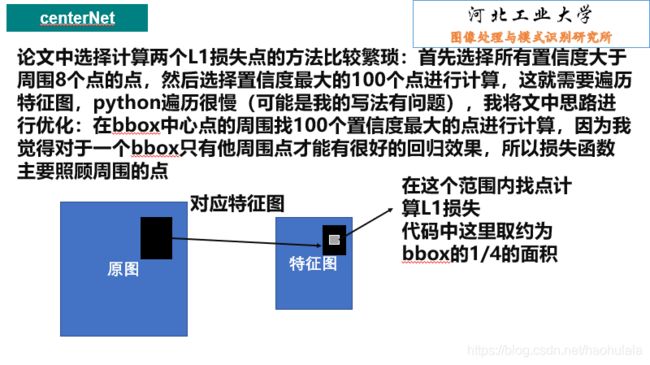
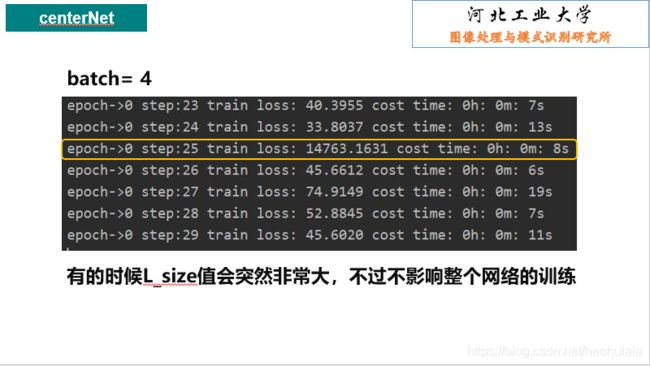
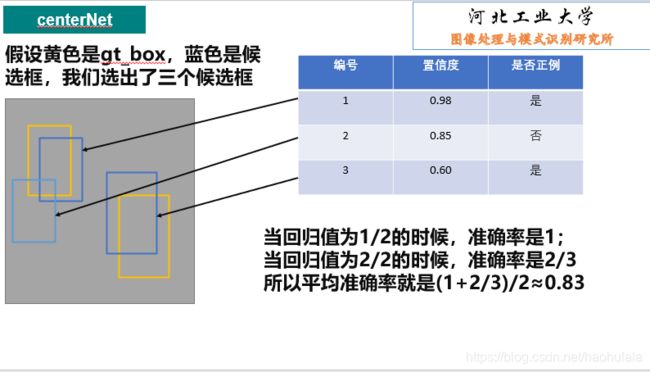
centerNet pytorch复现
论文题目:Objects as Points
论文地址:https://arxiv.org/pdf/1904.07850.pdf
官方代码:https://github.com/xingyizhou/CenterNet
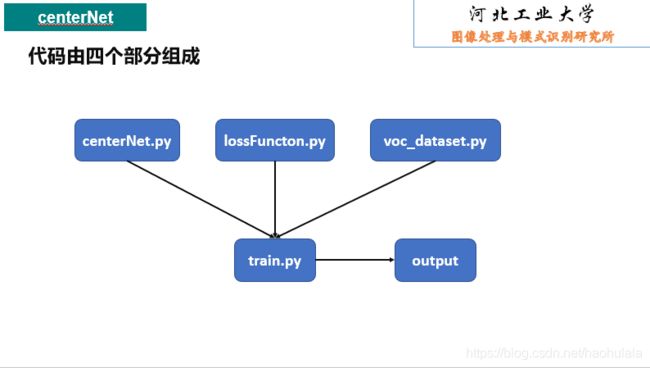
下面是我写的代码
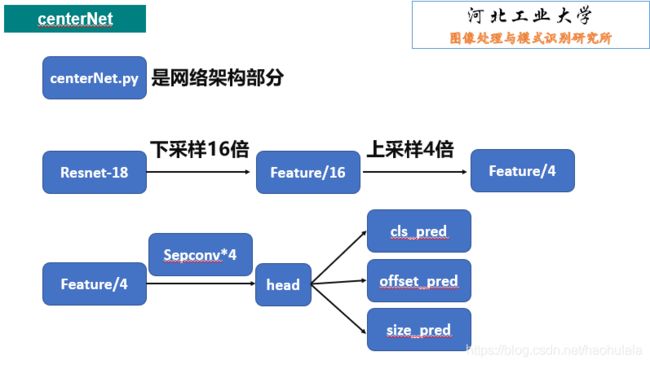
centerNet.py
import torch
from torch import nn
import torch.nn.functional as f
import torchvision.models as models
import numpy as np
"""
这个文件是centerNet的网络结构
"""
# 预训练模型的路径
BACKBONE = "G:/工作空间/预训练模型/resnet18-5c106cde.pth"
class SepConv(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, padding=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channel, in_channel,kernel_size,stride,padding, groups=in_channel)
self.conv2 = nn.Conv2d(in_channel, out_channel, kernel_size=1,stride=1,padding=0)
def forward(self, input):
x = self.conv1(input)
x = self.conv2(x)
return x
class CenterNet(nn.Module):
# backbone是预训练模型的路径
# class_num是分类数量,voc数据集中分类数量是20
# feature是上采样之后卷积层的通道数
def __init__(self, backbone=None, class_num=20):
super(CenterNet, self).__init__()
if(backbone==None):
self.Backbone = BACKBONE
else:
self.Backbone = backbone
self.backbone = models.resnet18(pretrained=False)
self.backbone.load_state_dict(torch.load(self.Backbone))
self.softmax = nn.Softmax(dim=1)
# [1,3,500,500] -> [1,256,32,32]
self.stage1 = nn.Sequential(*list(self.backbone.children())[:-3])
"""
# [1,64,125,125] -> [1,128,63,63]
self.stage2 = nn.Sequential(list(backbone.children())[-5])
# [1,128,63,63] -> [1,256,32,32]
self.stage3 = nn.Sequential(list(backbone.children())[-4])
"""
# 改变通道数
self.conv1 = nn.Conv2d(256, 128, kernel_size=1)
self.conv2 = nn.Conv2d(128, 64, kernel_size=1)
batchNorm_momentum = 0.1
self.block = nn.Sequential(
SepConv(64, 64, kernel_size=3, padding=1, stride=1),
nn.BatchNorm2d(64, momentum= batchNorm_momentum),
nn.ReLU(),
)
# head的内容
self.head = nn.Sequential(
self.block,
self.block,
self.block,
self.block
)
# 分类预测
self.head_cls = nn.Conv2d(64, class_num, kernel_size=3, padding=1, stride=1)
# 偏移量修正预测
self.head_offset = nn.Conv2d(64, 2, kernel_size=3, padding=1, stride=1)
# 回归框大小预测
self.head_size = nn.Conv2d(64, 2, kernel_size=3, padding=1, stride=1)
# 上采样,mode参数默认的是"nearest",使用mode="bilinear"的时候会有warning
def upsampling(self, src, width, height, mode="nearest"):
