memcache命令
memcached 是由 Danga Interactive 开发并使用 BSD 许可的一种通用的分布式内存缓存系统。
Danga Interactive 开发 memcached 的目的是创建一个内存缓存系统来处理其网站 LiveJournal.com 的巨大流量。每天超过 2000 万的页面访问量给 LiveJournal 的数据库施加了巨大的压力,因此 Danga 的 Brad Fitzpatrick 便着手设计了 memcached。memcached 不仅减少了网站数据库的负载,还成为如今世界上大多数高流量网站所使用的缓存解决方案。
本文首先全面概述 memcached,然后指导您安装 memcached 以及在开发环境中构建它。我还将介绍 memcached 客户机命令(总共有 9 个)并展示如何在标准和高级 memcached 操作中使用它们。最后,我将提供一些使用 memcached 命令测量缓存的性能和效率的技巧。
在开始安装和使用 using memcached 之前,我们需要了解如何将 memcached 融入到您的环境中。虽然在任何地方都可以使用 memcached,但我发现需要在数据库层中执行几个经常性查询时,memcached 往往能发挥最大的效用。我经常会在数据库和应用服务器之间设置一系列 memcached 实例,并采用一种简单的模式来读取和写入这些服务器。图 1 可以帮助您了解如何设置应用程序体系结构:
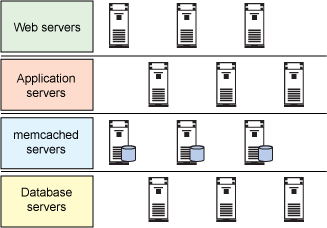
体系结构相当容易理解。我建立了一个 Web 层,其中包括一些 Apache 实例。下一层是应用程序本身。这一层通常运行于 Apache Tomcat 或其他开源应用服务器之上。再下面一层是配置 memcached 实例的地方 — 即应用服务器与数据库服务器之间。在使用这种配置时,需要采用稍微不同的方式来执行数据库的读取和写入操作。
我执行读取操作的顺序是从 Web 层获取请求(需要执行一次数据库查询)并检查之前在缓存中存储的查询结果。如果我找到所需的值,则返回它。如果未找到,则执行查询并将结果存储在缓存中,然后再将结果返回给 Web 层。
将数据写入到数据库中时,首先需要执行数据库写入操作,然后将之前缓存的任何受此写入操作影响的结果设定为无效。此过程有助于防止缓存和数据库之间出现数据不一致性。
memcached 支持一些操作系统,包括 Linux®、Windows®、Mac OS 和 Solaris。在本文中,我将详细介绍如何通过源文件构建和安装 memcached。采用这种方式的主要原因是我在遇到问题时可以查看源代码。
libevent 是安装 memcached 的唯一前提条件。它是 memcached 所依赖的异步事件通知库。您可以在 monkey.org 上找到关于 libevent 的源文件。接下来,找到其最新版本的源文件。对于本文,我们使用稳定的 1.4.11 版本。获取了归档文件之后,将它解压到一个方便的位置,然后执行清单 1 中的命令:
|
从 Danga Interactive 获取 memcached 源文件,仍然选择最新的分发版。在撰写本文时,其最新版本是 1.4.0。将 tar.gz 解压到方便的位置,并执行清单 2 中的命令:
|
完成这些步骤之后,您应该安装了一个 memcached 工作副本,并且可以使用它了。让我们进行简单介绍,然后使用它。
要开始使用 memcached,您首先需要启动 memcached 服务器,然后使用 telnet 客户机连接到它。
要启动 memcached,执行清单 3 中的命令:
|
这会以守护程序的形式启动 memcached(-d ),为其分配 2GB 内存(-m 2048 ),并指定监听 localhost,即端口 11211。您可以根据需要修改这些值,但以上设置足以完成本文中的练习。接下来,您需要连接到 memcached。您将使用一个简单的 telnet 客户机连接到 memcached 服务器。
大多数操作系统都提供了内置的 telnet 客户机,但如果您使用的是基于 Windows 的操作系统,则需要下载第三方客户机。我推荐使用 PuTTy 。
安装了 telnet 客户机之后,执行清单 4 中的命令:
|
如果一切正常,则应该得到一个 telnet 响应,它会指示 Connected to localhost(已经连接到 localhost) 。如果未获得此响应,则应该返回之前的步骤并确保 libevent 和 memcached 的源文件都已成功生成。
