CV-Model【7】:Swin Transformer
系列文章目录
Transformer 系列网络(一):
CV-Model【5】:Transformer
Transformer 系列网络(二):
CV-Model【6】:Vision Transformer
Transformer 系列网络(三):
CV-Model【7】:Swin Transformer
文章目录
- 系列文章目录
- 前言
- 1. Abstract & Introduction
-
- 1.1. Abstract
- 1.2. Introduction
- 2. Method
-
- 2.1. Model
-
- 2.1.1. Comparison between ViT & SiT
- 2.1.2. Architecture
- 2.2. Patch Merging
- 2.3. Shifted Window based Self-Attention
-
- 2.3.1. MSA
- 2.3.2. W-MSA
- 2.3.3. MSA & W-MSA Calculation volume
-
- 2.3.3.1. MSA Calculation volume
- 2.3.3.2. W-MSA Calculation volume
- 2.3.3. SW-MSA
- 2.3.4. Efficient batch computation for shifted configuration
- 2.3.5. Relative Position Bias
- 2.3.6. Model configuration parameters
- 总结
前言
Swin Transformer 是 Vision Transformer 的一种类型。它通过合并深层的图像斑块(灰色显示)来建立分层的特征图,由于只在每个局部窗口(红色显示)内计算 self-attention,所以计算复杂度与输入图像大小成线性关系。因此,它可以作为图像分类和密集识别任务的通用 backbone。相比之下,以前的视觉变换器产生单一的低分辨率的特征图,并且由于全局的 self-attention 的计算,对输入图像的大小有二次计算的复杂性。
原论文链接:
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
1. Abstract & Introduction
1.1. Abstract
本文介绍了一种称为 Swin Transformer 的新视觉 Transformer,它可以作为 CV 的通用主干。将 Transformer 从语言适应到视觉方面的挑战来自 两个域之间的差异,例如视觉实体的规模以及相比于文本单词的高分辨率图像像素的巨大差异。为解决这些差异,本位提出了一种 层次化 ( hierarchical ) Transformer,其表示是用移位窗口 ( Shifted Windows ) 计算的。移位窗口方案通过将自注意力计算限制在不重叠的局部窗口的同时,还允许跨窗口连接来提高效率。这种分层架构具有在各种尺度上建模的灵活性,并且相对于图像大小具有线性计算复杂度。
1.2. Introduction
视觉领域与语言领域两种模态之间主要存在以下差异:
- 与在语言
Transformer中作为处理的基本元素的word token不同,视觉元素在尺度 (scale) 上可以存在很大差异,这是一个在目标检测等任务中受到关注的问题。在现有的基于Transformer的模型中,token的尺度 (scale) 都是固定的,这是一种不适合这些视觉应用的性质 - 图像中的像素分辨率比文本段落中的文字要高得多。存在许多视觉任务 ,如语义分割,需在像素级别上进行密集预测,这对于高分辨率图像上的
Transformer而言是难以处理的,因为其自注意力的计算复杂度是关于图像大小的二次方
2. Method
2.1. Model
2.1.1. Comparison between ViT & SiT
为解决上述问题,相比于 Vision Transformer,Swin Transformer 做出了以下改变(有关 Vision Transformer 的内容可以参考我的另一篇 blog:CV-Model【6】:Vision Transformer):
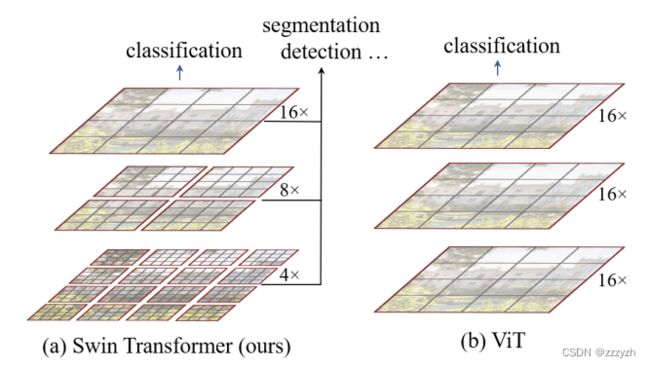
