瑞吉外卖项目 SpringBoot+MyBatis-Plus Day01-05
SpringBoot+MyBatis-Plus 瑞吉外卖项目
声明哦:
整个记录中的所有的资料均来自哔哩哔哩黑马程序员,也感谢该机构的项目资料与教学视频的分享,同时也感谢BlaCloud博主的项目实现搭建的博客记录。
项目基本功能展示
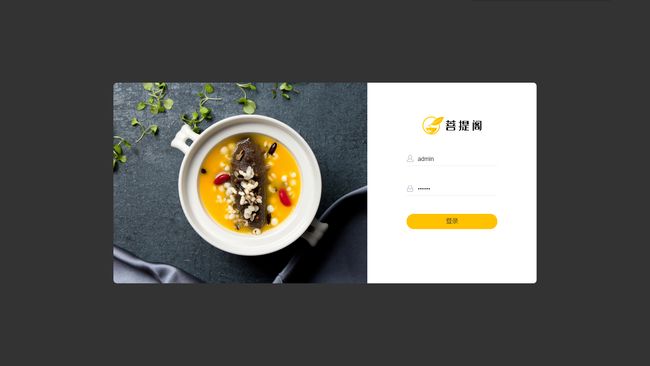
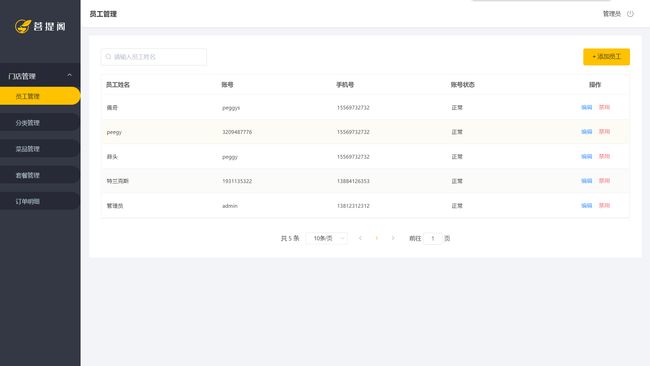
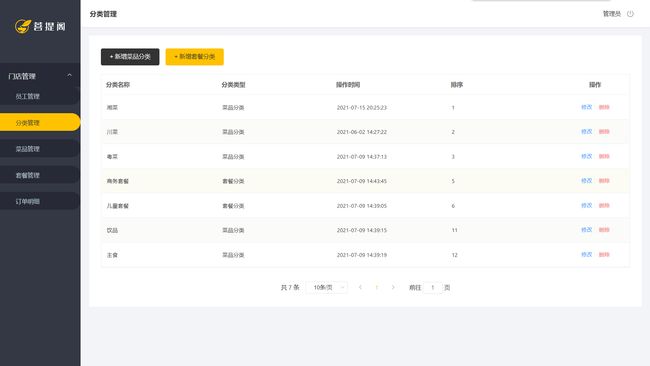
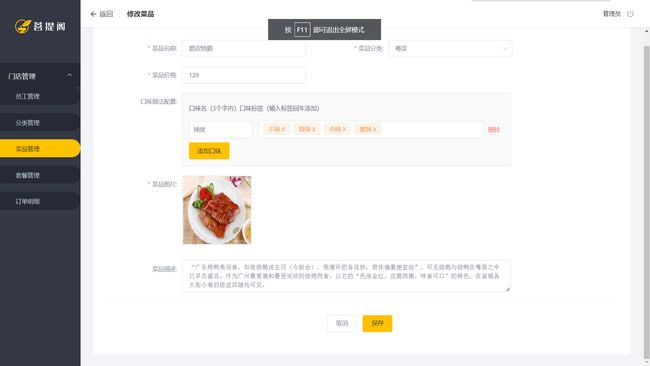
项目结构
- 后台系统
菜单管理(批量删除、起售停售)
套餐管理(修改、起售停售)
订单明细
- 移动端
个人中心(退出登录、最新订单查询、历史订单、地址管理-地址修改、地址管理-地址修改)
购物车(删除购物车中的商品)
因为网上关于该项目的记录其实挺多的,所以关于其详细步骤记录的并不多,只有自己在学习过程中的难点的记录。
项目技术
项目中用到的重要的技术:
- SpringBoot
- MyBatis-puls
- Vue
MyBatis-Plus 官网
Vue 官网
黑马程序员官方提供的项目资料 提取码 :4444
后台系统后端源码分析
登录分析
在我之前接触到的前端HTML+JS的传统中增删改查的项目中,Conllecton都会返回一个URL请求地址或标识符,但由于Vue的引入使得前后端分离,我们的Collection层不再返回请求的映射地址,只需要一个公共的结果集即可。前端的JS会自动当解析我们的后端响应返回的JSON数据,并进行处理。
前端登录页面
<el-button :loading="loading" class="login-btn" size="medium" type="primary" style="width:100%;" @click.native.prevent="handleLogin">
<span v-if="!loading">登录span>
<span v-else>登录中...span>
el-button>
methods: {
async handleLogin() {
this.$refs.loginForm.validate(async (valid) => {
if (valid) {
this.loading = true
let res = await loginApi(this.loginForm)
if (String(res.code) === '1') {
localStorage.setItem('userInfo',JSON.stringify(res.data))
window.location.href= '/backend/index.html'
} else {
this.$message.error(res.msg)
this.loading = false
}
}
})
}
}
function loginApi(data) {
return $axios({
'url': '/employee/login',
'method': 'post',
data
})
}
后端处理登录页面
/**
* 员工登录
* @param request 请求体中的数据
* @param employee 登录成功员工的id
* @return R -返回结果集
*
* 将页面提交的密码进行MD5加密处理
* 根据页面提交的用户名username查询数据库
* 如果没有查询到则返回登录失败结果
* 密码比对,如果不一致则返回登录结果
* 查看员工状态,如果已为禁用状态,则返回员工已禁用结果
* 登录成功,将员工id存入session并返回登录成功结果
*
*/
//@RequestBody 接收前端传递给后端的json字符串(请求体中的数据)
//HttpServletRequest 登录成功,将员工对应的id存到session一份,这样想获取一份登录用户的信息就可以随时获取出来
@PostMapping("/login")
public R<Employee> login(HttpServletRequest request, @RequestBody Employee employee){
//- 将页面提交的密码进行MD5加密处理
String password=employee.getPassword();