您现现已经登录到 memcached 服务器。此后,您将能够通过一系列简单的命令来与 memcached 通信。9 个 memcached 客户端命令可以分为三类:
- 基本
- 高级
- 管理
您将使用五种基本 memcached 命令执行最简单的操作。这些命令和操作包括:
-
set -
add -
replace -
get -
delete
前三个命令是用于操作存储在 memcached 中的键值对的标准修改命令。它们都非常简单易用,且都使用清单 5 所示的语法:
|
表 1 定义了 memcached 修改命令的参数和用法。
| 参数 | 用法 |
|---|---|
| key | key 用于查找缓存值 |
| flags | 可以包括键值对的整型参数,客户机使用它存储关于键值对的额外信息 |
| expiration time | 在缓存中保存键值对的时间长度(以秒为单位,0 表示永远) |
| bytes | 在缓存中存储的字节点 |
| value | 存储的值(始终位于第二行) |
现在,我们来看看这些命令的实际使用。
set
set 命令用于向缓存添加新的键值对。如果键已经存在,则之前的值将被替换。
注意以下交互,它使用了 set 命令:
set userId 0 0 5 |
如果使用 set 命令正确设定了键值对,服务器将使用单词 STORED 进行响应。本示例向缓存中添加了一个键值对,其键为 userId ,其值为 12345 。并将过期时间设置为 0,这将向 memcached 通知您希望将此值存储在缓存中直到删除它为止。
add
仅当缓存中不存在键时,add 命令才会向缓存中添加一个键值对。如果缓存中已经存在键,则之前的值将仍然保持相同,并且您将获得响应 NOT_STORED 。
下面是使用 add 命令的标准交互:
set userId 0 0 5 |
replace
仅当键已经存在时,replace 命令才会替换缓存中的键。如果缓存中不存在键,那么您将从 memcached 服务器接受到一条 NOT_STORED 响应。
下面是使用 replace 命令的标准交互:
replace accountId 0 0 5 |
最后两个基本命令是 get 和 delete 。这些命令相当容易理解,并且使用了类似的语法,如下所示:
command <key> |
接下来看这些命令的应用。
get
get 命令用于检索与之前添加的键值对相关的值。您将使用 get 执行大多数检索操作。
下面是使用 get 命令的典型交互:
set userId 0 0 5 |
如您所见,get 命令相当简单。您使用一个键来调用 get ,如果这个键存在于缓存中,则返回相应的值。如果不存在,则不返回任何内容。
delete
最后一个基本命令是 delete 。delete 命令用于删除 memcached 中的任何现有值。您将使用一个键调用 delete ,如果该键存在于缓存中,则删除该值。如果不存在,则返回一条 NOT_FOUND 消息。
下面是使用 delete 命令的客户机服务器交互:
set userId 0 0 5 |
可以在 memcached 中使用的两个高级命令是 gets 和 cas 。gets 和 cas 命令需要结合使用。您将使用这两个命令来确保不会将现有的名称/值对设置为新值(如果该值已经更新过)。我们来分别看看这些命令。
gets
gets 命令的功能类似于基本的 get 命令。两个命令之间的差异在于,gets 返回的信息稍微多一些:64 位的整型值非常像名称/值对的 “版本” 标识符。
下面是使用 gets 命令的客户机服务器交互:
set userId 0 0 5 |
考虑 get 和 gets 命令之间的差异。gets 命令将返回一个额外的值 — 在本例中是整型值 4,用于标识名称/值对。如果对此名称/值对执行另一个 set 命令,则 gets 返回的额外值将会发生更改,以表明名称/值对已经被更新。清单 6 显示了一个例子:
|
您看到 gets 返回的值了吗?它已经更新为 5。您每次修改名称/值对时,该值都会发生更改。
cas
cas (check 和 set)是一个非常便捷的 memcached 命令,用于设置名称/值对的值(如果该名称/值对在您上次执行 gets 后没有更新过)。它使用与 set 命令相类似的语法,但包括一个额外的值:gets 返回的额外值。
注意以下使用 cas 命令的交互:
set userId 0 0 5 |
如您所见,我使用额外的整型值 6 来调用 gets 命令,并且操作运行非常顺序。现在,我们来看看清单 7 中的一系列命令:
|
注意,我并未使用 gets 最近返回的整型值,并且 cas 命令返回 EXISTS 值以示失败。从本质上说,同时使用 gets 和 cas 命令可以防止您使用自上次读取后经过更新的名称/值对。
最后两个 memcached 命令用于监控和清理 memcached 实例。它们是 stats 和 flush_all 命令。
stats
stats 命令的功能正如其名:转储所连接的 memcached 实例的当前统计数据。在下例中,执行 stats 命令显示了关于当前 memcached 实例的信息:
stats |
此处的大多数输出都非常容易理解。稍后在讨论缓存性能时,我还将详细解释这些值的含义。至于目前,我们先来看看输出,然后再使用新的键来运行一些 set 命令,并再次运行 stats 命令,注意发生了哪些变化。
flush_all
flush_all 是最后一个要介绍的命令。这个最简单的命令仅用于清理缓存中的所有名称/值对。如果您需要将缓存重置到干净的状态,则 flush_all 能提供很大的用处。下面是一个使用 flush_all 的例子:
set userId 0 0 5 |
在本文的最后,我将讨论如何使用高级 memcached 命令来确定缓存的性能。stats 命令用于调优缓存的使用。需要注意的两个最重要的统计数据是 et_hits 和 get_misses。这两个值分别指示找到名称/值对的次数(get_hits)和未找到名称/值对的次数(get_misses)。
结合这些值,我们可以确定缓存的利用率如何。初次启动缓存时,可以看到 get_misses 会自然地增加,但在经过一定的使用量之后,这些 get_misses 值应该会逐渐趋于平稳 — 这表示缓存主要用于常见的读取操作。如果您看到 get_misses 继续快速增加,而 get_hits 逐渐趋于平稳,则需要确定一下所缓存的内容是什么。您可能缓存了错误的内容。
确定缓存效率的另一种方法是查看缓存的命中率(hit ratio)。缓存命中率表示执行 get 的次数与错过 get 的次数的百分比。要确定这个百分比,需要再次运行 stats 命令,如清单 8 所示:
|
现在,用 get_hits 的数值除以 cmd_gets。在本例中,您的命中率大约是 71%。在理想情况下,您可能希望得到更高的百分比 — 比率越高越好。查看统计数据并不时测量它们可以很好地判定缓存策略的效率。
缓存是任何海量 Web 应用程序不可或缺的部分。我自己成功使用过它好几次。如果您选择使用 memcached 作为缓存解决方案,那么我敢保证您可以看到它的效率如何。
在本系列的第 2 部分中,您将学习如何将 memcached 集成到一个 Grails 应用程序中。我们将借此机会讨论一个激动人心的用于可伸缩 Web 应用程序开发的栈,并应用一些出色的技巧。到目前为止,本文介绍的知识足以帮助您开始掌握 memcached。我鼓励您安装自己的 memcached 实例并开始尝试使用它。
学习
- “Distributed Caching with Memcached ”(Brad Fitzpatrick,Linux Journal ,2004 年 8 月):Danga Interactive 的 Brad Fitzpatrick 向您介绍 memcached。
- “Server load-balancing architectures: Transport-level architectures ”(Gregor Roth,JavaWorld,2008 年 10 月):介绍跨多台机器缓存
HttpResponse消息的 memcached 负载平衡解决方案。 - “对 Web 应用程序进行性能调优 ”(Sean Walberg,developerWorks,2009 年 1 月):概述 Web 应用程序的各种组件之间如何交互,包括常见的性能瓶颈和缓存等解决方案。
- “Is Memcached a Good or Bad Sign for MySQL? ”(Gary Orenstein,Gigaom.com,2009 年 5 月):概述 memcached 在应用程序栈中的位置,以及将轻量级缓存替代为 RDBMS 带来的挑战。
- developerWorks Java 技术专区 :查看数百篇关于 Java 编程各个方面的文章。
获得产品和技术
- 下载 memcached :一种分布式内存缓存系统。
- 下载 libevent :一个异步事件通知库。
- 下载 PuTTy :一个 Windows telnet 客户机。