Swin Transformer构造了层次化特征图,且关于图像大小具有线性计算复杂度;而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变Swin Transformer使用了类似卷积神经网络中的层次化构建方法 (Hierarchical feature maps)Swin Transformer通过从小尺寸patch(灰色轮廓)开始,逐渐在更深的 Transformer 层中合并相邻patch,从而构造出一个层次化表示 (hierarchical representation)- 通过这些层次化特征图,
Swin Transformer模型可方便地利用先进技术进行密集预测,例如特征金字塔网络 ( FPN ) 或 U-Net
- 通过这些层次化特征图,
- 比如特征图尺寸中有对图像下采样
4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。
- 线性计算复杂度是通过在图像分区的非重叠窗口内,局部地计算自注意力来实现的(红色轮廓),而非在整张图像的所有
patch上进行- 每个窗口中的
patch数量是固定的,因此复杂度与图像大小成线性关系
- 每个窗口中的
Swin Transformer的一个关键设计元素是它在连续自注意力层之间的窗口分区的移位 ( shift )- 将特征图划分成了多个不相交的区域( Window ),并且
Multi-Head Self-Attention只在每个窗口( Window )内进行- 相对于
Vision Transformer中直接对整个( Global )特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候 - 这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以本文又提出了
Shifted Windows Multi-Head Self-Attention ( SW-MSA )的概念,通过此方法能够让信息在相邻的窗口中进行传递
- 相对于
- 将特征图划分成了多个不相交的区域( Window ),并且
2.1.2. Architecture

整个框架的基本流程如下:
- 首先将图片输入到
Patch Partition模块中进行分块,即每 4 × 4 4 \times 4 4×4 相邻的像素为一个Patch,然后在channel方向展平( flatten )- 将输入的 H × W × 3 H \times W \times 3 H×W×3 的 RGB 图像拆分为非重叠等尺寸的 N × ( P 2 × 3 ) N \times (P^{2} \times 3) N×(P2×3)
patch。每个 P 2 × 3 P^2 \times 3 P2×3patch都被视为一个patch token,共拆分出 N 个(即 Transformer 的有效输入序列长度)- 用大小为 P 2 = 4 × 4 P^2 = 4 \times 4 P2=4×4 且通道数 C = 3 C = 3 C=3 的
patch,故各patch展平后的特征维度为 P × P × C = 4 × 4 × 3 = 48 P \times P \times C = 4 \times 4 \times 3 = 48 P×P×C=4×4×3=48,共有 N = H 4 × W 4 = H W 16 N = \frac{H}{4} \times \frac{W}{4} = \frac{HW}{16} N=4H×4W=16HW 个patch tokens。换言之,每张 H × W × 3 H \times W \times 3 H×W×3 的图片被处理为了 H 4 × W 4 \frac{H}{4} \times \frac{W}{4} 4H×4W 个图片 patches,每个 patch 被展平为 48 48 48 维的 token 向量(类似 ViT 的 Flattened Patches),整体上是一个展平 ( flatten ) 的 N × ( P 2 × 3 ) = ( H 4 × W 4 × 48 ) N \times (P^2 \times 3) = (\frac{H}{4} \times \frac{W}{4} \times 48) N×(P2×3)=(4H×4W×48) 维 2 D 2D 2D patch 序列 - 线性嵌入层 ( Linear Embedding ),即全连接层,将此时维度为 H 4 × W 4 × 48 \frac{H}{4} \times \frac{W}{4} \times 48 4H×4W×48 的张量投影到任意维度 C C C,得到维度为 H 4 × W 4 × C \frac{H}{4} \times \frac{W}{4} \times C 4H×4W×C 的 Linear Embedding