password= DigestUtils.md5DigestAsHex(password.getBytes());
//- 根据页面提交的用户名username查询数据库
LambdaQueryWrapper<Employee> queryWrapper=new LambdaQueryWrapper<>();
queryWrapper.eq(Employee::getUsername,employee.getUsername());
Employee emp = employeeService.getOne(queryWrapper);
//- 如果没有查询到则返回登录失败结果
if(emp==null){
return R.error("用户名不存在");
}
//- 密码比对,如果不一致则返回登录结果
if(!password.equals(emp.getPassword())){
log.info("登录界面密码:"+password);
log.info("查询到的用户密码:"+emp.getPassword());
return R.error("抱歉,用户【"+emp.getUsername()+"】您的登录密码错误");
}
//查看员工状态,如果已为禁用状态,则返回员工已禁用结果
if(emp.getStatus()!=1){
return R.error("抱歉,用户【"+emp.getUsername()+"】您的账户当前被禁用,请及时联系管理员处理");
}
//登录成功,将员工id存入session并返回登录成功结果
request.getSession().setAttribute("employee",emp.getId());
return R.success(emp);
}
公共结果集R
package com.peggy.reggies.commom;
import lombok.Data;
import java.util.HashMap;
import java.util.Map;
@Data
public class R<T> {
private Integer code; //编码:1成功,0和其它数字为失败
private String msg; //错误信息
private T data; //数据
private Map map = new HashMap(); //动态数据
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
public R<T> add(String key, Object value) {
this.map.put(key, value);
return this;
}
}
- 登录请求响应之前
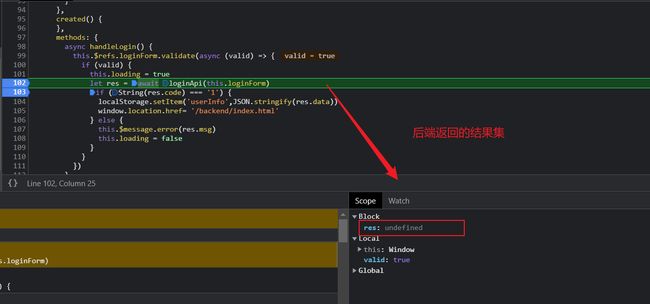
- 登录请求响应之后
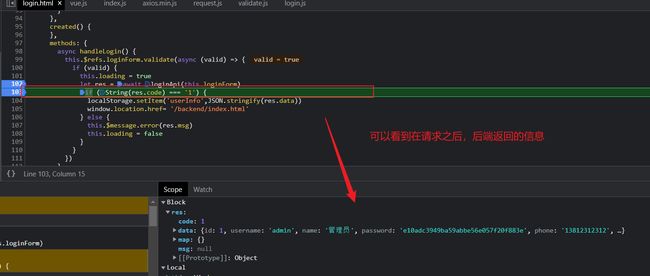
通过以上的代码就比较容易的分析出其实,我们的前端的登录按钮被按下后会调用JS中的 loginApi()方法进行Ajax请求获取,后端 return R.success(emp)会返回 结果集R
所以这里的R集使用的采用泛型 R 进行数据返回结果的封装,保证任何类型的数据都可以通过结果集进行分装返回
其实分析看到这里也就解释了,为什么我之前提出的疑惑,后端是如何通过返回一个结果集R就可以实现,不需要URI响应跳转,就可以实现前端数据的响应赖。其实就是一个Ajax请求,好像没使用过Ajax都已经忘记赖,哈哈。
拦截器分析
对于SpringBoot的静态资源访问,必须都是在resources资源包下的指定的目录文件之下。对于自定义的子目录,需要通过自定义是图解析器进行映射处理
@Slf4j
@Configuration
public class WebMvcConfig extends WebMvcConfigurationSupport {
@Override
protected void addResourceHandlers(ResourceHandlerRegistry registry) {
log.info("自定义视图解析====启动");
registry.addResourceHandler("/backend/**").addResourceLocations("classpath:/backend/");
registry.addResourceHandler("/front/**").addResourceLocations("classpath:/front/");
}
}
