred = []
for _,sample in X_credit_test.iterrows():
credit_tree_pred.append(credit_tree.predict(sample))
credit_rf_pred = rf_predict(credit_rf_trees,X_credit_test)
credit_ada_pred = adaboost_predict(credit_ada_trees,credit_ada_weights,X_credit_test)
from sklearn.metrics import accuracy_score
print(round(accuracy_score(y_credit_test,credit_tree_pred),2))
print(round(accuracy_score(y_credit_test,credit_rf_pred),2))
print(round(accuracy_score(y_credit_test,credit_ada_pred),2))
0.75
0.77
0.73
6 总结
在本案例中,我们使用 Python 分别实现了分类决策树、回归决策树、随机森林和 AdaBoost 算法。在实践中,我们分别使用了 Matplotlib,Seaborn 和 Networkx 等 Python 工具实现数据的可视化和决策树的可视化。数据的预处理使用的主要是 Pandas 包。本案例的目的是通过动手实践,加深对决策树、随机森林和 AdaBoost 算法的理解。案例中的代码实现并不是性能最优的,仅供参考。
参考资料
[1]UCI鸢尾花: http://archive.ics.uci.edu/ml/datasets/Iris
[2]Networkx: http://networkx.github.io/
机器学习十讲往期直播案例
直播案例 |使用PageRank对全球机场进行排序
直播案例 |使用KNN对新闻主题进行自动分类
直播案例 |使用回归模型预测鲍鱼年龄
直播案例 |使用感知机、逻辑回归、支持向量机进行中文新闻主题分类
机器学习十讲直播课件

/机器会学习吗?
05/14---机器学习介绍

/回归初心,方得始终
05/21---回归

/分门别类,各得其所
05/28---分类