# target的形状举例 torch.Size([1, 256, 50, 64])
return f.interpolate(src, size=[width, height], mode=mode)
def forward(self, input):
output = self.stage1(input)
# 将通道数由256变为128
output = self.conv1(output)
width = input.shape[2] // 8
height = input.shape[3] // 8
output = self.upsampling(output, width, height)
# 将通道数由128变为64
output = self.conv2(output)
width = input.shape[2] // 4
height = input.shape[3] // 4
output = self.upsampling(output, width, height)
output = self.head(output)
# 分类预测
classes = self.head_cls(output)
# 偏移量预测
offset = self.head_offset(output)
# 回归框大小预测
size = self.head_size(output)
# 由于分类值输出在[0,1]之间,所以需要使用sigmoid函数
# classes = nn.Sigmoid()(classes)
# 使用softmax函数
classes = self.softmax(classes)
# 回归值为正
size = torch.exp(size)
return classes, offset, size
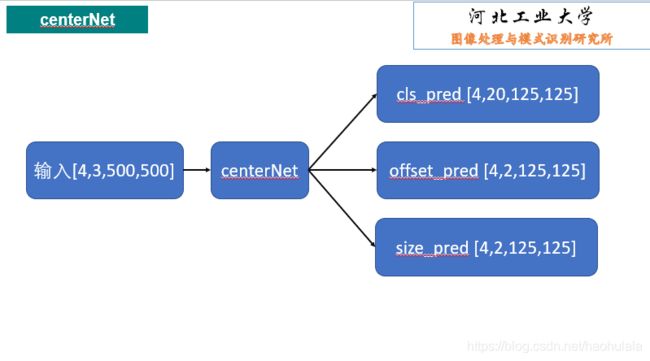
if __name__ == "__main__":
network = CenterNet()
img = torch.rand(1,3,500,500)
output = network(img)
print(output[0])
print(output[1])
print(output[2])lossFunction.py
import torch
import torch.nn as nn
import exp.voc_dataset as dataload
import exp.centerNet as network
import time
import numpy as np
"""
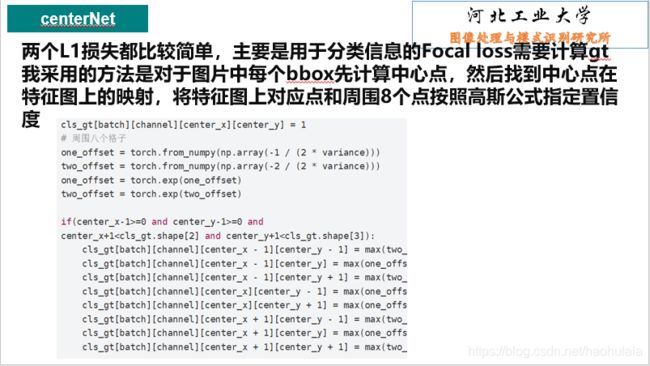
这个脚本是centerNet的三个损失函数
分类损失 Focal loss
校正损失 L1 loss
回归损失 L1 loss
"""
class CenterNetLoss(nn.Module):
# pred是网络输出结果,包含三个部分(分类信息,校正值和回归值)
# target是数据集给定的结果,包含两个部分(bbox和分类信息)
# candidate_num是候选点的个数,文中是100
def __init__(self, pred=None, target=None, candidate_num=100):
super(CenterNetLoss, self).__init__()
# 先获取三个输入
if(pred==None and target==None):
self.cls_pred = None
self.offset_pred = None
self.size_pred = None
self.gt_box = None
self.gt_class = None
else:
# [batch, class_num, h, w]
self.cls_pred = pred[0]
# [batch, 2, h, w]
self.offset_pred = pred[1]
# [batch, 2, h, w]
self.size_pred = pred[2]
# 获取两个gt值
# [batch, num, 4]
self.gt_box = target[0]
# [batch, num]
self.gt_class = target[1]
# 选出置信度最大的多少个点
self.candidate = candidate_num
self.batch_size = 0
self.mask = None
# 计算分类得分的gt,就是对应论文中使用高斯公式那部分
# 我们假定方差都variance都是1
# 返回cls_gt -> [batch, class_num, h, w]
def get_cls_gt(self, variance=1.0):
# [batch, class_num, h, w]
cls_gt = torch.zeros_like(self.cls_pred)
#print(cls_gt.shape)
keypoints = []
# 根据gt_box和分类标签计算keypoint
for batch in range(self.batch_size):
for num in range(self.gt_class.shape[1]):
if(self.gt_class[batch][num] != -1):
# 计算gt_box的中心点坐标
center_x = (self.gt_box[batch][num][2]-self.gt_box[batch][num][0]) // 2