虽然静态资源的目录映射可以解决,但是对于 非法访问 (绕过登录界面访问静态资源或进行Controller请求),却是无法避免。所以我们就需要加入一个拦截器,对于非法的访问进行,拦截判断处理。
登录页面拦截器
package com.peggy.reggies.filter;
import com.alibaba.fastjson.JSON;
import com.peggy.reggies.commom.R;
import lombok.extern.slf4j.Slf4j;
import org.springframework.util.AntPathMatcher;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
@WebFilter(filterName = "loginCheckFilter",urlPatterns = "/*")
@Slf4j
public class LoginCheckFilter implements Filter {
/**
* PATH_MATCHER 定义静态方法AntPathMatcher对象用于路径匹配调用
*/
public static final AntPathMatcher PATH_MATCHER = new AntPathMatcher();
/**
* 非法访问拦截
*
* @param servletRequest 请求
* @param servletResponse 响应
* @param filterChain 过滤器
* @throws IOException
* @throws ServletException
*
*
判断本次请求是否需要处理
*如果不需要处理,则直接放行
*判断登录状态,如果已登录,则直接放行
*如果未登录则返回未登录结果
*
*/
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
//将ServletRequest转换为 Http 获取Session
HttpServletRequest request= (HttpServletRequest) servletRequest;
HttpServletResponse response= (HttpServletResponse) servletResponse;
log.info("拦截器请求:{}",request.getRequestURI());
//获取当前请求的URL
String requestURI = request.getRequestURI();
//定义不需要处理的请求
String[] urls=new String[]{
"/employee/login", //登录
"/employee/logout", //注销
"/backend/**", //静态资源目录
"/front/**" //静态资源目录
};
//判断本次请求是否需要处理
if(check(urls,requestURI)){
log.info("本次请求不需要处理{}",requestURI);
filterChain.doFilter(request,response);
return;
}
//判断当前的登录状态,如果已经登录,放行
if(request.getSession().getAttribute("employee")!=null){
log.info("用户{}已经登录",request.getSession().getAttribute("employee"));
filterChain.doFilter(request,response);
return;
}
//如果未登录则返回未登录结果
log.info("未登录");
//将结果集R中的数据与当前的状态码进行返回到前段交给与js处理
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));
return;
}
/**
* 路径匹配校验
* @param urls 预设放行路径
* @param requestURI 当前前端请求路径
* @return 路径匹配结果
*
* 如果在请求中,预设放行行路径与请求路径匹配,则返回 ture 负责返回 flash
*
*/
public boolean check(String[] urls,String requestURI){
for (String url : urls) {
boolean math=PATH_MATCHER.match(url,requestURI);