- 用大小为 P 2 = 4 × 4 P^2 = 4 \times 4 P2=4×4 且通道数 C = 3 C = 3 C=3 的
- 举例来说:

- 假设输入的是 RGB 三通道图片,那么每个
patch就有 4 × 4 = 16 4 \times 4=16 4×4=16 个像素,然后每个像素有 R、G、B 三个值所以展平后是 16 × 3 = 48 16 \times 3=48 16×3=48,所以通过Patch Partition后图像shape由 [ H , W , 3 ] [H, W, 3] [H,W,3] 变成了 [ H / 4 , W / 4 , 48 ] [H/4, W/4, 48] [H/4,W/4,48] - 然后在通过
Linear Embeding层对每个像素的channel数据做线性变换,由 48 48 48 变成 C C C,即图像shape再由 [ H / 4 , W / 4 , 48 ] [H/4, W/4, 48] [H/4,W/4,48] 变成了 [ H / 4 , W / 4 , C ] [H/4, W/4, C] [H/4,W/4,C] - 在调整特征矩阵的
channel之后,还对每个channel经过一个Layer Normalization - 在源码中
Patch Partition和Linear Embeding就是直接通过一个卷积层 ( k e r n e l _ s i z e = 4 × 4 , n u m s = 48 , s t r i d e s = 4 kernel\_size = 4 \times 4, \ nums = 48, \ strides = 4 kernel_size=4×4, nums=48, strides=4 ) 实现的,和之前 Vision Transformer 中讲的 Embedding 层结构一模一样
- 假设输入的是 RGB 三通道图片,那么每个
- 将输入的 H × W × 3 H \times W \times 3 H×W×3 的 RGB 图像拆分为非重叠等尺寸的 N × ( P 2 × 3 ) N \times (P^{2} \times 3) N×(P2×3)
- 然后就是通过四个
Stage构建不同大小的特征图,这些patch tokens(此时已为Linear Embedding)被馈入若干具有改进自注意力的Swin Transformer blocks。为产生一个层次化表示 ( Hierarchical Representation ),随着网络的加深,tokens数逐渐通过 Patch 合并层 ( Patch Meraging ) 被减少- 除了
Stage 1中先通过一个 Linear Embeding 层外,剩下三个Stage都是先通过一个Patch Merging层进行下采样,再重复堆叠Swin Transformer Block,Swin Transformer Block有两种结构(成对出现)- 一个使用了
W-MSA结构,一个使用了SW-MSA结构 - 先使用一个
W-MSA结构再使用一个SW-MSA结构
- 一个使用了
- 每个 Stage 都会改变张量的维度,从而形成一种层次化的表征
- 除了
- 最后对于分类网络,
Stage 4的后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出
2.2. Patch Merging
通过 Patch Merging 层后,feature map 的高和宽会减半,深度会翻倍

假设输入 Patch Merging 的是一个 4 × 4 4 \times 4 4×4 大小的单通道特征图(feature map)
Patch Merging会将每个 2 × 2 2 \times 2 2×2 的相邻像素划分为一个patch- 然后将每个
patch中相同位置(同一颜色)像素给拼在一起就得到了 4 个 feature map - 接着将这四个
feature map在深度方向进行concat拼接,然后在通过一个LayerNorm层 - 最后通过一个全连接层在
