从零开始手把手搭建Vision Transformers(tensorflow版本)
导言
Vision Transformers (ViT)在2020年Dosovitskiy et. al.提出后,在计算机视觉领域逐渐占领主导位置,在图像分类以及目标检测、语义分割等下游任务中获得了很好的性能,掀起transformer系列在CV领域的浪潮。这里将介绍如何从头开始基于tensorflow 框架一步步实现ViT模型。
前言
上一篇我们写了基于pytorch版本实现ViT模型,感兴趣点击这里,应大家要求,今天将实战如何从头开始实现我的第一个 ViT(使用 tensorflow版本),如果你还没有熟悉自然语言处理(NLP)中使用的Transformer模型,可能会对transformer在CV领域的应用有点懵圈,对ViT模型在图像上的使用不明所以,别担心,从这里开始!
定义任务
因为上一篇已经对ViT模型有一些讲解,这里就直接搭建框架模型,同时上一篇使用的是MNIST 数据集,这里丰富点,使用cifar100数据集,虽然目标简单,但是我们可以基于该图像分类任务理清ViT模型的整个脉络。
首先这里配置的环境是:
python==3.7
tensorflow==2.7.0
tensorflow_addons==0.16.1
首先对需要使用的一些模块导入:
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tensorflow_addons as tfa # Community-made Tensorflow code (AdamW optimizer)
导入tensorflow_addons模块是为了使用AdamW优化器【1】,当然这里可以使用Adam等其他优化器。
下面我们来创建main函数,因为tensorflow2以后内置keras框架,这里先直接通过keras.datasets模块加载数据集并分割成train和test数据集,用于预处理cifar100数据集,定义学习率、batch_size、epochs等超参;
通过model.compile 定义AdamW优化器,定义loss,评价指标metrics;通过keras.callbacks.ModelCheckpoint 保存训练过程中的权重文件,通过model.fit 执行训练过程,训练100 epochs,然后,在测试集上计算准确率。
def main():
# Downloading dataset
num_classes = 100
input_shape = (32, 32, 3)
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar100.load_data()
print(f"x_train shape: {x_train.shape} - y_train shape: {y_train.shape}")
print(f"x_test shape: {x_test.shape} - y_test shape: {y_test.shape}")
# Hyper-parameters
learning_rate = 0.001
weight_decay = 0.0001
batch_size = 256
num_epochs = 100
def create_vit_classifier():
#TODO
pass
def run_experiment(model):
#define optimizer
optimizer = tfa.optimizers.AdamW(
learning_rate=learning_rate, weight_decay=weight_decay
)
# define optimizer, loss and metrics
model.compile(
optimizer=optimizer,
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[
keras.metrics.SparseCategoricalAccuracy(name='accuracy'),
keras.metrics.SparseTopKCategoricalAccuracy(5, name='top-5 accuracy'),
],
)
# saved model path
checkpoint_filepath = './tmp/checkpoint'