if(math)
//路径请求与预设放行路径匹配
return true;
}
//不匹配
return false;
}
}
这里的自定义的登录拦截器整体的逻辑就是 请求拦截——>请求判断——>请求处理(放行或拦截)
对于请求的拦截:
用户未登录的非法访问
- 用户登录后注销的非法访问
对于请求的判断:
- 用户登录后再Session域中是否存在当前用户的登录信息(是否登录后注销了用户)
- 访问的请求是否是不需要拦截的请求(登录请求、静态网页的访问)
对于请求的处理:
- 对于非法的访问请求进行处理
response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN"))); - 对于符合条件的请求放行
filterChain.doFilter(request,response);
那么对于非法的访问我们的后台通过response.getWriter().write(JSON.toJSONString(R.error("NOTLOGIN")));,将错误的信息通过解析为JSON格式响应到我们的前台,那我们的前台是如何进行处理,实现任何非法访问到都会跳转到登录页面赖?
我们通过前端调试进行测试:
在我们的后台的拦截器出打一个断点进行调试
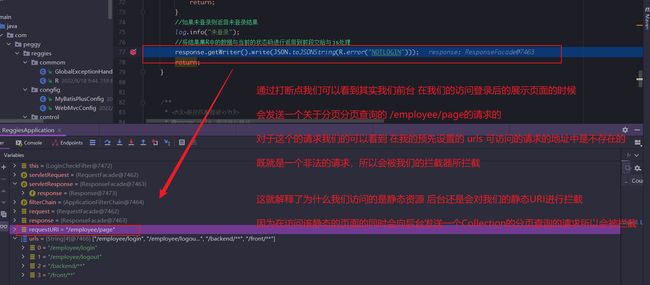
那么我们的后台的在Rsponse中响应的数据到底是在前端如何进行处理的我们接着看
可以看到当我们的后台进行放行时

我们的前台的中的code与msg中就会响应到后台的json数据此时 code=0 msg=NOLOGIN
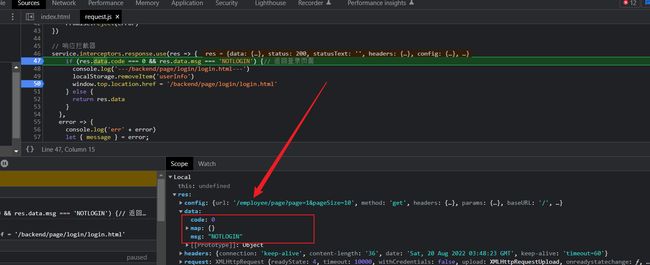
并且同时跳转到登录页面 window.top.location.href = '/backend/page/login/login.html' ,并且清楚之前在用户的所有信息。
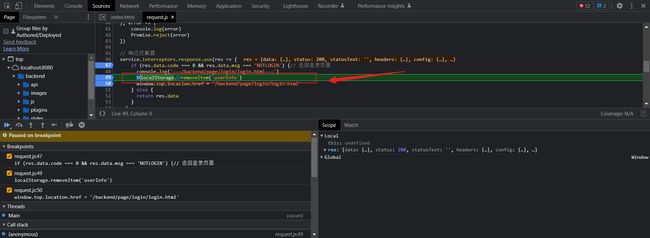
如果是正常登录就会发现这里 code=1 msg=null
这个其实就是我们在访问正常登录时 return R.success(emp)返回了登录的用户信息,也就是调用不同的结果集方法所返回的不同的code状态码。
public static <T> R<T> success(T object) {
R<T> r = new R<T>();
r.data = object;
r.code = 1;
return r;
}
public static <T> R<T> error(String msg) {
R r = new R();
r.msg = msg;
r.code = 0;
return r;
}
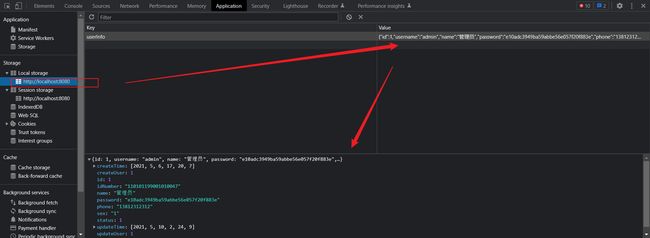
分页查询分析
由于在整个的项目当中使用的都是MyBatis-Plus,我们的所以的业务操作都是直接通过MP的构造器进行处理的,所以我们对于员工的页面展示需要进行分页查询,先测试前端将前端与后端的请求连通。
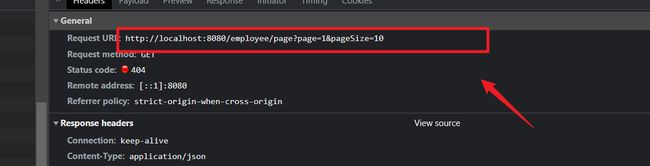
通过前端的加载页面可以看到向我们后端发送了一个GET的URI请求,并且携带参数 page与pageSize。所以我们需要了在后端对响应的请求进行处理,然后将分页查询到的数据通过结果集R返回。
关于MP分页查询的数据测试
MP分页查询步骤:
- 构造分页构造器
- 构造条件构造器
- 执行查询
//构造分页构造器
Page pageInfo =new Page(page,pageSize);
//构造条件查询器
LambdaQueryWrapper<Employee> queryWrapper = new LambdaQueryWrapper<>();
//添加过滤条件
queryWrapper.like(StringUtils.isNotEmpty(name),Employee::getName,name);
//添加排序条件
queryWrapper.orderByDesc(Employee::getUpdateTime);
//执行查询
employeeService.page(pageInfo,queryWrapper);
StringUtils.isNotEmpty(name)
- 该语句的是为进行模糊查询的匹配是否开启,如果我们的前端没有返回name就如起始页的加载,返回的name是为空,就不需要为我们的条件构造器中添加like模糊查询