feature map的深度方向做线性变化,将feature map的深度由 C C C 变成 C / 2 C/2 C/2
与 Yolo v5 中的 focus 模块十分接近
2.3. Shifted Window based Self-Attention
2.3.1. MSA
标准的 Transformer 架构及其对图像分类的适应版本都执行全局自注意力,计算了每个 token 与其他所有 tokens 之间的关系 ( Attention Map ),即对每一个像素求它的 q , k , v q,k,v q,k,v,每一个像素求得的 q q q 将和整个特征图中所有像素的 k k k 进行一个匹配,然后进行其他相应的操作。
全局自注意力计算会导致相对于 token 计算二次复杂度
- 取
Self-attention计算的两次矩阵乘法的复杂度 - O ( M S A ) = O ( Q K ) + O ( Q K V ) = O ( N D 2 ) + O ( N 2 D ) = O ( N 2 D ) O(MSA) = O(QK) + O(QKV) = O(ND^2) + O(N^2D) = O(N^2D) O(MSA)=O(QK)+O(QKV)=O(ND2)+O(N2D)=O(N2D)
- N N N 为 token 数 / 序列长度
- D D D 为 token 向量长度 / 嵌入维度
- 使之不适用于许多需大量 tokens 进行密集预测或表示高分辨率图像等计算量很高的视觉问题。
Self-Attention 的公式如下所示:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt{d_k}}) V Attention(Q,K,V)=softmax(dkQKT)V
有关于 Multi-Head Self-Attention 的原理部分可以看我的另一篇 blog:CV-Model【5】:Transformer
2.3.2. W-MSA
引入 Windows Multi-head Self-Attention (W-MSA) 模块是为了减少计算量
在使用 Windows Multi-head Self-Attention (W-MSA) 模块时
- 首先将 feature map 按照 M × M M \times M M×M 大小划分成一个个 Windows
- 然后单独对每个 Window 内部进行 Self-Attention
基于窗口的自注意力模块 (W-MSA) 虽将计算复杂度从二次降为线性,但窗口之间无法进行信息交互,将限制感受野的大小(无法获取全局的视野,对最后的结果会有影响)
2.3.3. MSA & W-MSA Calculation volume
MSA 与 W-MSA 的计算复杂度如下所示:
Ω ( M S A ) = 4 h w C 2 + 2 ( h w ) 2 C Ω ( W − M S A ) = 4 h w C 2 + 2 M 2 h w c \Omega(MSA) = 4hwC^2 + 2(hw)^2C \\ \Omega(W-MSA) = 4hwC^2 + 2M^2hwc Ω(MSA)=4hwC2+2(hw)2CΩ(W−MSA)=4hwC2+2M2hwc
参数含义:
h代表 feature map 的高度w代表 feature map 的宽度C代表 feature map 的深度M代表每个窗口 (Windows) 的大小- 假如 h = w = 112 , M = 7 , C = 128 h=w=112,M=7,C=128 h=w=112,M=7,C=128,那么将节省
40124743680 FLOPs的计算量
公式含义:
MSA关于 patch token 数 h × w h \times w h×w 具有二次复杂度- 共 h × w h \times w h×w 个 patch tokens,每个 patch token 在全局计算 h × w h \times w h×w 次
W-MSA则当 M M M 固定时(默认设为 7)具有线性复杂度- 共 h × w h \times w h×w 个 patch tokens,每个 patch token 在各自的局部窗口内计算 M 2 M^2 M2 次
2.3.3.1. MSA Calculation volume