# save model when training,and only save the best model by monitor val_accuracy.
checkpoint_callback = keras.callbacks.ModelCheckpoint(
checkpoint_filepath,
monitor="val_accuracy",
save_best_only=True,
save_weights_only=True
)
# train process
history = model.fit(
x=x_train,
y=y_train,
batch_size=batch_size,
epochs=num_epochs,
validation_split=0.1,
callbacks=[checkpoint_callback]
)
# test process
model.load_weights(checkpoint_filepath)
_, accuracy, top5_accuracy = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {accuracy}")
print(f"Test Top-5 Accuracy: {top5_accuracy}")
return history
model = create_vit_classifier()
run_experiment(model)
搭建好整个训练测试框架后,我们现在来主攻create_vit_classifier 函数的搭建,即ViT模型的搭建,模型的任务是对cifar100的图像进行分类。
ViT架构
因tensorflow以及大多数 DL 框架都提供autograd计算,我们只需要将ViT网络中的网络层继承keras的layers类,并定义好在训练框架中的优化器,tensorflow框架将负责反向传播梯度并训练模型的参数,这样我们只需要关心实现 ViT 模型的前向传递过程。上一篇已经对ViT模型有所介绍,这里就粘贴主要的网络图。
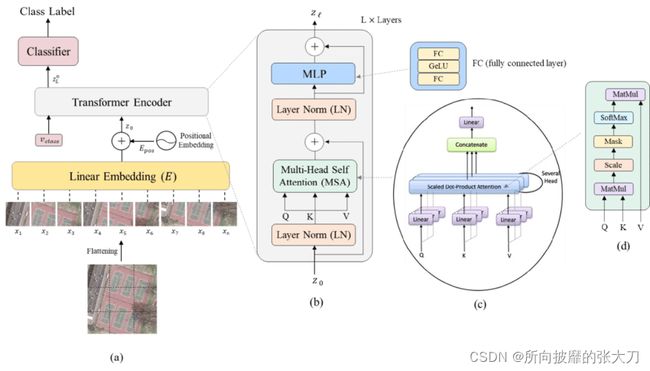
数据增强
在CIfar100数据集上,我们使用keras的layers模块,做数据增强:
image_size = 72
# Data augmentation
data_augmentation = keras.Sequential(
[
layers.experimental.preprocessing.Normalization(),
layers.experimental.preprocessing.Resizing(image_size, image_size),
layers.experimental.preprocessing.RandomFlip("horizontal"),
layers.experimental.preprocessing.RandomRotation(factor=0.02),
layers.experimental.preprocessing.RandomZoom(height_factor=0.2, width_factor=0.2)
],
name='data_augmentation'
)
# Normalizing based on training data
data_augmentation.layers[0].adapt(x_train)
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
Patchifying
ViT中首先将一张图像分解成多个子图像,将每个子图像映射成一个向量。将图像resize到72x72大小后,将每个的图像分成12x12块,每块大小是6x6(如果不能完全整除分块,需要对图像padding填充),这样我们能从单个图像中获得144个子图像。将原图重塑成:
(N, PxP, H/P x W/P x C) = (N, 12x12, 6x6) = (N, 144, 108)
请注意,虽然每个子图大小为 3x6x6 ,但我们将其展平为 108 维向量。
我们对代码实现上述功能:
class Patches(layers.Layer):
"""Gets some images and returns the patches for each image"""
def __init__(self, patch_size):
super(Patches, self).__init__()
self.patch_size = patch_size
def call(self, images):
batch_size = tf.shape(images)[0]
patches = tf.image.extract_patches(
images=images,
sizes=[1, self.patch_size, self.patch_size, 1],
strides=[1, self.patch_size, self.patch_size, 1],
rates=[1, 1, 1, 1],
padding="VALID",
)
patch_dims = patches.shape[-1]
patches = tf.reshape(patches, [batch_size, -1, patch_dims])
return patches
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
patches = Patches(patch_size)(augmented)
线性映射并添加位置编码
得到展平后的patches即向量后,通过layers.Dense来改变维度,线性映射可以映射到任意向量大小,我们这里设置为64,当然你可以设置成任意维度。模型维度变成 (N, 36, 64),通过layers.Embedding 添加可学习的位置编码。注:这里有稍许的变更,没有添加分类标记,对应MLP最后的输出也有所改变。主要原因是为了训练快点。。如果大家想加的话,可以在PatchEncoder类中的call函数里添加。
projection_dim = 64
class PatchEncoder(layers.Layer):
"""Adding (learnable) positional encoding to input patches"""
def __init__(self, num_patches, projection_dim):
super(PatchEncoder, self).__init__()
self.num_patches = num_patches
self.projection = layers.Dense(units=projection_dim)
self.position_embedding = layers.Embedding(
input_dim=num_patches, output_dim=projection_dim
)
def call(self, patch):
positions = tf.range(start=0, limit=self.num_patches, delta=1)
encoded = self.projection(patch) + self.position_embedding(positions)
return encoded