我们在测试环境下对接受到分页查询的数据进行测试。
对于测试类比较重要的一点就是:**@RunWith(SpringRunner.class)**注解,该注解的作用就是当前的测试类以SpringBoot环境运行
@SpringBootTest
@RunWith(SpringRunner.class)
class ReggiesApplicationTests {
@Autowired
EmployeeControl employeeControl;
@Test
void contextLoads() {
R<Page> page = employeeControl.page(1, 4, "null");
System.out.println(page);
}
}

感受:MyBatis-plus想对于之前使用的MyBatis对于简单的CRUD操作更加的方便,直接调用我们的条件构造器进行处理即可。
员工账户状态管理分析
动态显示员工的状态分析

我们可以看到对于员工有禁用正常与否的两种状态。我们在看我们的后台实体员工类,我们可以发现,我们的员工实体类当中有一个属性为private Integer status;表示该员工的当前的状态。
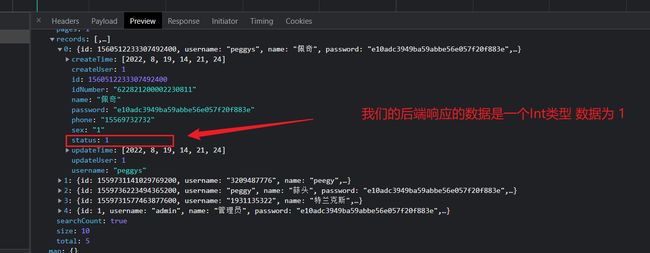
可以看到对于后端我们返回的数据确实是一个Int类型的数据,而非字符串。那么我们的前端到底是怎么处理 后台返回的这个 status值的呢?使得我们的前端的展示页面的数据就是 正常 或 禁用 赖,这个就需要我们去到前端的列表页面,进行查看前端的处理源码与逻辑赖。
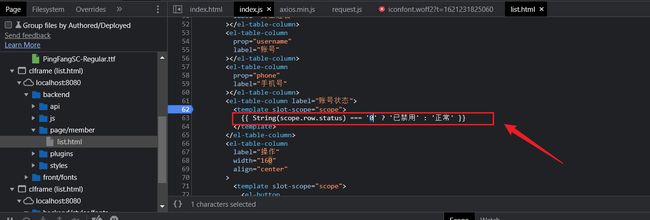
对于局部刷新的list页面,可以看到对其后台响应的数据进行了逻辑判断的处理,将 status 的值进行了判断输出。 所以我们在前台看到了员工的当前状态 正常或者是禁用
员工状态修改处理分析
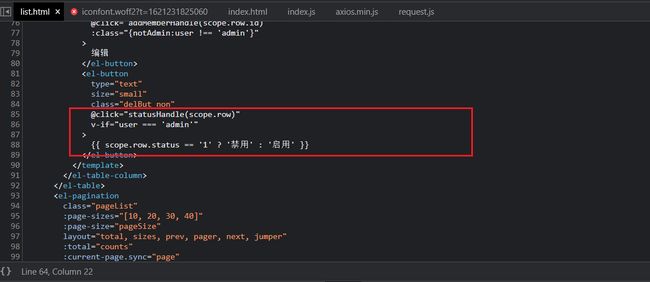
可以看到这里有一个对修改的当前用户的判断,也就是。如果我们的当前用户不是管理员 admin用户,那么是不允许对其他的用户状态权限进行修改的。
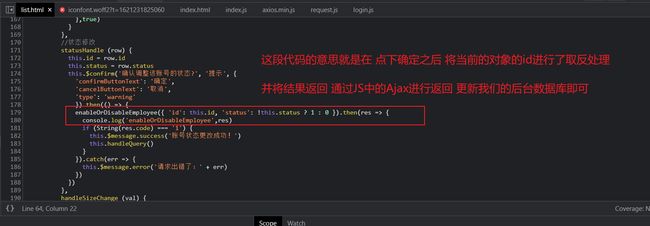
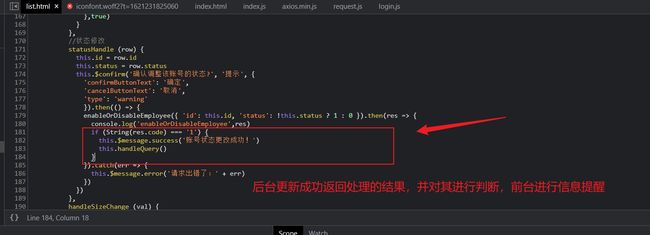
员工的状态管理代码实现
@RequestBody 主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的)
其实对于员工的当前的状态的修改就是,只是修改了员工属性中的 status字段,所以我们只需要通过员工属性中的唯一标识ID对员工进行修改。至于我们的后台是如果获取到更新后的员工的信息的呢?
其实前面提到过,通过前端的 enableOrDisableEmployee()方法,进行Ajax请求将Employee数据返回到我们的后台,后台操作对数据库进行更新。
这里需要注意的一点:
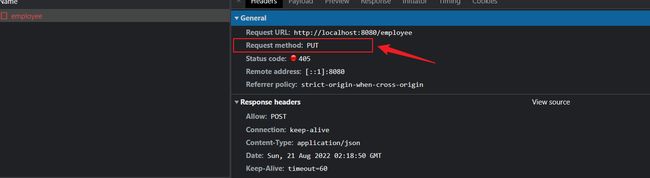
前台的请求是一个PUT请求也就是一个针对于update更新的请求
关于四种请求的方式的不同大家可以参考该博主的博客——四种请求方式 get、post、put、delete 的用法及区别(全)
由于请求的uri是一个父级别路径,所以我们在后台端Control中需要指定我们的 put 请求所以在我们的更新方法上,需要添加一个@PutMapping注解用于指定我们的具体请求。
//获取当前修改者的信息
Long empID= (Long) request.getSession().getAttribute("employee");
//更新当前的修改者
employee.setUpdateUser(empID);
//更新当前的修改时间
employee.setUpdateTime(LocalDateTime.now());
//更新数据库
employeeService.updateById(employee);
我们测试可以看到我们的更新的请求响应成功,但是我们的前台用户的状态却没有发生更改。
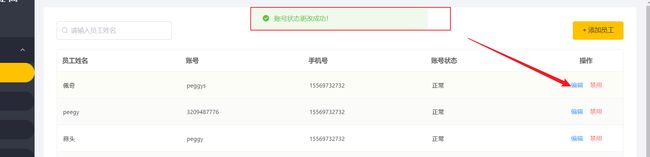
从后台的返回更新的字段信息可以看到,我们成功更新的字段为0个,前台返回的id解析后的json字段没有问题,但是前台返回的json的id字段却与数据库中的id字段数据,不匹配,导致更新失败。

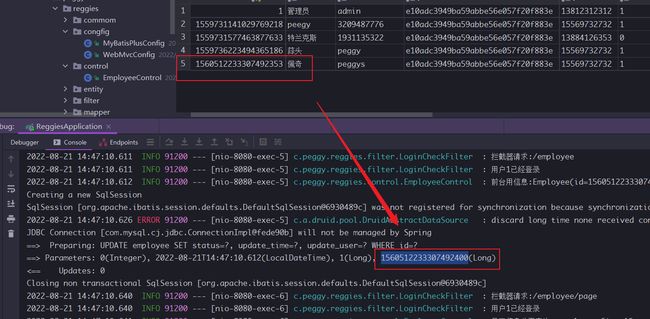
那么是什么原因导致的呢?