center_y = (self.gt_box[batch][num][3]-self.gt_box[batch][num][1]) // 2
# 进行四倍下采样
center_x = center_x // 4
center_y = center_y // 4
tmp = [batch,self.gt_class[batch][num],center_x,center_y]
# print(tmp)
keypoints.append(tmp)
# 根据keypoints计算分类的gt
for num in range(len(keypoints)):
batch = keypoints[num][0]
channel = keypoints[num][1]
center_x = keypoints[num][2]
center_y = keypoints[num][3]
#print("(%d, %d)"%(center_x, center_y))
cls_gt[batch][channel][center_x][center_y] = 1
# 周围八个格子
one_offset = torch.from_numpy(np.array(-1 / (2 * variance)))
two_offset = torch.from_numpy(np.array(-2 / (2 * variance)))
one_offset = torch.exp(one_offset)
two_offset = torch.exp(two_offset)
if(center_x-1>=0 and center_y-1>=0 and
center_x+1"+str(ed1-st1))
return loss
# 选择候选点,选择当前与bbox距离最近的100个候选框
def getTarget(self):
target = torch.zeros(self.offset_pred.shape[0], self.offset_pred.shape[2], self.offset_pred.shape[3], dtype=torch.int32)
target_size = torch.zeros(self.offset_pred.shape[0], self.offset_pred.shape[2], self.offset_pred.shape[3],2)
target_offset = torch.zeros(self.offset_pred.shape[0], self.offset_pred.shape[2], self.offset_pred.shape[3], 2)
for batch in range(self.batch_size):
# 先计算出gt_box的keypoint
keypoints = []
for idx in range(len(self.gt_class[batch])):
if(self.gt_class[batch][idx]==-1):
continue
center_x = (self.gt_box[batch][idx][2]-self.gt_box[batch][idx][0])//2
center_y = (self.gt_box[batch][idx][3]-self.gt_box[batch][idx][1])//2
width = (self.gt_box[batch][idx][2]-self.gt_box[batch][idx][0])//4
height = (self.gt_box[batch][idx][3]-self.gt_box[batch][idx][1])//4
#print(center_x)
#print(center_y)
keypoints.append([self.gt_class[batch][idx], center_x//4, center_y//4, width, height, idx])
for idx in range(len(keypoints)):
channel = keypoints[idx][0]
center_x = keypoints[idx][1]
center_y = keypoints[idx][2]
width = keypoints[idx][3]
height = keypoints[idx][4]
idx_point = keypoints[idx][5]
# 选择候选框里面置信度最大的100个点进行回归
min_ = 9999999
# 指向最小值点的坐标
min_idx = -1
coords = []
num_pos = 0
radiu = 2
left = max((center_x-width//2)//radiu, 0)
right = min((center_x+width//2)//radiu, self.cls_pred.shape[2]//radiu)
top = max((center_y-height//2)//radiu,0)
bottom = min((center_y+height//2)//radiu, self.cls_pred.shape[3]//radiu)
for i in range(left, right):
for j in range(top, bottom):
# print(str(i)+" "+str(j))
if(num_pos%.4f s" % (ed - st))