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
patches = Patches(patch_size)(augmented)
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
添加LN, transformer
在得到encoding结果后,先对token做归一化,然后应用多头注意力机制,最后添加一个残差连接(连接LN 之前的输入和多头注意力之后的输出)。
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
patches = Patches(patch_size)(augmented)
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
for _ in range(transformer_layers):
# Layer normalization and self-attention
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Residual conenction
x2 = layers.Add()([attention_output, encoded_patches])
LN,MLP 和残差连接
继续下面网络,将当前张量再通过另一个 LN 和 MLP 后,通过残差连接,搭积木这样搭起来,这里相对于pytorch版本使用gelu激活函数,并使用多层transformer。
def mlp(x, hidden_units, dropout_rate):
"""MLP with dropout and skip-connections"""
for units in hidden_units:
x = layers.Dense(units, activation=tf.nn.gelu)(x)
x = layers.Dropout(dropout_rate)(x)
return x
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
patches = Patches(patch_size)(augmented)
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
for _ in range(transformer_layers):
# Layer normalization and self-attention
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Residual conenction
x2 = layers.Add()([attention_output, encoded_patches])
# Normalization and MLP
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Residual connection
encoded_patches = layers.Add()([x3, x2])
LN, MLP, Dense分类
对输出结果先LN归一化后,再对其展平,为防止过拟合,增加dropout后,加入MLP,因为pytorch使用的是分类标记,MLP输出后,取首位值即为分类结果,这里改进后,后面通过Dense输出。
def create_vit_classifier():
# Creating classifier
inputs = layers.Input(shape=input_shape)
augmented = data_augmentation(inputs)
patches = Patches(patch_size)(augmented)
encoded_patches = PatchEncoder(num_patches, projection_dim)(patches)
for _ in range(transformer_layers):
# Layer normalization and self-attention
x1 = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
attention_output = layers.MultiHeadAttention(
num_heads, key_dim=projection_dim, dropout=0.1
)(x1, x1)
# Residual conenction
x2 = layers.Add()([attention_output, encoded_patches])
# Normalization and MLP
x3 = layers.LayerNormalization(epsilon=1e-6)(x2)
x3 = mlp(x3, hidden_units=transformer_units, dropout_rate=0.1)
# Residual connection
encoded_patches = layers.Add()([x3, x2])
# Create a [batch_size, projection_dim] tensor
representation = layers.LayerNormalization(epsilon=1e-6)(encoded_patches)
representation = layers.Flatten()(representation)
representation = layers.Dropout(0.5)(representation)
# Add MLP
features = mlp(representation, hidden_units=mlp_head_units, dropout_rate=0.5)
# Classify output
logits = layers.Dense(num_classes)(features)
# create whole net
model = keras.Model(inputs=inputs, outputs=logits)
return model
我们模型的输出现在是一个 (N, 100) 张量。ok,大功告成!
现在来试试我们的模型表现如何,cpu下运行:
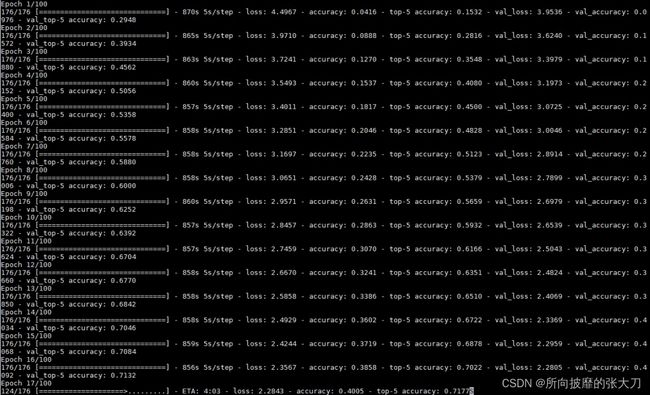
嗯,趋势都正确。就是有点慢。完结撒花。

结语
tensorflow版本相对于上一版pytorch版本使用 GeLU 激活函数、将多个 Transformer 编码器块堆叠在一起。后续ViT也有各个版本的改进,大家可以基于此去添加,关注公众号后台回复"vit_tf"获完整代码。
论文:https://arxiv.org/abs/2010.11929
参考:
[1]https://blog.csdn.net/u012744245/article/details/112671504?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_utm_term~default-9.pc_relevant_aa&spm=1001.2101.3001.4242.6&utm_relevant_index=12
[2] https://zhuanlan.zhihu.com/p/340149804