首先我们的员工的信息是从后台的数据库中取出,响应到前台的所以数据库与后台的交互是不会出现问题的,那我们去查看前台从后台请求中获取的id是不是数据就已经发生了问题。
我们重新刷新我们的 list 页面可以发现,后台响应给我们前台的 id 是一个非String类型的数据,导致了js前台处理时对long类型数据的精度的丢失。
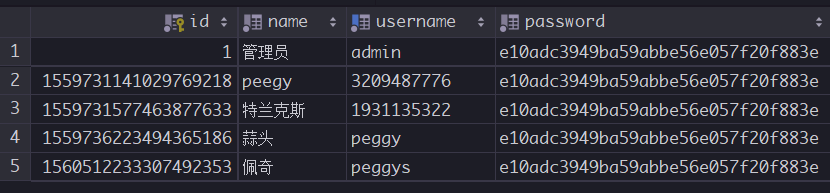
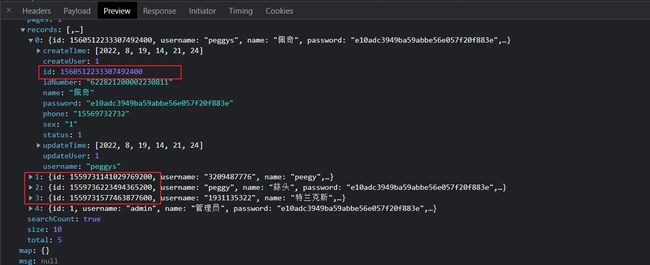
所以我们需要将后台的id数据在Ajax响应前台时进行处理转化为 String 类型
配置状态转化器
具体实现步骤
- 提供对象转换器Jackson0bjectMapper,基于Jackson进行Java对象到json数据的转换(资料中已经提供,直接复制到项目中使用)
- 在WebMcConfig配置类中扩展Spring mvc的消息转换器,在此消息转换器中使用提供的对象转换器进行Java对象到json数据的转换
配置对象映射器JacksonObjectMapper ,继承ObjectMapper
- 虽然代码项目中,已经提供但是还是有必要拿过来分析一下哒
/**
* 对象映射器:基于jackson将Java对象转为json,或者将json转为Java对象
* 将JSON解析为Java对象的过程称为 [从JSON反序列化Java对象]
* 从Java对象生成JSON的过程称为 [序列化Java对象到JSON]
*/
public class JacksonObjectMapper extends ObjectMapper {
public static final String DEFAULT_DATE_FORMAT = "yyyy-MM-dd";
public static final String DEFAULT_DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
public static final String DEFAULT_TIME_FORMAT = "HH:mm:ss";
public JacksonObjectMapper() {
super();
//收到未知属性时不报异常
this.configure(FAIL_ON_UNKNOWN_PROPERTIES, false);
//反序列化时,属性不存在的兼容处理
this.getDeserializationConfig().withoutFeatures(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES);
SimpleModule simpleModule = new SimpleModule()
.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)))
.addSerializer(BigInteger.class, ToStringSerializer.instance)
.addSerializer(Long.class, ToStringSerializer.instance)
.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_TIME_FORMAT)))
.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern(DEFAULT_DATE_FORMAT)))
.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern(DEFAULT_TIME_FORMAT)));
//注册功能模块 例如,可以添加自定义序列化器和反序列化器
this.registerModule(simpleModule);
}
}
扩展mvc框架的消息转换器
/**
* 扩展mvc框架的消息转换器
* @param converters
*/
@Override
protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {
//创建消息转换器对象
MappingJackson2HttpMessageConverter messageConverter = new MappingJackson2HttpMessageConverter();
//设置对象转化器,底层使用jackson将java对象转为json
messageConverter.setObjectMapper(new JacksonObjectMapper());
//将上面的消息转换器对象追加到mvc框架的转换器集合当中(index设置为0,表示设置在第一个位置,避免被其它转换器接收,从而达不到想要的功能)
converters.add(0,messageConverter);
}
额。。。还是不分析赖,我觉得不能说是不懂,是完全没感觉。
现在可以看到已经可以成功修改

后端返回的数据与数据库sql语句的执行日志也没有问题
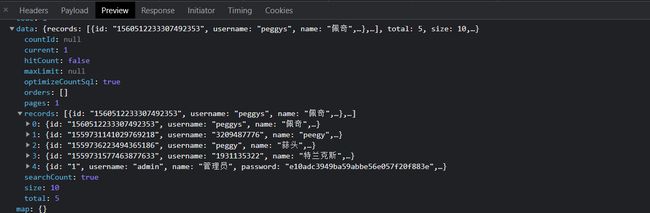

其实今天在做另一个项目测试的时候发现对于MyBtais-plus查询导致的前端传送的数据精度的丢失,其实可以通过另一种的方式解决。
只需要在id属性中加上 @JsonFormat(shape = JsonFormat.Shape.STRING)注解即可
@JsonFormat(shape = JsonFormat.Shape.STRING)
private Long id;