cls_loss = self.FocalLoss1()
ed = time.time()
#print("focal loss->%.4f s" % (ed - st))
# print("offset loss: %.4f size loss: %.4f cls loss:%.4f"%(offset_loss, size_loss, cls_loss))
loss = nameda_cls*cls_loss + nameda_size*size_loss + nameda_offset*offset_loss
# loss = loss/self.batch_size
end = time.time()
cost = end - st
#print("cost time:%.4f s"%(cost))
return loss
if __name__ == "__main__":
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
dataset = dataload.VOCDetection(readInfo=False, mode="train")
batch = 4
train_loader = torch.utils.data.DataLoader(dataset, batch_size=batch, shuffle=True,
collate_fn=dataset.collate_fn,pin_memory=True, num_workers=8)
image = None
gt_box = None
gt_class = None
for data in train_loader:
image = data[0].to(device)
gt_box = data[1]
gt_class = data[2]
target = [gt_box, gt_class]
centerNet = network.CenterNet().to(device)
cls_pred, offset_pred, size_pred = centerNet(image)
print("image->" + str(image.shape))
print("box->" + str(gt_box.shape))
print("class->" + str(gt_class.shape))
pred = [cls_pred, offset_pred, size_pred]
loss = CenterNetLoss()
st = time.time()
print(loss(pred, target))
ed = time.time()
print("cost time:%.4f s" % (ed - st)) voc_dataset.py
https://blog.csdn.net/haohulala/article/details/109316804
train.py
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
import numpy as np
import exp.lossFunction as loss
import exp.voc_dataset as dataload
import exp.centerNet as network
import argparse
import time
import matplotlib.pyplot as plt
import os
"""
超参数设定
"""
EPOCHES = 30
BATCH_SIZE = 4
LR = 0.01
##########
# 路径设置
##########
# 交换了测试集和训练集,嘻嘻
class Boot(nn.Module):
# load_model是加载预训练模型的路径
# offset是当前训练轮次偏移,为0表示从头开始训练
def __init__(self, load_model=None, offset=0):
super(Boot, self).__init__()
self.offset = offset
self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu()")
self.network = network.CenterNet().to(self.device)
if (load_model != None):
self.network.load_state_dict(torch.load(load_model))
print("加载模型"+str(load_model)+"成功")
self.lossFunction = loss.CenterNetLoss()
self.dataset_train = dataload.VOCDetection(readInfo=False, mode="train")
self.dataset_val = dataload.VOCDetection(readInfo=False, mode="val")
##########################################
# 注意这里交换了测试集和训练集,让训练快一点 #
# 改过来了 #
##########################################