对于 feature map 中的每个像素(或称作 token,patch),都要通过 W q , W k , W v W_q, W_k, W_v Wq,Wk,Wv 生成对应的 query (q),key (k) 以及 value (v)。这里假设 q , k , v q, k, v q,k,v 的向量长度与 feature map 的深度 C C C 保持一致。那么对应所有像素生成 Q Q Q 的过程如下式:
A h w × C ⋅ W q C × C = Q h w × C A^{hw\times C} \cdot W_q^{C\times C} = Q^{hw\times C} Ahw×C⋅WqC×C=Qhw×C
等式含义:
- A h w × C A^{hw\times C} Ahw×C 为将所有像素(
token)拼接在一起得到的矩阵(一共有 h w hw hw 个像素,每个像素的深度为 C C C)hw行(一层feature map所包含的所有token),c列
- W q C × C W_q^{C\times C} WqC×C 为生成的
query的变换矩阵 - Q h w × C Q^{hw\times C} Qhw×C 为所有像素通过 W q C × C W_q^{C\times C} WqC×C 得到的
query拼接后的矩阵
矩阵运算的计算量公式:
A a × b ⋅ B b × c F L O P s = a × b × c A^{a\times b} \cdot B^{b\times c} \\ FLOPs = a \times b \times c Aa×b⋅Bb×cFLOPs=a×b×c
根据矩阵运算的计算量公式可以得到生成Q的计算量为 h w × C × C hw \times C \times C hw×C×C,生成 K K K 和 V V V 同理都是 h w C 2 hwC^2 hwC2,那么总共是 3 h w C 2 3hwC^2 3hwC2。接下来 Q Q Q 和 K T K^T KT 相乘,对应计算量为 ( h w ) 2 C (hw)^2 C (hw)2C:
Q h w × C ⋅ K T ( C × h w ) = X h w × h w Q^{hw\times C} \cdot K^{T(C\times hw)} = X^{hw\times hw} Qhw×C⋅KT(C×hw)=Xhw×hw
接下来忽略除以 d \sqrt d d 以及 softmax 的计算量,假设归一化后得到矩阵 Λ h w × h w \Lambda ^{hw \times hw} Λhw×hw,最后还要乘以 V V V(与这个矩阵做点积之后要保证输入输出的矩阵维度相同),对应的计算量为 ( h w ) 2 C (hw)^2 C (hw)2C:
Λ h w × h w ⋅ V h w × C = B h w × C \Lambda ^{hw \times hw} \cdot V^{hw\times C} = B^{hw\times C} Λhw×hw⋅Vhw×C=Bhw×C
那么对应单头的 Self-Attention 模块,总共需要 3 h w C 2 + ( h w ) 2 C + ( h w ) 2 C = 3 h w C 2 + 2 ( h w ) 2 C 3hwC^2 + (hw)^2C + (hw)^2C=3hwC^2 + 2(hw)^2C 3hwC2+(hw)2C+(hw)2C=3hwC2+2(hw)2C。
而在实际使用过程中,使用的是多头的 Multi-head Self-Attention 模块,在之前的文章中有进行过实验对比,多头注意力模块相比单头注意力模块的计算量仅多了最后一个融合矩阵 W O W_O WO 的计算量 h w C 2 hwC^2 hwC2
B h w × C ⋅ W O C × C = O h w × C B^{hw\times C} \cdot W_O^{C \times C} = O^{hw \times C} Bhw×C⋅WOC×C=Ohw×C
使用 MSA 模块的总计算量为: 4 h w C 2 + 2 ( h w ) 2 C 4hwC^2 + 2(hw)^2C 4hwC2+2(hw)2C
2.3.3.2. W-MSA Calculation volume