@JsonFormat 用来表示json序列化的一种格式或者类型,shap表示序列化后的一种类型
修改员工分析
过程分析,当点击修改页面的时候,会向后台请求一个id,根据id查询用户信息,将需要修改的用的信息回显到我们的添加页面。
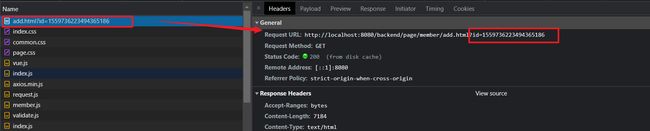
这里向后台发送get请求后台以RESTful风格接受返回的数据,根据id查询
@GetMapping({"/{id}"})
public R<Employee> getById(@PathVariable Long id){
log.info("更加id获取员工的信息。。。。。");
Employee employee=employeeService.getById(id);
if(employee!=null){
return R.success(employee);
}else{
return R.error("没有查询到该员工的信息");
}
}
后台以json返回查询到的结果信息

当我们在修改信息之后点击保存按钮的时候,会调用**submitFrom()**函数
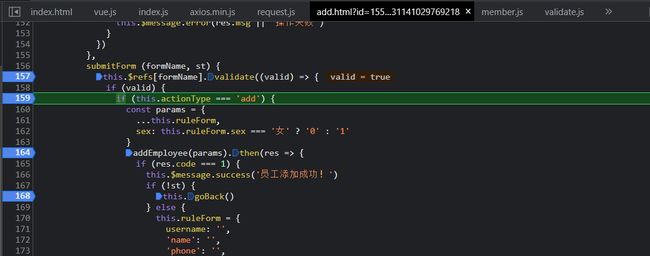
跳转到后台的更新请求对数据库进行更具ID进行更新,employeeService.updateById(employee);
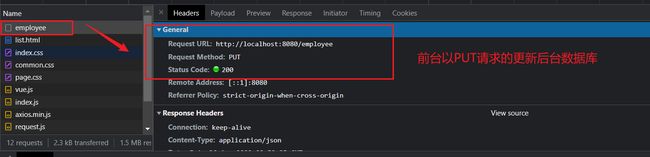
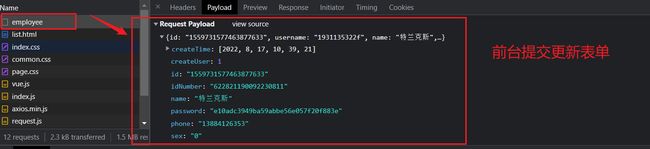

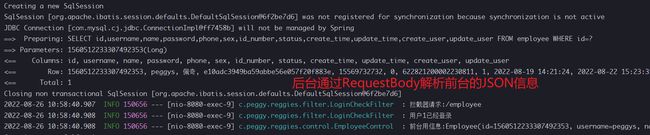
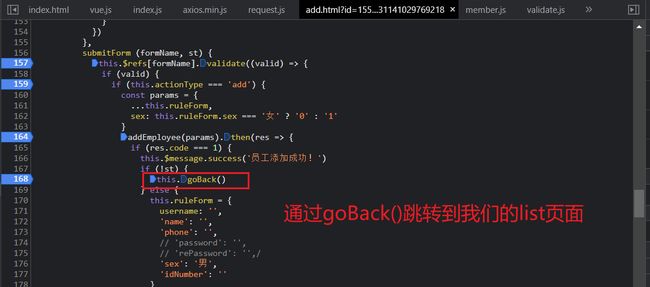

至此一次关于修改请求的响应已经全部完成
关于公共字段的分析与简化处理
其实我们在项目中可以发现我们在每一次的操作用户(添加,修改)用户的时候,都会对公共的字段进行更新,比如在添加用户的时候我们会对一下的字段进行更新
//用户的创建时间与更新时间
employee.setCreateTime(LocalDateTime.now());
employee.setUpdateTime(LocalDateTime.now());
//创建与更新用户的用户ID
employee.setCreateUser(empID);
employee.setUpdateUser(empID);
我们在更新用户的时候会对以下的字段进行更新
//更新当前的修改者
employee.setUpdateUser(empID);
//更新当前的修改时间
employee.setUpdateTime(LocalDateTime.now());
对用这种进行相同操作的公共字段我们可不可提取出来,单独的进行自动处理赖?没错我们的MyBatis-Plus举手说这个我可以,交给我。
我们的MP给我们提供了便捷的 公共字段自动填充 功能,可以直接将公共的字段提取出来,交付于我们的MP处理。
对于实现MP的自动填充我们需要的只有两步:
- 在需要提取的公共字段的实体类中添加@TableField注解,指定自动填充的策略
- 按照框架的要求编写元数据对象的处理器,在此类中为统一公共字段赋值,此类需要实现MetaObjectHadler接口
公共的字段中添加不同的更新处理注解
对应实体类的TableField注解添加
//表示插入时填充字段
@TableField(fill = FieldFill.INSERT)
private LocalDateTime createTime; //创建时间
@TableField(fill = FieldFill.INSERT_UPDATE)
private LocalDateTime updateTime; //修改时间
@TableField(fill = FieldFill.INSERT)
private Long createUser; //创建者
//表示插入和更新时填充字段
@TableField(fill = FieldFill.INSERT_UPDATE)
private Long updateUser; //修改者
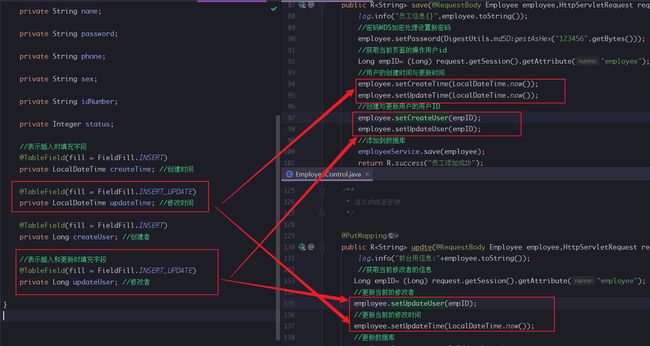
创建自定义的MetaObjectHadler处理
@Controller
@Slf4j
public class MyMethObjectHandler implements MetaObjectHandler {
@Override
public void insertFill(MetaObject metaObject) {
log.info("公共字段填充【insert】");
metaObject.setValue("createTime", LocalDateTime.now());
metaObject.setValue("updateTime", LocalDateTime.now());
metaObject.setValue("createUser", new Long(1l));
metaObject.setValue("updateUser", new Long(1l));
}
@Override
public void updateFill(MetaObject metaObject) {
log.info("公共字段填充【update】");
metaObject.setValue("updateTime", LocalDateTime.now());
metaObject.setValue("updateUser", new Long(1l));
}
}
这里其实我们的发现存在一个比较明显的问题的就是,我们无法获取用户的id信息