self.train_data = torch.utils.data.DataLoader(self.dataset_train, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=self.dataset_train.collate_fn)
self.val_data = torch.utils.data.DataLoader(self.dataset_val, batch_size=BATCH_SIZE, shuffle=True,
collate_fn=self.dataset_val.collate_fn)
self.optimizer = torch.optim.Adam(self.network.parameters(), lr=LR, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
self.train_loss = []
self.val_loss = []
def train(self):
print("开始训练✿✿ヽ(°▽°)ノ✿")
for epoch in range(EPOCHES):
st_total = time.time()
total_loss = 0
num_data = 0
for step, data in enumerate(self.train_data):
"""
if(step%50 != 0):
continue
"""
st_step = time.time()
batch_img = data[0].to(self.device)
batch_bbox = data[1].to(self.device)
batch_class = data[2].to(self.device)
num_data += 1
pred = self.network(batch_img)
#print("interface->%.4f s" % (time.time() - st_step))
loss = self.lossFunction(pred, [batch_bbox, batch_class])
#print("loss->%.4f s" % (time.time() - st_step))
total_loss += loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
#print("update->%.4f s" % (time.time() - st_step))
cost = time.time()-st_step
print("epoch->%d step:%d train loss: %.4f cost time: %dh: %dm: %ds"%(epoch+self.offset, step, loss,cost/3600,cost%3600/60, cost%60))
self.train_loss.append(total_loss/num_data)
cost =time.time()-st_total
print("epoch->%d train loss: %.4f cost time: %dh: %dm: %ds"%(epoch+self.offset, total_loss/num_data,cost/3600,cost%3600/60, cost%60))
save_path = "./centerNet_"+str(epoch+self.offset)+".pth"
torch.save(self.network.state_dict(), save_path)
x = np.arange(EPOCHES)
plt.plot(x, self.train_loss)
plt.title("train loss")
plt.grid()
plt.savefig("./trian_loss.jpg")
# 跑一轮测试集
val_loss = 0
num_data = 0
for step, data in enumerate(self.val_data):
st = time.time()
batch_img = data[0].to(self.device)
batch_bbox = data[1].to(self.device)
batch_class = data[2].to(self.device)
num_data += 1
pred = self.network(batch_img)
loss = self.lossFunction(pred, [batch_bbox, batch_class])
val_loss += loss
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
ed = time.time()
print("step:%d val loss: %.4f cost time: %.4f s" % (step, total_loss / (step + 1), (ed - st)))
ed = time.time()
print("val loss: %.4f cost time: %.4f s" % (total_loss / num_data, (ed - st)))
if __name__ == "__main__":
offset = 0
model = None
boot = Boot(load_model=model, offset=offset)
boot.train()运行train.py就能开始训练