首先要将 feature map 划分到一个个窗口 ( Windows ) 中(窗口与窗口之间没有重叠),假设每个窗口的宽高都是 M M M,那么总共会得到 h M × w M \frac {h} {M} \times \frac {w} {M} Mh×Mw 个窗口,然后对每个窗口内使用多头注意力模块。刚刚计算高为 h h h,宽为 w w w,深度为 C C C 的 feature map 的计算量为 4 h w C 2 + 2 ( h w ) 2 C 4hwC^2 + 2(hw)^2C 4hwC2+2(hw)2C,这里每个窗口的高为 M M M 宽为 M M M,带入公式得:
4 ( M C ) 2 + 2 ( M ) 4 C 4(MC)^2 + 2(M)^4C 4(MC)2+2(M)4C
又因为有 h M × w M \frac {h} {M} \times \frac {w} {M} Mh×Mw 个窗口,则:
h M × w M × ( 4 ( M C ) 2 + 2 ( M ) 4 C ) = 4 h w C 2 + 2 M 2 h w c \frac {h} {M} \times \frac {w} {M} \times (4(MC)^2 + 2(M)^4C) = 4hwC^2 + 2M^2hwc Mh×Mw×(4(MC)2+2(M)4C)=4hwC2+2M2hwc
使用 W-MSA 模块的计算量为: 4 h w C 2 + 2 M 2 h w C 4hwC^2 + 2M^2 hwC 4hwC2+2M2hwC
2.3.3. SW-MSA
采用 W-MSA 模块时,只会在每个窗口内进行自注意力计算,所以窗口与窗口之间是无法进行信息传递的。为了解决这个问题,本文引入了 Shifted Windows Multi-Head Self-Attention (SW-MSA) 模块,即进行偏移的 W-MSA,以实现不同 Window 之间的信息交互
由上述信息我们可以知道,W-MSA 和 SW-MSA 是成对使用的。下图中左侧使用的是 W-MSA(假设是第 L 层),右侧使用的是 SW-MSA(假设是第 L+1 层),根据左右两幅图对比能够发现窗口(Windows)发生了偏移(可以理解成窗口从左上角分别向右侧和下方各偏移了 M 2 \frac {M} {2} 2M 个 patches)
偏移过程如下所示:
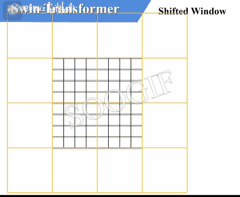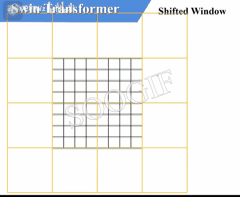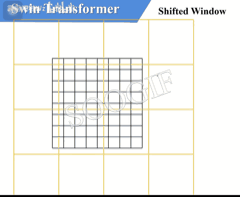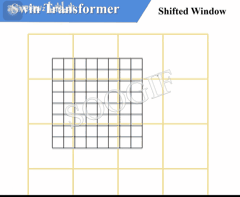
看下偏移后的窗口(右侧图):
- 对于第 1 1 1 行第 2 2 2 列的 2 × 4 2\times 4 2×4 的窗口,它能够使第 L L L 层的第一排的两个窗口信息进行交流
- 对于第 2 2 2 行第 2 2 2 列的 4 × 4 4 \times 4 4×4 的窗口,他能够使第 L L L 层的四个窗口信息进行交流
- 其余同理,这就解决了不同窗口之间无法进行信息交流的问题

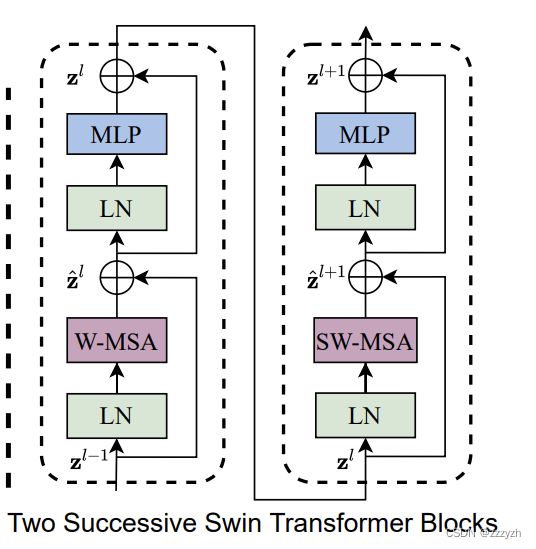
通过采用移位窗口划分方法,如下图的两个连续 Swin Transformer Blocks 的计算可表示为

参数含义:
- z ^ l \hat{z}^l z^l 第 l l l 个 block 的
(S)W-MSA模块输出特征 - z l z^l zl 第 l l l 个 block 的
MLP模块输出特征
2.3.4. Efficient batch computation for shifted configuration
一个关于移位窗口划分的问题是,从 h M × w M \frac{h}{M} \times \frac{w}{M} Mh×Mw 到 ( h M + 1 ) × ( w M + 1 ) (\frac{h}{M}+ 1 ) \times ( \frac{w}{M}+ 1 ) (Mh+1)×(Mw+1) 不但会产生更多窗口,而且有些窗口尺寸将小于 M × M M \times M M×M(窗口的大小做计算时向下取整)
一个朴素的解决方法是,将更小的窗口填充至 M × M M \times M M×M,且在计算注意力时屏蔽掉填充值。当规则划分的窗口数很少时,即 2 × 2 2 \times 2 2×2,由该朴素方法所带来的计算量增长是相当可观的 ( 2 × 2 → 3 × 3 2 \times 2 \rightarrow 3 \times 3 2×2→3×3,增大了 2.25 倍)