这里就需要引进一个ThreaLocal。在引入ThreaLocal之前我们先需要先观察确定一下,每一次客户端发送Http请求的时候,与之对应的会给服务端分配一个新的线程进行处理,因次在处理的过程当中,只要是涉及到config包下,自定义配置类中的方法都是数据同一个线程的处理。
为了验证,我们可以在每一个的类中都加入一个 提取当前的线程的id的方法,进行测试。
- LoginCheckFilter的doFilter方法
- EmployeeController的update方法
- MyMetaObjectHandler的updateFill方法
分别在以下类的调用的方法中加入 日志打印发现,调用者三个类时,调用的都是相同的一个线程


关于ThreadLocal线程的概述

- 可以参考博主:我叫大魔王-多线程中的ThreadLocal 详解
关于ThreadLocal方法的使用详解
public T get() { } // 用来获取ThreadLocal在当前线程中保存的变量副本
public void set(T value) { } //set()用来设置当前线程中变量的副本
public void remove() { } //remove()用来移除当前线程中变量的副本
protected T initialValue() { } //initialValue()是一个protected方法,一般是用来在使用时进行重写的
其实简单点来说就是,由于每一次的前端完整的一次请求,**LoginCheckFilter的doFilter**类中的方法都会启动一个新线程,并且该线程与
EmployeeController中的update ,MyMetaObjectHandler中的updateFill中启动的线程是同一个,因为我们可以通过**LoginCheckFilter的doFilter** ,为ThreadaLocal 设置一个当前的线程中的当前用户的副本,然后在**MyMetaObjectHandler**中取出当前用户
-
封装一个ThradLocal的对象获取类
public class BaseContext { public static ThreadLocal<Long> threadLocal=new InheritableThreadLocal<>(); public Long getContextId(){ return threadLocal.get(); } public void setContextId(Long id){ threadLocal.set(id); } }
分类管理
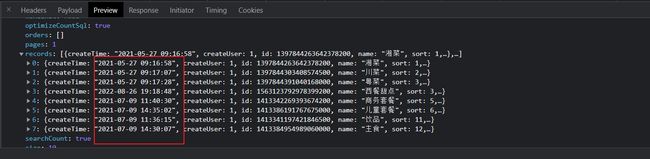
对于分管理这部分其实与之前的部门管理之前没有什么大的区别,唯一需要注意的就是,我们的发现我们的后台解析**LocalDateTime**格式的数据时出现了问题,数据格式不再是 2022-08-17 10:37:37的形式而是[2022, 8, 26, 17, 27, 28]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g6lmUBub-1661515318176)(C:\Users\Peggy\AppData\Roaming\Typora\typora-user-images\image-20220826194634780.png)]

这个是由于我们JSON在解析 **LocalDateTime**格式的数据时没有对于的序列化规则,所以采用的默认的序列化的规则,返回了一堆数组。解决的方式就是配置一个序列化的规则让其执行
当然其实也可以直接通过 **@JsonFormat(pattern = “yyyy年MM月dd日”)**的这种格式进行序列化
@Override
protected void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
FastJsonHttpMessageConverter fastJsonHttpMessageConverter = new FastJsonHttpMessageConverter();
FastJsonConfig fastJsonConfig = new FastJsonConfig();
fastJsonConfig.setSerializerFeatures(
SerializerFeature.PrettyFormat,
SerializerFeature.WriteMapNullValue,
SerializerFeature.DisableCircularReferenceDetect
);
fastJsonConfig.setDateFormat("yyyy-MM-dd HH:mm:ss");
fastJsonHttpMessageConverter.setFastJsonConfig(fastJsonConfig);
converters.add(0, fastJsonHttpMessageConverter);
}
额 这个项目后续由于其他的时间问题,就再没有花费更多的精力再去更新。
项目也已经完成部署到服务器中前台地址:
瑞吉外卖后台管理
瑞吉外卖客户端
总结:
- 整体前后端分离通过封装的返回集与Axios进行前台交互,但严格意义上说只是前后端的雏形,并未将前台重新部署到一个独立的服务端口中。
- 使用MyBatis-Plus,通过数据实体类的二次封装,在Service层的实现类中通过,对其他Dao层的调用实现数据的关联操作
其他方面并未有特别突出的亮点,主要是在整个项目的实施搭建测试过程中发现的两个新的设计思想,比较有意思。