这种有效的批计算方法,通过循环将 SW-MSA 生成的 9 9 9 块 patches 循环向左上方移位 实现,在这种移位后,批窗口可由特征图中不相邻的子窗口组成。具体移位过程如下所示:
下图左侧是刚刚通过偏移窗口后得到的新窗口,右侧是对每个窗口加上了一个标识后的示意图
- 0 0 0 对应的窗口标记为区域 A A A
- 3 3 3 和 6 6 6 对应的窗口标记为区域 B B B
- 1 1 1 和 2 2 2 对应的窗口标记为区域 C C C
先将区域 A A A 和 C C C 移到最下方
将区域 A A A 和 B B B 移至最右侧,得到最后的结果图



移动完后
- 4 4 4 是一个单独的窗口
- 将 5 5 5 和 3 3 3 合并成一个窗口
- 将 7 7 7 和 1 1 1 合并成一个窗口
- 将 8 , 6 , 2 8,6,2 8,6,2 和 0 0 0 合并成一个窗口
这样又和原来一样是 4 4 4 个 4 × 4 4 \times 4 4×4 的窗口了,所以能够保证计算量是一样的。但是引入了一个新的问题:不属于一个窗口的信息合并在一起做 M S A MSA MSA 操作的时候将会互相影响。为了解决这个问题,在实际计算中使用的是 masked MSA 即带蒙板 mask 的 MSA,这样就能够通过设置蒙板来隔绝不同区域的信息了,并将自注意计算限制在每个子窗口内
masked MSA 机制:先正常计算自注意力,再进行 mask 操作将不需要的注意力图置 0 0 0,从而将自注意力计算限制在各子窗口内
- 针对的是不连续的数据,以上图为例
- 对于区域 4 4 4 可以直接进行
MSA操作(平移之后数据仍连续) - 而对于区域 5 , 3 5,3 5,3 就没办法直接对所有区域进行
MSA操作(否则我们将认为一张图片的左边和右边是有关的)
- 对于区域 4 4 4 可以直接进行
以区域5和区域3为例,解释 mask 的原理:
对于该窗口内的每一个patch(或称token),在进行MSA计算时,都要先生成对应的 q u e r y ( q ) query (q) query(q), k e y ( k ) key (k) key(k), v a l u e ( v ) value (v) value(v)
- 假设对于上图的像素 0 0 0 而言,得到 q 0 q^0 q0 后要与每一个像素的 k k k 进行匹配
- 假设 α 0 , 0 \alpha _{0,0} α0,0 代表 q 0 q^0 q0 与像素 0 0 0 对应的 k 0 k^0 k0 进行匹配的结果,那么同理可以得到 α 0 , 0 \alpha _{0,0} α0,0 至 α 0 , 15 \alpha _{0,15} α0,15
- 按照普通的MSA计算,接下来进行
SoftMax操作
- 像素 0 0 0 是属于区域 5 5 5 的,我们只想让它和区域 5 5 5 内的像素进行匹配。那么我们可以将像素 0 0 0 与区域 3 3 3 中的所有像素匹配结果都减去 100 100 100(例如 α 0 , 2 , α 0 , 3 , α 0 , 6 , α 0 , 7 \alpha _{0,2}, \alpha _{0,3}, \alpha _{0,6}, \alpha _{0,7} α0,2,α0,3,α0,6,α0,7 等等)
- 由于 α \alpha α 的值都很小,一般都是零点几的数,将其中一些数减去 100 100 100 后在通过
SoftMax得到对应的权重都等于 0 0 0 了。所以对于像素 0 0 0 而言实际上还是只和区域 5 5 5 内的像素进行了MSA- 那么对于其他像素也是同理

最后需要注意的是,在计算完后还要把数据给挪回到原来的位置上
2.3.5. Relative Position Bias
在计算自注意力时,我们在计算相似度的过程中对每个 head 加入相对位置偏置 B ∈ R M 2 × M 2 B \in \mathbb{R}^{M^2 \times M^2} B∈RM2×M2
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T d + B ) V Attention(Q,K,V)=SoftMax(\frac{QK^T}{\sqrt{d}}+B)V Attention(Q,K,V)=SoftMax(dQKT+B)V
参数含义:
- Q , K , V ∈ R M 2 , d Q, K, V \in \mathbb{R}^{M^2, d} Q,K,V∈RM2,d 分别为 Q u e r y Query Query, K e y Key Key 和 V a l u e Value Value 矩阵
- d d d 为 Q u e r y / K e y Query / Key Query/Key 维度
- M 2 M^2 M2 为 (局部) 窗口内的 patches 数
- 偏置矩阵 B ^ ∈ R ( 2 M − 1 ) × ( 2 M − 1 ) \hat{B} \in \mathbb{R}^{(2M-1) \times (2M-1)} B^∈R(2M−1)×(2M−1),且 B 中的值均取自 B ^ \hat{B} B^
举例说明如下所示:
假设输入的
feature map高宽都为 2
- 首先我们可以构建出每个像素的绝对位置索引(左下方的矩阵),对于每个像素的绝对位置是使用行号和列号表示的
- 比如蓝色的像素对应的是第 0 0 0 行第 0 0 0 列所以绝对位置索引是 ( 0 , 0 ) (0,0) (0,0)
- 接下来看相对位置索引
- 首先看下蓝色的像素,在蓝色像素使用 q q q 与所有像素 k k k 进行匹配过程中,是以蓝色像素为参考点,然后用蓝色像素的绝对位置索引与其他位置索引相减,就得到其他位置相对蓝色像素的相对位置索引
- 黄色像素的绝对位置索引是 ( 0 , 1 ) (0,1) (0,1),则它相对蓝色像素的相对位置索引为 ( 0 , 0 ) − ( 0 , 1 ) = ( 0 , − 1 ) (0, 0) - (0, 1)=(0, -1) (0,0)−(0,1)=(0,−1)
- 那么同理可以得到其他位置相对蓝色像素的相对位置索引矩阵
- 同样,也能得到相对黄色,红色以及绿色像素的相对位置索引矩阵
- 接下来将每个相对位置索引矩阵按行展平,并拼接在一起可以得到下面的 4 × 4 4 \times 4 4×4 矩阵
请注意,这里描述的一直是相对位置索引,并不是相对位置偏执参数
- 随后根据相对位置索引去取对应的参数
- 首先在原始的相对位置索引上加上 M − 1 M-1 M−1( M M M 为窗口的大小,在本示例中 M = 2 M=2 M=2),加上之后索引中就不会有负数了
- 接着将所有的行标都乘上 2 M − 1 2M-1 2M−1
- 最后将行标和列标进行相加
- 这样即保证了相对位置关系,而且不会出现上述 0 + ( − 1 ) = ( − 1 ) + 0 0+(-1)=(-1)+0 0+(−1)=(−1)+0 的问题了
- 刚刚上面提到了,之前计算的是相对位置索引,并不是相对位置偏执参数
- 经过上面的步骤,我们求得了
relative position index- 真正使用到的可训练参数 B ^ \hat{B} B^ 保存在
relative position bias table表里
- 这个表的长度等于 ( 2 M − 1 ) × ( 2 M − 1 ) (2M-1) \times (2M-1) (2M−1)×(2M−1)
- 从最开始的具有 4 个元素的
feature map可知,以左上角为参考能取到的极端索引值为 [ − 1 , − 1 ] [-1,-1] [−1,−1];以右下角为参考能取到的极端索引值为 [ 1 , 1 ] [1,1] [1,1]。即可以取到的索引范围为 [ − M + 1 , M − 1 ] [-M+1,M-1] [−M+1,M−1]- 行索引对应的可能取值的数目为 ( M − 1 ) − ( − M + 1 ) + 1 = 2 M − 1 (M-1)-(-M+1) + 1 = 2M-1 (M−1)−(−M+1)+1=2M−1,列索引同理
- 上述公式中的相对位置偏执参数B是根据上面的相对位置索引表根据查
relative position bias table表得到的
- 索引 4 4 4 所对应的参数值为 0.1 0.1 0.1,其余参数依此类推





2.3.6. Model configuration parameters
不同 Swin Transformer 的配置如下所示:
- T (Tiny)
- S (Small)
- B (Base)
- L (Large)

参数含义:
win. sz. 7x7表示使用的窗口(Windows)的大小dim表示feature map的channel深度(或者说token的向量长度)head表示多头注意力模块中head的个数
总结
博客参考
视频参考